ビッグデータを使用する操作には、多くの計算能力が必要です。 データベースからHadoopへの一般的なデータの移動には、飛行機の翼と同じくらいの数週間または費用がかかります。 待って散財したくないですか? 異なるプラットフォームで負荷を分散します。 1つの方法は、プッシュダウンの最適化です。
Informatica製品の開発と管理を行うロシアの大手トレーナーであるAlexey Ananyevに、Informatica Big Data Management(BDM)のプッシュダウン最適化機能について話してもらいました。 Informatica製品の操作を学んだことがありますか? おそらく、PowerCenterの基本を説明し、マッピングを構築する方法を説明したのはアレックスでした。
アレクセイ・アナニエフ、DISグループのトレーニング責任者
プッシュダウンとは何ですか?
あなたの多くはすでにInformatica Big Data Management(BDM)に精通しています。 この製品は、さまざまなソースからのビッグデータを統合し、さまざまなシステム間でビッグデータを移動したり、それらに簡単にアクセスしたり、プロファイルを作成したりできます。
熟練した人であれば、BDMは驚異的に機能します。タスクは最小限のコンピューティングリソースで迅速に完了します。
あなたも欲しい? BDMのプッシュダウン機能を使用して、プラットフォーム間でコンピューティングの負荷を分散する方法を学びます。 プッシュダウンテクノロジを使用すると、マッピングをスクリプトに変換し、このスクリプトを実行する環境を選択できます。 そのような選択の可能性により、異なるプラットフォームの長所を組み合わせて、最大のパフォーマンスを実現できます。
