今日の会話のトピックは、記憶を扱うことです。 ページディレクトリの初期化、物理メモリのマッピング、仮想管理とアロケータの組織ヒープについて説明します。
最初の記事で述べたように、私は4 MBのページを使用して生活を簡素化し、階層テーブルを処理しないことにしました。 将来的には、最新のシステムのように、4 KBページに移動したいと考えています。 既製のもの(たとえば、 このようなブロックアロケーター )を使用することもできますが、自分で書くのはもう少し面白く、メモリがどのように生きているかをもう少し理解したかったので、あなたに伝えることがあります。
前回、アーキテクチャに依存するsetup_pdメソッドに落ち着いて、それを継続したかったのですが、前回の記事ではカバーしていなかった詳細がもう1つありました。Rustと標準のprintlnマクロを使用したVGA出力です。 その実装は簡単なので、ネタバレの下で削除します。 コードはデバッグパッケージに含まれています。
#[macro_export] macro_rules! print { ($($arg:tt)*) => ($crate::debug::_print(format_args!($($arg)*))); } #[macro_export] macro_rules! println { () => ($crate::print!("\n")); ($($arg:tt)*) => ($crate::print!("{}\n", format_args!($($arg)*))); } #[cfg(target_arch = "x86")] pub fn _print(args: core::fmt::Arguments) { use core::fmt::Write; use super::arch::vga; vga::VGA_WRITER.lock().write_fmt(args).unwrap(); } #[cfg(target_arch = "x86_64")] pub fn _print(args: core::fmt::Arguments) { use core::fmt::Write; use super::arch::vga; // vga::VGA_WRITER.lock().write_fmt(args).unwrap(); }
今、明確な良心をもって、私は記憶に戻ります。
ページディレクトリの初期化
kmainメソッドは、入力として3つの引数を取りました。そのうちの1つはページテーブルの仮想アドレスです。 後で割り当てとメモリ管理に使用するには、レコードとディレクトリの構造を指定する必要があります。 x86の場合、PageディレクトリとPageテーブルは非常によく説明されているので、私は小さな入門者に限定します。 ページディレクトリエントリはポインタサイズ構造であり、私たちにとっては4バイトです。 値には、ページの4KBの物理アドレスが含まれます。 レコードの最下位バイトはフラグ用に予約されています。 仮想アドレスを物理アドレスに変換するメカニズムは次のようになります(私の4 MBの粒度の場合、シフトは22ビットで発生します。他の粒度の場合、シフトは異なり、階層テーブルが使用されます!)。
仮想アドレス0xC010A110->アドレスを22ビット右に移動してディレクトリ内のインデックスを取得->インデックス0x300->インデックス0x300でページの物理アドレスを取得、フラグとステータスを確認-> 0x1000000->仮想アドレスの下位22ビットをオフセットとして追加ページの物理アドレス-> 0x1000000 + 0x10A110 =メモリ0x110A110の物理アドレス
アクセスを高速化するために、プロセッサはTLB(ページアドレスをキャッシュする変換ルックアサイドバッファー)を使用します。
それで、ここに私のディレクトリとそのエントリがどのように記述され、まさにsetup_pdメソッドが実装されています。 ページを書き込むために、「コンストラクター」メソッドが実装されます。これは、4 KBによるアライメントとフラグの設定を保証し、ページの物理アドレスを取得するメソッドです。 ディレクトリは、1024個の4バイトエントリの配列です。 ディレクトリは、set_by_addrメソッドを使用して仮想アドレスをページに関連付けることができます。
#[derive(Debug, Clone, Copy, PartialEq, Eq)] pub struct PDirectoryEntry(u32); impl PDirectoryEntry { pub fn by_phys_address(address: usize, flags: PDEntryFlags) -> Self { PDirectoryEntry((address as u32) & ADDRESS_MASK | flags.bits()) } pub fn flags(&self) -> PDEntryFlags { PDEntryFlags::from_bits_truncate(self.0) } pub fn phys_address(&self) -> u32 { self.0 & ADDRESS_MASK } pub fn dbg(&self) -> u32 { self.0 } } pub struct PDirectory { entries: [PDirectoryEntry; 1024] } impl PDirectory { pub fn at(&self, idx: usize) -> PDirectoryEntry { self.entries[idx] } pub fn set_by_addr(&mut self, logical_addr: usize, entry: PDirectoryEntry) { self.set(PDirectory::to_idx(logical_addr), entry); } pub fn set(&mut self, idx: usize, entry: PDirectoryEntry) { self.entries[idx] = entry; unsafe { invalidate_page(idx); } } pub fn to_logical_addr(idx: usize) -> usize { (idx << 22) } pub fn to_idx(logical_addr: usize) -> usize { (logical_addr >> 22) } } use lazy_static::lazy_static; use spin::Mutex; lazy_static! { static ref PAGE_DIRECTORY: Mutex<&'static mut PDirectory> = Mutex::new( unsafe { &mut *(0xC0000000 as *mut PDirectory) } ); } pub unsafe fn setup_pd(pd: usize) { let mut data = PAGE_DIRECTORY.lock(); *data = &mut *(pd as *mut PDirectory); }
