」のシーン")
映画「The Loop of Time」のシーン(2012)
マルチスレッドは、プログラミング、特にC ++で最も難しい分野の1つです。 開発の長年にわたって、私は多くのミスを犯しました。 幸いなことに、それらのほとんどはレビューコードとテストによって特定されました。 しかし、なんらかの方法で生産性が低下し、オペレーティングシステムを編集する必要がありました。これは常に高価です。
この記事では、知っているすべてのエラーを可能な解決策で分類しようとしました。 他の落とし穴に気付いている場合、または説明されているエラーを解決するための提案がある場合は、記事の下にコメントを残してください。
間違い#1:アプリケーションを終了する前にjoin()を使用してバックグラウンドスレッドを待機しない
プログラムが終了する前にストリームのアタッチ( join() )またはデタッチ ( detach() )( ジョインできないようにする)を忘れると、クラッシュにつながります。 (翻訳には、 join()のコンテキストでjoinという単語が含まれ、 detach()のコンテキストでdetachが含まれますが、これは完全に正しいわけではありません。実際、 join()は、実行のスレッドが別のスレッドの完了を待機し、接続またはスレッドのマージが発生しないポイントです[コメント翻訳者])。
以下の例では、メインスレッドでスレッドt1のjoin()を実行するのを忘れていました。
#include "stdafx.h"
#include <iostream>
#include <thread>
using namespace std ;
void LaunchRocket ( )
{
cout << "Launching Rocket" << endl ;
}
int main ( )
{
thread t1 ( LaunchRocket ) ;
//t1.join(); // join-
return 0 ;
}
なぜプログラムがクラッシュしたのですか?! main()関数の最後で、変数t1がスコープ外になり、スレッドデストラクタが呼び出されたためです。 デストラクタは、スレッドt1が参加可能かどうかをチェックします。 スレッドは、切り離されていなければ参加可能です。 この場合、 std :: terminateはデストラクタで呼び出されます。 たとえば、MSVC ++コンパイラの機能は次のとおりです。
~thread ( ) _NOEXCEPT
{ // clean up
if ( joinable ( ) )
XSTD terminate ( ) ;
}
タスクに応じて、問題を修正する2つの方法があります。
1.メインスレッドでスレッドt1のjoin()を呼び出します。
int main ( )
{
thread t1 ( LaunchRocket ) ;
t1. join ( ) ; // join t1,
return 0 ;
}
2.メインストリームからストリームt1を切り離し、「悪魔化された」ストリームとして動作し続けるようにします。
int main ( )
{
thread t1 ( LaunchRocket ) ;
t1. detach ( ) ; // t1
return 0 ;
}
間違い2:以前に切り離されたスレッドを接続しようとする
プログラムの動作中にデタッチストリームがある場合、メインストリームにアタッチすることはできません。 これは非常に明らかな間違いです。 問題は、ストリームの固定を解除してから、数百行のコードを記述して再アタッチできることです。 結局、300行を書き戻したことを覚えている人はいますか?
問題は、これによりコンパイルエラーが発生せず、代わりにプログラムが起動時にクラッシュすることです。 例:
#include "stdafx.h"
#include <iostream>
#include <thread>
using namespace std ;
void LaunchRocket ( )
{
cout << "Launching Rocket" << endl ;
}
int main ( )
{
thread t1 ( LaunchRocket ) ;
t1. detach ( ) ;
//..... 100 -
t1. join ( ) ; // CRASH !!!
