
データサイエンスの分野における従来のツールは、 RやPythonなどの言語です。リラックスした構文と、機械学習およびデータ処理用の多数のライブラリにより、いくつかの実用的なソリューションをすばやく取得できます。 ただし、これらのツールの制限が重大な障害となる状況があります。まず、処理速度の点で高いパフォーマンスを達成する必要がある場合や、非常に大きなデータセットを使用する必要がある場合です。 この場合、スペシャリストはしぶしぶ「ダークサイド」の助けを借りて、「産業用」プログラミング言語( Scala 、 Java 、 C ++)のツールを接続する必要があります。
しかし、こちら側はとても暗いですか? 長年の開発を経て、「産業用」データサイエンスのツールは大きく進歩し、今日では2〜3年前の独自のバージョンとは大きく異なります。 SNA Hackathon 2019タスクの例を使用して、Scala + SparkエコシステムがPython Data Scienceにどれだけ対応できるかを考えてみましょう。
SNA Hackathon 2019のフレームワーク内で、参加者は、ソーシャルネットワークのユーザーのニュースフィードを、テキスト、画像、または機能ログのデータを使用する3つの「分野」のいずれかに分類する問題を解決します。 この出版物では、従来の機械学習ツールを使用して、Sparkで標識のログに基づいて問題を解決する方法を説明します。
問題を解決するには、モデルを開発するときにデータ分析の専門家が経験する標準的な方法を使用します。
- 研究データ分析を実施し、グラフを作成します。
- データ内の兆候の統計的特性を分析し、トレーニングセットとテストセットの違いを調べます。
- 統計的特性に基づいて、特徴の初期選択を実行します。
- 記号とターゲット変数間の相関、および記号間の相互相関を計算します。
- 機能の最終セットを形成し、モデルをトレーニングし、その品質を確認します。
- モデルの内部構造を分析して、成長ポイントを特定しましょう。
「旅」では、 Zeppelinインタラクティブなノートブック、 Spark ML機械学習ライブラリ、その拡張機能PravdaML 、 GraphX グラフ作成パッケージ、 Vegas視覚化ライブラリ、そしてもちろんApache Sparkなどのツールに精通します。 ) すべてのコードと実験結果は、 Zeplコラボレーティブノートパッドプラットフォームで利用できます 。
データの読み込み
SNA Hackathon 2019でレイアウトされたデータの機能は、Pythonを使用して直接処理できることですが、Apache Parquet列形式の機能のおかげでソースデータは非常に効率的に圧縮され、メモリに「額で」読み込まれると数十ギガバイトに圧縮解除されます。 Apache Sparkを使用する場合、データをメモリに完全にロードする必要はありません。Sparkアーキテクチャはデータを断片的に処理し、必要に応じてディスクからロードするように設計されています。
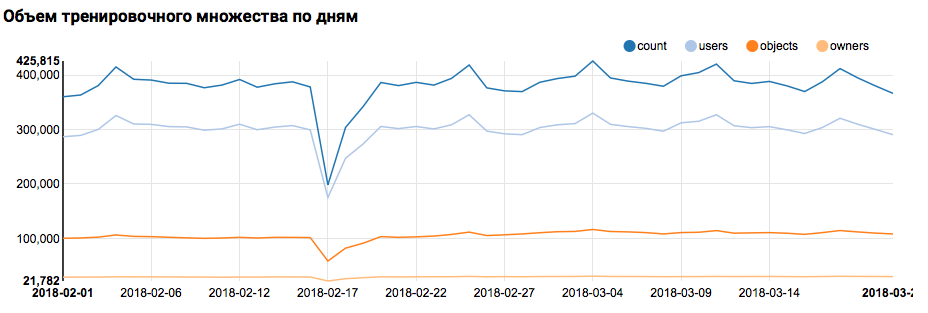
したがって、最初のステップ(日ごとのデータ分布の確認)は、ボックス化されたツールで簡単に実行できます。
val train = sqlContext.read.parquet("/events/hackatons/SNAHackathon/2019/collabTrain") z.show(train.groupBy($"date").agg( functions.count($"instanceId_userId").as("count"), functions.countDistinct($"instanceId_userId").as("users"), functions.countDistinct($"instanceId_objectId").as("objects"), functions.countDistinct($"metadata_ownerId").as("owners")) .orderBy("date"))
対応するグラフが Zeppelinに表示するもの:
Scalaの構文は非常に柔軟性があり、同じコードはたとえば次のように見えるかもしれません。
val train = sqlContext.read.parquet("/events/hackatons/SNAHackathon/2019/collabTrain") z.show( train groupBy $"date" agg( count($"instanceId_userId") as "count", countDistinct($"instanceId_userId") as "users", countDistinct($"instanceId_objectId") as "objects", countDistinct($"metadata_ownerId") as "owners") orderBy "date" )
ここで重要な警告を行う必要があります。誰もが自分の好みの観点からのみScalaコードの作成に取り組む大規模なチームで作業する場合、コミュニケーションははるかに困難です。 そのため、コードスタイルの統一された概念を開発する方が適切です。