存在しないアドレスを使用して最初の静的初期化を非常に厄介に行ったので、リンクの再割り当てを使用してそのような初期化を行うことがRustコミュニティで慣習的である方法をご連絡いただければ幸いです。
上位レベルのコードからページを管理できるようになったので、メモリの初期化のコンパイルに移ります。 これは、物理メモリカードの処理と仮想マネージャーの初期化の2段階で行われます。
match mb_magic { 0x2BADB002 => { println!("multibooted v1, yeah, reading mb info"); boot::init_with_mb1(mb_pointer); }, . . . . . . } memory::init();
GRUBメモリーカードとOS1物理メモリーカード
GRUBからメモリカードを取得するために、ブート段階でヘッダーに対応するフラグを設定し、GRUBは構造の物理アドレスを提供しました。 公式ドキュメントからRust表記に移植し、メモリカードを快適に反復するメソッドも追加しました。 GRUB構造の大部分は埋められず、この段階ではあまり面白くありません。 主なことは、使用可能なメモリの量を手動で決定したくないということです。
マルチブートを使用して初期化する場合、最初に物理アドレスを仮想に変換します。 理論的には、GRUBは構造を任意の場所に配置できるため、アドレスがページを超える場合は、ページディレクトリに仮想ページを割り当てる必要があります。 実際、ほとんどの場合、構造は最初のメガバイトの隣にあります。最初のメガバイトは、ブート段階ですでに割り当てています。 念のため、メモリカードが存在することを示すフラグを確認し、分析に進みます。
pub mod multiboot2; pub mod multiboot; use super::arch; unsafe fn process_pointer(mb_pointer: usize) -> usize { //if in first 4 MB - map to kernel address space if mb_pointer < 0x400000 { arch::KERNEL_BASE | mb_pointer } else { arch::paging::allocate_page(mb_pointer, arch::MB_INFO_BASE, arch::paging::PDEntryFlags::PRESENT | arch::paging::PDEntryFlags::WRITABLE | arch::paging::PDEntryFlags::HUGE_PAGE ); arch::MB_INFO_BASE | mb_pointer } } pub fn init_with_mb1(mb_pointer: usize) { let ln_pointer = unsafe { process_pointer(mb_pointer) }; println!("mb pointer 0x{:X}", ln_pointer); let mb_info = multiboot::from_ptr(ln_pointer); println!("mb flags: {:?}", mb_info.flags().unwrap()); if mb_info.flags().unwrap().contains(multiboot::MBInfoFlags::MEM_MAP) { multiboot::parse_mmap(mb_info); println!("Multiboot memory map parsed, physical memory map has been built"); } else { panic!("MB mmap is not presented"); } }
メモリカードは、基本的な構造(すべてを仮想のものに変換することを忘れないでください)で初期物理アドレスが指定されているリンクリストと、バイト単位の配列のサイズです。 理論的にはサイズが異なる可能性があるため、各要素のサイズに基づいてリストを反復処理する必要があります。 これは、反復がどのように見えるかです:
impl MultibootInfo { . . . . . . pub unsafe fn get_mmap(&self, index: usize) -> Option<*const MemMapEntry> { use crate::arch::get_mb_pointer_base; let base: usize = get_mb_pointer_base(self.mmap_addr as usize); let mut iter: *const MemMapEntry = (base as u32 + self.mmap_addr) as *const MemMapEntry; for _i in 0..index { iter = ((iter as usize) + ((*iter).size as usize) + 4) as *const MemMapEntry; if ((iter as usize) - base) >= (self.mmap_addr + self.mmap_lenght) as usize { return None } else {} } Some(iter) } }
メモリカードを解析するとき、GRUB構造を繰り返し処理し、ビットマップに変換します。OS1はこれを使用して物理メモリを管理します。 GRUBとBIOSはより多くのオプションを提供しますが、制御に使用可能な値の小さなセット-無料、使用中、予約済み、使用不可に制限することにしました。 そのため、マップエントリを反復処理し、その状態をGRUB / BIOS値からOS1の値に変換します。