return 0 ;
}
解決策は、スレッドを呼び出しスレッドにアタッチする前に、常にスレッドのjoinable()をチェックすることです。
int main ( )
{
thread t1 ( LaunchRocket ) ;
t1. detach ( ) ;
//..... 100 -
if ( t1. joinable ( ) )
{
t1. join ( ) ;
}
return 0 ;
}
間違い#3:std :: thread :: join()は実行の呼び出しスレッドをブロックするという誤解
実際のアプリケーションでは、多くの場合、ネットワークI / Oの処理やユーザーがボタンをクリックするのを待つなどの「長時間にわたる」操作を分離する必要があります。 このようなワークフロー(UIレンダリングスレッドなど)のjoin()を呼び出すと、ユーザーインターフェイスがハングする場合があります。 より適切な実装方法があります。
たとえば、GUIアプリケーションでは、ワーカースレッドが完了すると、UIスレッドにメッセージを送信できます。 UIストリームには、マウスの移動、キーの押下などの独自のイベント処理ループがあります。 このループは、ワーカースレッドからメッセージを受信し、ブロッキングjoin()メソッドを呼び出すことなくメッセージに応答することもできます。
このまさに理由で、MicrosoftのWinRTプラットフォームでのほとんどすべてのユーザーインタラクションは非同期になり、同期の代替は利用できません。 これらの決定は、開発者が可能な限り最高のエンドユーザーエクスペリエンスを提供するAPIを使用するようにするために行われました。 このトピックの詳細については、「 Modern C ++ and Windows Store Apps 」マニュアルを参照してください。
間違い4:ストリーム関数の引数がデフォルトで参照によって渡されると仮定する
ストリーム関数への引数はデフォルトで値で渡されます。 渡された引数に変更を加える必要がある場合は、 std :: ref()関数を使用して参照で渡す必要があります。
ネタバレの下で、 Q&A-スレッド管理の基本(Deb Haldar)を介した別のC ++ 11マルチスレッドチュートリアルの例は、パラメーターの受け渡しを示しています[約。 翻訳者]。
詳細:
コードを実行するとき:
ターミナルに表示されます:
ご覧のとおり、参照によってストリームで呼び出された関数が受け取るtargetCity変数の値は変更されていません。
引数を渡すには、 std :: ref()を使用してコードを書き換えます。
出力されます:
新しいスレッドで行われた変更は、 main関数で宣言および初期化されたtargetCity変数の値に影響します。
#include "stdafx.h"
#include <string>
#include <thread>
#include <iostream>
#include <functional>
using namespace std ;
void ChangeCurrentMissileTarget ( string & targetCity )
{
targetCity = "Metropolis" ;
cout << " Changing The Target City To " << targetCity << endl ;
}
int main ( )
{
string targetCity = "Star City" ;
thread t1 ( ChangeCurrentMissileTarget, targetCity ) ;
t1. join ( ) ;
cout << "Current Target City is " << targetCity << endl ;
return 0 ;
}
ターミナルに表示されます:
Changing The Target City To Metropolis
Current Target City is Star City
ご覧のとおり、参照によってストリームで呼び出された関数が受け取るtargetCity変数の値は変更されていません。
引数を渡すには、 std :: ref()を使用してコードを書き換えます。
#include "stdafx.h"
#include <string>
#include <thread>
#include <iostream>
#include <functional>
using namespace std ;
void ChangeCurrentMissileTarget ( string & targetCity )
{
targetCity = "Metropolis" ;
cout << " Changing The Target City To " << targetCity << endl ;
}
int main ( )
{
string targetCity = "Star City" ;
thread t1 ( ChangeCurrentMissileTarget, std :: ref ( targetCity ) ) ;
t1. join ( ) ;
cout << "Current Target City is " << targetCity << endl ;
return 0 ;
}
出力されます:
Changing The Target City To Metropolis
Current Target City is Metropolis
新しいスレッドで行われた変更は、 main関数で宣言および初期化されたtargetCity変数の値に影響します。
間違い5:クリティカルセクション(ミューテックスなど)を使用して共有データとリソースを保護しない
マルチスレッド環境では、通常、複数のスレッドがリソースと共有データを奪い合います。 多くの場合、リソースとデータへのアクセスが不確実な状態になります。ただし、それらのアクセスは、いつでも1つの実行スレッドのみがそれらの操作を実行できるメカニズムによって保護されている場合を除きます。
以下の例では、 std :: coutは6つのスレッドが動作する共有リソースです(t1-t5 + main)。
#include "stdafx.h"
#include <iostream>
#include <string>
#include <thread>
#include <mutex>
using namespace std ;
std :: mutex mu ;
void CallHome ( string message )
{
cout << "Thread " << this_thread :: get_id ( ) << " says " << message << endl ;
}
int main ( )
{
thread t1 ( CallHome, "Hello from Jupiter" ) ;
thread t2 ( CallHome, "Hello from Pluto" ) ;
thread t3 ( CallHome, "Hello from Moon" ) ;
CallHome ( "Hello from Main/Earth" ) ;
thread t4 ( CallHome, "Hello from Uranus" ) ;
thread t5 ( CallHome, "Hello from Neptune" ) ;
t1. join ( ) ;
t2. join ( ) ;
t3. join ( ) ;
t4. join ( ) ;
t5. join ( ) ;
return 0 ;
}
このプログラムを実行すると、結論が得られます。
Thread 0x1000fb5c0 says Hello from Main/Earth
Thread Thread Thread 0x700005bd20000x700005b4f000 says says Thread Thread Hello from Pluto0x700005c55000Hello from Jupiter says 0x700005d5b000Hello from Moon
0x700005cd8000 says says Hello from Uranus
Hello from Neptune
これは、5つのスレッドがランダムな順序で同時に出力ストリームにアクセスしているためです。 結論をより具体的にするには、 std :: mutexを使用して共有リソースへのアクセスを保護する必要があります。 CallHome()関数を変更するだけで、 std :: coutを使用する前にミューテックスをキャプチャし、その後解放します。
