このアプローチは、私たちの国と西洋でどの程度関連していますか? たとえば、HabréおよびMediumの記事で結論を出すことができます。 予測保守の問題の解決に関するHabréに関する記事はほとんどありません。 Mediumにはセット全体があります。 ここ、 ここ 、 ここでは 、このアプローチの目標と利点を詳しく説明しています。
この記事から次のことを学びます。
- この技術が必要な理由
- どの機械学習アプローチが予測メンテナンスに一般的に使用されていますか、
- 簡単な例を使ってトリックの1つをどのように試したか。

出所
予測サービスはどのような機能を提供しますか?
- 必要に応じて実行される、修復作業の制御されたプロセス。これにより、費用を節約し、急いで、これらの作業の品質を向上させます。
- 機器の動作における特定の誤動作の特定(機器が動作しているときに交換のために特定の部品を購入できることは大きな利点を提供します);
- 機器の動作、負荷などの最適化。
- 機器の定期的なシャットダウンのコストの削減。
Mediumに関する次の記事では、特定のケースでこの問題に対処する方法を理解するために回答する必要がある質問について詳しく説明しています。
データを収集するとき、またはデータを選択してモデルを構築するとき、次の3つのグループの質問に答えることが重要です。
- すべてのシステムの問題を予測できますか? どの予測が特に重要ですか?
- 障害プロセスとは何ですか? システム全体が動作を停止しますか、または動作モードのみが変更されますか? それは迅速なプロセスですか、瞬間的または段階的な劣化ですか?
- システムのパフォーマンスは、そのパフォーマンスを適切に反映していますか? それらはシステムの個々の部分に関係していますか、それともシステム全体に関係していますか?
また、予測したいこと、予測できること、不可能なことを事前に理解することも重要です。
Mediumに関する記事には、特定の目標を決定するのに役立つ質問もリストされています。
- 何を予測する必要がありますか? 残りの寿命、異常な動作かどうか、次のN時間/日/週の失敗の確率?
- 十分な履歴データがありますか?
- システムが異常な測定値を与えたときと、そうでないときがわかっています。 そのような兆候をマークすることは可能ですか?
- モデルはどこまで見る必要がありますか? 時間/日/週の間隔でのシステムの動作を反映する測定値の独立性
- 最適化するには何が必要ですか? モデルが可能な限り多くの違反をキャッチする一方で、誤報を与えるべきか、それとも誤検知のない複数のイベントをキャッチするのに十分か。
今後状況が改善されることが望まれます。 これまで、予知保全の分野には困難があります。システムの誤動作の例はほとんどないか、システムの誤動作の瞬間で十分ですが、マークアップされていません。 失敗プロセスは不明です。
予知保全の困難を克服する主な方法は、 異常検索方法を使用することです。 このようなアルゴリズムは、トレーニングのためのマークアップを必要としません。 アルゴリズムをテストおよびデバッグするには、何らかの形式のマークアップが必要です。 そのような方法は、特定の障害を予測せず、インジケータの異常を通知するだけであるという点で制限されています。
しかし、これはすでに悪いことではありません。

出所
方法
次に、異常検出アプローチのいくつかの機能について説明したいと思います。その後、実際にいくつかの簡単なアルゴリズムの機能をテストします。
特定の状況では、異常を検索して最適なアルゴリズムを選択するためにいくつかのアルゴリズムをテストする必要がありますが、この分野で使用される主な手法の長所と短所を特定することは可能です。
まず、データの異常の割合を事前に理解することが重要です。
半教師ありアプローチのバリエーションについて話している場合(「通常の」データのみを調査し、異常のあるデータで作業(テスト)します)、最も最適な選択は、1つのクラス( One-Class SVM )のサポートベクトル法です。 動径基底関数をカーネルとして使用する場合、このアルゴリズムは原点の周りに非線形表面を構築します。 トレーニングデータがクリーンであるほど、うまく機能します。
