
「 すべてのものは、宇宙の一部であるパターンを隠しています。 対称性、優雅さ、美しさを備えています。まず、世界をとらえた真の芸術家がその品質を把握します。 このパターンは、季節の変化、砂が斜面に沿って流れる方法、クレオソート低木のもつれた枝、その葉のパターンに捉えることができます。
私たちはこのパターンを私たちの生活と社会にコピーしようとしているので、リズム、歌、ダンス、私たちを幸せにし、私たちを慰めるさまざまな形が大好きです。 ただし、完全なパターンが変更されていないことは明らかであるため、絶対的な完全性の検索に潜む危険を識別することもできます。 そして、完璧に近づいて、すべてのものが死に行く」- デューン (1965)
埋め込みの概念は、機械学習の最も注目すべきアイデアの1つだと思います。 Siri、Google Assistant、Alexa、Google Translate、または次の単語の予測にスマートフォンのキーボードを使用したことがある場合は、添付ファイルベースの自然言語処理モデルをすでに使用しています。 過去数十年にわたって、この概念はニューラルモデル用に大幅に開発されました(最近の開発には、 BERTやGPT2などの高度なモデルへのコンテキストに応じた単語の埋め込みが含まれます)。
Word2vecは、2013年に開発された効果的な投資作成方法です。 言葉での作業に加えて、彼の概念のいくつかは、推奨メカニズムを開発し、商業的な非言語タスクでもデータに意味を与えるのに効果的でした。 このテクノロジーは、 Airbnb 、 Alibaba 、 Spotify、 Anghamiなどの企業が推奨エンジンで使用しています。
この記事では、word2vecを使用して添付ファイルを生成する概念とメカニズムについて説明します。 オブジェクトをベクトル形式で表現する方法を理解するための例から始めましょう。 5つの数字(ベクトル)のリストがあなたの性格についてどれだけ言えるか知っていますか?
パーソナライズ:あなたは何ですか?
「砂漠のカメレオンを差し上げます。 砂と融合する彼の能力は、生態学のルーツとあなたの人格を維持する理由について知る必要があるすべてを教えてくれます。 - 砂丘の子供たち
0から100までのスケールで、あなたは内向型または外向型の人格を持っていますか(0は最も内向型で、100は最も外向型です)。 性格テストに合格したことがありますか。たとえば、MBTI、またはそれ以上、ビッグファイブですか? 質問のリストが表示され、内向/外向を含むいくつかの軸で評価されます。

Big Fiveテスト結果の例。 彼は性格について本当に多くを語り、 学問的 、 個人的および職業的成功を予測することができます。 たとえば、 ここで確認できます。
内向性/外向性の評価で100のうち38を獲得したとします。 これは次のように表すことができます。
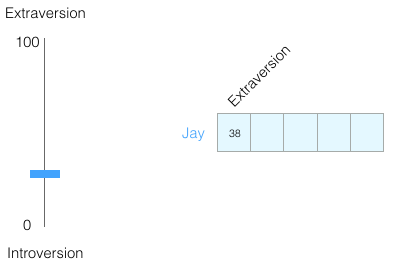
または、-1から+1のスケールで:

この評価だけで人をどれだけ認識できますか? そうでもない。 人間は複雑な生き物です。 したがって、もう1つのディメンション、つまりテストからのもう1つの特性を追加します。
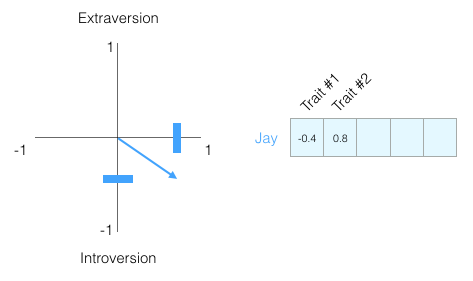
これらの2つの次元は、グラフ上の点、またはさらに良いことに、原点からこの点までのベクトルとして想像できます。 すぐに役立つ便利なベクターツールがあります。
特定の特性に執着することのないように、どの性格特性をチャートに載せるかは示しませんが、人の性格全体のベクトル表現をすぐに理解します。
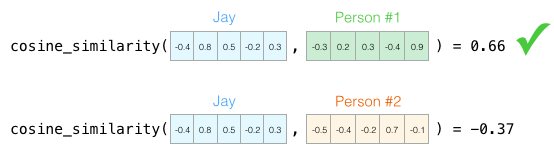
今、このベクトルは私の性格を部分的に反映していると言えます。 これは、異なる人々を比較するときに役立つ説明です。 私が赤いバスに襲われ、あなたを私と同じような人と交換する必要があるとします。 次の表の2人のうち、どちらが私に似ているでしょうか?

ベクトルを使用する場合、類似度は通常、Otiai係数 (幾何係数)によって計算されます。

人1番は 性格上私に似ています。 一方向のベクトル(長さも重要)は、より大きなOtiai係数を与えます
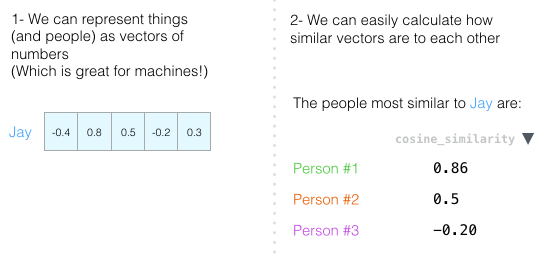
繰り返しますが、人を評価するには2つの次元では不十分です。 心理学の数十年にわたる発展により、5つの基本的な人格特性(さらに多くの特性)のテストが作成されました。 したがって、5つのディメンションすべてを使用しましょう。

5次元の問題は、2Dで適切な矢印を描画できなくなることです。 これは、多次元空間で作業しなければならないことが多い機械学習の一般的な問題です。 幾何係数が任意の数の測定値で機能するのは良いことです。
幾何係数は、任意の数の測定に対して機能します。 5次元では、結果ははるかに正確です。
この章の最後で、2つの主なアイデアを繰り返します。
- 人(および他のオブジェクト)は数値ベクトルとして表すことができます(自動車に最適です!)。
- ベクトルがどれだけ似ているかを簡単に計算できます。
単語の埋め込み
「言葉の賜物は、欺ceptionと幻想の賜物です。」 - 砂丘の子供たち
この理解に基づいて、トレーニングの結果として得られる単語のベクトル表現(添付ファイルとも呼ばれます)に進み、それらの興味深い特性を見ていきます。
「キング」という言葉の添付ファイルを次に示します(GloVeベクトル、Wikipediaでトレーニング済み):
[ 0.50451 , 0.68607 , -0.59517 , -0.022801, 0.60046 , -0.13498 , -0.08813 , 0.47377 , -0.61798 , -0.31012 , -0.076666, 1.493 , -0.034189, -0.98173 , 0.68229 , 0.81722 , -0.51874 , -0.31503 , -0.55809 , 0.66421 , 0.1961 , -0.13495 , -0.11476 , -0.30344 , 0.41177 , -2.223 , -1.0756 , -1.0783 , -0.34354 , 0.33505 , 1.9927 , -0.04234 , -0.64319 , 0.71125 , 0.49159 , 0.16754 , 0.34344 , -0.25663 , -0.8523 , 0.1661 , 0.40102 , 1.1685 , -1.0137 , -0.21585 , -0.15155 , 0.78321 , -0.91241 , -1.6106 , -0.64426 , -0.51042 ]
50個の数字のリストが表示されますが、何か言うのは難しいです。 他のベクトルと比較するためにそれらを視覚化しましょう。 数字を1行に入力します。

値でセルを色付けします(2に近い赤、0に近い白、-2に近い青):

数字を忘れて、色だけで「王」と他の言葉を対比します。

「男」と「女」は「王」よりもはるかに近いことがわかりますか? それは何かを言います。 ベクトル表現は、これらの単語の多くの情報/意味/関連付けをキャプチャします。
次に、別の例のリストを示します(同様の色の列を比較します)。