しかし、タスクに戻ります。 日ごとの簡単な分析では、2月17日と18日に異常なポイントの存在が示されました。 おそらく最近では不完全なデータが収集されており、形質の分布は偏っている可能性があります。 これは、さらに分析する際に考慮する必要があります。 さらに、一意のユーザーの数がオブジェクトの数に非常に近いため、オブジェクトの数が異なるユーザーの分布を調査することは理にかなっています。
z.show(filteredTrain .groupBy($"instanceId_userId").count .groupBy("count").agg(functions.log(functions.count("count")).as("withCount")) .orderBy($"withCount".desc) .limit(100) .orderBy($"count"))
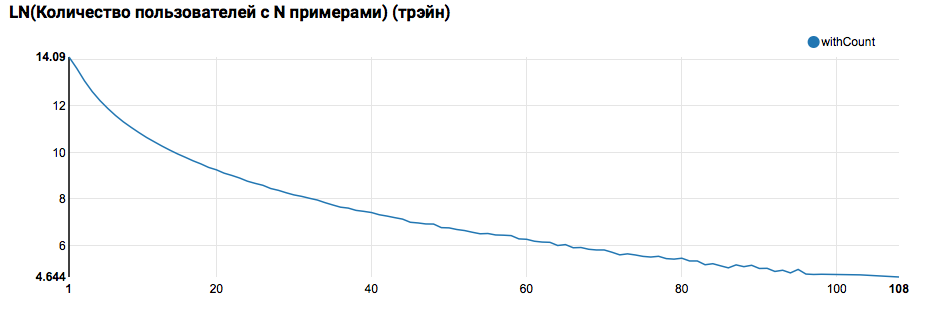
非常に長いテールを持つ指数関数に近い分布が見られると予想されます。 このようなタスクでは、原則として、さまざまなレベルのアクティビティを持つユーザーのモデルをセグメント化することにより、作業の品質を向上させることができます。 これを行う価値があるかどうかを確認するには、テストセット内のユーザーごとのオブジェクト数の分布を比較します。
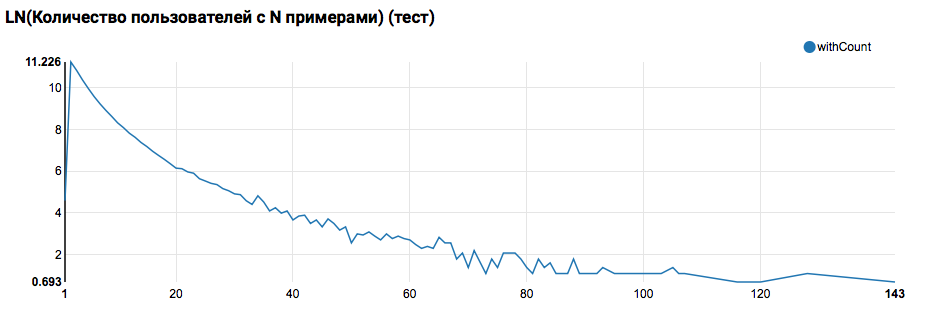
テストとの比較は、テストユーザーがログに少なくとも2つのオブジェクトを持っていることを示しています(ランキングタスクはハッカソンで解決されるため、これは品質を評価するための必要条件です)。 将来は、トレーニングセットのユーザーをより詳しく調べることをお勧めします。トレーニングセットでは、ユーザー定義関数をフィルターで宣言します。
// , "", , // val testSimilar = sc.broadcast(filteredTrain.groupBy($"instanceId_userId") .agg( functions.count("feedback").as("count"), functions.sum(functions.expr("IF(array_contains(feedback, 'Liked'), 1.0, 0.0)")).as("sum") ) .where("count > sum AND sum > 0") .select("instanceId_userId").rdd.map(_.getInt(0)).collect.sorted) // // User Defined Function val isTestSimilar = sqlContext.udf.register("isTestSimilar", (x: Int) => java.util.Arrays.binarySearch(testSimilar.value, x) >= 0)
ここでも重要な発言を行う必要があります。Scala/ JavaとPythonでのSparkの使用が著しく異なるのは、UDFを定義するという観点からです。 PySparkコードは基本的な機能を使用しますが、すべてがほぼ同じ速度で機能しますが、オーバーライドされた関数が表示されると、PySparkのパフォーマンスは桁違いに低下します。
最初のMLパイプライン
次のステップでは、アクションと属性に関する基本的な統計の計算を試みます。 ただし、このためにはSparkMLの機能が必要なので、まずその一般的なアーキテクチャを見ていきます。

SparkMLは、次の概念に基づいて構築されています。
- トランスフォーマー-データセットを入力として受け取り、変更されたセット(変換)を返します。 原則として、前処理および後処理アルゴリズム、特徴抽出を実装するために使用され、結果のMLモデルを表すこともできます。
- Estimator-データセットを入力として受け取り、Transformer(fit)を返します。 当然、EstimatorはMLアルゴリズムを表すことができます。
- パイプラインは、推定器の特殊なケースであり、トランスフォーマーと推定器のチェーンで構成されています。 メソッドが呼び出されると、fitはチェーンを通過し、トランスフォーマーが見つかった場合はデータに適用し、推定器が見つかった場合はトランスフォーマーをトレーニングしてデータに適用し、さらに先に進みます。
- PipelineModel-Pipelineの結果には内部にチェーンも含まれますが、トランスフォーマのみで構成されます。 したがって、PipelineModel自体もトランスフォーマーです。
MLアルゴリズムの形成に対するこのようなアプローチは、明確なモジュール構造と優れた再現性を実現するのに役立ちます。モデルとパイプラインの両方を節約できます。
まず、トレーニングセットのユーザーのアクションの分布(フィードバックフィールド)の統計を計算する単純なパイプラインを構築します。
val feedbackAggregator = new Pipeline().setStages(Array( // (feedback) one-hot new MultinominalExtractor().setInputCol("feedback").setOutputCol("feedback"), // new VectorStatCollector() .setGroupByColumns("date").setInputCol("feedback") .setPercentiles(Array(0.1,0.5,0.9)), // new VectorExplode().setValueCol("feedback") )).fit(train) z.show(feedbackAggregator .transform(filteredTrain) .orderBy($"date", $"feedback"))