他の場合には、異常なポイントと「正常な」ポイントの比率を知る必要もあります-カットオフしきい値を決定するため。
データ内の異常の数が5%を超えており、主要なサンプルから非常によく分離できる場合は、標準の異常検索方法を使用できます。
この場合、 分離フォレスト方式は品質の点で最も安定しています。 分離フォレストはランダム化されたデータです。 より特徴的な指標はより深くなる可能性が高く、一方、異常な指標は最初の反復で残りのサンプルから分離します。
他のアルゴリズムは、データの仕様の下で「適合する」場合、より適切に機能します。
データに正規分布がある場合は、データを多次元正規分布で近似する楕円エンベロープ法が適しています。 ポイントが分布に属する可能性が低いほど、異常である確率が高くなります。
異なる点の相対位置がそれらの差をうまく反映するようにデータが提示される場合、メトリック手法が適切な選択のようです:例えば、 k最近傍、k次最近傍、ABOD(角度に基づく異常値検出)またはLOF(局所異常因子) )
これらすべての方法は、「正しい」指標が多次元空間の1つの領域に集中していることを示唆しています。 k(またはk番目)の最近傍のすべてがターゲットから遠い場合、ポイントは異常です。 ABODの場合、推論は似ています。k個すべての最も近いポイントが、考慮されたポイントと比較して同じスペースのセクターにある場合、そのポイントは異常です。 LOFの場合:ローカル密度(k個の最近傍によって各ポイントに対して事前に決定されている)がk個の最近傍の密度よりも低い場合、そのポイントは異常です。
データが適切にクラスター化されている場合、 クラスター分析に基づく方法が適切な選択です。 ポイントが複数のクラスターの中心から等距離にある場合、それは異常です。
最大の分散変化の方向がデータ内で明確に区別されている場合、 主成分法に基づいて異常を検索するのが適切な選択のようです。 この場合、n1(最も「主な」成分)およびn2(最も「主な」成分)の平均値からの偏差は、異常測定と見なされます。
たとえば、 The Prognostics and Health Management Society(PHM Society)のデータセットを参照することをお勧めします。 この非営利組織は毎年競争を手配します。 たとえば、2018年には、操作のエラーと、イオンビームエッチングプラントの故障までの時間を予測する必要がありました 。 2015年のデータセットを使用します。 これには、30のインストール用の複数のセンサーの読み取り値(トレーニングサンプル)が含まれており、いつどのエラーが発生するかを予測する必要があります。
ネットワーク上のテストサンプルで回答が見つかりませんでしたので、トレーニングサンプルでのみプレイします。
一般に、すべての設定は似ていますが、たとえば、コンポーネントの数、異常の数などが異なります。 したがって、最初の20で学習し、他の20でテストすることはあまり意味がありません。
そのため、インストールの1つを選択してロードし、このデータを確認します。 この記事は機能エンジニアリングに関するものではないため、あまり詳しくは説明しません。
import pandas as pd import matplotlib.pyplot as plt %matplotlib inline import seaborn as sns from sklearn.covariance import EllipticEnvelope from sklearn.neighbors import LocalOutlierFactor from sklearn.ensemble import IsolationForest from sklearn.svm import OneClassSVM dfa=pd.read_csv('plant_12a.csv',names=['Component number','Time','S1','S2','S3','S4','S1ref','S2ref','S3ref','S4ref']) dfa.head(10)