pub fn parse_mmap(mbi: &MultibootInfo) { unsafe { let mut mmap_opt = mbi.get_mmap(0); let mut i: usize = 1; loop { let mmap = mmap_opt.unwrap(); crate::memory::physical::map((*mmap).addr as usize, (*mmap).len as usize, translate_multiboot_mem_to_os1(&(*mmap).mtype)); mmap_opt = mbi.get_mmap(i); match mmap_opt { None => break, _ => i += 1, } } } } pub fn translate_multiboot_mem_to_os1(mtype: &u32) -> usize { use crate::memory::physical::{RESERVED, UNUSABLE, USABLE}; match mtype { &MULTIBOOT_MEMORY_AVAILABLE => USABLE, &MULTIBOOT_MEMORY_RESERVED => UNUSABLE, &MULTIBOOT_MEMORY_ACPI_RECLAIMABLE => RESERVED, &MULTIBOOT_MEMORY_NVS => UNUSABLE, &MULTIBOOT_MEMORY_BADRAM => UNUSABLE, _ => UNUSABLE } }
物理メモリは、メモリ::物理モジュールで管理されます。このモジュールに対して、上記のmapメソッドを呼び出し、領域のアドレス、長さ、状態を渡します。 システムで潜在的に使用可能な4 MBのメモリはすべて、4メガバイトページに分割され、ビットマップの2ビットで表されます。これにより、1024ページの4つの状態を保存できます。 合計で、この構築には256バイトが必要です。 ビットマップはひどいメモリの断片化につながりますが、理解しやすく、実装が簡単です。これが私の目的の主な目的です。
記事が乱雑にならないように、スポイラーの下のビットマップの実装を削除します。 この構造は、クラスと空きメモリの数をカウントし、インデックスとアドレスでページをマークし、空きページを検索することもできます(これは将来、ヒープを実装するために必要になります)。 カード自体は64 u32要素の配列であり、必要な2ビット(ブロック)を分離するために、いわゆるチャンク(配列内のインデックス、16ブロックのパッキング)およびブロック(チャンク内のビット位置)への変換が使用されます。
pub const USABLE: usize = 0; pub const USED: usize = 1; pub const RESERVED: usize = 2; pub const UNUSABLE: usize = 3; pub const DEAD: usize = 0xDEAD; struct PhysMemoryInfo { pub total: usize, used: usize, reserved: usize, chunks: [u32; 64], } impl PhysMemoryInfo { // returns (chunk, page) pub fn find_free(&self) -> (usize, usize) { for chunk in 0..64 { for page in 0.. 16 { if ((self.chunks[chunk] >> page * 2) & 3) ^ 3 == 3 { return (chunk, page) } else {} } } (DEAD, 0) } // marks page to given flag and returns its address pub fn mark(&mut self, chunk: usize, block: usize, flag: usize) -> usize { self.chunks[chunk] = self.chunks[chunk] ^ (3 << (block * 2)); let mask = (0xFFFFFFFC ^ flag).rotate_left(block as u32 * 2); self.chunks[chunk] = self.chunks[chunk] & (mask as u32); if flag == USED { self.used += 1; } else if flag == UNUSABLE || flag == RESERVED { self.reserved += 1; } else { if self.used > 0 { self.used -= 1; } } (chunk * 16 + block) << 22 } pub fn mark_by_addr(&mut self, addr: usize, flag: usize) { let block_num = addr >> 22; let chunk: usize = (block_num / 16) as usize; let block: usize = block_num - chunk * 16; self.mark(chunk, block, flag); } pub fn count_total(& mut self) { let mut count: usize = 0; for i in 0..64 { let mut chunk = self.chunks[i]; for _j in 0..16 { if chunk & 0b11 != 0b11 { count += 1; } chunk = chunk >> 2; } } self.total = count; } pub fn get_total(&self) -> usize { self.total } pub fn get_used(&self) -> usize { self.used } pub fn get_reserved(&self) -> usize { self.reserved } pub fn get_free(&self) -> usize { self.total - self.used - self.reserved } }
そして、マップの1つの要素の分析に取りかかりました。 マップ要素が4 MBで1ページ未満またはそれに等しいメモリの一部を記述する場合、このページ全体をマークします。 複数の場合-4 MBの破片にビートし、各破片は再帰的に別々にマークされます。 ビットマップの初期化の段階で、メモリのすべてのセクションにアクセスできないと見なします。たとえば、128 MBなどのカードがなくなると、残りのセクションはアクセス不可としてマークされます。