このパイプラインでは、 PravdaMLの機能が積極的に使用されています。つまり、SparkML用の拡張された便利なブロックを備えたライブラリです。
- MultinominalExtractorは、ワンホット原則に従って、「文字列の配列」タイプの文字をベクトルにエンコードするために使用されます。 これは、パイプラインの唯一の推定器です(エンコードを作成するには、データセットから一意の行を収集する必要があります)。
- VectorStatCollectorは、ベクトル統計の計算に使用されます。
- VectorExplodeは、結果を視覚化に便利な形式に変換するために使用されます。
作業の結果は、データセット内のクラスのバランスが取れていないことを示すグラフになりますが、ターゲットLikedクラスの不均衡は極端ではありません。

テスト対象(ログに「ポジティブ」と「ネガティブ」の両方がある)に類似するユーザー間の類似分布の分析は、ポジティブクラスに偏っていることを示しています。
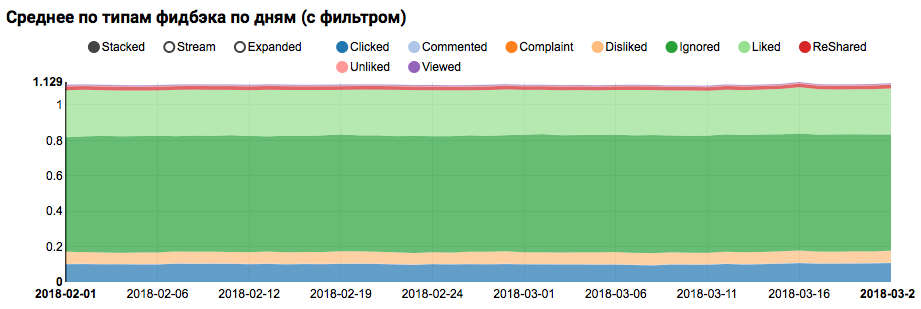
兆候の統計分析
次の段階では、属性の統計特性の詳細な分析を実行します。 今回は、より大きなコンベアが必要です。
val statsAggregator = new Pipeline().setStages(Array( new NullToDefaultReplacer(), // new AutoAssembler() .setColumnsToExclude( (Seq("date", "feedback") ++ train.schema.fieldNames.filter(_.endsWith("Id")) : _*)) .setOutputCol("features"), new VectorStatCollector() .setGroupByColumns("date").setInputCol("features") .setPercentiles(Array(0.1,0.5,0.9)), new VectorExplode().setValueCol("features") ))
これから、個別のフィールドではなく、すべての属性を一度に処理する必要があるため、さらに2つの便利なPravdaMLユーティリティを使用します。
- NullToDefaultReplacerを使用すると、データの欠落要素をデフォルト値(数値の場合は0、論理変数の場合はfalseなど)で置き換えることができます。 この変換を行わないと、結果のベクトルにNaN値が表示されます。これは多くのアルゴリズムにとって致命的です(たとえば、XGBoostはこれに耐えることができます)。 ゼロで置き換える代わりに、平均で置き換えることができます。これはNaNToMeanReplacerEstimatorで実装されます。
- AutoAssemblerは、テーブルレイアウトを分析し、列のタイプに一致する各列のベクトル化スキームを選択する非常に強力なユーティリティです。
結果のパイプラインを使用して、3つのセット(トレーニング、ユーザーフィルターとテストによるトレーニング)の統計を計算し、個別のファイルに保存します。
// ( AutoAssembler ) val trained = statsAggregator.fit(filteredTrain) // - , . trained .transform(filteredTrain .withColumn("date", // , , , // All functions.explode(functions.array(functions.lit("All"), $"date")))) .coalesce(7).write.mode("overwrite").parquet("sna2019/featuresStat") trained .transform(filteredTrain .where(isTestSimilar($"instanceId_userId")) .withColumn("date", functions.explode(functions.array(functions.lit("All"), $"date")))) .coalesce(7).write.mode("overwrite").parquet("sna2019/filteredFeaturesStat") trained .transform(filteredTest.withColumn("date", functions.explode(functions.array(functions.lit("All"), $"date")))) .coalesce(3).write.mode("overwrite").parquet("sna2019/testFeaturesStat")
フィーチャの統計情報を含む3つのデータセットを受け取った後、次のことを分析します。