void CallHome ( string message )
{
mu. lock ( ) ;
cout << "Thread " << this_thread :: get_id ( ) << " says " << message << endl ;
mu. unlock ( ) ;
}
間違い6:クリティカルセクションを終了した後にロックを解除するのを忘れる
前のパラグラフでは、クリティカルセクションをミューテックスで保護する方法を見ました。 ただし、mutexでlock()およびunlock()メソッドを直接呼び出すことは、保持されたロックの付与を忘れる可能性があるため、推奨されるオプションではありません。 次に何が起こりますか? リソースの解放を待機している他のすべてのスレッドは無限にブロックされ、プログラムがハングする可能性があります。
合成例では、 CallHome()関数呼び出しでミューテックスをロック解除するのを忘れた場合、ストリームt1からの最初のメッセージが標準ストリームに出力され、プログラムがクラッシュします。 これは、スレッドt1がミューテックスロックを受信し、残りのスレッドがこのロックが解除されるのを待つためです。
void CallHome ( string message )
{
mu. lock ( ) ;
cout << "Thread " << this_thread :: get_id ( ) << " says " << message << endl ;
//mu.unlock();
}
以下はこのコードの出力です-プログラムがクラッシュし、端末に唯一のメッセージが表示され、終了しませんでした:
Thread 0x700005986000 says Hello from Pluto
このようなエラーは頻繁に発生するため、mutexから直接lock()/ unlock()メソッドを使用することは望ましくありません。 代わりに、 RADイディオムを使用してロックの有効期間を制御するstd :: lock_guardテンプレートクラスを使用します。 lock_guardオブジェクトが作成されると、mutexを引き継ごうとします。 プログラムがlock_guardオブジェクトのスコープを出ると、デストラクタが呼び出され、ミューテックスが解放されます。
std :: lock_guardオブジェクトを使用して、 CallHome()関数を書き換えます。
void CallHome ( string message )
{
std :: lock_guard < std :: mutex > lock ( mu ) ; //
cout << "Thread " << this_thread :: get_id ( ) << " says " << message << endl ;
} // lock_guard
間違い7:クリティカルセクションのサイズを必要以上に大きくする
1つのスレッドがクリティカルセクション内で実行されると、それを入力しようとする他のすべてのスレッドは基本的にブロックされます。 クリティカルセクションにはできるだけ少ない指示を保持する必要があります。 説明のために、大きなクリティカルセクションを持つ不正なコードの例を示します。
void CallHome ( string message )
{
std :: lock_guard < std :: mutex > lock ( mu ) ; // , std::cout
ReadFifyThousandRecords ( ) ;
cout << "Thread " << this_thread :: get_id ( ) << " says " << message << endl ;
} // lock_guard mu
ReadFifyThousandRecords()メソッドはデータを変更しません。 ロックされた状態で実行する理由はありません。 このメソッドが10秒間実行され、データベースから5万行が読み取られると、他のすべてのスレッドがこの期間全体にわたって不必要にブロックされます。 これは、プログラムのパフォーマンスに深刻な影響を与える可能性があります。
正しい解決策は、クリティカルセクションでstd :: coutのみを使用し続けることです。
void CallHome ( string message )
{
ReadFifyThousandRecords ( ) ; // ..
std :: lock_guard < std :: mutex > lock ( mu ) ; // , std::cout
cout << "Thread " << this_thread :: get_id ( ) << " says " << message << endl ;
} // lock_guard mu
間違い8:複数のロックを異なる順序で取得する
これは、 デッドロックの最も一般的な原因の1つであり、他のスレッドによってブロックされたリソースへのアクセスを待機しているためにスレッドが無限にブロックされる状況です。 例を考えてみましょう:
| ストリーム1 | ストリーム2 |
|---|---|
| ロックA | ロックB |
| // ...一部の操作 | // ...一部の操作 |
| ロックB | ロックA |
| // ...その他の操作 | // ...その他の操作 |
| Bのロックを解除 | Aのロックを解除 |
| Aのロックを解除 | Bのロックを解除 |
スレッド1がBをロックしようとして、スレッド2がすでにBをロックしているためにブロックされる状況が発生する場合があります。 同時に、2番目のスレッドはロックAをキャプチャしようとしていますが、最初のスレッドによってキャプチャされたため、ロックAをキャプチャできません。 スレッド1は、BをロックするまでロックAを解放できません。 つまり、プログラムがフリーズします。
このコード例は、 デッドロックの再現に役立ちます。
#include "stdafx.h"
#include <iostream>
#include <string>
#include <thread>
#include <mutex>
using namespace std ;
std :: mutex muA ;
std :: mutex muB ;
void CallHome_Th1 ( string message )
{
muA. lock ( ) ;
// -
std :: this_thread :: sleep_for ( std :: chrono :: milliseconds ( 100 ) ) ;
muB. lock ( ) ;
cout << "Thread " << this_thread :: get_id ( ) << " says " << message << endl ;
muB. unlock ( ) ;
muA. unlock ( ) ;
}
void CallHome_Th2 ( string message )
{
muB. lock ( ) ;
// -
std :: this_thread :: sleep_for ( std :: chrono :: milliseconds ( 100 ) ) ;
muA. lock ( ) ;
cout << "Thread " << this_thread :: get_id ( ) << " says " << message << endl ;
muA. unlock ( ) ;
muB. unlock ( ) ;
}
int main ( )
{
thread t1 ( CallHome_Th1, "Hello from Jupiter" ) ;
thread t2 ( CallHome_Th2, "Hello from Pluto" ) ;
t1. join ( ) ;
t2. join ( ) ;
return 0 ;
}
このコードを実行すると、クラッシュします。 スレッドウィンドウでデバッガをさらに深く見ると、最初のスレッド( CallHome_Th1()から呼び出される)がmutex Bロックを取得しようとしているのに対し、スレッド2( CallHome_Th2()から呼び出される)はmutex Aをブロックしようとしていることがわかります。成功できず、デッドロックが発生します!