use lazy_static::lazy_static; use spin::Mutex; lazy_static! { static ref RAM_INFO: Mutex<PhysMemoryInfo> = Mutex::new(PhysMemoryInfo { total: 0, used: 0, reserved: 0, chunks: [0xFFFFFFFF; 64] }); } pub fn map(addr: usize, len: usize, flag: usize) { // if len <= 4MiB then mark whole page with flag if len <= 4 * 1024 * 1024 { RAM_INFO.lock().mark_by_addr(addr, flag); } else { let pages: usize = len >> 22; for map_page in 0..(pages - 1) { map(addr + map_page << 22, 4 * 1024 * 1024, flag); } map(addr + (pages << 22), len - (pages << 22), flag); } }
ヒープと彼女の管理
現在、仮想メモリ管理はヒープ管理のみに制限されています。これは、カーネルがそれ以上理解していないためです。 もちろん、将来的には、メモリ全体を管理する必要があり、この小さなマネージャーは書き直されます。 ただし、今のところ必要なのは、実行可能コードとスタックを含む静的メモリと、マルチスレッド用の構造を割り当てる動的ヒープメモリだけです。 ブート段階で静的メモリを割り当てます(カーネルが適合するため、これまでのところ4 MBに制限されています)。一般的には、現在は問題ありません。 また、この段階では、DMAデバイスはありません。そのため、すべてが非常にシンプルですが、理解できます。
512 MBのカーネルメモリ領域(0xE0000000)をヒープに割り当て、ヒープ使用マップ(0xDFC00000)を4 MB低く保存しました。 状態を説明するために、物理メモリと同様にビットマップを使用しますが、ビジー/フリーという2つの状態しかありません。 メモリブロックのサイズは64バイトです。これは、u32、u8などの小さな変数には非常に多くなりますが、おそらく、データ構造の格納に最適です。 それでも、ヒープに単一の変数を格納する必要はほとんどありません。現在の主な目的は、マルチタスクのコンテキスト構造を格納することです。
64バイトのブロックは、4 MBページ全体の状態を記述する構造にグループ化されるため、少量のメモリと大量のメモリの両方を複数のページに割り当てることができます。 私は次の用語を使用します:チャンク-64バイト、パック-2 KB(1 u32-64バイト*パッケージあたり32ビット)、ページ-4 MB。
#[repr(packed)] #[derive(Copy, Clone)] struct HeapPageInfo { //every bit represents 64 bytes chunk of memory. 0 is free, 1 is busy //u32 size is 4 bytes, so page information total size is 8KiB pub _4mb_by_64b: [u32; 2048], } #[repr(packed)] #[derive(Copy, Clone)] struct HeapInfo { //Here we can know state of any 64 bit chunk in any of 128 4-MiB pages //Page information total size is 8KiB, so information about 128 pages requires 1MiB reserved data pub _512mb_by_4mb: [HeapPageInfo; 128], }
アロケーターからメモリーを要求するとき、粒度に応じて3つのケースを検討します。
- 2 KB未満のメモリの要求がアロケーターから送信されました。 無料のパックを見つける必要があります[サイズ/ 64、ゼロ以外の余りは1を追加]チャンクを連続して、これらのチャンクをビジーとしてマークし、最初のチャンクのアドレスを返します。
- 4 MB未満、2 KBを超えるメモリの要求がアロケーターから送信されました。 空き[サイズ/ 2048、ゼロ以外の残りが1を追加]パックを連続して含むページを見つける必要があります。 [サイズ/ 2048]パックをビジーとしてマークし、残りがある場合は、最後のパックの[残り]チャンクをビジーとしてマークします。
- 4 MBを超えるメモリの要求がアロケーターから送信されました。 [サイズ/ 4 Mi、ゼロ以外の余りは1つ追加]ページを連続して検索し、[サイズ/ 4 Mi]ページを使用中としてマークします。 最後のパックで、残りのチャンクをビジーとしてマークします。
空き領域の検索も粒度に依存します。反復またはビットマスク用に配列が選択されます。 海外に行くたびに、OOMが起こります。 割り当てを解除する場合、同様のアルゴリズムが使用されますが、マークが解除されるだけです。 解放されたメモリはリセットされません。 コード全体が大きいので、ネタバレの下に置きます。
//512 MiB should be enough for kernel heap. If not - ooops... pub const KHEAP_START: usize = 0xE0000000; //I will keep 1MiB info about my heap in separate 4MiB page before heap at this point pub const KHEAP_INFO_ADDR: usize = 0xDFC00000; pub const KHEAP_CHUNK_SIZE: usize = 64; pub fn init() { KHEAP_INFO.lock().init(); } #[repr(packed)] #[derive(Copy, Clone)] struct HeapPageInfo { //every bit represents 64 bytes chunk of memory. 