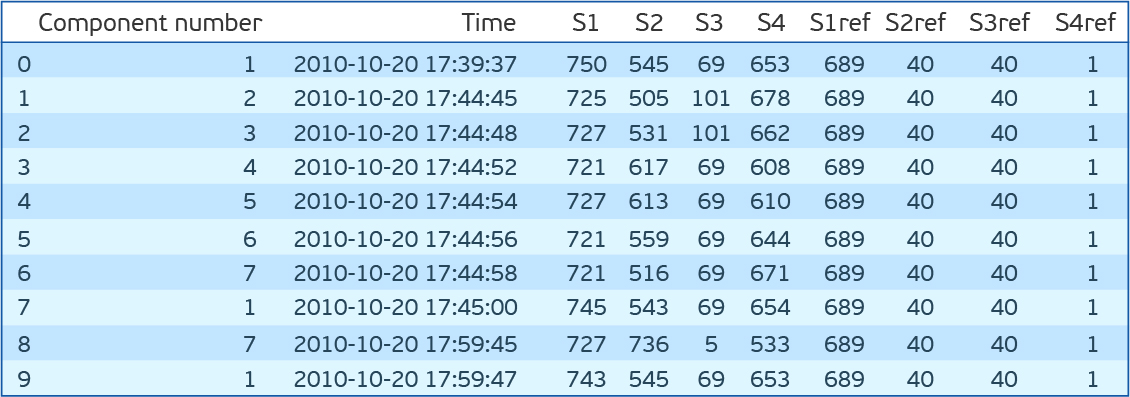
ご覧のとおり、15分ごとに取得される4つのセンサーの読み取り値がある7つのコンポーネントがあります。 競合の説明のS1ref-S4refは参照値としてリストされていますが、値はセンサーの読み取り値とは非常に異なります。 それらが何を意味するのかを考えて時間を無駄にしないために、それらを削除します。 各特性(S1-S4)の値の分布を見ると、分布はS1、S2、S4では連続的であり、S3では離散的であることがわかります。 さらに、S2とS4の共同分布を見ると、それらは反比例していることがわかります。
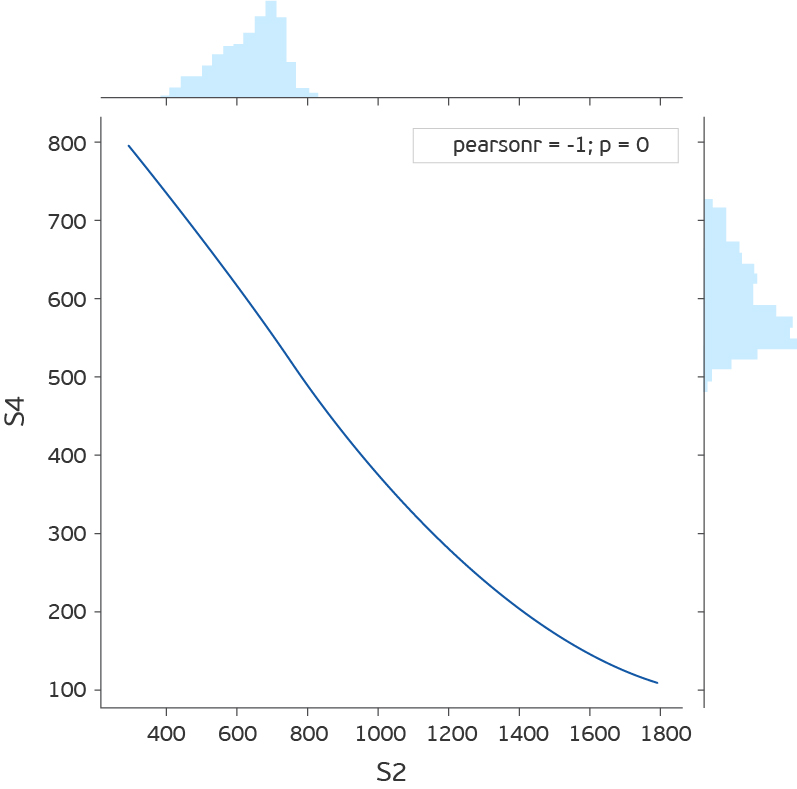
直接的な依存関係からの逸脱は間違いを示している可能性がありますが、これを確認するのではなく、単にS4を削除します。
もう一度、データセットを処理します。 S1、S2、およびS3のままにします。 StandardScalerを使用してS1とS2をスケーリングし(平均値を減算し、標準偏差で除算します)、S3をOHE(One Hot Encoding)に変換します。 すべてのインストールコンポーネントの測定値を1行で縫います。 合計89の機能。 2 * 7 = 14-7つのコンポーネントおよび75のR3の一意の値の読み取り値S1およびS2。 そのような行はわずか56千行です。
エラーのあるファイルをアップロードします。
dfc=pd.read_csv('plant_12c.csv',names=['Start Time', 'End Time','Type']) dfc.head()
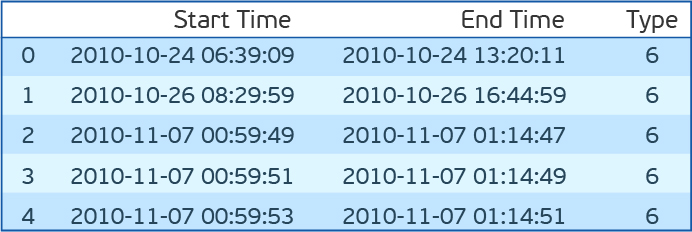
データセットでこれらのアルゴリズムを試す前に、もう少し余談をします。 テストする必要があります。 このため、エラーの開始時刻と終了時刻を取得することをお勧めします。 そして、この間隔内のすべての兆候は異常と見なされ、外部-正常と見なされます。 このアプローチには多くの欠点があります。 ただし、特に1つ-エラーが修正される前に異常な動作が発生する可能性が高いです。 忠実性のために、30分前に異常のウィンドウを時間的にシフトします。 F1の測定値、精度、再現率を評価します。
機能を選択し、モデルの品質を決定するためのコード:
def load_and_preprocess(plant_num): # , dfa=pd.read_csv('plant_{}a.csv'.format(plant_num),names=['Component number','Time','S1','S2','S3','S4','S1ref','S2ref','S3ref','S4ref']) dfc=pd.read_csv('plant_{}c.csv'.format(plant_num),names=['Start Time','End Time','Type']).drop(0,axis=0) N_comp=len(dfa['Component number'].unique()) # 15 dfa['Time']=pd.to_datetime(dfa['Time']).dt.round('15min') # 6 ( , ) dfc=dfc[dfc['Type']!