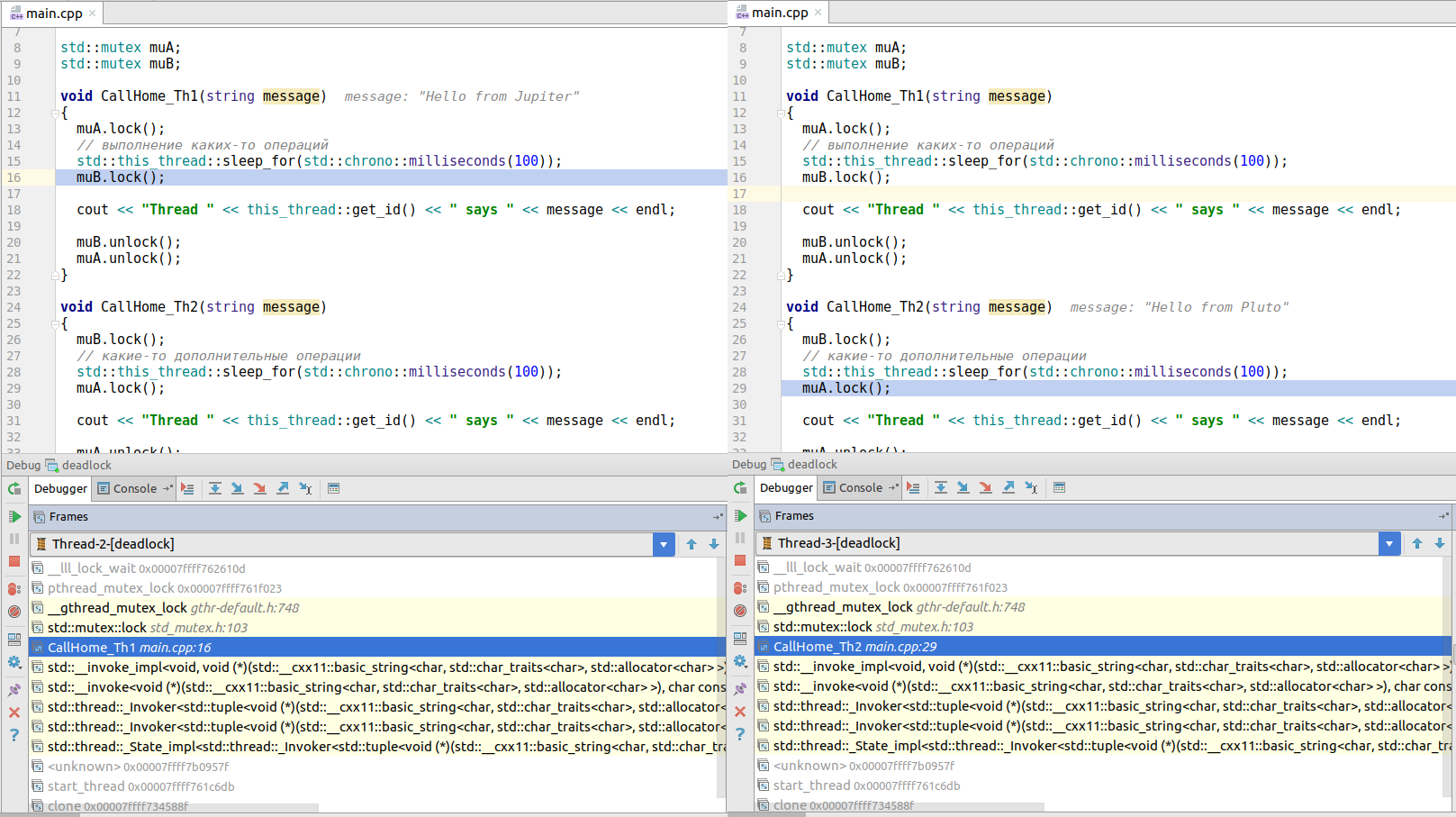
(写真はクリック可能です)
あなたはそれについて何ができますか? 最良の解決策は、ロックロックが毎回同じ順序で発生するようにコードを再構築することです。
状況に応じて、他の戦略を使用できます。
1.ラッパークラスstd :: scoped_lockを使用して、複数のロックを共同でキャプチャします。
std :: scoped_lock lock { muA, muB } ;
2.クラスstd :: timed_mutexを使用します。このクラスでは、タイムアウトを指定できます。その後、リソースが使用できなくなった場合にロックが解除されます。
std :: timed_mutex m ;
void DoSome ( ) {
std :: chrono :: milliseconds timeout ( 100 ) ;
while ( true ) {
if ( m. try_lock_for ( timeout ) ) {
std :: cout << std :: this_thread :: get_id ( ) << ": acquire mutex successfully" << std :: endl ;
m. unlock ( ) ;
} else {
std :: cout << std :: this_thread :: get_id ( ) << ": can't acquire mutex, do something else" << std :: endl ;
}
}
}
間違い9:stdを二重にキャプチャしようとする:: mutexロック
ロックを2回ロックしようとすると、未定義の動作が発生します。 ほとんどのデバッグ実装では、これはクラッシュします。 たとえば、次のコードでは、 LaunchRocket()は mutex をロックしてからStartThruster()を呼び出します。 不思議なことに、上記のコードでは、プログラムの通常の動作中にこの問題は発生しません。問題は例外がスローされたときにのみ発生し、未定義の動作またはプログラムの異常終了を伴います。
#include "stdafx.h"
#include <iostream>
#include <thread>
#include <mutex>
std :: mutex mu ;
static int counter = 0 ;
void StartThruster ( )
{
try
{
// -
}
catch ( ... )
{
std :: lock_guard < std :: mutex > lock ( mu ) ;
std :: cout << "Launching rocket" << std :: endl ;
}
}
void LaunchRocket ( )
{
std :: lock_guard < std :: mutex > lock ( mu ) ;
counter ++ ;
StartThruster ( ) ;
}
int main ( )
{
std :: thread t1 ( LaunchRocket ) ;
t1. join ( ) ;
return 0 ;
}
この問題を解決するには、以前に受信したロックの再取得を防ぐようにコードを修正する必要があります。 std :: recursive_mutexを松葉杖のソリューションとして使用できますが、そのようなソリューションはほとんどの場合、プログラムのアーキテクチャが貧弱であることを示しています。
間違い10:std ::原子型で十分な場合にmutexを使用する
ブール値や整数カウンターなどの単純なデータ型を変更する必要がある場合、 std:atomicを使用すると、一般にミューテックスを使用するよりもパフォーマンスが向上します。
たとえば、次の構成を使用する代わりに:
int counter ;
...
mu. lock ( ) ;
counter ++ ;
mu. unlock ( ) ;
変数をstd :: atomicとして宣言することをお勧めします。
std :: atomic < int > counter ;