スクリプトランタイムを設定するには、プッシュダウンタイプを選択します。 スクリプトは、Hadoopで完全に実行することも、ソースとレシーバーの間で部分的に配布することもできます。 プッシュダウンには4つのタイプがあります。 マッピングをスクリプトに変換することはできません(ネイティブ)。 マッピングは、ソース(ソース)で可能な限り実行することも、ソース(完全)で完全に実行することもできます。 マッピングをHadoop(なし)スクリプトに変換することもできます。
プッシュダウンの最適化
リストされた4種類はさまざまな方法で組み合わせることができます-システムの特定のニーズに合わせてプッシュダウンを最適化します。 たとえば、多くの場合、独自の機能を使用してデータベースからデータを抽出することをお勧めします。 そして、データを変換する-Hadoopによって、データベース自体が過負荷にならないようにします。
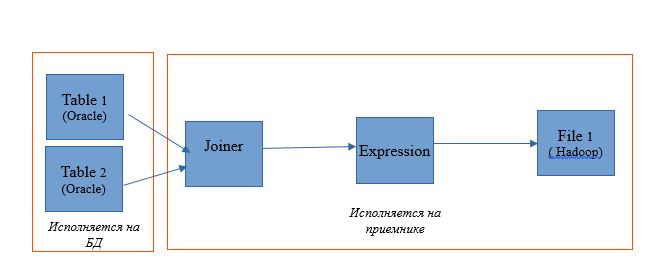
ソースとレシーバーの両方がデータベースにあり、変換実行プラットフォームを選択できる場合を見てみましょう。設定に応じて、Informatica、データベースサーバー、またはHadoopになります。 このような例は、このメカニズムの技術的な側面を最も正確に理解することを可能にします。 当然のことながら、実際にはこのような状況は発生しませんが、機能を実証するのに最適です。
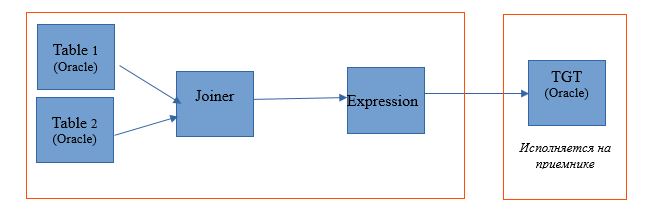
マッピングを使用して、単一のOracleデータベース内の2つのテーブルを読み取ります。 そして、読み取り結果を同じデータベースのテーブルに書き込むようにします。 マッピングスキームは次のようになります。