注意すべき点がいくつかあります。
- すべての単語を通して、1つの赤い列が表示されます。 つまり、これらの単語はこの特定の次元で似ています(そして、その中に何がエンコードされているかわかりません)。
- 「女性」と「少女」は非常に似ていることがわかります。 「男」と「少年」についても同じことが言えます。
- 「少年」と「少女」もいくつかの次元で似ていますが、「女性」と「男性」とは異なります。 これは、若者のコード化された漠然としたアイデアでしょうか? おそらく。
- 最後の言葉以外はすべて人々のアイデアです。 カテゴリ間の違いを示すオブジェクト(水)を追加しました。 たとえば、青い列が「水」ベクトルの前でどのように下降して停止するかを確認できます。
- 「王」と「女王」が互いに似ており、他のすべてとは異なる明確な次元があります。 漠然としたロイヤリティの概念がそこにコーディングされているのでしょうか?
類推
「言葉は私たちが望むどんな重荷にも耐えます。 必要なのは、コンセプトを構築するための伝統に関する合意です。」 - 砂丘の神
投資の驚くべき特性を示す有名な例は、類推の概念です。 単語ベクトルを加算および減算して、興味深い結果を得ることができます。 最も有名な例は、「王-男+女」という式です。
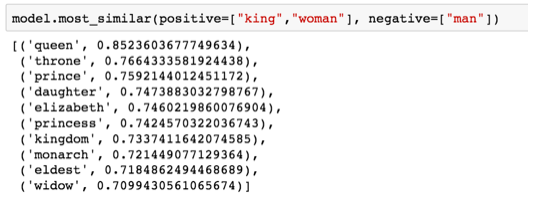
PythonのGensimライブラリを使用して、単語ベクトルを追加および削除できます。ライブラリは、結果のベクトルに最も近い単語を検索します。 画像には、最も類似した単語のリストが表示され、それぞれに幾何学的類似性の係数があります
この類推を以前と同様に視覚化します。

「王-男+女」の計算から得られるベクトルは「女王」と正確には等しくありませんが、これはデータセット内の400,000ワードの添付ファイルから最も近い結果です
言葉の添付を検討した後、学習がどのように行われるかを学びましょう。 しかし、word2vecに進む前に、単語埋め込みの概念上の祖先であるニューラル言語モデルを調べる必要があります。
言語モデル
「預言者は過去、現在、未来の幻想の影響を受けません。 そのような線形の違いは、言語形式の固定性によって決まります。 預言者たちは舌の鍵の鍵を握っています。 彼らにとって、物理的イメージは物理的イメージのみであり、それ以上のものではありません。
彼らの宇宙は、機械的な宇宙の特性を持っていません。 イベントの線形シーケンスは、オブザーバーによって想定されます。 原因と結果は? これはまったく別の問題です。 預言者は運命的な言葉を発します。 「物事の論理に従って」発生するはずのイベントを垣間見ることができます。 しかし、預言者は即座に無限の奇跡的な力のエネルギーを放出します。 宇宙は精神的な変化を受けています。」 - 砂丘の神
NLP(自然言語処理)の1つの例は、スマートフォンのキーボード上の次の単語の予測機能です。 何十億人もの人々が1日に数百回それを使用しています。
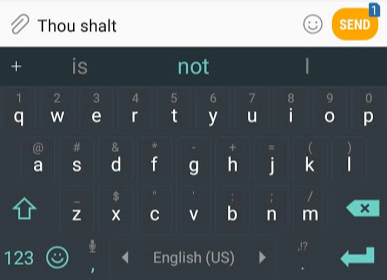
次の単語を予測することは、言語モデルに適したタスクです。 彼女は単語のリスト(たとえば、2つの単語)を取得して、次のことを予測しようとします。
上記のスクリーンショットでは、モデルはこれらの2つの緑の単語(
thou shalt
)を取り、オプションのリストを返しました(単語
not
最も可能性が高い)。

