少し前まで、私はかなり単純で興味深い仕事に出くわしました。読み取り専用端末をWebアプリケーションに実装することです。 タスクへの関心は、3つの重要な側面によって与えられました。
- 基本的なANSIエスケープシーケンスのサポート
- 少なくとも50,000データ行のサポート
- 利用可能になったデータを表示します。
この記事では、どのように実装し、どのように最適化したのかについて説明します。
免責事項:私は経験豊富なウェブ開発者ではないので、いくつかのことはあなたには明らかであると思われるかもしれません。 訂正と説明については、感謝します。
なぜそれまで
全体のタスクは次のとおりです。スクリプトはサーバー(bash、pythonなど)で実行され、stdoutに何かを書き込みます。 そして、この結論は、到着時にWebページに表示する必要があります。 同時に、端末上でのように見えるはずです(フォーマット、カーソル転送などを使用)
スクリプト自体とその出力は一切制御せず、純粋な形式で表示します。
もちろん、Webインターフェイスとスクリプトの間には、仲介者(Webサーバー)が必要です。 そして、解散しない場合-私はすでにウェブアプリケーションとサーバーを持っており、何らかの形で動作します。 スキームは次のようになります。

しかし以前は、サーバーが処理とフォーマットを担当していました。 そして、私は多くの理由でそれを改善したかった:
- ダブルデータ処理-最初にサーバーで解析し、次にクライアントでhtmlコンポーネントに変換します
- クライアントのデータ準備のための最適でないアルゴリズム
- サーバーの負荷が重い-単一のスクリプトからの出力を処理すると、サーバーに単一のストリームが完全にロードされる可能性があります
- ANSI Escapeシーケンスの不完全なサポート
- 微妙なバグ
- クライアントは1万行のフォーマットされた行を表示することでも非常に悪い結果を出しました
そのため、解析ロジック全体をWebアプリケーションに転送し、ストリーミング生データのみをサーバーに残すことにしました。
問題の声明
テキストの一部がクライアントに届きます。 クライアントは、それらをコンポーネントに解析する必要があります:プレーンテキスト、ラインフィード、キャリッジリターン、および特別なANSIコマンド。 部品の完全性には保証がありません。1つのコマンドまたは単語が異なるパッケージに含まれる場合があります。
ANSIコマンドは、テキストの形式(色、背景、スタイル)、カーソルの位置(後続のテキストを表示する場所)、または画面の一部をクリアするために影響を与える可能性があります。
どのように見えるかの例:

さらに、テキストには、認識および強調表示する必要があるURLが含まれている場合があります。
完成したライブラリーを受け取り...
すべてのコマンドを正しく高速に処理することは簡単なことではないことを理解しました。 したがって、私は既製のライブラリを探すことにしました。 そして、 見よ 、文字通りすぐにxterm.jsを見つけました。 端末の既製のコンポーネントは、すでに多くの場所で使用されており、さらに「非常に高速で、GPUアクセラレーションレンダラーも含まれています」 。 後者が私にとって最も重要でした。なぜなら、 私は最終的に非常に高速なクライアントを取得したかった。
私は自分の自転車を書くのが好きであるという事実にもかかわらず、時間を節約できるだけでなく、便利な機能を無料でたくさん手に入れることができることを非常に嬉しく思いました。
端末を接続しようとするのに午後2時かかり、それに対処できませんでした。 絶対に。
さまざまな行の高さ、曲がった選択、端末の適応サイズ、非常に奇妙なAPI、健全なドキュメントの欠如...
しかし、私にはまだ少しインスピレーションがあり、これらの問題に対処できると信じていました。
私がテスト10kラインをターミナルに送るまで...彼は死にました。 そして、私の希望の残りを私と一緒に埋めました。
最終的なアルゴリズムの説明
まず、Pythonで実装されている現在のアルゴリズムをコピーし、javascriptに適合させました(中括弧と別の構文を削除するだけです)。
古いアルゴリズムの主な長所と短所をすべて知っていたので、その中の無効な部分を改善するだけでした。
審議、試行錯誤の後、次のオプションに決めました。アルゴリズムを2つのコンポーネントに分割します。
- テキストを解析し、「端末」の現在の状態を保存するためのモデル
- モデルをHTMLに変換するマッピング
モデル(構造とアルゴリズム)
- すべての行は配列に格納されます(行番号=配列のインデックス)
- テキストスタイルは別の配列に保存されます。
- 現在のカーソル位置は保存され、コマンドで変更できます
- アルゴリズム自体は、入力データを文字ごとにチェックします。
- これが単なるテキストの場合、現在の行に追加します
- 改行の場合、現在の行インデックスを増やします
- これがチームキャラクターの1つである場合は、チームバッファーに入れて次のキャラクターを待ちます
- コマンドバッファーが正しい場合は、このコマンドを実行します。そうでない場合は、このバッファーをテキストとして書き込みます
- モデルは、着信テキストの処理後にどの行が変更されたかについてリスナーに通知します。
私の実装では、アルゴリズムの複雑さはO( n log n )です。lognは、通知(一意性と並べ替え)のために変更された行の準備です。 この記事を書いている時点で、行が最後に追加されることが最も多いため、特別な場合にはlog nを削除できることに気付きました。
ディスプレイ
- テキストをHTML要素として表示します
- 文字列が変更されている場合、文字列のすべての要素を完全に置き換えます
- スタイルに基づいて各行を分割します。各様式化されたセグメントには独自の要素があります
このような構造では、テストは非常に簡単なタスクです。テキストを(単一のパッケージまたはパーツで)モデルに転送し、その中のすべての行とスタイルの現在の状態を確認するだけです。 そして、いくつかのテストを表示するため、 変更された行は常に再描画されます。
重要な利点は、ディスプレイの特定の怠inessでもあります。 1つのテキストで同じ行(たとえば、進行状況バー)を上書きすると、モデルが機能した後、表示のために1行変更されたように見えます。
DOM vs Canvas
目標はパフォーマンスでしたが、なぜDOMを選んだのかについて少し説明したいと思います。 答えは簡単です-怠iness。 私にとっては、Canvasですべてを自分でレンダリングするのは、かなり困難な作業のように思えます。 使いやすさを維持しながら、ハイライト、コピー、画面のサイズ変更、見た目など xterm.jsの例から、これはまったく簡単ではないことが明確に示されました。 キャンバスでのレンダリングは理想とはほど遠いものでした。
さらに、ブラウザーでDOMツリーをデバッグし、単体テストをカバーする機能は重要な利点です。
最終的に、私の目標は5万行であり、古いアルゴリズムの作業に基づいて、DOMがこれに対処する必要があることを知っていました。
最適化
アルゴリズムは準備が完了し、デバッグされ、ゆっくりと、しかし確実に機能しました。 プロファイラーを開いて最適化するときが来ました。 将来を考えると、ほとんどの最適化は私にとって驚きでした(通常は起こります)。
プロファイリングは1万行で実行され、各行には定型化された要素が含まれていました。 DOM要素の総数は約100kです。
特別なアプローチやツールは使用されていません。 Chrome Dev Toolsと、各測定の数回の起動のみ。 実際には、起動時に、測定値の絶対値(完了までの秒数)のみが異なり、メソッド間の比率は変わりませんでした。 したがって、この手法は条件付きで十分であると考えます。
以下では、最も興味深い改善点について詳しく説明します。 そして、まず第一に、何のグラフでしたか:

すべてのプロファイリンググラフィックは、メモリからコードを最適化解除することにより、実装後に構築されました。
string.trim
まず第一に、非常に顕著な量のCPUを消費する不可解なstring.trimに出会いました(これは約10-20%だったようです)

trim()は、言語の基本機能です。 なんらかの種類のライブラリが使用されているのはなぜですか? そして、それが何らかのポリフィルであっても、なぜ最新バージョンのクロムをオンにしたのですか?
少しグーグルで答えが見つかります: https : //babeljs.io/docs/en/babel-preset-env デフォルトでは、かなり多くのブラウザーでポリフィルを有効にし、コンパイル段階でこれを行います。 私にとっての解決策は、 'targets': '> 0.25%, not dead'
を指定することでした'targets': '> 0.25%, not dead'
しかし、最終的には、不要なトリムコールを完全に削除しました。
Vue.js
昨年、私は端末コンポーネントをVue.jsに移行しました。 今、私はそれをバニラに戻す必要がありました、理由は以下のスクリーンショットにあります(Vue.jsを含む行の数を参照):
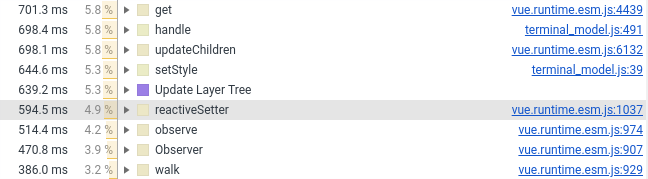
Vueコンポーネントにはラッパー、スタイル、およびマウス処理のみを残しました。 DOM要素の作成に関連するすべてのものは、通常のフィールドとしてVueコンポーネントに接続されている純粋なJSに送られました(フレームワークによって監視されません)。
created() { this.terminalModel = new TerminalModel(); this.terminal = new Terminal(this.terminalModel); },
私はこれをVue.jsのマイナスまたは欠陥とは考えていません。 フレームワークとパフォーマンス自体の組み合わせが不十分なだけです。 さて、数万から数十万のオブジェクトをリアクティブフレームワークにドロップすると、数ミリ秒以内にそこから処理することを期待するのは非常に困難です。 正直に言うと、Vue.jsが非常にうまくいったことにも驚きました。
新しいアイテムを追加する
ここではすべてが簡単です。数千の新しい要素があり、それらを親コンポーネントに追加する場合、appendChildを実行することはお勧めできません。 ブラウザは処理をもう少し頻繁に実行し、レンダリングにより多くの時間を費やす必要があります。 私の場合の副作用の1つは、自動スクロールの速度低下でした。 追加されたすべてのコンポーネントの再カウントを強制します。

この問題を解決するために、DocumentFragmentがあります。 まず、すべての要素を追加してから、親コンポーネントに追加します。 ブラウザは、着信コンポーネントのインラインを処理します。
このアプローチは、ブラウザーが要素のレンダリングと配置に費やす時間を削減します。
また、要素の追加を高速化する他の方法も試しました。 DocumentFragmentの上に何かを追加することはできませんでした。
スパンvs div
実際には、 display:inline
(span)vs display:block
(div)と呼ばれdisplay:inline
。
最初に、私が持っていた各行はスパンにあり、改行文字で終了しました。 ただし、パフォーマンスの点では、これはあまり効果的ではありません。ブラウザーは、要素の開始位置と終了位置を把握する必要があります。 display:blockを使用すると、このような計算ははるかに簡単になります。
divに置き換えると、レンダリングがほぼ2倍加速されました。
残念ながら、 display:block
場合、複数行のテキストを強調表示するのは悪く見えます:

長い間、どちらが良いかを判断できませんでした-余分な2秒のレンダリングまたは人間の選択。 その結果、実用性は美を打ち負かしました。
レベル10 CSSウィザード
テキストの書式設定に使用するCSSを「最適化」することにより、レンダリング時間のもう10%が削減されました。
Web開発の経験が浅く、基本的なことを理解できなかったことが私に反論しました。 セレクタが正確であればあるほど良いと思いましたが、特に私の場合はそうではありませんでした。
ターミナルでテキストをフォーマットするには、次のセレクターを使用しました。
#script-panel-container .log-content > div > span.text_color_green,
しかし(クロムで)、次のオプションは少し速いです:
span.text_color_green
私はこのセレクターがあまり好きではありません、なぜなら グローバルすぎますが、パフォーマンスはより高くなります。
string.split
前の点のいずれかに起因するdeja vuがある場合、それはfalseです。 今回はポリフィルではなく、クロムの標準実装についてです。

