
私はオペラとバレエが大好きですが、あまり好きではありません-チケットに多額のお金を与えてください。 各ボタンに突くと劇場のウェブサイトを毎日表示するのはひどく面倒で、スーパートレインの170ルーブルのチケットが突然表示されるのは悲痛でした。
このビジネスを自動化するために、ポスターで実行され、選択された月の最も安いチケットに関する情報を収集するスクリプトが登場しました。 シリーズからの要求は、「1000ルーブルまでの新旧ステージで、3月にすべてのオペラのリストを発行します。」 友人が「電報ボットをやっていませんか?」 これは計画に含まれていませんでしたが、そうではありません。 ボットは生まれましたが、自宅のラップトップで回転していました。
その後、Telegramはブロックされました。 ボットを稼働中のサーバーにプッシュするというアイデアは消え去り、機能を頭に入れたいという関心は薄れていきました。 カットの下で、私は最初から安いチケット探偵の運命と1年の使用後に彼に何が起こったのかについて話します。
1.アイデアの起源と問題の説明
最初の制作では、ストーリー全体に1つのタスクがありました。ポスターの各パフォーマンスを個別に手動で表示する時間を節約するために、価格で除外されたパフォーマンスのリストを編集します。 ポスターが興味を持った唯一の劇場は、マリインスキーであり、現在も残っています。 個人的な経験から、予算の「ギャラリー」はランダムなパフォーマンスのためにランダムな日に開かれ、(スタッフが立っている場合)十分な速さで報われることがすぐにわかりました。 何も見逃さないために、自動コレクターが必要です。
手動でナビゲートする必要があったボタン付きのポスターのタイプ 
スクリプトを実行するためのパフォーマンスの限られたセットを取得したかった。 すでに述べたように、主な基準はチケットの価格です。
サイトAPIとチケットシステムは公開されていないため、HTMLページを解析し、必要なタグを引き出すという決定が(苦労せずに)行われました。 メインを開き、F12を押して構造を調べます。 それは十分に見えたので、物事はすぐに最初の実装に達しました。
このアプローチは、ポスターのある他のサイトに拡大縮小できず、現在の構造を変更することを決めた場合に崩れることは明らかです。 読者がAPIなしで安定性を高める方法についてアイデアを持っている場合は、コメントに書いてください。
2.最初の実装。 最低限の機能
機械学習に関連する問題を解決するためだけに、Pythonの経験を持つ実装にアプローチしました。 また、htmlとwebアーキテクチャについての深い理解もありませんでした(そして、それは現れませんでした)。 したがって、すべては「私が行くところ、私は知っているが、今、私たちは行く方法を見つける」という原則に従って行われました
最初のドラフトでは、夕方に4時間、リクエストとBeautiful Soup 4モジュールの紹介が必要でした(著者のおかげで、良い記事の助けが得られました)。 スケッチを仕上げるために-別の日。 モジュールがそのセグメントで最適かどうかは完全にはわかりませんが、現在のニーズは満たされていません。 これが最初の段階で起こったことです。
サイトの構造によって、どの情報とどこを引き出すかを理解できます。 まず、選択した月の投稿者の投稿のアドレスを収集します。
ブラウザのポスターページの構造、すべてが便利に強調表示されます 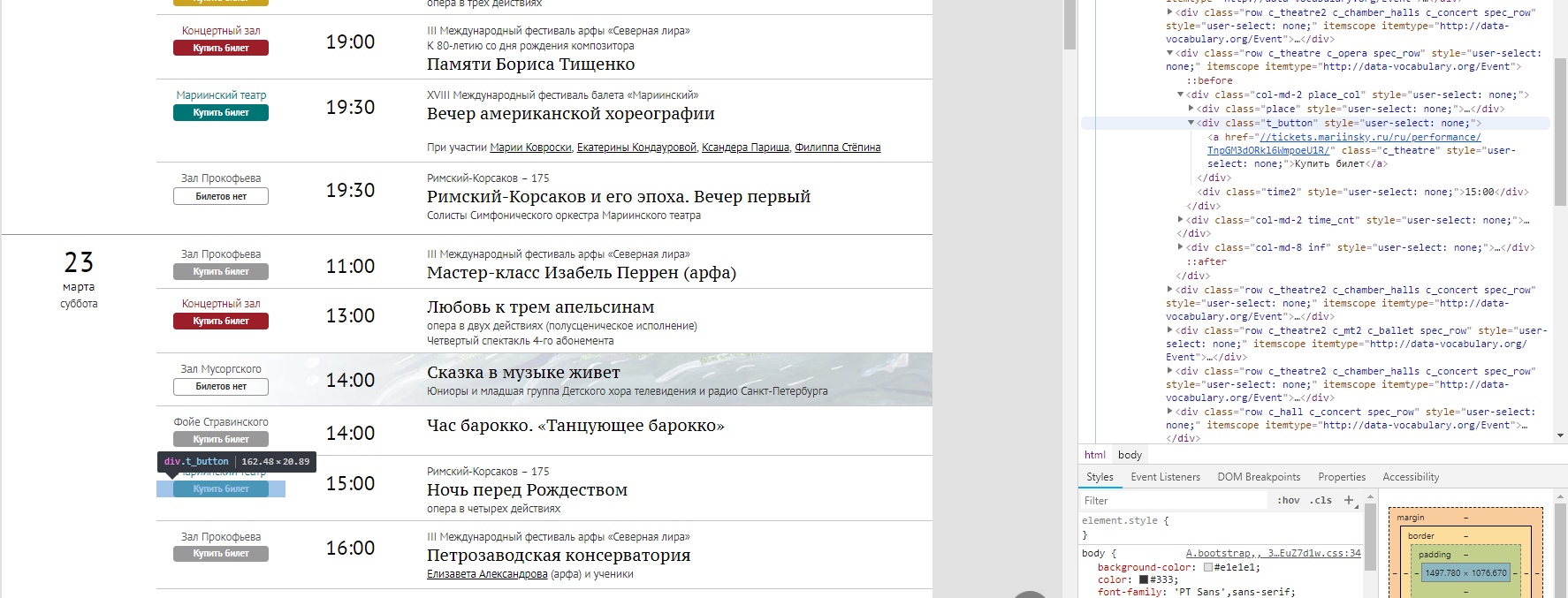
htmlページから、純粋なURLを読み取り、それらを調べて価格タグを確認する必要があります。 これがリンクリストの組み立て方法です。