=6] dfc['Start Time']=pd.to_datetime(dfc['Start Time']) dfc['End Time']=pd.to_datetime(dfc['End Time']) # , OHE 3- dfa=pd.concat([dfa.groupby('Time').nth(i)[['S1','S2','S3']].rename(columns={"S1":"S1_{}".format(i),"S2":"S2_{}".format(i),"S3":"S3_{}".format(i)}) for i in range(N_comp)],axis=1).dropna().reset_index() for k in range(N_comp): dfa=pd.concat([dfa.drop('S3_'+str(k),axis=1),pd.get_dummies(dfa['S3_'+str(k)],prefix='S3_'+str(k))],axis=1).reset_index(drop=True) # df_train,df_test=train_test_split(dfa,test_size=0.25,shuffle=False) cols_to_scale=df_train.filter(regex='S[1,2]').columns scaler=preprocessing.StandardScaler().fit(df_train[cols_to_scale]) df_train[cols_to_scale]=scaler.transform(df_train[cols_to_scale]) df_test[cols_to_scale]=scaler.transform(df_test[cols_to_scale]) return df_train,df_test,dfc # def get_true_labels(measure_times,dfc,shift_delta): idxSet=set() dfc['Start Time']-=pd.Timedelta(minutes=shift_delta) dfc['End Time']-=pd.Timedelta(minutes=shift_delta) for idx,mes_time in tqdm_notebook(enumerate(measure_times),total=measure_times.shape[0]): intersect=np.array(dfc['Start Time']<mes_time).astype(int)*np.array(dfc['End Time']>mes_time).astype(int) idxs=np.where(intersect)[0] if idxs.shape[0]: idxSet.add(idx) dfc['Start Time']+=pd.Timedelta(minutes=shift_delta) dfc['End Time']+=pd.Timedelta(minutes=shift_delta) true_labels=pd.Series(index=measure_times.index) true_labels.iloc[list(idxSet)]=1 true_labels.fillna(0,inplace=True) return true_labels # def check_model(model,df_train,df_test,filt='S[123]'): model.fit(df_train.drop('Time',axis=1).filter(regex=(filt))) y_preds = pd.Series(model.predict(df_test.drop(['Time','Label'],axis=1).filter(regex=(filt)))).map({-1:1,1:0}) print('F1 score: {:.3f}'.format(f1_score(df_test['Label'],y_preds))) print('Precision score: {:.3f}'.format(precision_score(df_test['Label'],y_preds))) print('Recall score: {:.3f}'.format(recall_score(df_test['Label'],y_preds))) score = model.decision_function(df_test.drop(['Time','Label'],axis=1).filter(regex=(filt))) sns.distplot(score[df_test['Label']==0]) sns.distplot(score[df_test['Label']==1]) df_train,df_test,anomaly_times=load_and_preprocess(12) df_test['Label']=get_true_labels(df_test['Time'],dfc,30)