(string.splitをdefSplitでラップして、プロファイラーに関数が表示されるようにしました)
1%は些細なことです。 しかし、私の理想主義的なサイクリストは幽霊が出ました。 私の場合、分割は常に一度に1文字ずつ行われ、正規表現はありません。 したがって、単純なオプションを実装しました。 結果は次のとおりです。

function fastSplit(str, separatorChar) { if (str === '') { return ['']; } let result = []; let lastIndex = 0; for (let i = 0; i < str.length; i++) { const char = str[i]; if (char === separatorChar) { const chunk = str.substr(lastIndex, i - lastIndex); lastIndex = i + 1; result.push(chunk); } } if (lastIndex < str.length) { const lastChunk = str.substr(lastIndex, str.length - lastIndex); result.push(lastChunk); } return result; }
この後、彼らはインタビューなしで私をGoogle Chromeチームに連れて行く義務があると思います。
最適化、あとがき
最適化は終わりのないプロセスであり、何かを無期限に改善できます。 特に、異なるユースケースでは異なる(および競合する)最適化が必要であることを考慮してください。
私の場合、主なユースケースを選択し、その動作時間を15秒から5秒に最適化しました。 これで私はやめることにした。

改善する予定の場所はまだいくつかありますが、これは得られた経験のおかげです。
ボーナス 突然変異テスト。
過去数ヶ月間、私はしばしば「突然変異テスト」という用語に出くわしました。 そして、私はこの仕事がこの獣を試す素晴らしい方法であると決めました。 特に、カルマのテストのために、Webstormでコードカバレッジを取得しなかった後。
テクニックとライブラリの両方が私にとって新しいので、私は少しの血でうまくいくことに決めました:1つのコンポーネントだけをテストする-モデル。 この場合、どのファイルをテストしているか、どのテストスイートがそれを対象としているかを明確に示すことができます。
しかし、とにかく、私はカルマとwebpackとの統合を達成するために多くをいじる必要がありました。
結局、すべてが起動し、30分後に悲しい結果が見られました:ミュータントの約半分が生き残りました。 一度にいくつかを殺し、将来のためにいくつかを残しました(欠落しているANSIコマンドを実装したとき)。
その後、怠lazが勝ち、現在の結果は次のとおりです(128テストの場合)。
Ran 79.04 tests per mutant on average. ------------------|---------|----------|-----------|------------|---------| File | % score | # killed | # timeout | # survived | # error | ------------------|---------|----------|-----------|------------|---------| terminal_model.js | 73.10 | 312 | 25 | 124 | 1 | ------------------|---------|----------|-----------|------------|---------| 23:01:08 (18212) INFO Stryker Done in 26 minutes 32 seconds.
一般に、このアプローチは私にとって非常に有用であり(コードカバレッジより明らかに優れている)、おもしろいように思えました。 唯一のマイナスは、非常に長い時間です。1つのクラスで30分が長すぎます。
そして最も重要なことは、このアプローチにより、100%のカバレッジと、すべてをテストでカバーする価値があるかどうかについて考え直したことです。
おわりに
私の意見では、パフォーマンスの最適化は、より深いことを学ぶ良い方法です。 脳にとっても良いトレーニングです。 そして、これが本当に必要なことはめったにありません(少なくとも私のプロジェクトでは)。
そして、いつものように、「最初のプロファイリング、次に最適化」アプローチは直感よりもはるかにうまく機能します。
参照資料
古い実装:
新しい実装:
残念ながら、Webコンポーネントのデモはありませんので、あなたはそれを突くことができません。 事前に謝罪します
お時間をいただきありがとうございます。コメント、提案、合理的な批判を歓迎します。