- 排出量が多い兆候はありますか。
-そのような兆候を制限するか、外れ値の記録を除外する必要があります。 - 中央値と比較して平均値が大きく変化する兆候はありますか。
-このようなシフトは、べき法則の分布がある場合によく発生しますが、これらの兆候を対数化することは理にかなっています。 - トレーニングセットとテストセットの間で平均分布にシフトがありますか。
- フィーチャーマトリックスがどの程度密に満たされているか。
これらの側面を明確にするために、次のリクエストが役立ちます。
def compareWithTest(data: DataFrame) : DataFrame = { data.where("date = 'All'") .select( $"features", // // ( ) functions.log($"features_mean" / $"features_p50").as("skewenes"), // 90- // 90- — functions.log( ($"features_max" - $"features_p90") / ($"features_p90" - $"features_p50")).as("outlieres"), // , // ($"features_nonZeros" / $"features_count").as("train_fill"), $"features_mean".as("train_mean")) .join(testStat.where("date = 'All'") .select($"features", $"features_mean".as("test_mean"), ($"features_nonZeros" / $"features_count").as("test_fill")), Seq("features")) // .withColumn("meanDrift", (($"train_mean" - $"test_mean" ) / ($"train_mean" + $"test_mean"))) // .withColumn("fillDrift", ($"train_fill" - $"test_fill") / ($"train_fill" + $"test_fill")) } // val comparison = compareWithTest(trainStat).withColumn("mode", functions.lit("raw")) .unionByName(compareWithTest(filteredStat).withColumn("mode", functions.lit("filtered")))
この段階では、視覚化の問題は緊急です。ツェッペリンの通常のツールを使用すると、すべての側面をすぐに表示することは難しく、膨大なグラフを含むノートブックは肥大化したDOMにより著しく遅くなり始めます。 Vegas - vega-lite仕様を作成するためのScalaのDSLライブラリは、この問題を解決できます。 Vegasは、豊富な視覚化機能(matplotlibと同等)を提供するだけでなく、DOMを拡張することなくCanvasに描画します:)。
興味のあるチャートの仕様は次のようになります。
vegas.Vegas(width = 1024, height = 648) // .withDataFrame(comparison.na.fill(0.0)) // .encodeX("meanDrift", Quant, scale = Scale(domainValues = List(-1.0, 1.0), clamp = true)) // - .encodeY("train_fill", Quant) // .encodeColor("outlieres", Quant, scale=Scale( rangeNominals=List("#00FF00", "#FF0000"), domainValues = List(0.0, 5), clamp = true)) // .encodeSize("skewenes", Quant) // - ( ) .encodeShape("mode", Nom) .mark(vegas.Point) .show
以下のチャートは次のようになります。
- X軸は、テストセットとトレーニングセット間の分布中心のシフトを示します(0に近いほど、符号は安定します)。
- 非ゼロ要素の割合はY軸に沿ってプロットされます(値が大きいほど、属性ごとのポイント数が多いほどデータが多くなります)。
- サイズは、中央値に対する平均値のシフトを示します(ポイントが大きいほど、べき乗則の分布が高くなります)。
- 色は、放出の存在を示します(赤く、放出が多い)。
- さて、フォームは比較モードで区別されます。トレーニングセットにユーザーフィルターを使用するか、フィルターを使用しないかです。
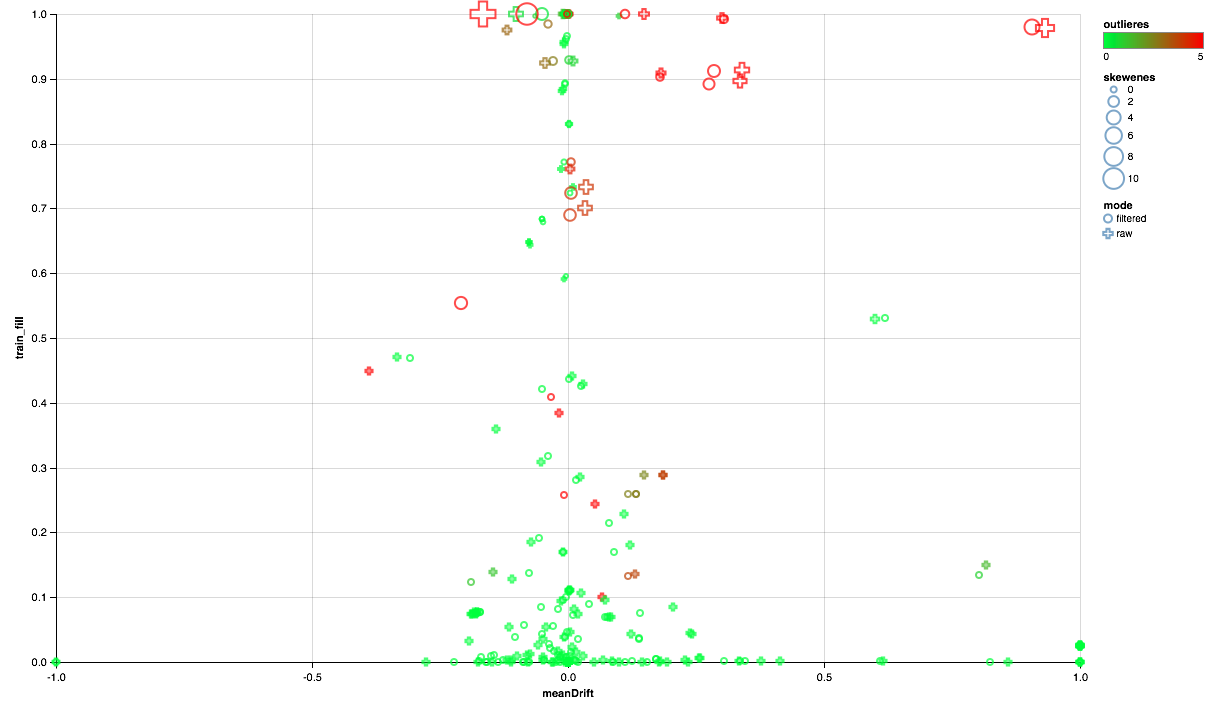
したがって、次の結論を導き出すことができます。
- 一部の標識には放射フィルターが必要です-90パーセンタイルの最大値を制限します。
- いくつかの兆候は、指数関数に近い分布を示しています-対数を取ります。
- 一部の機能はテストに含まれていません-トレーニングから除外します。