import requests import numpy as np from bs4 import BeautifulSoup def get_text(url): # URL html r = requests.get(url) text=r.text return text def get_items(text,top_name,class_name): """ html- "" url-, .. - . top_name class_name - <a class="c_theatre2 c_chamber_halls" href="//tickets.mariinsky.ru/ru/performance/WWpGeDRORFUwUkRjME13/"> </a> """ soup = BeautifulSoup(text, "lxml") film_list = soup.find('div', {'class': top_name}) items = film_list.find_all('div', {'class': [class_name]}) dirty_link=[] for item in items: dirty_link.append(str(item.find('a'))) return dirty_link def get_links(dirty_list,start,end): # "" URL- links=[] for row in dirty_list: if row!='None': i_beg=row.find(start) i_end=row.rfind(end) if i_beg!=-1 & i_end!=-1: links.append(row[i_beg:i_end]) return links # , , num=int(input(' : ')) #URL . , =) url ='https://www.mariinsky.ru/ru/playbill/playbill/?year=2019&month='+str(num) # top_name='container content gr_top' class_name='t_button' start='tickets' end='/">' # text=get_text(url) dirty_link=get_items(text,top_name,class_name) # URL-, links=get_links(dirty_link,start,end)
チケットを購入してページの構造を調べた後、価格のしきい値に加えて、ユーザーに次の項目を選択する機会を与えることにしました。
- パフォーマンスの種類(1オペラ、2バレエ、3コンサート、4講義)
- 会場(1古いステージ、2つの新しいステージ、3つのコンサートホール、4室のホール)
情報はコンソールから数値形式で入力され、複数の数字を選択できます。 このような変動は、オペラとバレエの価格の違い(オペラの方が安い)と、それらのリストを別々に見たいという欲求によって決まります。
結果は、 4つの質問と4つのデータフィルター (月、価格のしきい値、種類、場所)です。
次に、受信したすべてのリンクを確認します。 get_textを作成し、低価格を探し、関連情報も引き出します。 各URLを調べてテキストに変換する必要があるという事実により、プログラムの実行時間は瞬時ではありません。 最適化するのは良いことですが、その方法については考えませんでした。
コード自体は引用しませんが、少し長くなりますが、Beautiful Soup 4ではすべてが適切かつ「直感的に」真実です。
価格がユーザーが宣言した価格より低く、タイププレースがセットに対応する場合、パフォーマンスに関するメッセージがコンソールに表示されます。 これをすべて.xlsに保存する別のオプションがありましたが、ルートを取得しませんでした。 ファイルを確認するよりも、コンソールを見てすぐにリンクをたどる方が便利です。

約150行のコードが出てきました。 このバージョンでは、記述されている最小機能により、スクリプトはすべての生きているスクリプトよりも活発で、数日間定期的に実行されます。 他のすべての変更はドープされていないか(千枚通しが死んだ)、そのため非アクティブであるか、機能上これ以上有利ではありません。
3.機能の拡張
