この部分では、約束したように、 _construct_key()関数の分析を取り上げます。この関数は、プログラムに転送されたバイナリファイルを読み取り、読み取ったデータを確認する役割を果たします。
ステップ5-_construct_key()関数の概要
この関数の完全なリストをすぐに見てみましょう。
_construct_key()のリスト
char ** __cdecl _construct_key(FILE *param_1) { int iVar1; size_t sVar2; uint uVar3; uint local_3c; byte local_36; char local_35; int local_34; char *local_30 [4]; char *local_20; undefined4 local_19; undefined local_15; char **local_14; int local_10; local_14 = (char **)__prepare_key(); if (local_14 == (char **)0x0) { local_14 = (char **)0x0; } else { local_19 = 0; local_15 = 0; _text(&local_19,1,4,param_1); iVar1 = _text((char *)&local_19,*(char **)local_14[1],4); if (iVar1 == 0) { _text(local_14[1] + 4,2,1,param_1); _text(local_14[1] + 6,2,1,param_1); if ((*(short *)(local_14[1] + 6) == 4) && (*(short *)(local_14[1] + 4) == 5)) { local_30[0] = *local_14; local_30[1] = *local_14 + 0x10c; local_30[2] = *local_14 + 0x218; local_30[3] = *local_14 + 0x324; local_20 = *local_14 + 0x430; local_10 = 0; while (local_10 < 5) { local_35 = 0; _text(&local_35,1,1,param_1); if (*local_30[local_10] != local_35) { _free_key(local_14); return (char **)0x0; } local_36 = 0; _text(&local_36,1,1,param_1); if (local_36 == 0) { _free_key(local_14); return (char **)0x0; } *(uint *)(local_30[local_10] + 0x104) = (uint)local_36; _text(local_30[local_10] + 1,1,*(size_t *)(local_30[local_10] + 0x104),param_1); sVar2 = _text(local_30[local_10] + 1); if (sVar2 != *(size_t *)(local_30[local_10] + 0x104)) { _free_key(local_14); return (char **)0x0; } local_3c = 0; _text(&local_3c,1,1,param_1); local_3c = local_3c + 7; uVar3 = _text(param_1); if (local_3c < uVar3) { _free_key(local_14); return (char **)0x0; } *(uint *)(local_30[local_10] + 0x108) = local_3c; _text(param_1,local_3c,0); local_10 = local_10 + 1; } local_34 = 0; _text(&local_34,4,1,param_1); if (*(int *)(*local_14 + 0x53c) == local_34) { _text("Markers seem to still exist"); } else { _free_key(local_14); local_14 = (char **)0x0; } } else { _free_key(local_14); local_14 = (char **)0x0; } } else { _free_key(local_14); local_14 = (char **)0x0; } } return local_14; }
この関数を使用して、 main()を使用して以前と同じ処理を行います。最初に、「ベール化された」関数呼び出しについて説明します。 予想どおり、これらの関数はすべて標準Cライブラリからのものであるため、関数の名前を変更する手順については説明しません-必要に応じて、記事の最初の部分に戻ります。 名前を変更した結果、次の標準機能が「見つかりました」:
- 恐怖()
- strncmp()
- strlen()
- ftell()
- fseek()
- 置く()
インデックス2を追加することにより、元のC関数との混乱がないように、コード内の対応するラッパー関数の名前を変更しました(逆コンパイラが単語_textの後ろに大胆に隠れていたもの)。 これらの関数のほとんどすべては、ファイルストリームの操作に使用されます。 驚くことではありません-コードを一目見れば、ファイルからデータを順番に読み取り(その記述子は唯一のパラメーターとして関数に渡される)、読み取ったデータをlocal_14バイトの特定の2次元配列と比較することを理解するのに十分です。
この配列に鍵検証用のデータが含まれていると仮定しましょう。 key_arrayのように呼び出します。 Hydraでは、関数だけでなく変数の名前も変更できるため、これを使用して、わかりにくいlocal_14をより理解しやすいkey_arrayに変更します。 これは、機能の場合と同じ方法で行われます。マウスの右ボタンのメニュー( ローカル名の変更 )を使用するか、キーボードのLキーを使用します。
したがって、ローカル変数の宣言の直後に、特定の関数_prepare_key()が呼び出されます。