相関分析
属性がどのように分散され、トレーニングセットとテストセットの間でどのように関係するかについての一般的なアイデアを得た後、相関を分析してみましょう。 これを行うには、以前の観測に基づいて特徴抽出を構成します。
// val expressions = filteredTrain.schema.fieldNames // .filterNot(x => x == "date" || x == "audit_experiment" || idsColumns(x) || x.contains("vd_")) .map(x => if(skewedFeautres(x)) { // s"log($x) AS $x" } else { // cappedFeatures.get(x).map(capping => s"IF($x < $capping, $x, $capping) AS $x").getOrElse(x) }) val rawFeaturesExtractor = new Pipeline().setStages(Array( new SQLTransformer().setStatement(s"SELECT ${expressions.mkString(", ")} FROM __THIS__"), new NullToDefaultReplacer(), new AutoAssembler().setOutputCol("features") )) // val raw = rawFeaturesExtractor.fit(filteredTrain).transform( filteredTrain.where(isTestSimilar($"instanceId_userId")))
このパイプラインの新しい機械のうち、入力テーブルの任意のSQL変換を可能にするSQLTransformerユーティリティは注目に値します。
相関を分析するときは、ワンホットフィーチャの自然な相関によって作成されたノイズを除外することが重要です。 このため、ベクトルのどの要素がどの初期列に対応するかを理解したいと思います。 Sparkでのこのタスクは、列メタデータ(データと共に保存)と属性グループを使用して実行されます。 次のコードブロックは、String型の同じ列に由来する属性名のペアを除外するために使用されます。
val attributes = AttributeGroup.fromStructField(raw.schema("features")).attributes.get val originMap = filteredTrain .schema.filter(_.dataType == StringType) .flatMap(x => attributes.map(_.name.get).filter(_.startsWith(x.name + "_")).map(_ -> x.name)) .toMap // , val isNonTrivialCorrelation = sqlContext.udf.register("isNonTrivialCorrelation", (x: String, y : String) => // Scala-quiz Option originMap.get(x).map(_ != originMap.getOrElse(y, "")).getOrElse(true))
ベクトル列を持つデータセットを手元に置いて、Sparkを使用して相互相関を計算するのは非常に簡単ですが、結果はマトリックスになります。展開のために、ペアのセットを少し再生する必要があります。
val pearsonCorrelation = // Pearson Spearman Correlation.corr(raw, "features", "pearson").rdd.flatMap( // _.getAs[Matrix](0).rowIter.zipWithIndex.flatMap(x => { // , ( , // ) val name = attributes(x._2).name.get // , x._1.toArray.zip(attributes).map(y => (name, y._2.name.get, y._1)) } // DataFrame )).toDF("feature1", "feature2", "corr") .na.drop // .where(isNonTrivialCorrelation($"feature1", $"feature2")) // . pearsonCorrelation.coalesce(1).write.mode("overwrite") .parquet("sna2019/pearsonCorrelation")
そして、もちろん、視覚化:繰り返しますが、ヒートマップを描くにはVegasの助けが必要です。
