
myTargetの動的リマーケティング(dynrem)は、ウェブサイトや広告主のモバイルアプリケーションでのユーザーアクションに関する情報を使用するターゲット広告テクノロジーです。 たとえば、オンラインストアで、ユーザーは商品のページを見たり、バスケットに追加したり、myTargetはこれらのイベントを使用して、以前に興味を示した商品やサービスの広告を表示します。 今日は、非個人的、つまりitem2item-recommendationsを生成するメカニズムについて詳しく説明します。これにより、広告の出力を多様化し、補完することができます。
dynrem myTargetの顧客は、主にオンラインストアであり、1つ以上の製品リストを持つことができます。 推奨事項を作成するときは、「ストア-商品リスト」のペアを別のユニットと見なす必要があります。 ただし、簡単にするために、後で「ストア」を使用します。 入力タスクのディメンションについて説明する場合、約1,000の店舗について推奨事項を作成する必要があり、商品の数は数千から数百万までさまざまです。
dynremの推奨システムは、次の要件を満たしている必要があります。
- バナーには、CTRを最大化する製品が含まれています。
- 推奨事項は、一定期間オフラインで作成されます。
- システムアーキテクチャは、柔軟性、拡張性、安定性があり、コールドスタート環境で動作する必要があります。
一定時間の推奨事項を作成するための要件と、説明されている初期条件(店舗の数が増えていると楽観的に想定します)から、マシンリソースの経済的な使用のための要件が自然に発生することに注意してください。
セクション2には推奨システムを構築するための理論的基礎が含まれ、セクション3および4で問題の実際的な側面について説明し、セクション5に全体的な結果を要約します。
基本的な概念
1つの店舗のレコメンダーシステムを構築するタスクを検討し、基本的な数学的アプローチをリストします。
特異値分解(SVD)
推奨システムを構築する一般的なアプローチは、特異分解(SVD)アプローチです。 評価マトリックス 2つの行列の積として表す そして そのように その後、ユーザー評価を評価します グッズ用 として表される [1]、スカラー積の要素は次元ベクトルです (モデルの主なパラメーター)。 この式は、他のSVDモデルの基礎として機能します。 見つけるタスク そして 機能の最適化に帰着します。
(2.1)
どこで -エラー関数(たとえば、 Netflix競合他社のRMSE)、 -正則化、および合計が評価が知られているペアにあります。 式(2.1)を明示的な形式に書き換えます。
(2.2)
ここに 、 -ユーザー表現のL2正則化係数 と商品 それに応じて。 Netflixコンテストの基本モデルは次のとおりです。
(2.3)
(2.4)
どこで 、 そして -評価、ユーザー、および製品のバイアス。 モデル(2.3)-(2.4)は、暗黙的なユーザー設定を追加することで改善できます。 Netflixコンペティションの例では、明示的な応答は「リクエストに応じて」ユーザーが映画に設定したスコア、および「ユーザーの製品とのやり取り」に関するその他の情報です(映画、その説明、レビューの表示、つまり暗黙的な応答は暗黙的な応答を与えません)映画の評価に関する直接的な情報ですが、同時に関心を示しています)。 暗黙的な応答アカウンティングは、SVD ++モデルに実装されています。
(2.5)
どこで -ユーザーが暗黙的に対話するオブジェクトのセット、 -次元表現 からのオブジェクト 。
因数分解マシン(FM)
異なるSVDモデルを使用した例でわかるように、1つのモデルは評価式に含まれる用語のセットが他のモデルと異なります。 さらに、モデルの拡張は毎回新しいタスクを表します。 このような変更(たとえば、時間パラメーターを考慮した新しい種類の暗黙的な応答の追加)は、モデル実装コードを変更せずに簡単に実装する必要があります。 モデル(2.1)-(2.5)は、次のパラメーター化を使用して便利な普遍的な形式で表すことができます。 ユーザーと製品を一連の機能として表します。
(2.6)
(2.7)
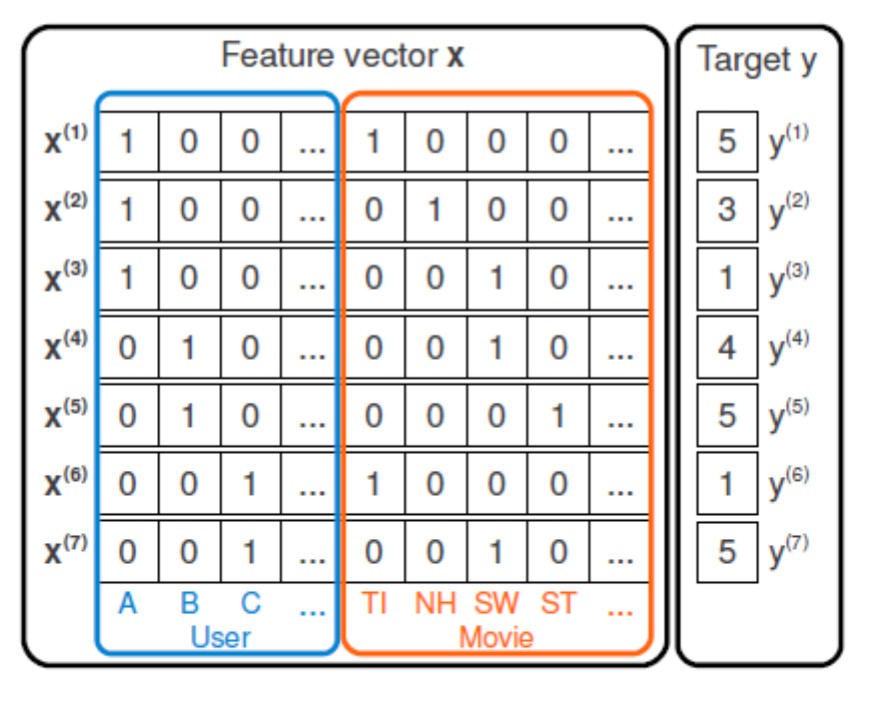
図 1:CFの場合の特徴マトリックスの例。
たとえば、コラボレーティブフィルタリング(CF)の場合、ユーザーと製品の相互作用に関するデータのみを使用すると、特徴ベクトルはワンホットコードのようになります(図1)。 ベクターを導入 、推奨タスクはターゲット変数の回帰問題に削減されます :
- 線形モデル:
(2.8)
- Poly2:
(2.9)
- FM:
(2.10)