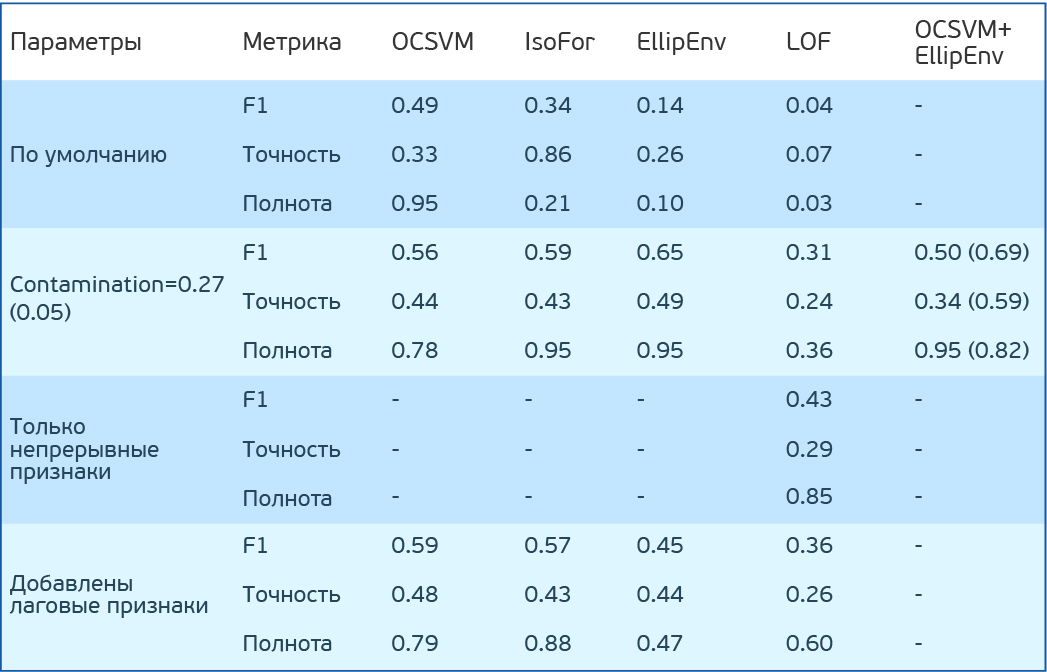
PHM 2015 Data Challengeデータセットでの単純な異常検索アルゴリズムのテスト結果
アルゴリズムに戻ります。 データに対してOne Class SVM(OCSVM)、IsolationForest(IF)、EllipticEnvelope(EE)、LocalOutlierFactor(LOF)を試してみましょう。 まず、パラメーターを設定しません。 LOFは2つのモードで動作することに注意してください。 novelty = Falseがトレーニングセットでのみ異常を検索できる場合(fit_predictのみがあります)、Trueの場合、トレーニングセット外の異常を検索することを目的としています(個別に適合および予測できます)。 IFには、新旧の動作モードがあります。 新品を使用しています。 彼はより良い結果を出します。
OCSVMは異常を適切に検出しますが、誤検出が多すぎます。 他の方法では、結果はさらに悪くなります。
しかし、データの異常の割合を知っていると仮定します。 私たちの場合、27%。 OCSVMにはnuがあります。エラーの割合の上限の推定値とサポートベクトルの割合の下限値です。 他の汚染方法には、データエラーの割合があります。 IFおよびLOFメソッドでは自動的に決定されますが、OCSVMおよびEEではデフォルトで0.1に設定されます。 汚染(nu)を0.27に設定してみましょう。 EEの最高の結果。
モデルをチェックするためのコード:
def check_model(model,df_train,df_test,filt='S[123]'): model_type,model = model model.fit(df_train.drop('Time',axis=1).filter(regex=(filt))) y_preds = pd.Series(model.predict(df_test.drop(['Time','Label'],axis=1).filter(regex=(filt)))).map({-1:1,1:0}) print('F1 score for {}: {:.3f}'.format(model_type,f1_score(df_test['Label'],y_preds))) print('Precision score for {}: {:.3f}'.format(model_type,precision_score(df_test['Label'],y_preds))) print('Recall score for {}: {:.3f}'.format(model_type,recall_score(df_test['Label'],y_preds))) score = model.decision_function(df_test.drop(['Time','Label'],axis=1).filter(regex=(filt))) sns.distplot(score[df_test['Label']==0]) sns.distplot(score[df_test['Label']==1]) plt.title('Decision score distribution for {}'.format(model_type)) plt.show()