0 is free, 1 is busy //u32 size is 4 bytes, so page information total size is 8KiB pub _4mb_by_64b: [u32; 2048], } impl HeapPageInfo { pub fn init(&mut self) { for i in 0..2048 { self._4mb_by_64b[i] = 0; } } pub fn mark_chunks_used(&mut self, _32pack: usize, chunk: usize, n: usize) { let mask: u32 = 0xFFFFFFFF >> (32 - n) << chunk; self._4mb_by_64b[_32pack] = self._4mb_by_64b[_32pack] | mask; } pub fn mark_chunks_free(&mut self, _32pack: usize, chunk: usize, n: usize) { let mask: u32 = 0xFFFFFFFF >> (32 - n) << chunk; self._4mb_by_64b[_32pack] = self._4mb_by_64b[_32pack] ^ mask; } pub fn empty(&self) -> bool { for i in 0..2048 { if self._4mb_by_64b[i] != 0 { return false } } true } } #[repr(packed)] #[derive(Copy, Clone)] struct HeapInfo { //Here we can know state of any 64 bit chunk in any of 128 4-MiB pages //Page information total size is 8KiB, so information about 128 pages requires 1MiB reserved data pub _512mb_by_4mb: [HeapPageInfo; 128], } impl HeapInfo { pub fn init(&mut self) { for i in 0..128 { self._512mb_by_4mb[i].init(); } } // returns page number pub fn find_free_pages_of_size(&self, n: usize) -> usize { if n >= 128 { 0xFFFFFFFF } else { let mut start_page: usize = 0xFFFFFFFF; let mut current_page: usize = 0xFFFFFFFF; for page in 0..128 { if self._512mb_by_4mb[page].empty() { if current_page - start_page == n { return start_page } if start_page == 0xFFFFFFFF { start_page = page; } current_page = page; } else { start_page = 0xFFFFFFFF; current_page = 0xFFFFFFFF; } } 0xFFFFFFFF } } // returns (page number, 32pack number) pub fn find_free_packs_of_size(&self, n: usize) -> (usize, usize) { if n < 2048 { for page in 0..128 { let mut start_pack: usize = 0xFFFFFFFF; let mut current_pack: usize = 0xFFFFFFFF; for _32pack in 0..2048 { let _32pack_info = self._512mb_by_4mb[page]._4mb_by_64b[_32pack]; if _32pack_info == 0 { if current_pack - start_pack == n { return (page, start_pack) } if start_pack == 0xFFFFFFFF { start_pack = _32pack; } current_pack = _32pack; } else { start_pack = 0xFFFFFFFF; current_pack = 0xFFFFFFFF; } } } (0xFFFFFFFF, 0xFFFFFFFF) } else { (0xFFFFFFFF, 0xFFFFFFFF) } } // returns (page number, 32pack number, chunk number) pub fn find_free_chunks_of_size(&self, n: usize) -> (usize, usize, usize) { if n < 32 { for page in 0..128 { for _32pack in 0..2048 { let _32pack_info = self._512mb_by_4mb[page]._4mb_by_64b[_32pack]; let mask: u32 = 0xFFFFFFFF >> (32 - n); for chunk in 0..(32-n) { if ((_32pack_info >> chunk) & mask) ^ mask == mask { return (page, _32pack, chunk) } } } } (0xFFFFFFFF, 0xFFFFFFFF, 0xFFFFFFFF) } else { (0xFFFFFFFF, 0xFFFFFFFF, 0xFFFFFFFF) } } fn mark_chunks_used(&mut self, page: usize, _32pack: usize, chunk: usize, n: usize) { self._512mb_by_4mb[page].mark_chunks_used(_32pack, chunk, n); } fn mark_chunks_free(&mut self, page: usize, _32pack: usize, chunk: usize, n: usize) { self._512mb_by_4mb[page].mark_chunks_free(_32pack, chunk, n); } fn mark_packs_used(&mut self, page: usize, _32pack:usize, n: usize) { for i in _32pack..(_32pack + n) { self._512mb_by_4mb[page]._4mb_by_64b[i] = 0xFFFFFFFF; } } fn mark_packs_free(&mut self, page: usize, _32pack:usize, n: usize) { for i in _32pack..