エラーと誤ったアプリケーション:違いは何ですか?
物理システムには、何らかのエラー、不正確さが含まれます。 最も多様な形式:いわゆるトレランス-同じタイプの異なる製品のサイズの違い。 非線形特性-デバイスまたは方法が特定の制限内で厳密に知られている法則に従って何かを測定し、その後適用されなくなる場合。 離散性-技術的にスムーズな出力特性を確保できない場合。
同時に、デバイス、機器、数学の法則の誤った使用など、純粋にヒューマンエラーがあります。 システムに固有のエラーとこのシステムの適用エラーには根本的な違いがあります。 同じ単語「エラー」と呼ばれるこれら2つの概念を区別し、混同しないことが重要です。 この記事では、システムの特性を示すために「エラー」という言葉を使用し、「誤った使用」という誤った使用を好んでいます。
つまり、ルーラーのエラーは機器の許容範囲に等しく、ストロークをキャンバスに配置します。 誤った使用という意味での間違いは、時計の詳細を測定するときに使用することです。 スチールヤードの過ちは書かれており、約50グラムになります。スチールヤードの誤用は、その上に25 kgのバッグを載せることになり、フックの法則の領域から塑性変形の領域までスプリングが伸びます。 原子間力顕微鏡の誤差は、その離散性に起因します。1つの原子の直径よりも小さいプローブでオブジェクトに「触れる」ことはできません。 しかし、データを誤用したり、データを誤って解釈したりする多くの方法があります。 などなど。
それで、これは統計的方法でどんな種類のエラーを持っていますか? そして、このエラーは正確に悪名高い重要度αです。
第1種および第2種のエラー
統計の数学的装置の間違いは、そのベイズ確率論的本質そのものです。 前回の記事では、統計的方法とは何かについて既に述べました。最大許容確率としての有意水準αの決定は帰無仮説を拒否することは違法であり、研究者による研究者へのこの値の独立した割り当てです。
あなたはすでにこの慣習を見ていますか? 実際、基準方法には、おなじみの数学的厳密さはありません。 数学は確率的特性に基づいて動作します。
そして、ここで、あるコンテキストを別のコンテキストで誤解する可能性がある別のポイントがあります。 確率の概念そのものと、確率の分布で表されるイベントの実際の実装を区別する必要があります。 たとえば、実験を開始する前は、結果としてどの値が得られるかわかりません。 考えられる結果は2つあります。結果の値を推測した後、実際に取得するかどうかを決定します。 両方のイベントの確率は1/2です。 しかし、前の記事で示したガウス曲線は、一致を正しく推測する確率分布を示しています。
これを例で明確に説明できます。 2つのサイコロを600回振ってみましょう-レギュラーとチートです。 次の結果が得られます。