Informatica BDM 10.2.1のマッピングの形式では、次のようになります。
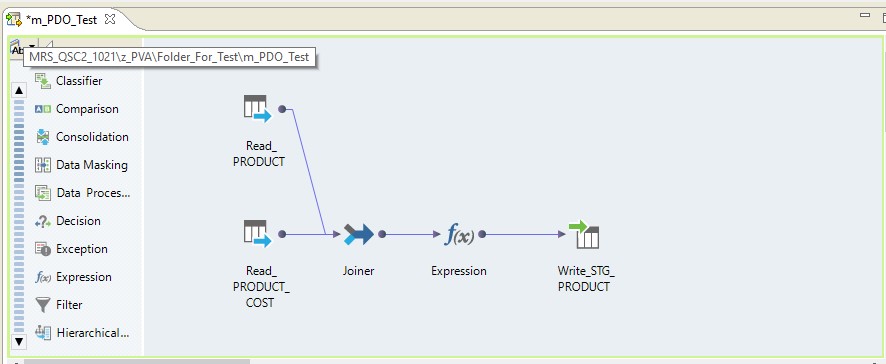
タイププッシュダウン-ネイティブ
プッシュダウンネイティブタイプを選択すると、マッピングはInformaticaサーバーで実行されます。 データはOracleサーバーから読み取られ、Informaticaサーバーに転送され、そこで変換されてHadoopに転送されます。 つまり、定期的なETLプロセスを取得します。
タイププッシュダウン-ソース
ソースの種類を選択するとき、データベースサーバー(DB)とHadoopの間でプロセスを分散する機会があります。 この設定でプロセスを実行すると、テーブルからデータを選択するリクエストがデータベースに送信されます。 そして、残りはHadoopのステップの形で行われます。
実行図は次のようになります。
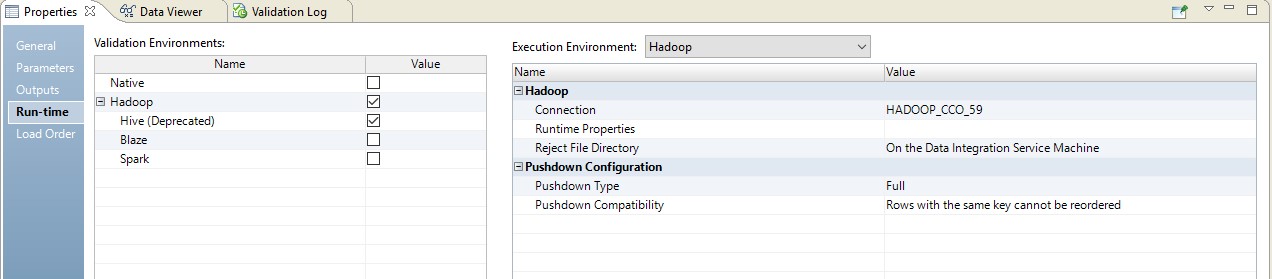
以下は、ランタイムのセットアップの例です。
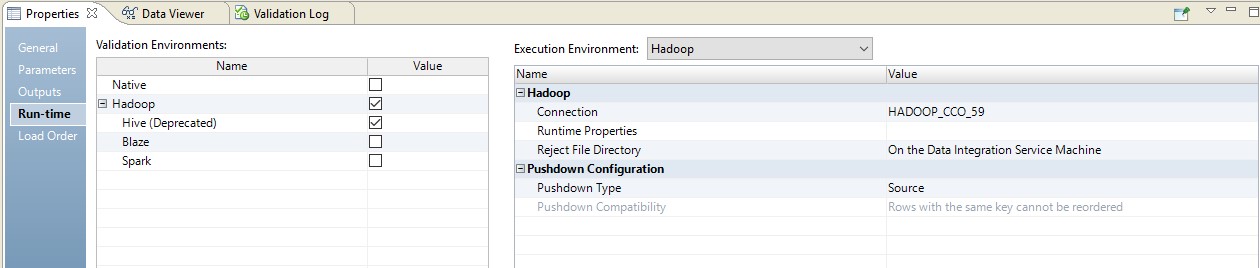
この場合、マッピングは2つのステップで実行されます。 彼の設定では、ソースに送信されるスクリプトになっていることがわかります。 さらに、テーブルとデータ変換の組み合わせは、ソースでオーバーライドされたクエリの形式で実行されます。
以下の図では、BDMおよびソースでの最適化されたマッピング(オーバーライドされたリクエスト)を確認できます。
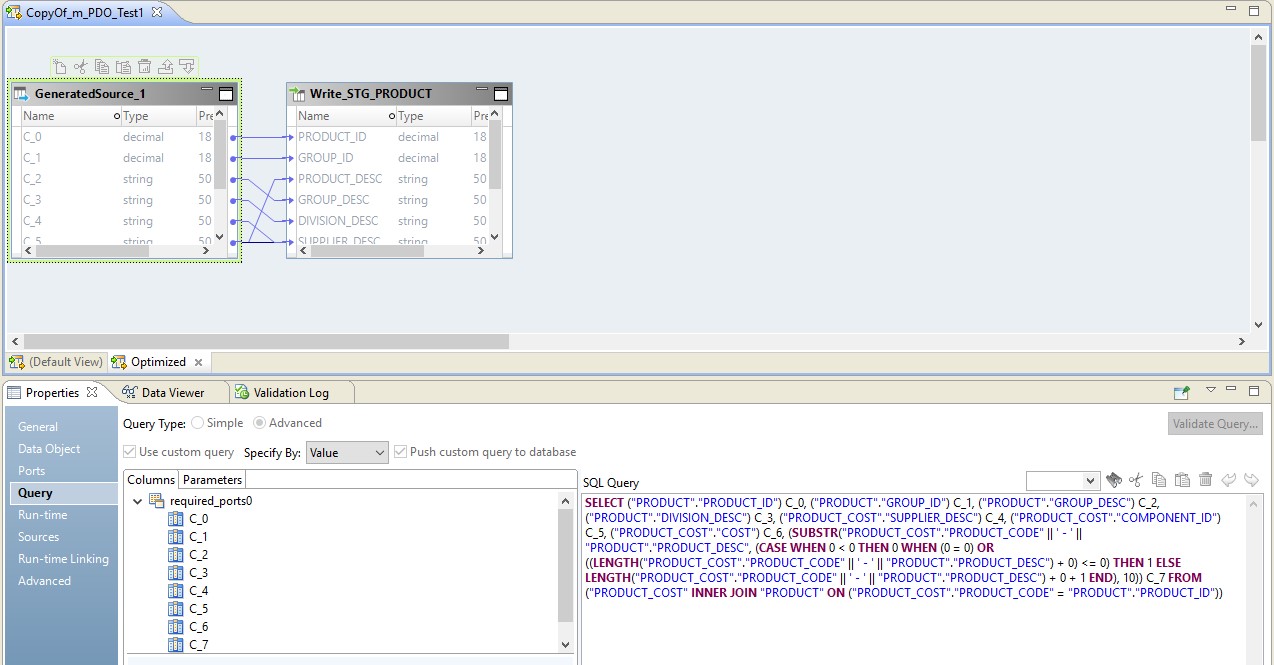