vegas.Vegas("Pearson correlation heatmap") .withDataFrame(pearsonCorrelation .withColumn("isPositive", $"corr" > 0) .withColumn("abs_corr", functions.abs($"corr")) .where("feature1 < feature2 AND abs_corr > 0.05") .orderBy("feature1", "feature2")) .encodeX("feature1", Nom) .encodeY("feature2", Nom) .encodeColor("abs_corr", Quant, scale=Scale(rangeNominals=List("#FFFFFF", "#FF0000"))) .encodeShape("isPositive", Nom) .mark(vegas.Point) .show
結果はZepl-eで見る方が良いです。 一般的な理解のために:
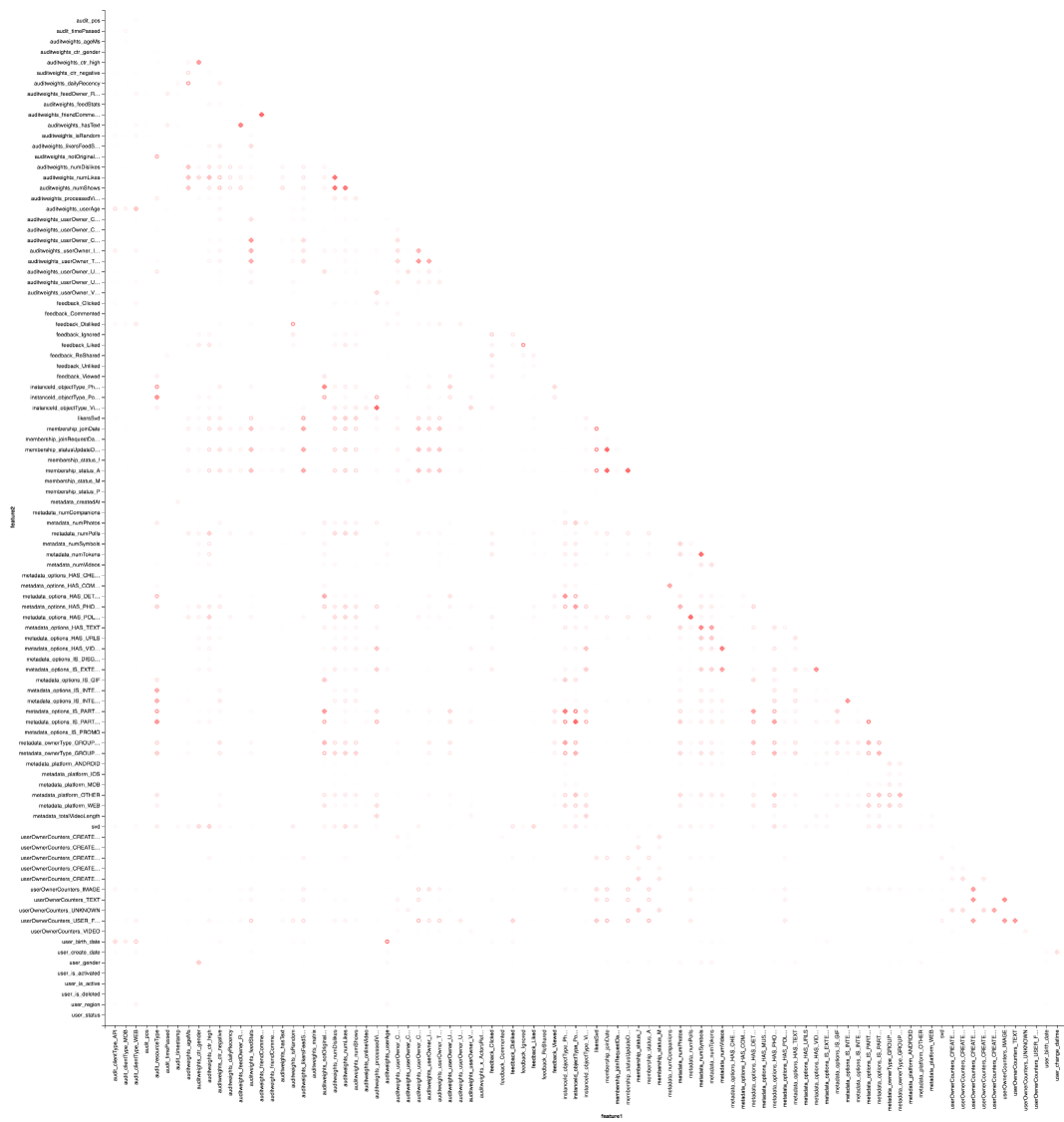
ヒートマップは、いくつかの相関関係が明らかに利用できることを示しています。 最も強く相関する特徴のブロックを選択してみましょう。これには、 GraphXライブラリを使用します:相関行列をグラフに変換し、重みでエッジをフィルター処理します。その後、接続されたコンポーネントを見つけ、非劣化コンポーネントのみを残します(複数の要素から)。 このような手順は、 DBSCANアルゴリズムのアプリケーションに本質的に類似しており、次のとおりです。
// (GrpahX ID) val featureIndexMap = spearmanCorrelation.select("feature1").distinct.rdd.map( _.getString(0)).collect.zipWithIndex.toMap val featureIndex = sqlContext.udf.register("featureIndex", (x: String) => featureIndexMap(x)) // val vertices = sc.parallelize(featureIndexMap.map(x => x._2.toLong -> x._1).toSeq, 1) // val edges = spearmanCorrelation.select(featureIndex($"feature1"), featureIndex($"feature2"), $"corr") // .where("ABS(corr) > 0.7") .rdd.map(r => Edge(r.getInt(0), r.getInt(1), r.getDouble(2))) // val components = Graph(vertices, edges).connectedComponents() val reversedMap = featureIndexMap.map(_.swap) // , , // val clusters = components .vertices.map(x => reversedMap(x._2.toInt) -> reversedMap(x._1.toInt)) .groupByKey().map(x => x._2.toSeq) .filter(_.size > 1) .sortBy(-_.size) .collect
結果は表形式で表示されます。
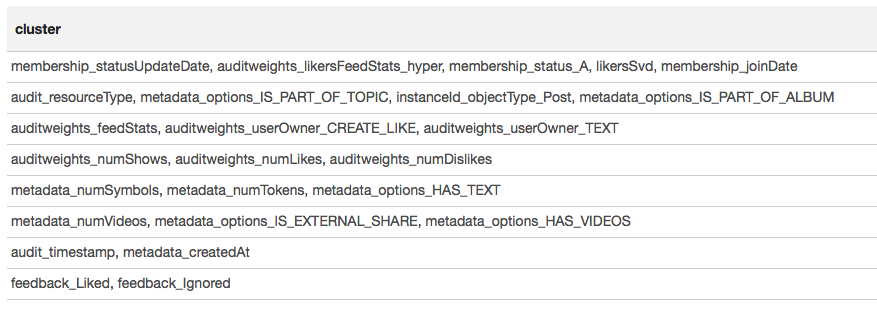
クラスタリングの結果に基づいて、最も相関性の高いグループは、グループのメンバーシップ(membership_status_A)とオブジェクトのタイプ(instanceId_objectType)に関連付けられた記号の周りに形成されたと結論付けることができます。 標識の相互作用の最適なモデリングのために、モデルのセグメンテーションを適用することは理にかなっています-ユーザーが存在するグループとそうでないグループに別々に異なるタイプのオブジェクトの異なるモデルをトレーニングするため。
機械学習
最も興味深いのは機械学習です。 SparkMLおよびPravdaML拡張機能を使用して最も単純なモデル(ロジスティック回帰)をトレーニングするためのパイプラインは次のとおりです。
new Pipeline().setStages(Array( new SQLTransformer().setStatement( """SELECT *, IF(array_contains(feedback, 'Liked'), 1.0, 0.0) AS label FROM __THIS__"""), new NullToDefaultReplacer(), new AutoAssembler() .setColumnsToExclude("date", "instanceId_userId", "instanceId_objectId", "feedback", "label") .setOutputCol("features"), Scaler.scale(Interceptor.intercept(UnwrappedStage.repartition( new LogisticRegressionLBFSG(), numPartitions = 127)))
ここでは、多くの馴染みのある要素だけでなく、いくつかの新しい要素も確認できます。
- LogisticRegressionLBFSGは、ロジスティック回帰の分散トレーニングを備えた推定量です。