key_array = (char **)__prepare_key(); if (key_array == (char **)0x0) { key_array = (char **)0x0; }
_prepare_key()に戻ります。これは、呼び出し階層のネストの3番目のレベルです: main()-> _construct_key()-> _prepare_key() 。 それまでは、この「テスト」2次元配列を作成し、何らかの方法で初期化することを受け入れます。 そして、この配列が空でない場合にのみ、上記の条件の直後のelseブロックによって証明されるように、関数はその作業を継続します。
次に、プログラムはファイルから最初の4バイトを読み取り、 key_array配列の対応するセクションと比較します。 (以下のコードは、 local_19変数を含む名前変更後のもので、 first_4bytesの名前を変更しました 。)
first_4bytes = 0; /* 4 */ fread2(&first_4bytes,1,4,param_1); /* key_array[1][0...3] */ iVar1 = strncmp2((char *)&first_4bytes,*(char **)key_array[1],4); if (iVar1 == 0) { ... }
したがって、最初の4バイトが一致する場合にのみ、さらに実行されます(これを思い出してください)。 次に、ファイルから2つの2バイトブロックを読み取ります(データを書き込むためのバッファーとして同じkey_arrayが使用されます)。
fread2(key_array[1] + 4,2,1,param_1); fread2(key_array[1] + 6,2,1,param_1);
そしてまた-次の条件が真である場合にのみ機能が動作します:
if ((*(short *)(key_array[1] + 6) == 4) && (*(short *)(key_array[1] + 4) == 5)) { // ... }
上記で読み取られた2バイトブロックの最初が5番で、2番目が4番であることが簡単にわかります(32ビットプラットフォームではデータ型shortは2バイトを占めるだけです)。
次はこれです:
local_30[0] = *key_array; // .. key_array[0] local_30[1] = *key_array + 0x10c; local_30[2] = *key_array + 0x218; local_30[3] = *key_array + 0x324; local_20 = *key_array + 0x430;
ここで、 local_30配列(char * local_30 [4]として宣言されている)がkey_arrayポインターのオフセットを記録していることがわかります。 つまり、 local_30はマーカー行の配列であり、ファイルからデータがおそらく読み込まれます。 この仮定の下で、 local_30の名前をmarkerに変更しました。 コードのこのセクションでは、最後の行のみが少し疑わしいようです。最後のオフセット(インデックス0x430、つまり1072)の割り当ては、次のマーカー要素ではなく、別のlocal_20変数( char * )によって実行されます。 しかし、私たちはそれを理解しますが、今のところは-先に進みましょう!
次に、サイクルを待っています:
i = 0; // local_10 i while (i < 5) { // ... i = i + 1; }
つまり 0から4までの5回の反復のみ。 ループでは、ファイルからの読み取りとマーカー配列への準拠の確認がすぐに開始されます。
char c_marker = 0; // local_35 /* . */ fread2(&c_marker, 1, 1, param_1); if (*markers[i] != c_marker) { /* - */ _free_key(key_array); return (char **)0x0; }
つまり、ファイルの次のバイトが(元の逆コンパイルされたコード-local_35の ) c_marker変数に読み込まれ、i番目のマーカー要素の最初の文字に準拠しているかどうかがチェックされます。 不一致の場合、 key_array配列は無効化され、空のダブルポインターが返されます。 さらにコードに沿って、読み取りデータが検証データと一致しないたびにこれが行われることがわかります。
しかし、ここでは、彼らが言うように、「犬は埋葬されています。」 このサイクルを詳しく見てみましょう。 私たちが発見したように、それは5つの反復を持っています。 必要に応じて、アセンブラコードを確認して確認できます。


実際、CMPコマンドはlocal_10変数の値(すでにiを持っています)と数値4を比較し、値が4 以下 (JLEコマンド)である場合、ラベルLAB_004017ebへの遷移が行われます 。 サイクルの本体の始まり。 つまり 条件はi = 0、1、2、3、および4で満たされます-5回の反復のみです! すべてうまくいきますが、 マーカーはループ内のこの変数によってもインデックス付けされ、この配列はすべて4つの要素のみで宣言されます。
char *markers [4];
だから、誰かが明らかに誰かをだまそうとしている:)覚えている、私はこの行が疑わしいと言った?
local_20 = *key_array + 0x430;
そのように! 関数のリスト全体を見て、 local_20変数への参照を少なくとも1つ見つけてください。 彼女はいない! 結論として、このオフセットはマーカー配列にも保存され、配列自体には5つの要素が含まれている必要があります。 それを修正しましょう。 変数宣言に移動し、 Ctrl + L (変数の再入力)を押して 、配列のサイズを5に大胆に変更します。
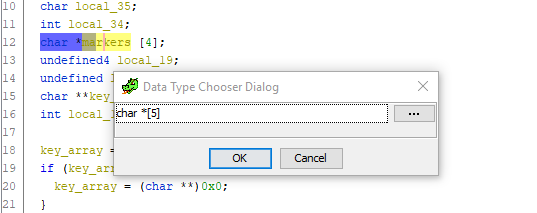
できた マーカーオフセットにポインターオフセットを割り当てるためのコードまでスクロールし、そして-見よ! -理解できない余分な変数が消え、すべてが所定の位置に収まります。
markers[0] = *key_array; markers[1] = *key_array + 0x10c; markers[2] = *key_array + 0x218; markers[3] = *key_array + 0x324; markers[4] = *key_array + 0x430; // ... !