さまざまな方法の異常インジケータの分布を見るのは興味深いです。 このデータではLOFがうまく機能しないことがわかります。 EEには、アルゴリズムが極端に異常であると見なすポイントがあります。 ただし、通常のポイントはそこに落ちます。 IsoForとOCSVMは、カットオフしきい値(汚染/ nu)の選択が重要であることを示しています。これにより、精度と完全性のトレードオフが変わります。

センサーの読み取り値が定常値に近い、正規分布に近いことは論理的です。 ラベルの付いたテストサンプルがあれば、できれば検証用のサンプルもあれば、汚染値に色を付けることができます。 次の質問は、どのエラーがより指向的であるかです:偽陽性または偽陰性?
LOFの結果は非常に低いです。 あまり印象的ではありません。 ただし、OHE変数は、StandardScalerによって変換された変数とともに入力に送られることに注意してください。 デフォルトの距離はユークリッドです。 ただし、S1およびS2に従って変数のみをカウントする場合、状況は修正され、結果は他の方法と比較できます。 ただし、リストされているメトリック分類子の重要なパラメーターの1つは、近隣の数であることを理解することが重要です。 品質に大きく影響するため、調整する必要があります。 距離メトリック自体も選択するとよいでしょう。
次に、2つのモデルを組み合わせてみます。 最初に、トレーニングセットから異常を削除します。 そして、「よりクリーンな」トレーニングセットでOCSVMをトレーニングします。 以前の結果によると、EEで最大の完全性が観察されました。 EEを通じてトレーニングサンプルをクリアし、OCSVMをトレーニングして、F1 = 0.50、精度= 0.34、完全性= 0.95を取得します。 印象的ではありません。 しかし、nu = 0.27を要求しました。 そして、私たちが持っているデータは多かれ少なかれ「クリーン」です。 トレーニングセットのEEの充足度が同じであると仮定すると、エラーの5%が残ります。 このようなnuを設定すると、F1 = 0.69、精度= 0.59、完全性= 0.82になります。 素晴らしい。 他の方法では、このような組み合わせは機能しないことに注意することが重要です。これらの組み合わせは、トレーニングセットの異常数とテスト数が同じであることを意味するためです。 純粋なトレーニングデータセットでこれらの方法をトレーニングする場合、実際のデータよりも少ない汚染を指定し、ゼロに近い値を指定する必要はありませんが、交差検証用に選択することをお勧めします。
指示のシーケンスで検索結果を見るのは興味深いです:

この図は、7つのコンポーネントの第1および第2センサーの読み取り値のセグメントを示しています。 凡例では、対応するエラーの色(開始と終了は同じ色の縦線で表示されます)。 ドットは予測を示します。緑-真の予測、赤-偽陽性、紫-偽陰性。 図から、エラー時間を視覚的に判断することは困難であり、アルゴリズムはこのタスクに非常によく対応していることがわかります。 ここでは、3番目のセンサーの測定値が示されていないことを理解することが重要です。 さらに、エラーの終了後に誤検知の読み取り値があります。 つまり アルゴリズムは誤った値もあると判断し、この領域にエラーがないとマークしました。 図の右側はエラーの前の領域を示しています。エラーのない領域(エラーの30分前)をマークすると、エラーなしと認識され、モデルのエラーがネガティブになります。 図の中央では、一貫性のあるピースが認識され、エラーとして認識されます。 結論は次のように描くことができます:異常の検索の問題を解決するとき、マークアップで使用されるアルゴリズムをチェックしても現実を完全に反映せず、そのようなアルゴリズムが可能な条件をシミュレートしないため、出力を予測する必要があるシステムの本質を理解するエンジニアと密接にやり取りする必要があります使用されます。
チャートをプロットするためのコード:
def plot_time_course(df_test,dfc,y_preds,start,end,vert_shift=4): plt.figure(figsize=(15,10)) cols=df_train.filter(regex=('S[12]')).columns add=0 preds_idx=y_preds.iloc[start:end][y_preds[0]==1].index true_idx=df_test.iloc[start:end,:][df_test['Label']==1].index tp_idx=set(true_idx.values).intersection(set(preds_idx.values)) fn_idx=set(true_idx.values).difference(set(preds_idx.values)) fp_idx=set(preds_idx.values).difference(set(true_idx.values)) xtime=df_test['Time'].iloc[start:end] for col in cols: plt.plot(xtime,df_test[col].iloc[start:end]+add) plt.scatter(xtime.loc[tp_idx].values,df_test.loc[tp_idx,col]+add,color='green') plt.scatter(xtime.loc[fn_idx].values,df_test.loc[fn_idx,col]+add,color='violet') plt.scatter(xtime.loc[fp_idx].values,df_test.loc[fp_idx,col]+add,color='red') add+=vert_shift failures=dfc[(dfc['Start Time']>xtime.iloc[0])&(dfc['Start Time']<xtime.iloc[-1])] unique_fails=np.sort(failures['Type'].unique()) colors=np.array([np.random.rand(3) for fail in unique_fails]) for fail_idx in failures.index: c=colors[np.where(unique_fails==failures.loc[fail_idx,'Type'])[0]][0] plt.axvline(failures.loc[fail_idx,'Start Time'],color=c) plt.axvline(failures.loc[fail_idx,'End Time'],color=c) leg=plt.legend(unique_fails) for i in range(len(unique_fails)): leg.legendHandles[i].set_color(colors[i])
異常の割合が5%未満である場合、および/または「正常な」インジケータからの分離が不十分な場合、上記の方法はうまく機能せず、ニューラルネットワークに基づくアルゴリズムを使用する価値があります。 最も単純な場合、これらは次のようになります。
- 自動エンコーダー(訓練された自動エンコーダーの高いエラーは、異常な読み取り値を通知します);
- 再帰ネットワーク(最後の読み取りを予測するためのシーケンスによる学習。差が大きい場合-ポイントは異常です)。
それとは別に、時系列での作業の詳細に注目する価値があります。 上記のアルゴリズムのほとんど(自動エンコーダーとフォレストの分離を除く)は、ラグ機能(以前の時点からの読み取り値)を追加すると品質が低下する可能性が高いことを理解することが重要です。
この例で遅延機能を追加してみましょう。 競合他社の説明では、エラーの3時間前の値はエラーとはまったく関係がないとされています。 その後、3時間で標識を追加します。 合計259サイン。
その結果、OCSVMとIsolationForestの結果はほとんど変化しませんでしたが、楕円エンベロープとLOFの結果は低下しました。