モデルはブラックボックスとして想像できます。

しかし実際には、モデルは複数の単語を生成します。 事実上すべての既知の単語の確率の推定値を提供します(モデルの「辞書」は数千から100万以上の単語まで変化します)。 キーボードアプリケーションは、スコアが最も高い単語を見つけてユーザーに表示します。
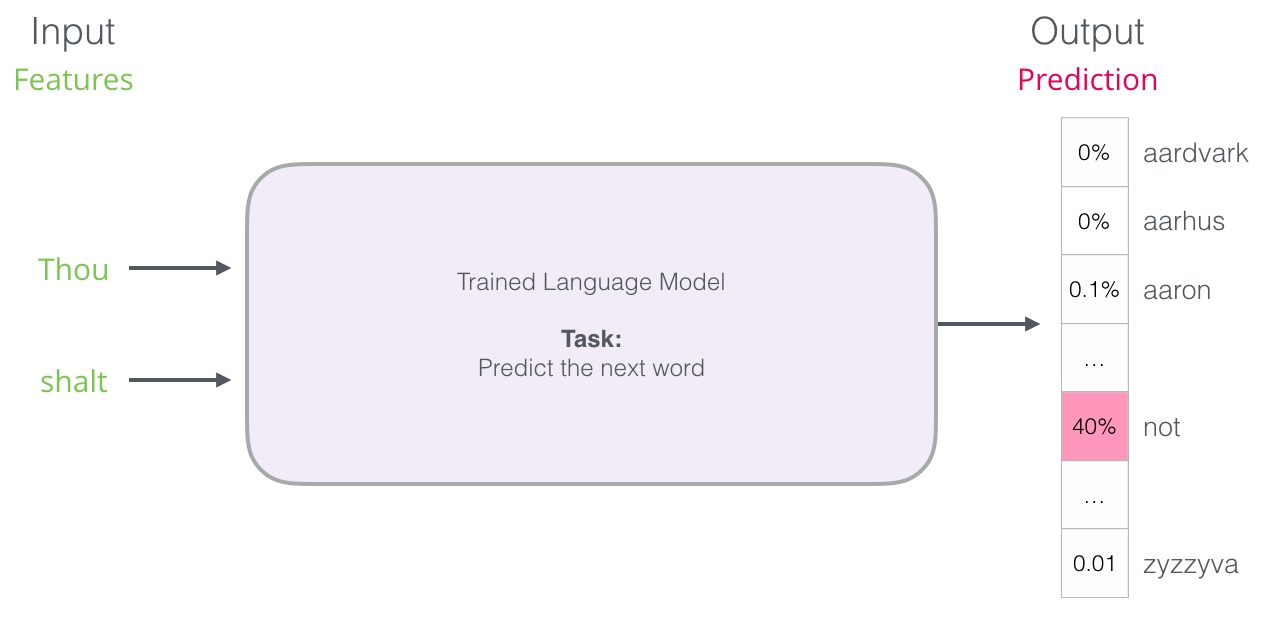
ニューラル言語モデルは、すべての既知の単語の確率を提供します。 確率をパーセンテージで示しますが、結果のベクトルでは40%が0.4として表されます
トレーニング後、最初のニューラルモデル( Bengio 2003 )は3段階で予後を計算しました。
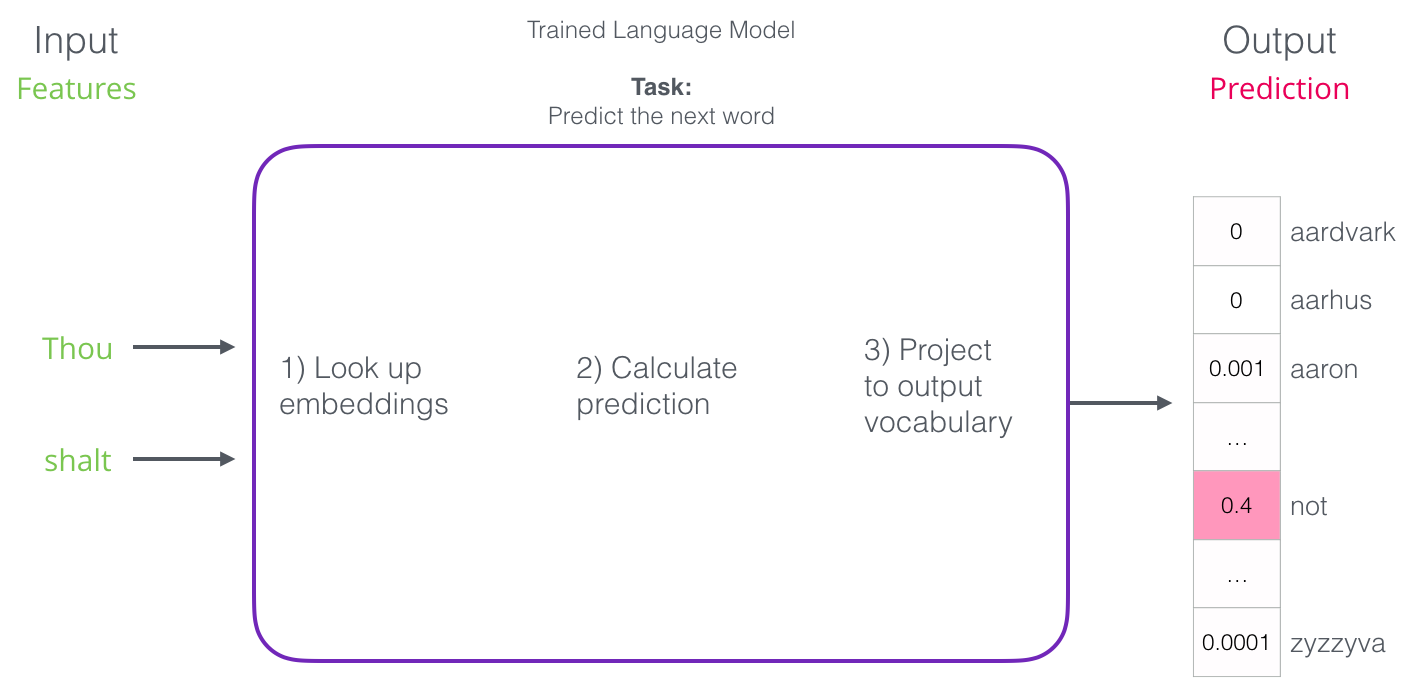
最初のステップは、投資について議論する際に最も関連性があります。 トレーニングの結果、辞書内のすべての単語の添付ファイルでマトリックスが作成されます。 結果を得るには、入力語の埋め込みを探して予測を開始します。
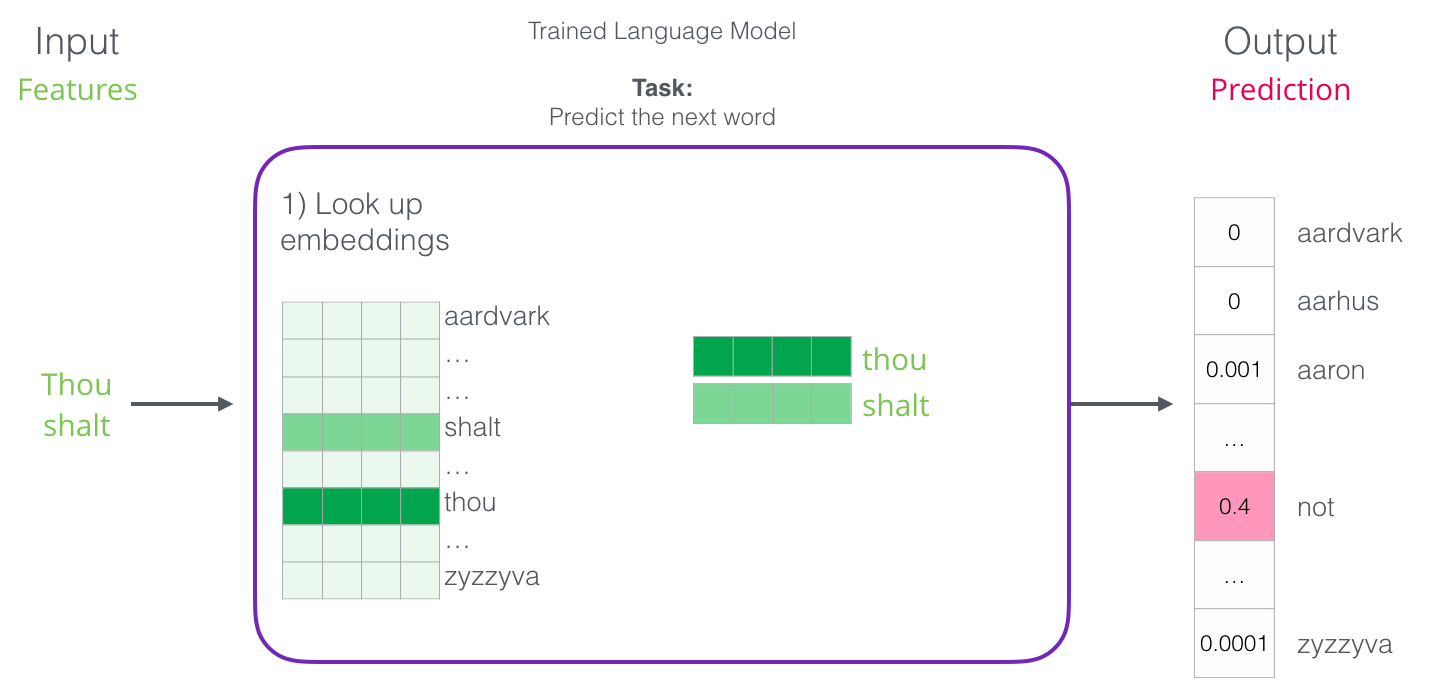
それでは、学習プロセスを見て、この投資のマトリックスがどのように作成されるかを見てみましょう。
言語モデルのトレーニング
「プロセスを停止することで理解することはできません。 理解はプロセスと一緒に動き、その流れと融合し、それと共に流れなければなりません。
言語モデルには、他のほとんどの機械学習モデルに比べて大きな利点があります。豊富なテキストでトレーニングできます。 私たちが持っているすべての本、記事、ウィキペディアの資料、およびその他の形式のテキストデータを考えてください。 手作業と特別に収集されたデータを必要とする他の機械学習モデルと比較してください。
「彼の会社で言葉を学ばなければならない」-J. R.ファーズ
単語の添付ファイルは、周囲の単語によって計算されます。周囲の単語は、多くの場合近くに表示されます。 仕組みは次のとおりです。
- 多くのテキストデータを取得します(たとえば、すべてのウィキペディアの記事)
- テキスト全体にスライドするウィンドウ(たとえば、3つの単語)を設定します。
- スライディングウィンドウは、モデルをトレーニングするためのパターンを生成します。
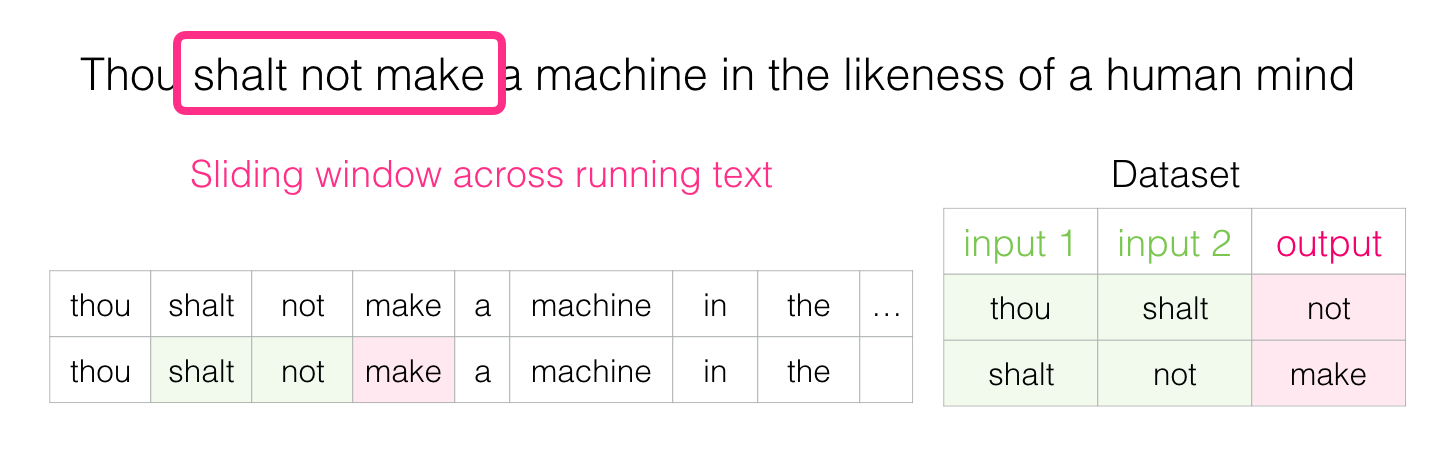
このウィンドウがテキスト上を滑ると、実際にデータセットを生成し、それを使用してモデルをトレーニングします。 理解のために、スライディングウィンドウがこのフレーズをどのように処理するかを見てみましょう。
「人間の心の肖像に恵まれた機械を構築しないように」- デューン
開始すると、ウィンドウは文の最初の3つの単語にあります。