whileループに戻ります (ソースコードでは、おそらくforになりますが 、気にしません)。 次に、ファイルからバイトが再度読み取られ、その値がチェックされます。
byte n_strlen1 = 0; // local_36 /* . */ fread2(&n_strlen1,1,1,param_1); if (n_strlen1 == 0) { /* */ _free_key(key_array); return (char **)0x0; }
OK、このn_strlen1はゼロ以外でなければなりません。 なんで? 表示されますが、同時にこの変数に次の名前を付けた理由を理解できます。
/* n_strlen1) (markers[i] + 0x104) */ *(uint *)(markers[i] + 0x104) = (uint)n_strlen1; /* (n_strlen1) (--> ?) */ fread2(markers[i] + 1,1,*(size_t *)(markers[i] + 0x104),param_1); n_strlen2 = strlen2(markers[i] + 1); // sVar2 if (n_strlen2 != *(size_t *)(markers[i] + 0x104)) { /* (n_strlen2) == n_strlen1 */ _free_key(key_array); return (char **)0x0; }
すべてを明確にする必要があるコメントを追加しました。 N_strlen1バイトがファイルから読み取られ、一連の文字(つまり文字列)としてマーカー[i]配列に保存されます。つまり、 key_arrayからすでに書き込まれた対応する「停止シンボル」の後に保存されます。 値n_strlen1をマーカー[i]のオフセット0x104(260)に保存しても、ここでは何の役割も果たしません(上記のコードの最初の行を参照)。 実際、このコードは次のように最適化することができます(そして確かにこれはソースコードの場合です)。
fread2(markers[i] + 1, 1, (size_t) n_strlen1, param_1); n_strlen2 = strlen2(markers[i] + 1); if (n_strlen2 != (size_t) n_strlen1) { ... }
また、読み取り行の長さがn_strlen1であることも確認します。 このパラメーターがfread関数に渡された場合、これは冗長に思えるかもしれませんが、 fread は 、指定されたバイト数を超えないため、たとえば、ファイルの終わりマーカー(EOF)を満たしている場合など、指定されたバイト未満を読み取ることができます。 つまり、すべてが厳密です。ファイル内で行の長さ(バイト単位)が示され、行自体が-5回だけです。 しかし、私たちは自分自身に先んじています。
このコードにさらに手を加えます(これについてもすぐにコメントしました)。
uint n_pos = 0; // local_3c /* . */ fread2(&n_pos,1,1,param_1); /* 7 */ n_pos = n_pos + 7; /* */ uint n_filepos = ftell2(param_1); // uVar3 if (n_pos < n_filepos) { /* n_pos >= n_filepos */ _free_key(key_array); return (char **)0x0; }
ここではさらに簡単です。ファイルから次のバイトを取得し、7を追加して、結果の値をftell()関数で取得したファイルストリームの現在のカーソル位置と比較します。 n_posの値は、カーソル位置(ファイルの先頭からのバイト単位のオフセット)以上でなければなりません。
ループの最後の行:
fseek2(param_1,n_pos,0);
つまり ファイルカーソルを(先頭から) fseek()関数によってn_posで示される位置に再配置します。 OK、ループでこれらのすべての操作を5回行います。 _construct_key()関数は、次のコードで終了します。
int i_lastmarker = 0; // local_34 /* 4 (int32) */ fread2(&i_lastmarker,4,1,param_1); if (*(int *)(*key_array + 0x53c) == i_lastmarker) { /* == key_array[0][1340] ... :) */ puts2("Markers seem to still exist"); } else { _free_key(key_array); key_array = (char **)0x0; }
したがって、ファイル内のデータの最後のブロックは4バイトの整数値であり、 key_array [0] [1340]の値と等しくなければなりません。 この場合、コンソールにお祝いのメッセージが表示されます。 それ以外の場合、空の配列はまだ賞賛なしで戻ります:)
ステップ6-__prepare_key()関数の概要
アセンブルされていない関数が 1つだけ残っています-__prepare_key() 。 検証データがkey_array配列の形式で形成されるのはその中にあるとすでに推測しています。この配列は_construct_key()関数で使用され、ファイルのデータを検証します。 そこにどんな種類のデータがあるのかを知ることは残っています!