システムのダイナミクスに関する情報を使用するには、リカレントまたは畳み込みニューラルネットワークで自動エンコーダーを使用する必要があります。 または、たとえば、自動エンコーダ、情報の圧縮、および圧縮された情報に基づいて異常を検索する従来のアプローチの組み合わせ。 逆のアプローチも有望なようです。 標準的なアルゴリズムによる最も特徴のないポイントの一次スクリーニングと、よりクリーンなデータですでに自動エンコーダーをトレーニングします。

出所
1次元の時系列を操作するための一連のテクニックがあります。 それらはすべて、将来の測定値を予測することを目的としており、予測と異なる点は異常と見なされます。
Holt-Wintersモデル
トリプル指数平滑法は、シリーズをレベル、トレンド、季節性の3つのコンポーネントに分割します。 したがって、シリーズがこの形式で表示される場合、この方法はうまく機能します。 Facebook Prophetは同様の原理で動作しますが、コンポーネント自体を異なる方法で評価します。 詳細については、たとえばこちらをご覧ください 。
S(ARIMA)
この方法では、予測モデルは自己回帰と移動平均に基づいています。 S(ARIMA)の拡張について話している場合、季節性を評価できます。 アプローチの詳細については、 こちら 、 こちら 、 こちらをご覧ください 。
その他の予測サービスアプローチ
時系列に関して、エラーの発生時刻に関する情報がある場合、教師に教育方法を適用できます。 タグ付きデータの必要性に加えて、この場合、エラー予測はエラーの性質に依存することを理解することが重要です。 多くのエラーがあり、性質が異なる場合、それぞれを個別に予測する必要があり、さらに多くのラベル付きデータが必要になりますが、見通しはより魅力的です。
予測メンテナンスで機械学習を使用する別の方法があります。 たとえば、今後N日間のシステム障害の予測(分類タスク)。 このようなアプローチでは、システム動作のエラーの前に劣化期間が必要である(必ずしも緩やかではない)ことを理解することが重要です。 この場合、最も成功したアプローチは、畳み込み層および/または再帰層を持つニューラルネットワークの使用であると思われます。 それとは別に、時系列を増強する方法に注目する価値があります。 私にとって、 2つのアプローチが最も興味深いと同時にシンプルに思えます。
- 行の連続部分が選択され(たとえば、70%で残りは削除されます)、元のサイズに引き伸ばされます。
- 行の連続部分(20%など)が選択され、伸縮されます。 その後、行全体がそれに応じて元のサイズに圧縮または拡大されます。
システムの残りの寿命を予測するオプションもあります(回帰タスク)。 ここで、別のアプローチを区別できます。予測は寿命ではなく、ワイブル分布パラメーターです。
ディストリビューション自体についてはこちら 、およびリカレントメッシュと組み合わせて使用する方法についてはこちらをご覧ください 。 この分布には2つのパラメーターαとβがあります。 αはイベントがいつ発生するかを示し、βはアルゴリズムの信頼度を示します。 このアプローチの適用は有望ですが、この場合、適切な寿命を予測するよりもアルゴリズムが最初は安全でない方が簡単であるため、ニューラルネットワークをトレーニングすることは困難です。
それとは別に、 Cox回帰に注目する価値があります。 診断後の各時点でシステムのフォールトトレランスを予測し、2つの機能の積として提示することができます。 1つの機能は、パラメーターに依存しないシステムの劣化です。 そのようなシステムに共通。 2番目は、特定のシステムのパラメーターへの指数関数的な依存です。 だから、人にとっては、老化に関連する共通の機能があり、だれでもほぼ同じです。 しかし、健康の悪化は内臓の状態にも関連しており、それは誰にとっても異なっています。
予知保全についてもう少し知っていただければ幸いです。 この技術で最もよく使用される機械学習方法について質問があると思います。 私はコメントでそれらのそれぞれに喜んで答えます。 書かれていることについて質問するだけでなく、似たようなことをしたい場合、 CleverDATAチームは常に才能のある熱心な専門家に喜んでいます。
欠員はありますか? もちろん!