この構成でのHadoopの役割は、データフローの管理-それを実行することです。 リクエストの結果はHadoopに送信されます。 読み取り後、Hadoopからのファイルが受信者に書き込まれます。
タイププッシュダウン-フル
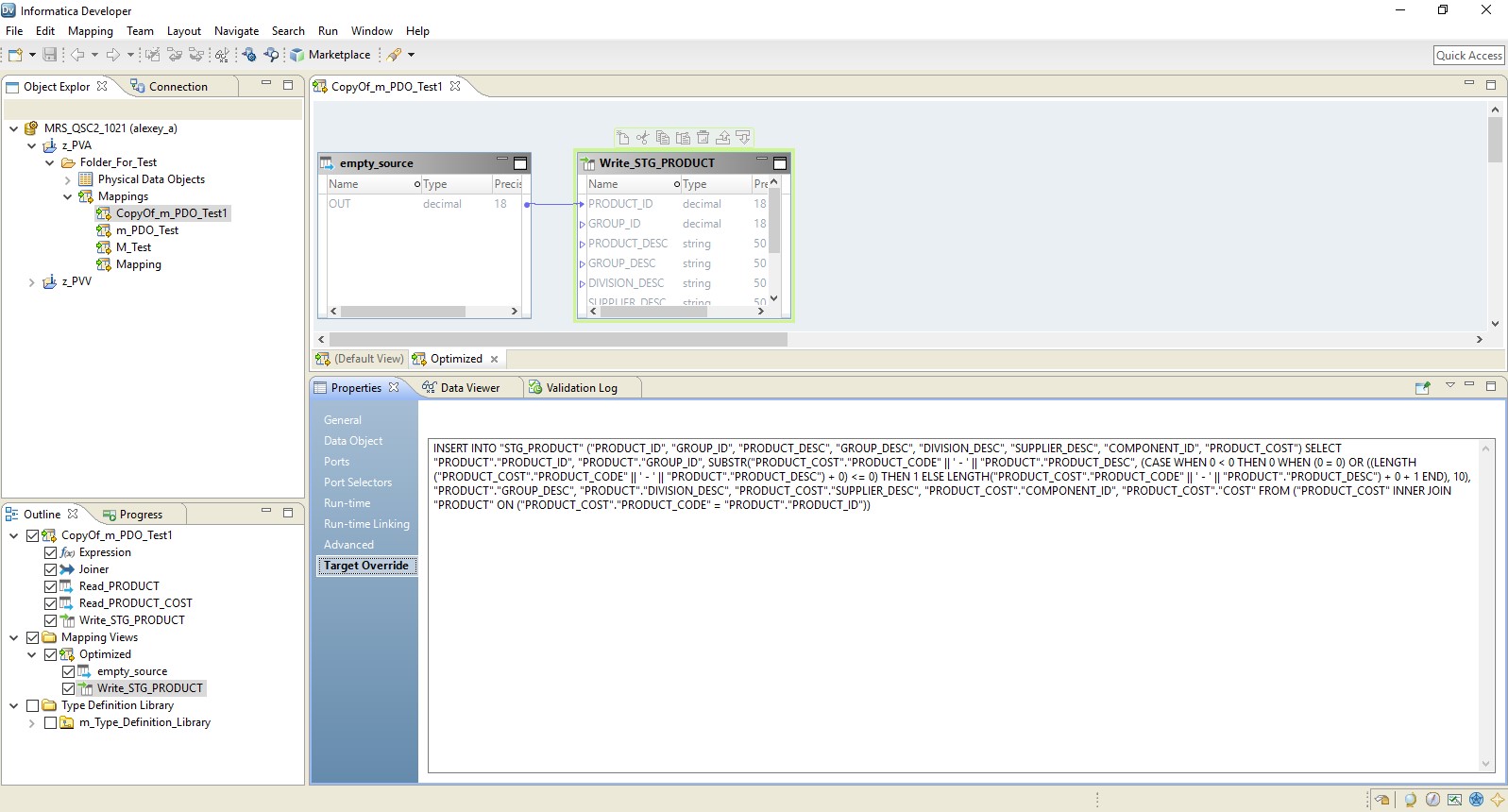
完全なタイプを選択すると、マッピングは完全にデータベース要求に変わります。 また、クエリ結果はHadoopに送信されます。 そのようなプロセスの図を以下に示します。
設定例を以下に示します。
その結果、前のものと同様の最適化されたマッピングが得られます。 唯一の違いは、すべてのロジックがその挿入のオーバーライドの形式でレシーバーに転送されることです。 最適化されたマッピングの例を以下に示します。
ここでは、前のケースと同様に、Hadoopはコンダクターとして機能します。 しかし、ここではソース全体が読み取られ、レシーバレベルでデータ処理ロジックが実行されます。
タイププッシュダウン-null
さて、最後のオプションはプッシュダウンタイプで、その中でマッピングがHadoopスクリプトに変わります。
最適化されたマッピングは次のようになります。
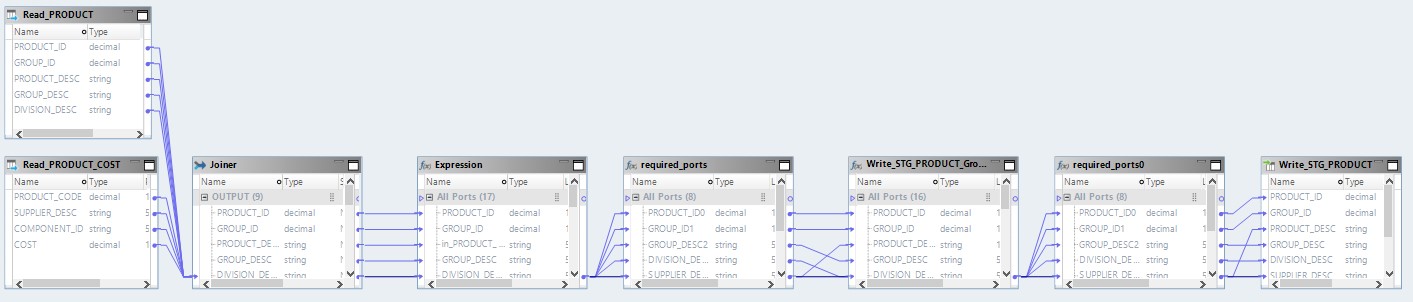
ここでは、ソースファイルのデータが最初にHadoopで読み取られます。 次に、彼自身の手段により、これら2つのファイルが結合されます。 その後、データが変換され、データベースにアップロードされます。
プッシュダウン最適化の原則を理解すると、ビッグデータを操作するための多くのプロセスを非常に効果的に整理できます。 そのため、ごく最近では、大企業がわずか数週間でストレージからHadoopに大きなデータをアップロードしました。