- 分散MLアルゴリズムから最大のパフォーマンスを達成するため。 データはパーティション間で最適に分散される必要があります。 UnwrappedStage.repartitionユーティリティはこれに役立ち、再分割操作をパイプラインに追加して、トレーニング段階でのみ使用されるようにします(結局、予測を構築するときは不要になります)。
- 線形モデルで良い結果が得られるように。 データはスケーリングする必要があり、そのためにScaler.scaleユーティリティが責任を負います。 ただし、2つの連続した線形変換(回帰重みによるスケーリングと乗算)が存在すると、不要な費用が発生するため、これらの操作を折りたたむことが望ましいです。 PravdaMLを使用すると 、出力は1つの変換を含むクリーンなモデルになります:)。
- もちろん、このようなモデルには、Interceptor.intercept操作を使用して追加する無料のメンバーが必要です。
結果のパイプラインは、すべてのデータに適用され、ユーザーごとのAUC 0.6889を提供します(検証コードはZeplで利用可能です)。 データのフィルター処理、機能の変換、セグメントモデルのすべての研究を適用することは今でも残っています。 最終的なパイプラインは次のようになります。
new Pipeline().setStages(Array( new SQLTransformer().setStatement(s"SELECT instanceId_userId, instanceId_objectId, ${expressions.mkString(", ")} FROM __THIS__"), new SQLTransformer().setStatement("""SELECT *, IF(array_contains(feedback, 'Liked'), 1.0, 0.0) AS label, concat(IF(membership_status = 'A', 'OwnGroup_', 'NonUser_'), instanceId_objectType) AS type FROM __THIS__"""), new NullToDefaultReplacer(), new AutoAssembler() .setColumnsToExclude("date", "instanceId_userId", "instanceId_objectId", "feedback", "label", "type","instanceId_objectType") .setOutputCol("features"), CombinedModel.perType( Scaler.scale(Interceptor.intercept(UnwrappedStage.repartition( new LogisticRegressionLBFSG(), numPartitions = 127))), numThreads = 6) ))
PravdaML — CombinedModel.perType. , numThreads = 6. .
, , per-user AUC 0.7004. ? , " " XGBoost :
new Pipeline().setStages(Array( new SQLTransformer().setStatement("""SELECT *, IF(array_contains(feedback, 'Liked'), 1.0, 0.0) AS label FROM __THIS__"""), new NullToDefaultReplacer(), new AutoAssembler() .setColumnsToExclude("date", "instanceId_userId", "instanceId_objectId", "feedback", "label") .setOutputCol("features"), new XGBoostRegressor() .setNumRounds(100) .setMaxDepth(15) .setObjective("reg:logistic") .setNumWorkers(17) .setNthread(4) .setTrackerConf(600000L, "scala") ))
, — XGBoost Spark ! DLMC , PravdaML , ( ). XGboost " " 10 per-user AUC 0.6981.
結果分析
, , , . SparkML , . PravdaML : Parquet Spark:
// val perTypeWeights = sqlContext.read.parquet("sna2019/perType/stages/*/weights") // 20 ( // ) val topFeatures = new TopKTransformer[Double]() .setGroupByColumns("type") .setColumnToOrderGroupsBy("abs_weight") .setTopK(20) .transform(perTypeWeights.withColumn("abs_weight", functions.abs($"unscaled_weight"))) .orderBy("type", "unscaled_weight")
Parquet, PravdaML — TopKTransformer, .