この関数を詳細に分析することはせず、必要な変数名をすべて変更した後、すぐにコメント付きの完全なリストを提供します。
__Prepare_key()関数のリスト
void ** __prepare_key(void) { void **key_array; void *pvVar1; /* key_array = new char*[2]; // 2 4- (char*) */ key_array = (void **)calloc2(1,8); if (key_array == (void **)0x0) { key_array = (void **)0x0; } else { pvVar1 = calloc2(1,0x540); /* key_array[0] = new char[1340] */ *key_array = pvVar1; pvVar1 = calloc2(1,8); /* key_array[1] = new char[8] */ key_array[1] = pvVar1; /* "VOID" */ *(undefined4 *)key_array[1] = 0x404024; /* 5 4 (2- ) */ *(undefined2 *)((int)key_array[1] + 4) = 5; *(undefined2 *)((int)key_array[1] + 6) = 4; /* key_array[0][0] = 'b' */ *(undefined *)*key_array = 0x62; *(undefined4 *)((int)*key_array + 0x104) = 3; /* 'W' */ *(undefined *)((int)*key_array + 0x218) = 0x57; /* 'p' */ *(undefined *)((int)*key_array + 0x324) = 0x70; /* 'l' */ *(undefined *)((int)*key_array + 0x10c) = 0x6c; /* 152 ( ASCII) */ *(undefined *)((int)*key_array + 0x430) = 0x98; /* = 1122 (int32) */ *(undefined4 *)((int)*key_array + 0x53c) = 0x462; } return key_array; }
考慮に値する唯一の場所は次の行です。
*(undefined4 *)key_array[1] = 0x404024;
ここに「VOID」という行があることをどのように理解できますか? 実際、0x404024は.rdataセクションにつながるプログラムのアドレス空間内のアドレスです。 この値をダブルクリックすると、何があるか一目でわかります。

ところで、これはこの行のアセンブラコードから理解できます。
004015da c7 00 24 MOV dword ptr [EAX], .rdata = 56h V
40 40 00
VOID行に対応するデータは、 .rdataセクションの先頭にあります (対応するアドレスからのオフセットはゼロ)。
そのため、この関数の終了時に、次のデータで2次元配列を形成する必要があります。
[0] [0]:'b' [268]:'l' [536]:'W' [804]:'p' [1072]:152 [1340]:1122
[1] [0-3]:"VOID" [4-5]:5 [6-7]:4
ステップ7-クラック用のバイナリを準備する
これで、バイナリファイルの合成を開始できます。 私たちの手にあるすべての初期データ:
1)検証データ(「ストップシンボル」)および検証配列内の位置。
2)ファイル内のデータのシーケンス
_construct_key()関数のアルゴリズムに従って、探しているファイルの構造を復元しましょう。 したがって、ファイル内のデータのシーケンスは次のようになります。
ファイル構造
- 4バイト== key_array [1] [0 ... 3] == "無効"
- 2バイト== key_array [1] [4] == 5
- 2バイト== key_array [1] [6] == 4
- 1バイト== key_array [0] [0] == 'b'(トークン)
- 1バイト==(次の行の長さ)== n_strlen1
- n_strlen1バイト==(任意の文字列)== n_strlen1
- 1バイト==(+7 ==次のトークン)== n_pos
- 1バイト== key_array [0] [0] == 'l'(トークン)
- 1バイト==(次の行の長さ)== n_strlen1
- n_strlen1バイト==(任意の文字列)== n_strlen1
- 1バイト==(+7 ==次のトークン)== n_pos
- 1バイト== key_array [0] [0] == 'W'(トークン)
- 1バイト==(次の行の長さ)== n_strlen1
- n_strlen1バイト==(任意の文字列)== n_strlen1
- 1バイト==(+7 ==次のトークン)== n_pos
- 1バイト== key_array [0] [0] == 'p'(トークン)
- 1バイト==(次の行の長さ)== n_strlen1
- n_strlen1バイト==(任意の文字列)== n_strlen1
- 1バイト==(+7 ==次のトークン)== n_pos
- 1バイト== key_array [0] [0] == 152(トークン)
- 1バイト==(次の行の長さ)== n_strlen1
- n_strlen1バイト==(任意の文字列)== n_strlen1
- 1バイト==(+7 ==次のトークン)== n_pos
- 4バイト==(key_array [1340])== 1122
明確にするために、Excelで目的のファイルのデータを使用してこのようなタブレットを作成しました。

ここの7行目-文字と数字の形式のデータ自体、6行目-8行目の16進表現-8行目の各要素のサイズ(バイト単位)、9行目-ファイルの先頭からのオフセット。 このビューは非常に便利です 将来のファイル(黄色の塗りつぶしでマーク)に任意の行を入力できますが、これらの行の長さの値と次の停止記号の位置オフセットは、プログラムアルゴリズムが必要とする式によって自動的に計算されます。 上記(1〜4行目)では、 key_arrayチェック配列の構造が示されています。