...
counter ++ ;
ミューテックスとアトミックの詳細な比較については、記事「比較:C ++ 11 vs. ミューテックスとRWロック»
間違い11:空きスレッドのプールを使用する代わりに、多数のスレッドを直接作成および破棄する
スレッドの作成と破棄は、プロセッサ時間の観点からすると高価な操作です。 システムが計算負荷の高い操作、たとえばグラフィックスのレンダリングやゲーム物理学の計算を実行している間にストリームを作成しようとすることを想像してください。 このようなタスクによく使用されるアプローチは、プロセスのライフサイクル全体を通してディスクへの書き込みやネットワーク経由のデータ送信などのルーチンタスクを処理できる事前割り当てスレッドのプールを作成することです。
自分でスレッドを生成および破棄することと比較したスレッドプールのもう1つの利点は、スレッドのオーバーサブスクリプション (スレッドの数が使用可能なコアの数を超え、プロセッサー時間のかなりの部分がコンテキストの切り替えに費やされる状況を心配する必要がないことです)翻訳者])。 これは、システムのパフォーマンスに影響を与える可能性があります。
さらに、プールを使用すると、スレッドのライフサイクルを管理する手間が省け、最終的にエラーの少ないよりコンパクトなコードになります。
スレッドプールを実装する2つの最も一般的なライブラリは、 Intelスレッドビルディングブロック(TBB)とMicrosoft Parallel Patterns Library(PPL)です。
エラー12:バックグラウンドスレッドで発生する例外を処理しない
あるスレッドでスローされた例外を別のスレッドで処理することはできません。 例外をスローする関数があると想像してみましょう。 メインの実行スレッドから分岐した別のスレッドでこの関数を実行し、追加のスレッドからスローされた例外をキャッチすると予想される場合、これは機能しません。 例を考えてみましょう:
#include "stdafx.h"
#include<iostream>
#include<thread>
#include<exception>
#include<stdexcept>
static std :: exception_ptr teptr = nullptr ;
void LaunchRocket ( )
{
throw std :: runtime_error ( "Catch me in MAIN" ) ;
}
int main ( )
{
try
{
std :: thread t1 ( LaunchRocket ) ;
t1. join ( ) ;
}
catch ( const std :: exception & ex )
{
std :: cout << "Thread exited with exception: " << ex. what ( ) << " \n " ;
}
return 0 ;
}
このプログラムが実行されるとクラッシュしますが、main()関数のcatchブロックは実行されず、スレッドt1でスローされた例外を処理しません。
この問題の解決策は、C ++ 11の機能を使用することです。std:: exception_ptrを使用して、バックグラウンドスレッドでスローされた例外を処理します。 実行する必要がある手順は次のとおりです。
- nullptrに初期化されたstd :: exception_ptrクラスのグローバルインスタンスを作成する
- 別のスレッドで実行される関数内で、すべての例外を処理し、前の手順で宣言されたグローバル変数std :: exception_ptrの値std :: current_exception()を設定します
- メインスレッド内のグローバル変数の値を確認する
- 値が設定されている場合は、 std :: rethrow_exception(exception_ptr p)関数を使用して、以前にキャッチした例外を再度呼び出し、参照としてパラメーターとして渡します
参照による例外の呼び出しは、それが作成されたスレッドでは発生しないため、この機能は異なるスレッドで例外を処理するのに最適です。