どこで -モデルパラメータ、 次元ベクトルです サインを表す 潜在空間で そして -ユーザーと製品の兆候の数。 ワンホットコードに加えて、コンテンツベースの属性(コンテンツベース、CB)は、製品やユーザープロファイルのベクトル化された説明などの記号(図2)として機能します。

図 2:拡張された機能マトリックスの例。
[2]で導入されたFMモデルは、(2.1)-(2.5)、(2.8)、(2.10)の一般化です。 FMの本質は、スカラー積を使用して機能のペアワイズ相互作用を考慮することです 、パラメーターを使用しない 。 Poly2に対するFMの利点は、パラメーターの数が大幅に削減されることです。ベクトルの場合 必要になります パラメータ、および 必要になります パラメータ。 で そして 大規模な注文の場合、最初のアプローチでは大幅に少ないパラメーターを使用します。
注:トレーニングセットに特定のペアがない場合 、次に対応する用語 Poly2では、モデルのトレーニングには影響せず、評価スコアは線形部分でのみ形成されます。 ただし、アプローチ(2.10)では、他の機能を介して関係を確立できます。 言い換えれば、1つの相互作用に関するデータは、この例に含まれていない属性のパラメーターを評価するのに役立ちます。
FMに基づいて、CB属性がCF属性に追加される、いわゆるハイブリッドモデルが実装されます。 これにより、コールドスタートの問題を解決でき、ユーザー設定も考慮して、パーソナライズされた推奨事項を作成できます。
Lightfm
FMの一般的な実装では、ユーザーと製品の特性の分離に重点が置かれています。 行列はモデルパラメーターとして機能します そして カスタムおよび製品機能の提出:
(2.11)
オフセットと同様に 。 ユーザービューと製品ビューの使用:
(2.12)
(2.13)
ペア評価を取得する :
(2.14)
損失関数
この場合、特定のユーザーの製品をランク付けして、関連性の高い製品が関連性の低い製品よりも高い評価を持つようにする必要があります。 LightFMは、いくつかの損失関数を実装しています。
- ロジスティックは、ネガティブを必要とする実装であり、ほとんどのタスクでは明示的に提示されていません。
- BPR [3]は、特定のユーザーの肯定的な例と否定的な例の格付けの違いを最大化することです。 負の値は、ブートストラップサンプリングを使用して取得されます。 アルゴリズムで使用される品質機能は、ROC-AUCに似ています。
- WARP [4]は、負の例のサンプリング方法とランキングでもある損失関数の点でBPRとは異なりますが、同時にユーザーに対する上位の推奨事項を最適化します。
実用的な実装
特定の時間の推奨事項を作成するには、Sparkの並列実装を使用します。 店舗ごとに独立したタスクが起動され、その実行はルイージによって制御されます。
データの前処理
データの前処理は、自動的にスケーラブルなSpark SQLツールによって実行されます。 最終モデルで選択された機能は、標準変換された商品およびカタログのテキストによる説明です。
Sparkとやり取りする際に役立ったもの:
- 準備されたデータ(ユーザーと製品の相互作用のマトリックス、それらの属性)を店舗ごとに分割します。 これにより、HDFSからのデータの読み取りに関するトレーニングフェーズ中の時間を節約できます。 そうでない場合、各タスクはデータをSparkメモリに読み取り、ストアIDでフィルタリングする必要があります。
- Sparkへのデータの保存/ Sparkからのデータの受信はパーツを行います。 これは、これらのアクション中にデータがJVMのメモリにロードされるという事実によるものです。 JVMのメモリを増やすだけではどうですか? まず、モデルのトレーニングに使用できるメモリが減少します。次に、JVMに何も保存する必要がないため、この場合は一時的なストレージとして機能します。
モデルトレーニング
各ストアのモデルは、独自のSparkコンテナーでトレーニングされるため、クラスターリソースによってのみ制限される、ストアに対して任意の数のタスクを同時に実行できます。
LightFMには早期停止メカニズムがないため、ターゲットメトリックが増加しない場合、トレーニングの追加反復に余分なリソースを費やします。 AUCをメトリックとして選択し、CTRとの関係が実験的に確認されました。
注:
-ユーザーと製品間のすべての既知の相互作用、つまりペア 、
-すべての商品の多く 、
-すべてのユーザーの多く 。
特定のユーザー向け また紹介します -ユーザーが操作した多くの製品。 AUCは次のように計算できます[参照]:
(3.1)
(3.2)