(_32pack + n) { self._512mb_by_4mb[page]._4mb_by_64b[i] = 0; } } } use lazy_static::lazy_static; use spin::Mutex; lazy_static! { static ref KHEAP_INFO: Mutex<&'static mut HeapInfo> = Mutex::new(unsafe { &mut *(KHEAP_INFO_ADDR as *mut HeapInfo) }); } fn allocate_n_chunks_less_than_pack(n: usize, align: usize) -> *mut u8 { let mut heap_info = KHEAP_INFO.lock(); let (page, _32pack, chunk) = heap_info.find_free_chunks_of_size(n); if page == 0xFFFFFFFF { core::ptr::null_mut() } else { let tptr: usize = KHEAP_START + 0x400000 * page + _32pack * 32 * 64 + chunk * 64; let res = tptr % align; let uptr = if res == 0 { tptr } else { tptr + align - res }; //check bounds: more than start and less than 4GiB - 64B //but according to chunks error should never happen if uptr >= KHEAP_START && uptr <= 0xFFFFFFFF - 64 * n { heap_info.mark_chunks_used(page, _32pack, chunk, n); uptr as *mut u8 } else { core::ptr::null_mut() } } } fn allocate_n_chunks_less_than_page(n: usize, align: usize) -> *mut u8 { let mut heap_info = KHEAP_INFO.lock(); let packs_n: usize = n / 32; let lost_chunks = n - packs_n * 32; let mut packs_to_alloc = packs_n; if lost_chunks != 0 { packs_to_alloc += 1; } let (page, pack) = heap_info.find_free_packs_of_size(packs_to_alloc); if page == 0xFFFFFFFF { core::ptr::null_mut() } else { let tptr: usize = KHEAP_START + 0x400000 * page + pack * 32 * 64; let res = tptr % align; let uptr = if res == 0 { tptr } else { tptr + align - res }; //check bounds: more than start and less than 4GiB - 64B //but according to chunks error should never happen if uptr >= KHEAP_START && uptr <= 0xFFFFFFFF - 64 * n { heap_info.mark_packs_used(page, pack, packs_n); if lost_chunks != 0 { heap_info.mark_chunks_used(page, pack + packs_to_alloc, 0, lost_chunks); } uptr as *mut u8 } else { core::ptr::null_mut() } } } //unsupported yet fn allocate_n_chunks_more_than_page(n: usize, align: usize) -> *mut u8 { let mut heap_info = KHEAP_INFO.lock(); let packs_n: usize = n / 32; let lost_chunks = n - packs_n * 32; let mut packs_to_alloc = packs_n; if lost_chunks != 0 { packs_to_alloc += 1; } let pages_n: usize = packs_to_alloc / 2048; let mut lost_packs = packs_to_alloc - pages_n * 2048; let mut pages_to_alloc = pages_n; if lost_packs != 0 { pages_to_alloc += 1; } if lost_chunks != 0 { lost_packs -= 1; } let page = heap_info.find_free_pages_of_size(pages_to_alloc); if page == 0xFFFFFFFF { core::ptr::null_mut() } else { let tptr: usize = KHEAP_START + 0x400000 * page; let res = tptr % align; let uptr = if res == 0 { tptr } else { tptr + align - res }; //check bounds: more than start and less than 4GiB - 64B * n //but according to chunks error should never happen if uptr >= KHEAP_START && uptr <= 0xFFFFFFFF - 64 * n { for i in page..