実験の前に、両方の立方体について、どの面の損失も同様に可能性があります-1/6。 しかし、実験後、不正行為キューブの本質が現れ、その上の6個の確率密度は90%と言えます。
化学者、物理学者、および量子効果に興味のある人が知っている別の例は、原子軌道です。 理論的には、電子は宇宙で「スミア」され、ほぼどこにでも配置できます。 しかし実際には、90パーセント以上のケースに該当する領域があります。 電子の確率密度が90%の表面によって形成されるこれらの空間領域は、球、ダンベルなどの形の古典的な原子軌道です。
したがって、重要度のレベルを個別に設定することにより、その名前に記載されているエラーに慎重に同意します。 このため、「完全に信頼できる」と見なせる結果は1つではありません。常に統計的結論には、何らかの失敗の可能性が含まれます。
有意水準αを決定することによって定式化されたエラーは、第1種のエラーと呼ばれます 。 「誤報」、またはより正確には誤検知結果として定義できます。 実際、「帰無仮説を誤って拒否する」という言葉はどういう意味ですか? これは、2つのグループ間の有意差について観測データを誤って取得することを意味します。 病気の存在について誤った診断を下し、実際に存在しない新しい発見を急いで世界に公開するために-これらは第一種のエラーの例です。
しかし、その後、偽陰性の結果があるはずですか? まったくその通りであり、それらは第2種のエラーと呼ばれます。 例には、重要なデータが含まれていますが、研究の結果としてのタイミングの悪い診断または失望があります。 第二種のエラーは、奇妙なことにβという文字で示されます。 しかし、この概念自体は、数値1-βほど統計にとって重要ではありません。 数値1-βは基準の力と呼ばれ、ご想像のとおり、重要なイベントを見逃さない基準の能力を特徴づけます。
ただし、第1種および第2種のエラーの統計的方法の内容は、それらの制限だけではありません。 これらのエラーの概念は、統計分析で直接使用できます。 どうやって?
ROC分析
ROC分析(受信者の動作特性から)は、オブジェクトのバイナリ分類に対する特定の属性の適用可能性を定量化する方法です。 簡単に言えば、病気の人と健康な人、猫と犬、黒と白を区別し、この方法の有効性を確認する方法を考え出すことができます。 もう一度例を見てみましょう。
あなたが新進の法医学者になり、人が犯罪者であるかどうかを慎重かつ明確に決定する新しい方法を開発しましょう。 あなたは定量的な兆候を思いつきました:ミハイル・クリュッグを聞く頻度によって人々の犯罪傾向を評価するために。 しかし、あなたの症状は十分な結果をもたらしますか? 正しくしましょう。
基準を検証するには、一般市民と犯罪者の2つのグループが必要です。 確かに、ミハイル・クリュッグを聴く年平均時間が異なると仮定しましょう(図を参照)。
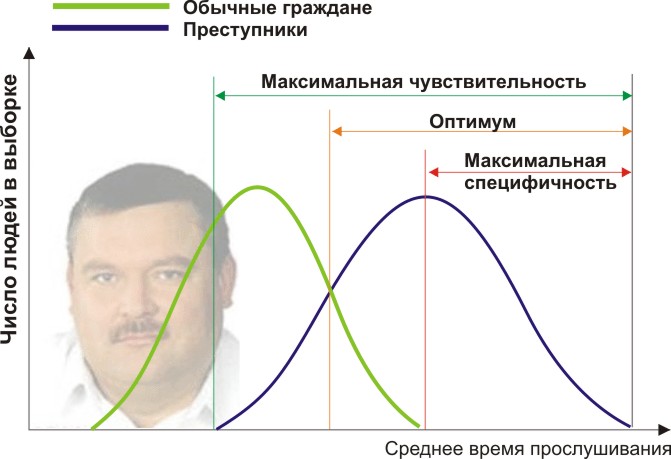
ここでは、リスニング時間の定量的な兆候によって、サンプルが交差していることがわかります。 誰かが犯罪を犯すことなく自発的にラジオでサークルを聴き、誰かが他の音楽を聴いたり、耳が聞こえなくなったりして法律を破ります。 どんな境界条件がありますか? ROC分析では、選択性(感度)と特異性の概念が導入されます。 感度とは、私たちが関心を持っているすべてのポイント(この例では犯罪者)と特異性を特定する能力として定義されます。偽陽性を捕捉しない(普通の住民を疑わない) 最大感度(緑)から最大特異性(赤)までの範囲で、一部を他の一部(オレンジ)から分離する重要な定量的特性を設定できます。
次の図を見てみましょう。

属性の値をシフトすることにより、偽陽性と偽陰性の結果(曲線の下の領域)の比率を変更します。 同様に、Sensitivity = Positionを定義できます。 Res-t /(位置Res-t +偽陰性。Res-t)および特異性=負。 Res-t /(負のRes-t +偽陽性。Res-t)。
しかし最も重要なことは、定量的属性の値の範囲全体にわたって、陽性と偽陽性の比率を評価できることです。これが、望ましいROC曲線です(図を参照)。

そして、このグラフから私たちの属性がどれほど良いかをどのように理解しますか? 非常に簡単に、曲線下面積(AUC、曲線下面積)を計算します。 破線(0,0; 1,1)は、2つのサンプルの完全な一致と完全に無意味な基準を意味します(曲線の下の面積は正方形全体の0.5です)。 しかし、ROC曲線の凸性は、基準の完全性を示しています。 サンプルがまったく交差しないという基準を見つけた場合、曲線の下の領域がグラフ全体を占有します。 一般に、AUC> 0.75-0.8の場合、特性は良好と見なされ、1つのサンプルを別のサンプルから確実に分離できます。
この分析により、さまざまな問題を解決できます。 マイケル・クルーグのせいで疑われている主婦が多すぎると判断し、さらに、Nogganoを聞いている危険な繰り返し犯人が見逃されたので、この基準を拒否して別の基準を開発することができます。
無線信号を処理し、真珠湾攻撃の後に「友人または敵」を識別する方法として登場したため(受信機特性の奇妙な名前)、ROC分析は生物医学統計で広く使用され、バイオマーカーパネルを分析、検証、作成、および特徴付けしましたなど サウンドロジックに基づいている場合は、柔軟に使用できます。 たとえば、非常に具体的な基準を適用し、心臓病の検出効率を高め、医師を不必要な患者で過負荷にしないことにより、退職したコア患者の診察の適応を開発できます。 それどころか、未知のウイルスの危険な流行の際には、ワクチン接種から逃れることができないように、非常に選択的な基準を考え出すことができます。
検証済みの基準の説明で、両方の種類のエラーとそれらの可視性に遭遇しました。 今、これらの論理的基盤から離れて、結果の一連の誤ったステレオタイプの記述を破壊することができます。 いくつかの誤った定式化は、よく似た言葉や概念に混同されたり、誤った解釈にほとんど注意が向けられなかったりすることで混乱することがあります。 これは、おそらく、個別に記述する必要があります。