以下のコードでは、バックグラウンドスレッドでスローされた例外を安全に処理できます。
#include "stdafx.h"
#include<iostream>
#include<thread>
#include<exception>
#include<stdexcept>
static std :: exception_ptr globalExceptionPtr = nullptr ;
void LaunchRocket ( )
{
try
{
std :: this_thread :: sleep_for ( std :: chrono :: milliseconds ( 100 ) ) ;
throw std :: runtime_error ( "Catch me in MAIN" ) ;
}
catch ( ... )
{
//
globalExceptionPtr = std :: current_exception ( ) ;
}
}
int main ( )
{
std :: thread t1 ( LaunchRocket ) ;
t1. join ( ) ;
if ( globalExceptionPtr )
{
try
{
std :: rethrow_exception ( globalExceptionPtr ) ;
}
catch ( const std :: exception & ex )
{
std :: cout << "Thread exited with exception: " << ex. what ( ) << " \n " ;
}
}
return 0 ;
}
間違い13:std :: asyncを使用する代わりに、スレッドを使用して非同期操作をシミュレートする
非同期に実行するコードが必要な場合、つまり メインスレッドの実行をブロックせずに、 std :: async()を使用するのが最良の選択です。 これは、ストリームを作成し、関数ラムダの形式の関数またはパラメーターへのポインターを介してこのストリームに実行するために必要なコードを渡すことと同等です。 ただし、後者の場合、このスレッドで発生する可能性のあるすべての例外の処理と同様に、このスレッドの作成、接続/切断を監視する必要があります。 std :: async()を使用すると、これらの問題から解放され、 デッドロック状態になる可能性が大幅に減少します。
std :: asyncを使用するもう1つの重要な利点は、 std :: futureオブジェクトを使用して、呼び出し元のスレッドに非同期操作の結果を取得できることです。 intを返すConjureMagic()関数があるとします。 タスクが完了すると、 未来のオブジェクトに将来の値を設定する非同期操作を開始でき、操作の呼び出し元の実行フローでこのオブジェクトから実行結果を抽出できます。
// future
std :: future asyncResult2 = std :: async ( & ConjureMagic ) ;
//... - future
// future
int v = asyncResult2. get ( ) ;
実行中のスレッドから呼び出し元に結果を取得することは、より面倒です。 次の2つの方法が可能です。
- 出力変数への参照を、結果を保存するストリームに渡します。
- 結果をワークフローオブジェクトのフィールド変数に保存します。この変数は、スレッドの実行が完了するとすぐに読み取ることができます。
Kurt Guntherothは、パフォーマンスの観点から、ストリームを作成するオーバーヘッドがasyncを使用するオーバーヘッドの14倍であることを発見しました。
結論: std :: threadを直接使用することを支持する強力な引数が見つかるまで、デフォルトでstd :: async()を使用します。
エラー14:非同期が必要な場合は、std :: launch :: asyncを使用しないでください
std :: async()関数は、デフォルトでは非同期に実行されない可能性があるため、完全に正しいわけではありません!