(page + pages_n) { heap_info.mark_packs_used(i, 0, 2048); } if lost_packs != 0 { heap_info.mark_packs_used(page + pages_to_alloc, 0, lost_packs); } if lost_chunks != 0 { heap_info.mark_chunks_used(page + pages_to_alloc, lost_packs, 0, lost_chunks); } uptr as *mut u8 } else { core::ptr::null_mut() } } } // returns pointer pub fn allocate_n_chunks(n: usize, align: usize) -> *mut u8 { if n < 32 { allocate_n_chunks_less_than_pack(n, align) } else if n < 32 * 2048 { allocate_n_chunks_less_than_page(n, align) } else { allocate_n_chunks_more_than_page(n, align) } } pub fn free_chunks(ptr: usize, n: usize) { let page: usize = (ptr - KHEAP_START) / 0x400000; let _32pack: usize = ((ptr - KHEAP_START) - (page * 0x400000)) / (32 * 64); let chunk: usize = ((ptr - KHEAP_START) - (page * 0x400000) - (_32pack * (32 * 64))) / 64; let mut heap_info = KHEAP_INFO.lock(); if n < 32 { heap_info.mark_chunks_free(page, _32pack, chunk, n); } else if n < 32 * 2048 { let packs_n: usize = n / 32; let lost_chunks = n - packs_n * 32; heap_info.mark_packs_free(page, _32pack, packs_n); if lost_chunks != 0 { heap_info.mark_chunks_free(page, _32pack + packs_n, 0, lost_chunks); } } else { let packs_n: usize = n / 32; let pages_n: usize = packs_n / 2048; let lost_packs: usize = packs_n - pages_n * 2048; let lost_chunks = n - packs_n * 32; for i in page..(page + pages_n) { heap_info.mark_packs_free(i, 0, 2048); } if lost_packs != 0 { heap_info.mark_packs_free(page + pages_n, 0, lost_packs); } if lost_chunks != 0 { heap_info.mark_chunks_free(page + pages_n, packs_n, 0, lost_chunks); } } }
割り当てとページ違反
ヒープを使用するには、アロケーターが必要です。 それを追加すると、ベクター、ツリー、ハッシュテーブル、ボックスなどが開かれ、それなしでは生きることはほとんど不可能になります。 allocモジュールを接続してグローバルアロケータを宣言すると、すぐにすぐに使いやすくなります。
アロケーターの実装は非常に単純です-それは単に上記のメカニズムを指します。
use alloc::alloc::{GlobalAlloc, Layout}; pub struct Os1Allocator; unsafe impl Sync for Os1Allocator {} unsafe impl GlobalAlloc for Os1Allocator { unsafe fn alloc(&self, layout: Layout) -> *mut u8 { use super::logical::{KHEAP_CHUNK_SIZE, allocate_n_chunks}; let size = layout.size(); let mut chunk_count: usize = 1; if size > KHEAP_CHUNK_SIZE { chunk_count = size / KHEAP_CHUNK_SIZE; if KHEAP_CHUNK_SIZE * chunk_count != size { chunk_count += 1; } } allocate_n_chunks(chunk_count, layout.align()) } unsafe fn dealloc(&self, ptr: *mut u8, layout: Layout) { use super::logical::{KHEAP_CHUNK_SIZE, free_chunks}; let size = layout.size(); let mut chunk_count: usize = 1; if size > KHEAP_CHUNK_SIZE { chunk_count = size / KHEAP_CHUNK_SIZE; if KHEAP_CHUNK_SIZE * chunk_count != size { chunk_count += 1; } } free_chunks(ptr as usize, chunk_count); } }
lib.rsのアロケーターは、次のようにオンになります。
#![feature(alloc, alloc_error_handler)] extern crate alloc; #[global_allocator] static ALLOCATOR: memory::allocate::Os1Allocator = memory::allocate::Os1Allocator;
そして、ちょうどそのように自分自身を割り当てようとすると、ページフォールト例外が発生します。これは、仮想メモリの割り当てをまだ行っていないためです。 まあ、なんと! さて、前の記事の素材に戻って例外を追加する必要があります。 仮想メモリの遅延割り当てを実装することにしました。つまり、ページはメモリ要求時ではなく、アクセス試行時に割り当てられました。 幸いなことに、x86プロセッサはこれを許可し、さらには奨励しています。 Page fault , , , — , , CR2 — , .