最初の2つの単語を標識に、3番目の単語をラベルに使用します。

後で言語モデルを教えるために使用できるデータセットの最初のサンプルを生成しました
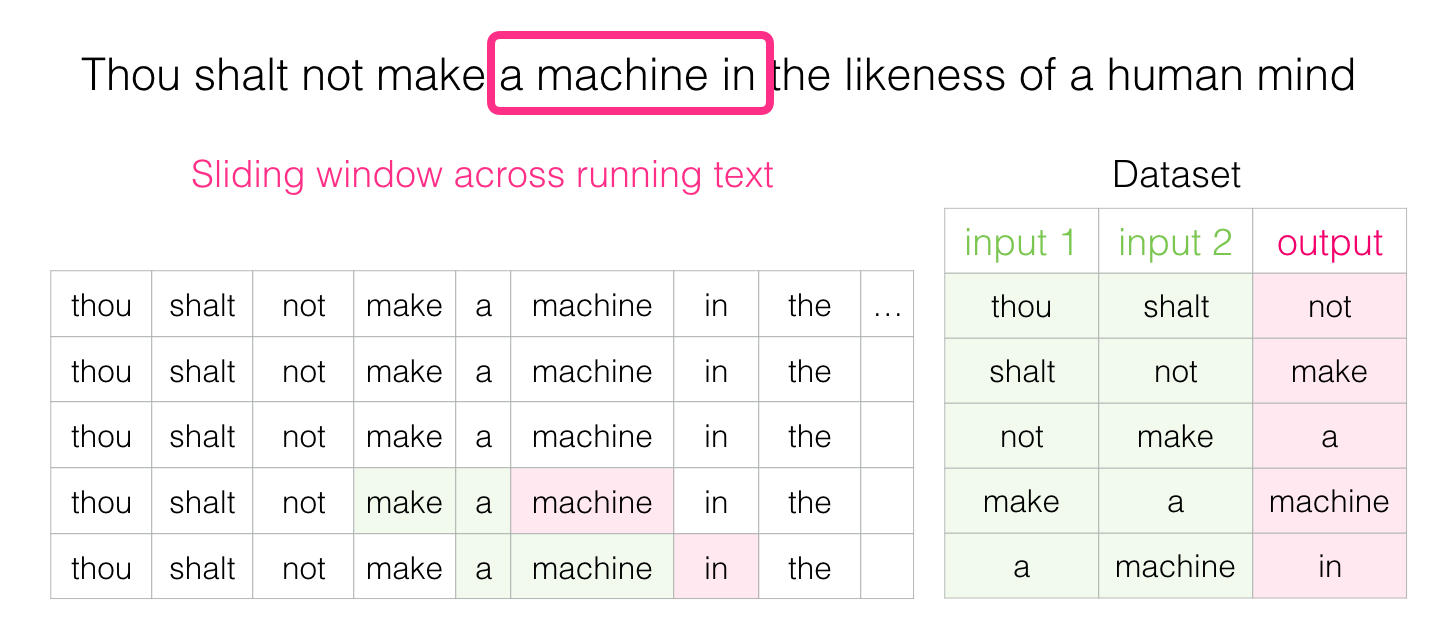
次に、ウィンドウを次の位置に移動して、2番目のサンプルを作成します。
そしてすぐに、より大きなデータセットを蓄積します:
実際には、モデルは通常、スライディングウィンドウを移動するプロセスで直接訓練されます。 ただし、論理的には、「データセットの生成」フェーズはトレーニングフェーズとは別です。 ニューラルネットワークのアプローチに加えて、N-gramメソッドは、以前は言語モデルの指導によく使用されていました( 「音声と言語処理」の本の第3章を参照)。 実際の製品でN-gramからニューラルモデルに切り替えるときの違いを見るために、 ここに私のお気に入りのAndroidキーボードの開発者であるSwiftkeyによる2015年のブログ投稿があります。彼は彼のニューラル言語モデルを提示し、以前のN-gramモデルと比較します。 この例は、投資のアルゴリズム特性をマーケティング言語でどのように説明できるかを示しているため、気に入っています。
私たちは両方の見方をしています
「パラドックスは、その背後にあるものを検討しようとする兆候です。 パラドックスがあなたに懸念を与えているなら、それはあなたが絶対を求めて努力していることを意味します。 相対主義者はパラドックスを単に面白くて、おもしろくて、時には恐ろしい考えであるが、非常に有益な考えだと考えている。 皇帝の砂丘
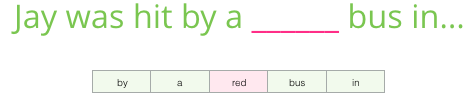
上記に基づいて、ギャップを埋めます。

コンテキストとして、5つの前の単語(および「バス」への以前の参照)があります。 ほとんどの人が「バス」があるはずだと推測していると思います。 しかし、スペースの後に私があなたに別の言葉を与えるならば、これはあなたの答えを変えますか?

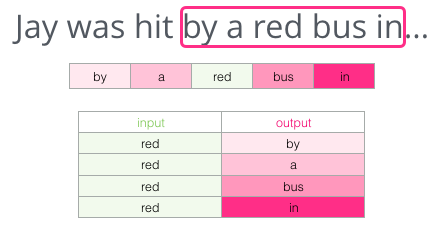
これにより状況が完全に変わります。現在、欠落している単語は「赤」である可能性が高いです。 明らかに、単語はスペースの前後に情報価値があります。 両方向(左と右)のアカウンティングにより、より良い投資を計算できることがわかります。 このような状況でモデルトレーニングを構成する方法を見てみましょう。
グラムをスキップ
「間違いなく間違いのない選択が不明な場合、知性はアリーナ内の限られたデータで作業する機会を得ます。そこではエラーが発生するだけでなく必要になります。」 -Capitul Dunes
ターゲットの前の2つの単語に加えて、そのあとの2つの単語を考慮することができます。
モデルトレーニングのデータセットは次のようになります。

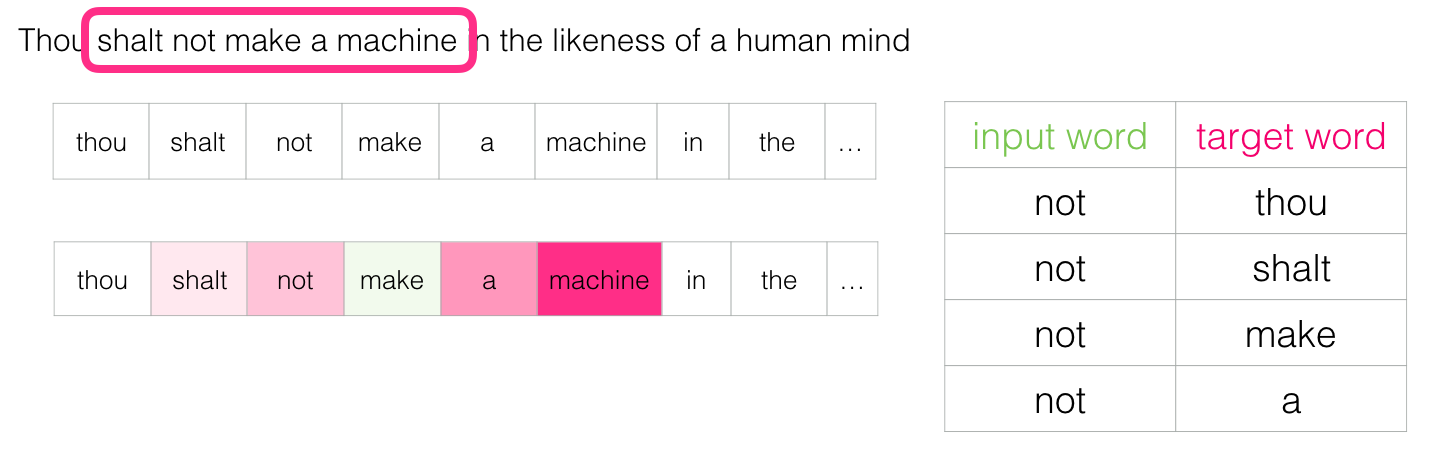
これはCBOW(Continuous Bag of Words)アーキテクチャと呼ばれ、word2vec [pdf] ドキュメントの1つで説明されています 。 優れた結果を示す別のアーキテクチャもありますが、配置が少し異なります。現在の単語で隣接する単語を推測しようとします。 スライディングウィンドウは次のようになります。