第二段階では、関心のあるパフォーマンスへのリンクを別のファイル(より正確には、それらへのURL)に保存して、価格の変化を追跡することにしました。 まず第一に、これはバレエに関係します-彼らはめったに非常に安価ではなく、彼らは一般的な予算の問題に含まれません。 しかし、特にパフォーマンスが恒星のキャストである場合、5000から2倍への低下は重要であり、私はそれを追跡したいと考えました。
これを行うには、最初に追跡用のURLを追加してから、定期的にそれらを「シェイク」し、新しい価格と古い価格を比較する必要があります。
def add_new_URL(user_id,perf_url): #user_id , - WAITING_FILE = "waiting_list.csv" with open(WAITING_FILE, "a", newline="") as file: curent_url='https://'+perf_url text=get_text(curent_url) # - , ,, minP, name,date,typ,place=find_lowest(text) user = [str(user_id), perf_url,str(m)] writer = csv.writer(file) writer.writerow(user) def update_prices(): # print(' ') WAITING_FILE = "waiting_list.csv" with open(WAITING_FILE, "r", newline="") as file: reader = csv.reader(file) gen=[] for row in reader: gen.append(list(row)) L=len(gen) lowest={} with open(WAITING_FILE, "w", newline="") as fl: writer = csv.writer(fl) for i in range(L): lowest[gen[i][1]]=gen[i][2] # URL for k in lowest.keys(): text=get_text('https://'+k) minP, name,date,typ,place=find_lowest(text) if minP==0: # , "" minP=100000 if int(minP)<int(lowest[k]): # , lowest[k]=minP for i in range(L): if gen[i][1]==k: # - URL gen[i][2]=str(minP) print(' '+k+' '+str(minP)) writer.writerows(gen) add_new_URL('12345','tickets.mariinsky.ru/ru/performance/ZVRGZnRNbmd3VERsNU1R/') update_prices()
価格の更新は、メインスクリプトの冒頭に開始され、個別に実行されませんでした。 私たちが望むほどエレガントではないかもしれませんが、それはその問題を解決します。 そのため、2番目の追加機能は、対象となるパフォーマンスの価格低下を監視することでした。
その後、Telegramボットが誕生しました。それほど簡単ではなく、速く、元気がありますが、まだ生まれています。 すべてをまとめないために、彼についての物語(未実現のアイデアとボリショイ劇場のウェブサイトでこれを行う試みについて)は記事の第2部にあります。
結果:アイデアは成功し、ユーザーは満足しています。 htmlページを操作する方法を理解するのに数週間かかりました。 幸いなことに、Pythonはほぼすべての言語に対応した既製のモジュールであるため、ハンマーの物理的性質を考慮することなく釘を打つことができます。
この事件がHabrachiansに役立つことを願っています。そしておそらく、魔法のペンデルのように働き、最終的に私の頭に長く座ってほしいと思うウィッシュリストを作ります。
UPD: ストーリーの継続-パート2