, . 32 ( , , 32 ), . Rust. , . , , iret , , Page fault Protection fault. Protection fault — , .
eE_page_fault: pushad mov eax, [esp + 32] push eax mov eax, cr2 push eax call kE_page_fault pop eax pop eax popad add esp, 4 iret
Rust , . , . . .
bitflags! { struct PFErrorCode: usize { const PROTECTION = 1; //1 - protection caused, 0 - not present page caused const WRITE = 1 << 1; //1 - write caused, 0 - read caused const USER_MODE = 1 << 2; //1 - from user mode, 0 - from kernel const RESERVED = 1 << 3; //1 - reserved page (PAE/PSE), 0 - not const INSTRUCTION = 1 << 4; //1 - instruction fetch caused, 0 - not } } impl PFErrorCode { pub fn to_pd_flags(&self) -> super::super::paging::PDEntryFlags { use super::super::paging; let mut flags = paging::PDEntryFlags::empty(); if self.contains(PFErrorCode::WRITE) { flags.set(paging::PDEntryFlags::WRITABLE, true); } if self.contains(PFErrorCode::USER_MODE) { flags.set(paging::PDEntryFlags::USER_ACCESSIBLE, true); } flags } } #[no_mangle] pub unsafe extern fn kE_page_fault(ptr: usize, code: usize) { use super::super::paging; println!("Page fault occured at addr 0x{:X}, code {:X}", ptr, code); let phys_address = crate::memory::physical::alloc_page(); let code_flags: PFErrorCode = PFErrorCode::from_bits(code).unwrap(); if !code_flags.contains(PFErrorCode::PROTECTION) { //page not presented, we need to allocate the new one let mut flags: paging::PDEntryFlags = code_flags.to_pd_flags(); flags.set(paging::PDEntryFlags::HUGE_PAGE, true); paging::allocate_page(phys_address, ptr, flags); println!("Page frame allocated at Paddr {:#X} Laddr {:#X}", phys_address, ptr); } else { panic!("Protection error occured, cannot handle yet"); } }
, . , . . , . , , :
println!("memory: total {} used {} reserved {} free {}", memory::physical::total(), memory::physical::used(), memory::physical::reserved(), memory::physical::free()); use alloc::vec::Vec; let mut vec: Vec<usize> = Vec::new(); for i in 0..1000000 { vec.push(i); } println!("vec len {}, ptr is {:?}", vec.len(), vec.as_ptr()); println!("Still works, check reusage!"); let mut vec2: Vec<usize> = Vec::new(); for i in 0..10 { vec2.push(i); } println!("vec2 len {}, ptr is {:?}, vec is still here? {}", vec2.len(), vec2.as_ptr(), vec.get(1000).unwrap()); println!("Still works!"); println!("memory: total {} used {} reserved {} free {}", memory::physical::total(), memory::physical::used(), memory::physical::reserved(), memory::physical::free());
:
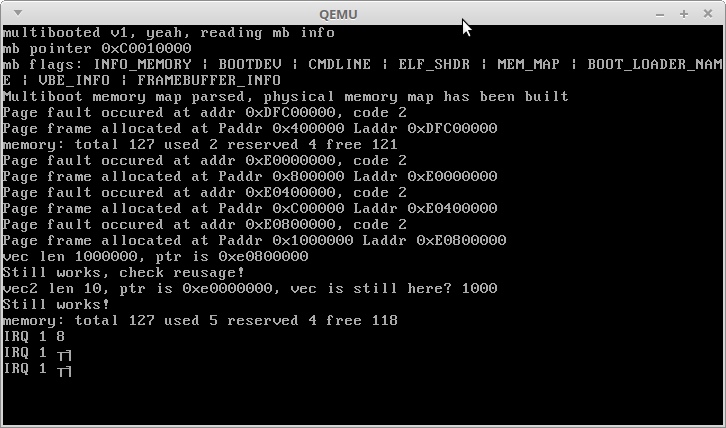
ご覧のように、メモリの割り当てはうまくいきますが、もちろん、多数の実現を伴う百万回目のサイクルには長い時間がかかります。予想どおり、すべての割り当て後の整数が100万のベクトルは、3.5 GB + 3 MBのアドレスを占有します。ヒープの最初のメガバイトが解放され、2番目の小さなベクターがその3.5 GBアドレスに配置されました。
IRQ 1と不可解な文字-Alt + PrntScrnキーからの割り込みに対するカーネルの反応:)
それで作業束ができたので、Rustデータ構造-好きなだけオブジェクトを作成できるようになりました。つまり、プロセッサが実行するタスクの状態を保存できるということです。
次の記事では、基本的なマルチタスクの実装方法と、同じプロセッサ上の並列スレッドで2つの愚かな関数を実行する方法について説明します。
ご清聴ありがとうございました!