エクセル自体と記事の他のソース資料は、 ここからダウンロードできます 。
バイナリファイルの生成と検証
残っているのは、目的のファイルをバイナリ形式で生成し、クラックでフィードすることだけです。 ファイルを生成するために、単純なPythonスクリプトを作成しました。
ファイルを生成するスクリプト
import sys, os import struct import subprocess out_str = ['!', 'I', ' solved', ' this', ' crackme!'] def write_file(file_path): try: with open(file_path, 'wb') as outfile: outfile.write('VOID'.encode('ascii')) outfile.write(struct.pack('2h', 5, 4)) outfile.write('b'.encode('ascii')) outfile.write(struct.pack('B', len(out_str[0]))) outfile.write(out_str[0].encode('ascii')) pos = 10 + len(out_str[0]) outfile.write(struct.pack('B', pos - 6)) outfile.write('l'.encode('ascii')) outfile.write(struct.pack('B', len(out_str[1]))) outfile.write(out_str[1].encode('ascii')) pos += 3 + len(out_str[1]) outfile.write(struct.pack('B', pos - 6)) outfile.write('W'.encode('ascii')) outfile.write(struct.pack('B', len(out_str[2]))) outfile.write(out_str[2].encode('ascii')) pos += 3 + len(out_str[2]) outfile.write(struct.pack('B', pos - 6)) outfile.write('p'.encode('ascii')) outfile.write(struct.pack('B', len(out_str[3]))) outfile.write(out_str[3].encode('ascii')) pos += 3 + len(out_str[3]) outfile.write(struct.pack('B', pos - 6)) outfile.write(struct.pack('B', 152)) outfile.write(struct.pack('B', len(out_str[4]))) outfile.write(out_str[4].encode('ascii')) pos += 3 + len(out_str[4]) outfile.write(struct.pack('B', pos - 6)) outfile.write(struct.pack('i', 1122)) except Exception as err: print(err) raise def main(): if len(sys.argv) != 2: print('USAGE: {this_script.py} path_to_crackme[.exe]') return if not os.path.isfile(sys.argv[1]): print('File "{}" unavailable!'.format(sys.argv[1])) return file_path = os.path.splitext(sys.argv[1])[0] + '.dat' try: write_file(file_path) except: return try: outputstr = subprocess.check_output('"{}" -f "{}"'.format(sys.argv[1], file_path), stderr=subprocess.STDOUT) print(outputstr.decode('utf-8')) except Exception as err: print(err) if __name__ == '__main__': main()
スクリプトは、クラックへのパスを単一のパラメーターとして取得し、同じディレクトリにキーを持つバイナリファイルを生成し、対応するパラメーターでクラックを呼び出して、プログラム出力をコンソールに変換します。
テキストデータをバイナリに変換するには、 structパッケージを使用します。 pack()メソッドを使用すると、データ型が示される形式( "B" = "byte"、 "i" = intなど)でバイナリデータを書き込むことができます。また、シーケンス( ">" = "Big -endian "、" <"="リトルエンディアン ")。 デフォルトの順序はリトルエンディアンです。 なぜなら 最初の記事で、これがまさに私たちのケースであると既に決定しており、タイプのみを示しています。
すべてのコードは全体として、発見したプログラムアルゴリズムを再現します。 行として、成功した場合の出力として、「このcrackmeを解決しました!」を指定しました(このスクリプトを変更して、任意の行を指定できるようにすることができます)。
出力を確認します。

やれやれ、すべてうまくいく! そのため、少し汗をかいて、いくつかの機能を整理し、プログラムアルゴリズムを完全に復元して「クラック」することができました。 もちろん、これは単なるクラック、テストプログラム、さらには2番目の難易度(そのサイトで提供されている5つのうち)のものです。 実際には、複雑な呼び出しの階層と数十、数百の関数、場合によっては、内部仮想マシンとPコードの使用までのデータの暗号化されたセクション、ガベージコード、その他の難読化手法を扱います...まったく異なる話。
記事の資料。