緑色のスロットは入力語で、ピンク色の各フィールドは可能な出口を表します
このスライディングウィンドウは、実際にトレーニングデータセットに4つの異なるパターンを作成するため、ピンクの長方形の色合いは異なります。
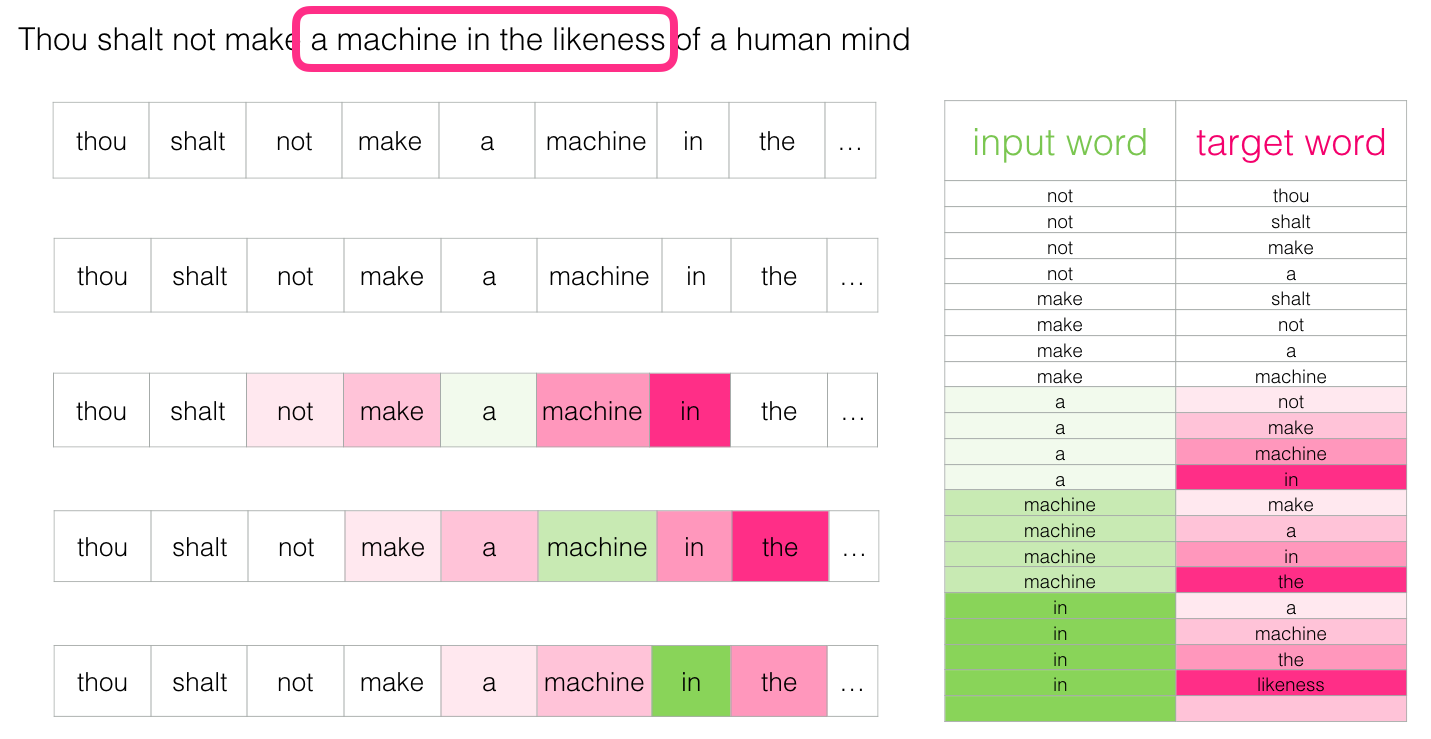
この方法は、 スキップグラムアーキテクチャと呼ばれます。 次のようにスライディングウィンドウを視覚化できます。

次の4つのサンプルがトレーニングデータセットに追加されます。

次に、ウィンドウを次の位置に移動します。
さらに4つの例を生成します。

すぐにもっと多くのサンプルがあります:
学習レビュー
「ムアディブは、主に学習方法を教えられていたため、早い学習者でした。 しかし、最初の教訓は、彼が学ぶことができるという信念の同化であり、これがすべての基礎です。 学ぶことや学ぶことができると信じていない人がどれだけいるのか、そして学習が非常に難しいと考える人がどれだけいるのかは驚くべきことです。」 - 砂丘
スキップグラムのセットができたので、それを使用して、隣接する単語を予測する言語の基本的なニューラルモデルをトレーニングします。
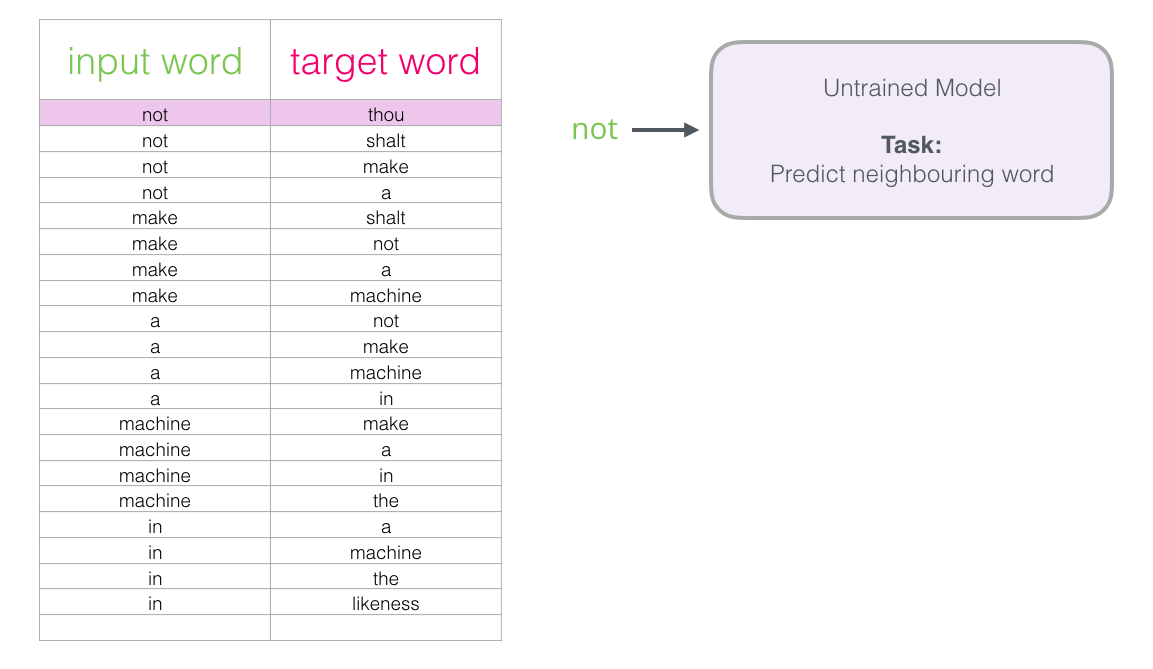
データセットの最初のサンプルから始めましょう。 サインを取得し、次の単語を予測するためのリクエストとともに、トレーニングされていないモデルに送信します。