2つのstd ::非同期ランタイムポリシーがあります。
- std :: launch :: async :渡された関数は別のスレッドですぐに実行を開始します
- std :: launch :: deferred :渡された関数はすぐには開始されず、 std :: futureオブジェクトでget()またはwait()呼び出しが行われる前にその起動が遅延され、 std :: async呼び出しから返されます。 これらのメソッドが呼び出される場所で、関数は同期的に実行されます。
デフォルトのパラメーターを指定してstd :: async()を呼び出すと、これら2つのパラメーターの組み合わせで開始され、実際には予測できない動作が発生します。 デフォルトの起動ポリシーでstd:async()を使用することには、他にも多くの困難が伴います。
- ローカルフロー変数への正しいアクセスを予測できない
- get()およびwait()メソッドの呼び出しはプログラム実行中に呼び出されない可能性があるため、非同期タスクはまったく開始されない可能性があります
- 終了条件がstd :: futureオブジェクトの準備ができていることを期待するループで使用される場合、これらのループは終了しない可能性があります。
これらのすべての問題を回避するには、 常に std :: launch :: async launchポリシーでstd :: asyncを呼び出します。
これをしないでください:
// myFunction std::async
auto myFuture = std :: async ( myFunction ) ;
代わりに、これを行います:
// myFunction
auto myFuture = std :: async ( std :: launch :: async , myFunction ) ;
この点については、スコット・マイヤーズの著書「Effective and Modern C ++」でさらに詳しく検討されています。
間違い15:stdのget()メソッドの呼び出し::実行時間が重要なコードブロック内のfutureオブジェクト
以下のコードは、非同期操作のstd :: futureオブジェクトから取得した結果を処理します。 ただし、 whileループは、非同期操作が完了するまでロックされます (この場合、10秒間)。 このループを使用して画面に情報を表示する場合、ユーザーインターフェイスのレンダリングに不快な遅延が発生する可能性があります。
#include "stdafx.h"
#include <future>
#include <iostream>
int main ( )
{
std :: future < int > myFuture = std :: async ( std :: launch :: async , [ ] ( )
{
std :: this_thread :: sleep_for ( std :: chrono :: seconds ( 10 ) ) ;
return 8 ;
} ) ;
//
while ( true )
{
//
std :: cout << "Rendering Data" << std :: endl ;
int val = myFuture. get ( ) ; // 10
// - Val
}
return 0 ;
}
注 :上記のコードのもう1つの問題は、 std :: futureオブジェクトの状態がループの最初の反復で取得され、取得できなかったにもかかわらず、 std :: futureオブジェクトに2回アクセスしようとすることです。
正しい解決策は、 get()メソッドを呼び出す前に、 std :: futureオブジェクトの有効性をチェックすることです。 したがって、非同期タスクの完了をブロックせず、既に抽出されたstd :: futureオブジェクトに問い合わせようとしません。
このコードスニペットを使用すると、これを実現できます。
#include "stdafx.h"
#include <future>
#include <iostream>
int main ( )
{
std :: future < int > myFuture = std :: async ( std :: launch :: async , [ ] ( )
{
std :: this_thread :: sleep_for ( std :: chrono :: seconds ( 10 ) ) ;
return 8 ;
} ) ;
//
while ( true )
{
//
std :: cout << "Rendering Data" << std :: endl ;
if ( myFuture. valid ( ) )
{
int val = myFuture. get ( ) ; // 10
// - Val
}
}
return 0 ;
}
№16: , , , std::future::get()
次のコードフラグメントがあると想像してください。std:: future :: get()を呼び出した結果はどうなると思いますか?プログラムがクラッシュすると思われる場合-あなたは絶対に正しいです!非同期操作でスローされる例外は、std :: futureオブジェクトでget()メソッドが呼び出された場合にのみスローされます。また、get()メソッドが呼び出されない場合、std :: futureオブジェクトがスコープ外になると、例外は無視されてスローされます。あなたの非同期操作が例外を投げることができる場合は、いつでもコールラップする必要があるのstd ::未来:: GET()内のtry / catchのブロックを。これがどのように見えるかの例:
#include "stdafx.h"
#include <future>
#include <iostream>
int main ( )
{
std :: future < int > myFuture = std :: async ( std :: launch :: async , [ ] ( )
{
throw std :: runtime_error ( "Catch me in MAIN" ) ;
return 8 ;
} ) ;
if ( myFuture. valid ( ) )
{
int result = myFuture. get ( ) ;
}
return 0 ;
}
#include "stdafx.h"
#include <future>
#include <iostream>
int main ( )
{
std :: future < int > myFuture = std :: async ( std :: launch :: async , [ ] ( )
{