Vegas ( Zepl ):
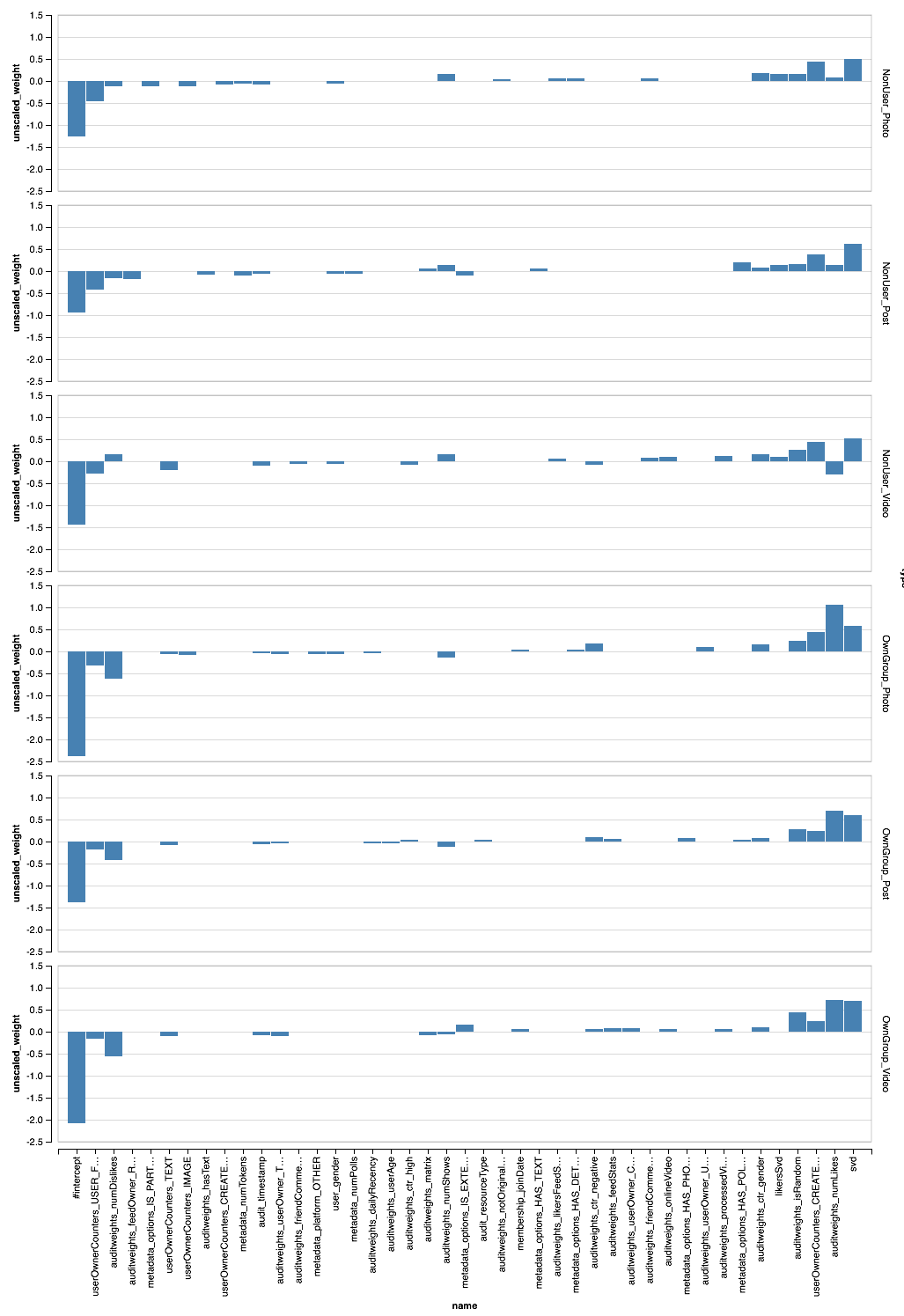
, - . XGBoost?
val significance = sqlContext.read.parquet( "sna2019/xgBoost15_100_raw/stages/*/featuresSignificance" vegas.Vegas() .withDataFrame(significance.na.drop.orderBy($"significance".desc).limit(40)) .encodeX("name", Nom, sortField = Sort("significance", AggOps.Mean)) .encodeY("significance", Quant) .mark(vegas.Bar) .show
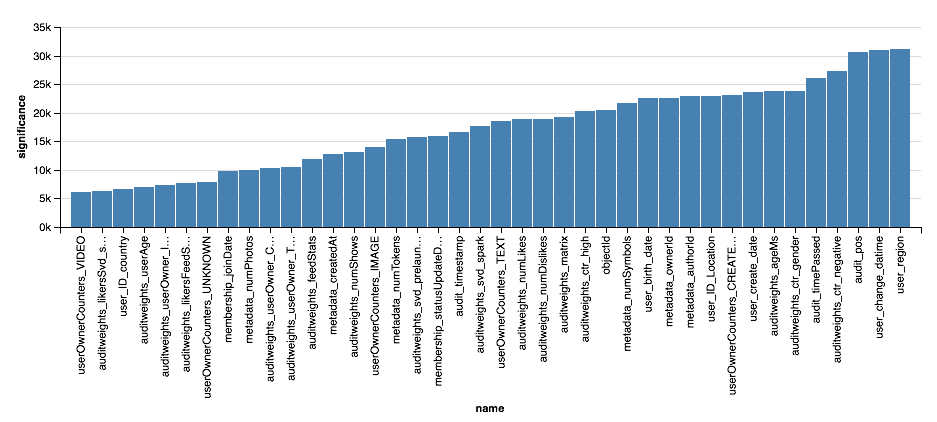
, , XGBoost, , . . , XGBoost , , .
結論
, :). :
, , , , -. , , " Scala " Newprolab.
, , — SNA Hackathon 2019 .