モデルは3つのステップを経て、予測ベクトル(ディクショナリ内の各単語の確率)を表示します。 モデルはトレーニングされていないため、この段階ではおそらく予測は正しくありません。 しかし、それは何もありません。 彼女が予測する単語はわかっています。これは、モデルのトレーニングに現在使用している行の結果のセルです。

「ターゲットベクトル」は、ターゲットワードの確率が1で、他のすべてのワードの確率が0であるものです。
モデルはどの程度間違っていましたか? ターゲットから予測ベクトルを減算し、エラーベクトルを取得します。

これで、このエラーベクトルを使用してモデルを更新できるため、次回は同じ入力データで正確な結果が得られる可能性が高くなります。
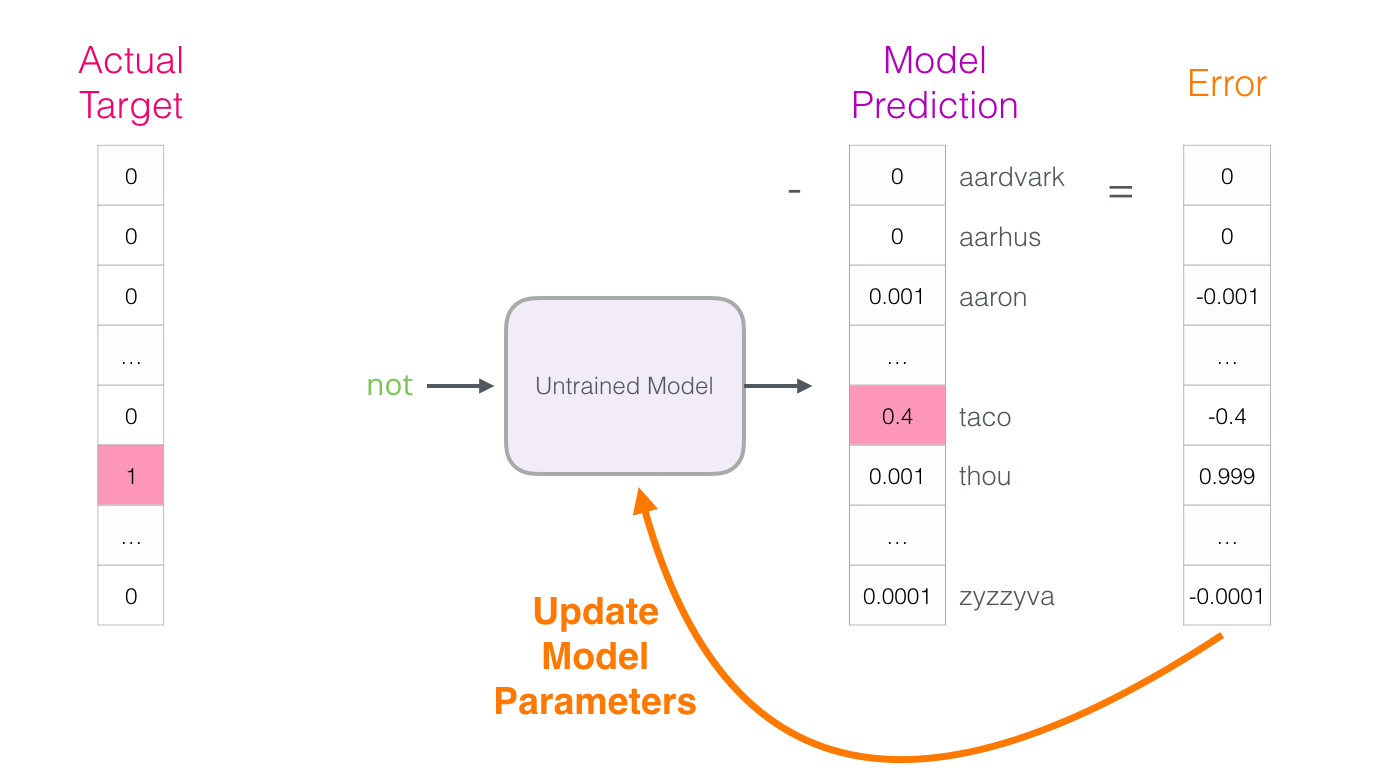
これで、トレーニングの最初の段階が終了します。 データセットの次のサンプルで同じことを続け、すべてのサンプルを調べるまで次のサンプルで続けます。 これは、学習の最初の時代の終わりです。 私たちはいくつかの時代に何度も何度も繰り返します。その結果、訓練されたモデルが得られます。そこから投資マトリックスを抽出し、あらゆるアプリケーションで使用できます。
多くのことを学びましたが、word2vecが実際に学習する方法を完全に理解するために、いくつかの重要なアイデアが欠落しています。
負の選択
「人間の敵であるハルコンノフを理解せずにムアディブを理解しようとすることは、偽りとは何かを理解せずに真実を理解しようとすることと同じです。 これは暗闇を知らずに光を知る試みです。 これは不可能です。」 - 砂丘
ニューラルモデルが予測を計算する3つの手順を思い出してください。
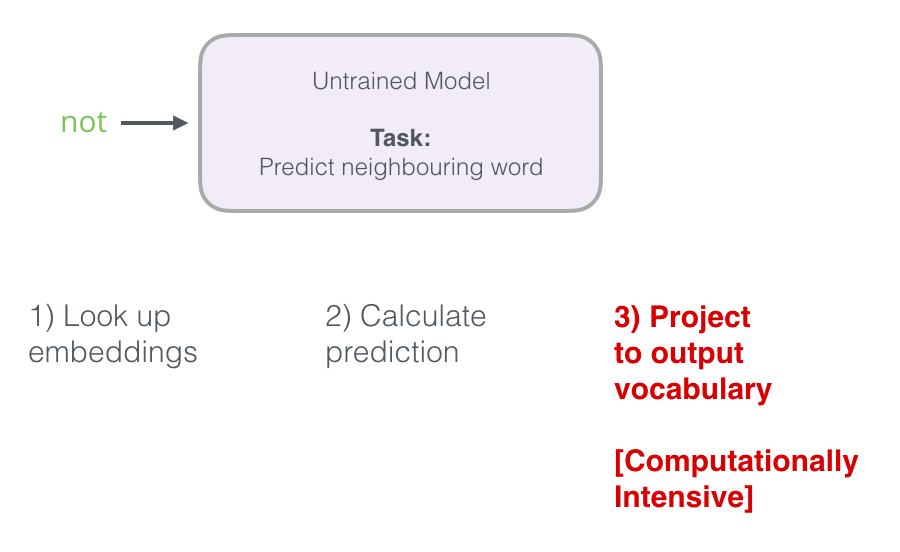
3番目のステップは、計算の観点から非常に高価です。特にデータセット内の各サンプルに対して行う場合(数千万回)。 生産性を何らかの形で高める必要があります。
1つの方法は、目標を2つの段階に分けることです。
- (次の単語を予測せずに)高品質の単語の添付ファイルを作成します。
- これらの高品質の投資を使用して、言語モデルを指導します(予測のため)。
この記事では、最初のステップに焦点を当てます。 生産性を高めるために、隣の単語を予測することから離れることができます...
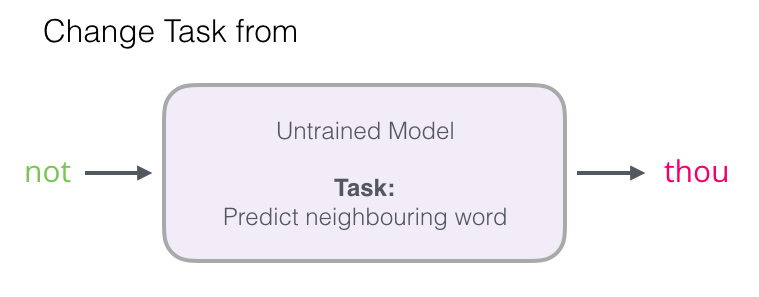
...そして、入力と出力の単語を取り、それらの近接の確率を計算するモデルに切り替えます(0から1)。