throw std :: runtime_error ( "Catch me in MAIN" ) ;
return 8 ;
} ) ;
if ( myFuture. valid ( ) )
{
try
{
int result = myFuture. get ( ) ;
}
catch ( const std :: runtime_error & e )
{
std :: cout << "Async task threw exception: " << e. what ( ) << std :: endl ;
}
}
return 0 ;
}
№17: std::async,
がのstd ::非同期()は、ほとんどのケースで十分です、あなたは、ストリームであなたのコードの実行上の注意深い監視が必要な可能性のある状況があります。たとえば、特定のスレッドをマルチプロセッサシステム(Xboxなど)の特定のプロセッサコアにバインドする場合。
指定されたコードフラグメントは、システム内の5番目のプロセッサコアへのスレッドのバインドを確立します。これは、std :: threadオブジェクトのnative_handle()メソッドと、Win32 APIストリーム関数に渡すことで可能です。ストリーミングWin32 APIには、std :: threadまたはstd :: async()で利用できない機能が他にもたくさんあります。作業するとき
#include "stdafx.h"
#include <windows.h>
#include <iostream>
#include <thread>
using namespace std ;
void LaunchRocket ( )
{
cout << "Launching Rocket" << endl ;
}
int main ( )
{
thread t1 ( LaunchRocket ) ;
DWORD result = :: SetThreadIdealProcessor ( t1. native_handle ( ) , 5 ) ;
t1. join ( ) ;
return 0 ;
}
std :: async()、これらの基本的なプラットフォーム関数は使用できないため、このメソッドはより複雑なタスクには適していません。
別の方法は、std :: packaged_taskを作成し、スレッドのプロパティを設定した後、目的の実行スレッドに移動することです。
間違い18:コアが利用できるよりもはるかに多くの「実行中の」スレッドを作成する
アーキテクチャの観点から、フローは「実行中」と「待機中」の2つのグループに分類できます。
実行中のスレッドは、実行中のカーネルのプロセッサ時間の100%を利用します。複数の実行中のスレッドが1つのコアに割り当てられると、CPU使用効率が低下します。 1つのプロセッサコアで複数の実行中のスレッドを実行してもパフォーマンスは向上しません。実際、追加のコンテキスト切り替えによりパフォーマンスが低下します。
待機スレッドは、システムイベントやネットワークI / Oなどを待機している間に実行される数クロックサイクルのみを使用します。この場合、カーネルの利用可能なプロセッサー時間のほとんどは未使用のままです。 1つの待機スレッドはデータを処理でき、他のスレッドはイベントのトリガーを待機しています。これが、複数の待機スレッドを1つのコアに分散することが有利な理由です。コアごとに複数の保留中のスレッドをスケジュールすると、プログラムのパフォーマンスが大幅に向上します。
それでは、システムがサポートする実行中のスレッドの数をどのように理解するのでしょうか?std :: thread :: hardware_concurrency()メソッドを使用します。通常、この関数はプロセッサコアの数を返しますが、2つ以上の論理コアのように動作するコアを考慮に入れますgipertredinga。
ターゲットプラットフォームの取得値を使用して、プログラムで同時に実行されるスレッドの最大数を計画する必要があります。保留中のすべてのスレッドに1つのコアを割り当て、スレッドの実行に残りのコア数を使用することもできます。たとえば、クアッドコアシステムでは、すべての保留中のスレッドに1つのコアを使用し、残りの3つのコアに3つの実行中のスレッドを使用します。スレッドスケジューラの効率に応じて、実行可能スレッドの一部は(ページアクセスの失敗などにより)コンテキストを切り替え、カーネルをしばらく非アクティブのままにする場合があります。プロファイリング中にこの状況を観察する場合、実行するスレッドの数をコアの数よりもわずかに多く作成し、この値をシステムに構成する必要があります。
間違い19:同期にvolatileキーワードを使用する
volatileキーワードは、変数のタイプを指定する前に、この変数に対する操作をアトミックまたはスレッドセーフにしません。おそらく必要なのはstd :: atomicです。
詳細については、stackoverflowの説明を参照してください。
間違い20:絶対に必要でない限り、Lock Free Architectureを使用する
すべてのエンジニアが好む複雑なものがあります。ロックなしで動作するプログラムを作成することは、ミューテックス、条件変数、非同期などの従来の同期メカニズムと比較して非常に魅力的です。しかし、私が話した経験豊富なC ++開発者は皆意見がありました。初期オプションとして非ロックプログラミングを使用することは、最も不適切な時点で横向きになる可能性がある一種の時期尚早な最適化です(完全なヒープダンプがない場合のオペレーティングシステムのクラッシュについて考えてください!)。
C ++での私のキャリアでは、ロックのないコードの実行を必要とする状況は1つだけでした。これは、リソースが限られたシステムで作業し、コンポーネントの各トランザクションが10マイクロ秒以内で済むためです。
ブロックせずに開発アプローチを適用することを考える前に、3つの質問に答えてください。
- 同期メカニズムを必要としないようにシステムのアーキテクチャを設計しようとしましたか?原則として、最良の同期は同期の欠如です。
- 同期が必要な場合、パフォーマンス特性を理解するためにコードのプロファイルを作成しましたか?もしそうなら、ボトルネックを最適化しようとしましたか?
- 垂直にスケーリングする代わりに水平にスケーリングできますか?
要約すると、通常のアプリケーション開発では、他のすべての選択肢を使い果たした場合にのみ、非ロックプログラミングを検討してください。これを見るもう1つの方法は、上記の19個のエラーのいくつかをまだ作成している場合、おそらくブロックせずにプログラミングから離れる必要があるということです。
[から。翻訳者:この記事の準備を手伝ってくれたvovo4Kに感謝します。]