式(3.1)では、可能なすべてのペアの評価を計算する必要があります ( 修正済み)、およびからのアイテムの評価を比較します からの評価 。 ユーザーが品揃えの乏しい部分と対話することを考えると、計算の複雑さは 。 同時に、FMトレーニングの1つの時代にはコストがかかります 。
したがって、AUCの計算を変更しました。 まず、サンプルをトレーニングに分割する必要があります および検証 、そして 。 次に、サンプリングを使用して、検証のために多くのユーザーを作成します 。 ユーザー向け から 陽性クラスの要素は多数と見なされます 同様の 。 負のクラスの要素として、サブサンプルを取得します からの要素がないように 。 サブサンプルのサイズは、サイズに比例して取得できます。 それは 。 次に、AUCを計算するための式(3.1)、(3.2)が変更されます。
(3.3)
(3.4)
その結果、ユーザーの固定部分のみを取得するため、AUCを計算するために一定の時間を取得します。 そして サイズが小さい。 ストアの学習プロセスは、AUC(3.4)の改善が止まった後に停止します。
類似オブジェクトを検索する
item2itemタスクの一部として、各アイテムを選択する必要があります (または可能な限り類似した製品)、バナーのクリック可能性を最大化する製品。 私たちの仮定:バナーの候補は上から考慮しなければなりません- 空間埋め込みに最も近い。 「最近傍」の計算方法として、Scala + Spark、ANNOY、SCANN、HNSWをテストしました。
50万のオブジェクトを含むストアのScala + Sparkバンドルの場合、正直なコサインメトリックの計算には15分とかなりの量のクラスターリソースが必要でした。 SCANNsメソッドを調べると、次のパラメーターが変化しました:
bucketLimit
、
shouldSampleBuckets
、
NumHashes
、および
setSignatureLength
ですが、結果は他のメソッドと比較して不十分であることが
setSignatureLength
(非常に異なるオブジェクトがバケットに落ちました)。 ANNOYおよびHNSWアルゴリズムは、正直なコサインに匹敵する結果を示しましたが、はるかに高速に動作しました。
| 20万個の製品 | 50万個の商品 | 220万製品 | ||||
| アルゴリズム | うるさい | Hnsw | うるさい | Hnsw | うるさい | Hnsw |
| ビルド時間
インデックス(秒) | 59.45 | 8.64 | 258.02 | 25.44 | 1190.81 | 90.45 |
| 合計時間(秒) | 141.23 | 01/14 | 527.76 | 43.38 | 2081.57 | 150.92 |
HNSWはすべてのアルゴリズムよりも速く動作したという事実のため、私たちはそれをやめることにしました。
また、Sparkコンテナー内の最近傍を検索し、適切なパーティションで結果をHiveに書き込みます。
おわりに
リコール:WARPを使用してモデルをトレーニングし、AUCを早期停止に使用します。最終品質評価は、ライブトラフィックのA / Bテストを使用して実行されます。
この場所で-実験を組織し、バナーの最適な構成を選択することで-データが終わり、科学が始まると信じています。 ここでは、リターゲティングが機能した製品の推奨事項を表示することが理にかなっているかどうかを判断します。 正確に表示する推奨事項の数。 閲覧した商品の数など。 これについては、次の記事で説明します。
アルゴリズムのさらなる改善-すべての店舗の製品を1つのスペースに配置できるようにするユニバーサル埋め込みの検索-は、記事の冒頭で説明したパラダイムのフレームワーク内で実行されます。
ご清聴ありがとうございました!
文学
[1] Ricci F.、Rokach L.、Shapira B.推奨システムハンドブックの紹介
//推奨システムハンドブック。 -2011年マサチューセッツ州ボストン、スプリンガー。-S. 147160
[2] Rendle S. Factorizationマシン// 2010 IEEE Data Conference on Data Mining。 -IEEE、2010年-S. 995-1000。
[3] Rendle S. et al。 BPR:暗黙的なフィードバックからのベイジアンパーソナライズランキング
//人工知能の不確実性に関する第25回会議の議事録。
-AUAI Press、2009年-S. 452-461。
[4] Weston J.、Bengio S.、Usunier N. Wsabie:大規模な語彙の画像注釈までのスケーリング//第22回人工知能に関する国際共同会議。 -2011。