このような単純な遷移により、ニューラルネットワークがロジスティック回帰モデルに置き換えられます。したがって、計算ははるかに単純かつ高速になります。
同時に、データセットの構造を改良する必要があります。ラベルは値0または1の新しい列になりました。テーブルでは、近隣が追加されているため、ユニットはどこにでもあります。
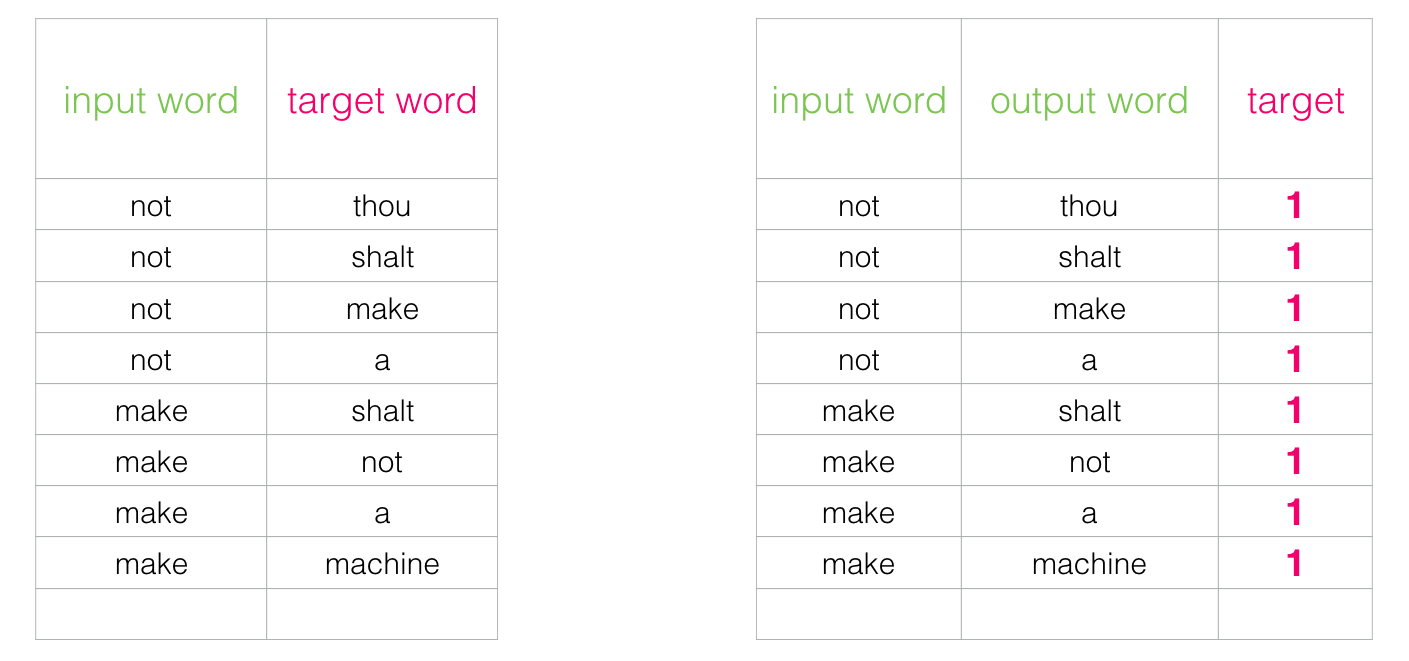
このようなモデルは、数分で数百万のサンプルという驚くべき速度で計算されます。 ただし、抜け穴を1つ閉じる必要があります。 すべての例が正の場合(目標:1)、100の精度を示す常に1を返すトリッキーなモデルを作成できますが、何も学習せず、ジャンク投資を生成します。
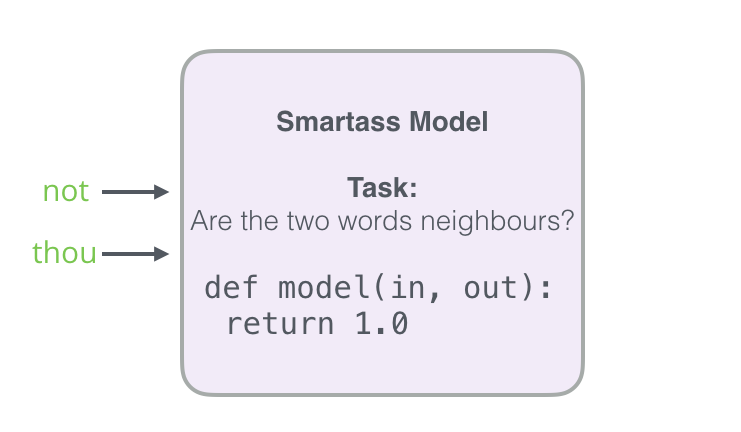
この問題を解決するには、 否定的なパターンをデータセットに入力する必要があります-明らかに隣人ではない単語。 これらの場合、モデルは0を返す必要があります。これで、モデルは一生懸命に動作する必要がありますが、計算は依然として非常に高速になります。

データセット内のサンプルごとに、0というラベルの付いた負の例を追加します
しかし、出力語として何を紹介しますか? 任意の単語を選択します。
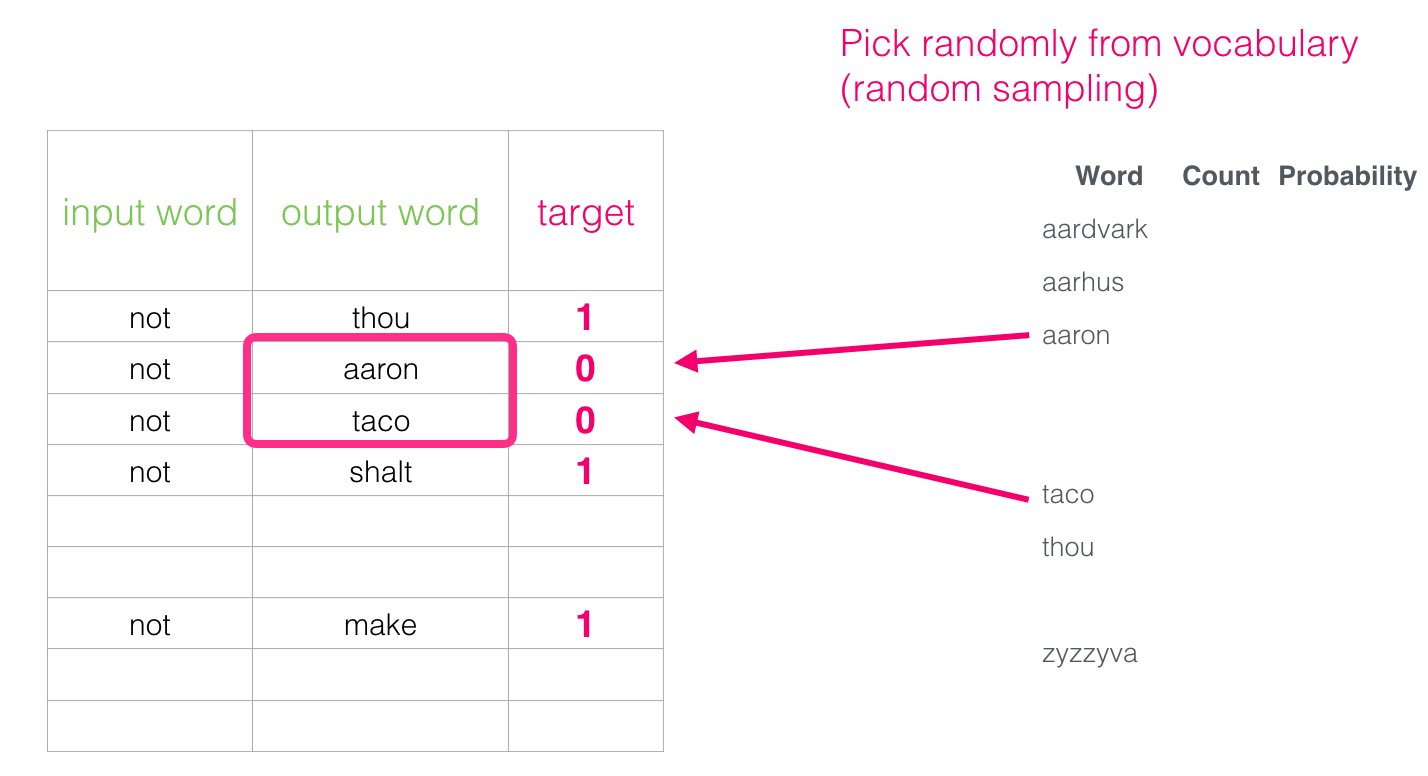
この考えは、 ノイズ比較法の影響下で生まれました[pdf]。 実際の信号(隣接する単語の肯定的な例)とノイズ(隣接しないランダムに選択された単語)を照合します。 これにより、パフォーマンスと統計パフォーマンスの優れた妥協点が提供されます。
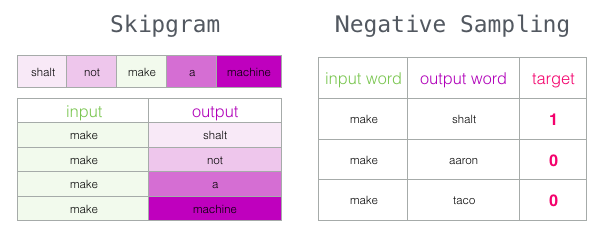
スキップグラムネガティブサンプル(SGNS)
word2vecの2つの中心的な概念に注目しました。これらは合わせて、「負のサンプリングによるスキップグラム」と呼ばれます。
word2vecの学習
「機械は、生きている人にとって重要なすべての問題を予測することはできません。 離散空間と連続連続体の間には大きな違いがあります。 私たちは1つのスペースに住んでおり、マシンは別のスペースに存在しています。」 - 砂丘の神
スキップグラムとネガティブサンプリングの基本的な考え方を検討したので、word2vecの学習プロセスを詳しく見ていきます。
まず、モデルをトレーニングするテキストを前処理します。 辞書のサイズ(
vocab_size
と呼ぶ)を定義します。たとえば、10,000個の添付ファイルと辞書内の単語のパラメーターで定義します。
トレーニングの開始時に、
Embedding
と
Context
2つのマトリックスを作成します。 各単語の添付ファイルは、辞書のこれらのマトリックスに格納されます(そのため、
vocab_size
はパラメーターの1つです)。 2番目のパラメーターは、添付ファイルの次元です(通常、
embedding_size
300に設定されていますが、以前に50次元の例を見てきました)。
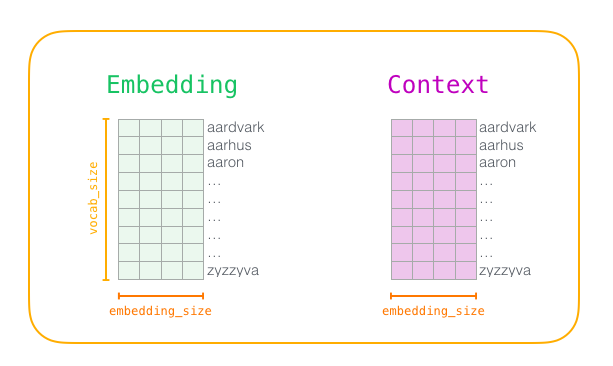
まず、これらの行列をランダムな値で初期化します。 次に、学習プロセスを開始します。 各段階で、1つのポジティブな例とそれに関連するネガティブな例を取り上げます。 これが最初のグループです。

現在、4つの単語があります。入力単語
not
と出力/文脈上の単語
thou
(実際の隣人)、
aaron
と
taco
(否定的な例)です。 両方のマトリックスには辞書のすべての単語の添付ファイルが含まれていますが、添付ファイルの検索は、
Embedding
(入力単語用)および
Context
(コンテキスト単語用)マトリックスで開始します。

次に、入力添付ファイルと各コンテキスト添付ファイルのスカラー積を計算します。 いずれの場合も、入力データとコンテキスト添付ファイルの類似性を示す数値が取得されます。

ここで、これらの推定値を確率の類似度に変換する方法が必要です。それらはすべて0から1までの正数でなければなりません。これはS字型ロジスティック方程式の優れたタスクです。
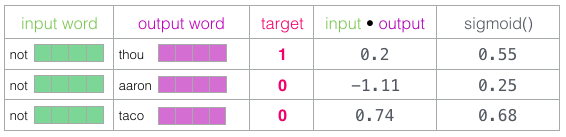
シグモイド計算の結果は、これらのサンプルのモデルの出力と見なすことができます。 ご覧のとおり、シグモイドの前と後の両方で、
taco
スコアが最高であり、
aaron
スコアは最低です。
訓練されていないモデルが予測を行い、比較のために実際のターゲットマークを持っている場合、モデル予測に含まれるエラーの数を計算しましょう。 これを行うには、ターゲットラベルからシグモイドスコアを減算します。
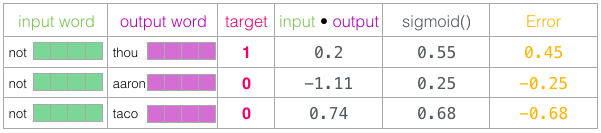
error
=
target
sigmoid_scores
ここで、「機械学習」という用語から「学習」段階が始まります。 これで、このエラー推定値を使用して
not
、
thou
、
aaron
および
taco
投資を調整し、次回の結果が目標推定値に近づくようにすることができます。

これにより、トレーニングの1つの段階が完了します。 いくつかの単語の添付ファイルを少し改善しました(
not
、
thou
、
aaron
、
taco
)。 次に、次のステージ(次のポジティブサンプルとそれに関連するネガティブサンプル)に進み、プロセスを繰り返します。
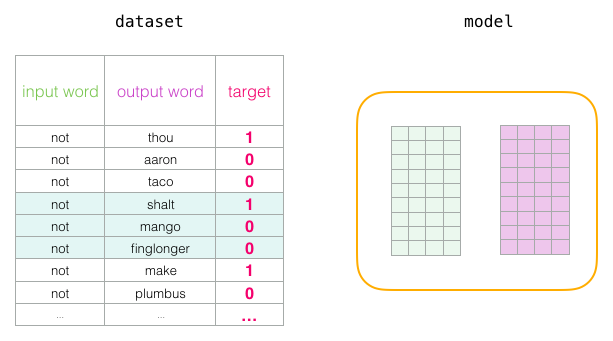
添付ファイルは、データセット全体を数回循環するにつれて改善され続けます。 その後、プロセスを停止し、
Context
マトリックスを脇に置いて、次のタスクでトレーニング済みの
Embeddings
マトリックスを使用できます。
ウィンドウサイズとネガティブサンプルの数
word2vecを学習する過程で、2つの主要なハイパーパラメーターはウィンドウサイズと負のサンプル数です。
さまざまなウィンドウサイズがさまざまなタスクに適しています。 小さいウィンドウサイズ(2〜15)は、類似のインデックスを持つ互換性のある添付ファイルを生成することがわかっています(周囲の単語を見ると、反意語はしばしば互換性があることに注意してください。 ウィンドウサイズを大きくすると(15〜50以上)、同様のインデックスを持つ関連投資が生成されます。 実際には、多くの場合、タスク内で有用なセマンティックの類似性のために注釈を提供する必要があります。 Gensimでは、デフォルトのウィンドウサイズは5です(入力ワード自体に加えて、左右に2ワード)。

ネガティブサンプルの数は、学習プロセスのもう1つの要因です。元の文書では5〜20を推奨しています。また、データセットが十分に大きい場合は2〜5個のサンプルで十分であると思われます。Gensimでは、デフォルト値は5つのネガティブパターンです。
おわりに
「もしあなたの行動があなたの基準を超えているなら、あなたはオートマトンではなく生きている人です」- デューンの神皇帝
単語の埋め込みとword2vecアルゴリズムの本質を理解していただければ幸いです。また、前述のレコメンダーシステムのように、「ネガティブサンプリングを使用したスキップグラム」(SGNS)の概念に言及している記事をよりよく理解していただければ幸いです。
参考資料と参考資料
- 「単語とフレーズの分散表現とその構成」 [pdf]
- « » [pdf]
- « » [pdf]
- « » — NLP. Word2vec .
- « » by — .
- Word2vec. « word2vec»
- ? :
- word2vec Python Gensim
- C ,
- « » , 2
- «»