こんにちは、Habr! Rudy GilmanとKatherine Wang Intuitive RL:Advantage-Actor-Criticの紹介(A2C)による記事の翻訳に注目してください。

強化学習スペシャリスト(RL)は、多くの優れたチュートリアルを作成しています。 ただし、ほとんどの場合、RLは数学の方程式と抽象的な図で記述されます。 私たちは別の視点から主題について考えるのが好きです。 RL自体は動物の学習方法に触発されているので、基になるRLメカニズムを翻訳して、シミュレートすることを意図した自然現象に戻してみませんか? 人々は物語を通して最もよく学びます。
これは、Actor Advantage Critic(A2C)モデルの物語です。 サブジェクトクリティカルモデルは、それ自体が従来のRLアルゴリズムであるポリシーグラデーションモデルの一般的な形式です。 A2Cを理解すれば、深いRLを理解できます。
A2Cを直感的に理解したら、次を確認してください。
- A2Cコードの簡単な実装 (トレーニング用)またはOpenAI TensorFlow Baselinesモデルに基づくPyTorchの工業用バージョン 。
- Barto&SuttonによるRLの紹介 、 David Silverの標準コース 、 Yusi Leeによるレビュー、およびGitHub上のDenny Britzの RLへの深い没入のためのリポジトリ 。
- PyTorchで実装された、一般的なディープラーニングの直感的で実用的な範囲をカバーする驚くべきfast.aiコース 。
- TensorFlowで実装されたArthur Giuliani RL チュートリアル 。
イラスト@embermarke
RLでは、エージェントのKlyukovkaキツネが行動に囲まれた州を移動し、その過程で報酬を最大化しようとします。
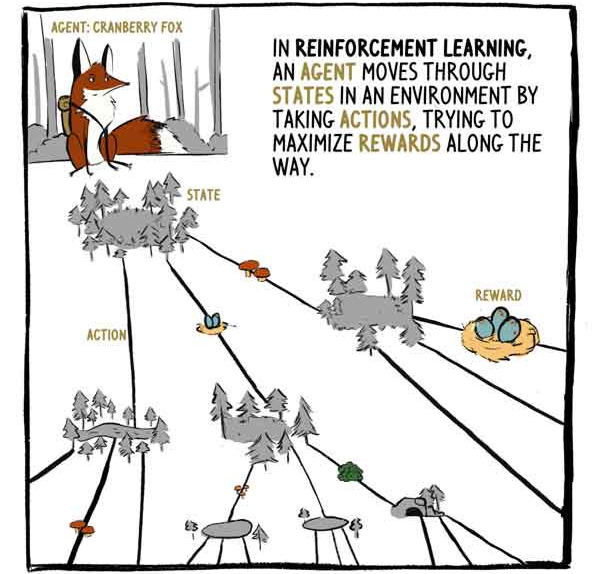
A2Cはステータス入力(Klukovkaの場合はセンサー入力)を受け取り、2つの出力を生成します。
1)現在の(既存の)報酬を除いて、現在の状態の瞬間から始まる、どのくらいの報酬を受け取るかの評価。
2)実行するアクションに関する推奨事項(ポリシー)。
評論家:わあ、なんて素晴らしい谷だ! 採餌の実り多い日になるでしょう! 今日は、日没前に20ポイントを集めます。
「被写体」:これらの花は美しく見え、「A」への渇望を感じます。

ディープRLモデルは、他の分類モデルや回帰モデルと同様に、入出力マッピングマシンです。 画像またはテキストを分類する代わりに、ディープRLモデルは状態をアクションに、および/または状態を状態値にもたらします。 A2Cは両方を行います。


このstate-action-rewardセットは1つの観察を構成します。 彼女はジャーナルにこのデータ行を書きますが、まだ考えていません。 彼女は考えるのをやめたときにそれを埋めます。
一部の著者は報酬1をタイムステップ1に関連付け、他の著者はそれをステップ2に関連付けますが、全員が同じ概念を念頭に置いています。報酬は状態に関連し、アクションはその直前にあります。

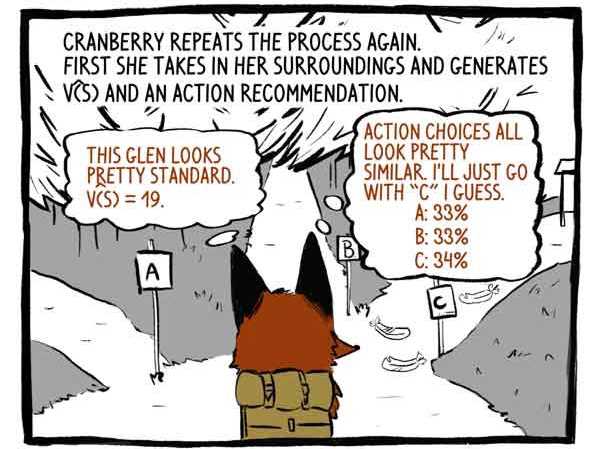
フックすると、プロセスが再び繰り返されます。 最初に、彼女は自分の周囲を知覚し、機能V(S)と行動の推奨を開発します。
評論家:この谷はかなり標準に見えます。 V(S)= 19。
件名:アクションのオプションは非常に似ています。 トラック「C」に進むと思います。
その後、動作します。

+20の報酬を受け取ります! そして、観察結果を記録します。

彼女はこのプロセスを繰り返します。

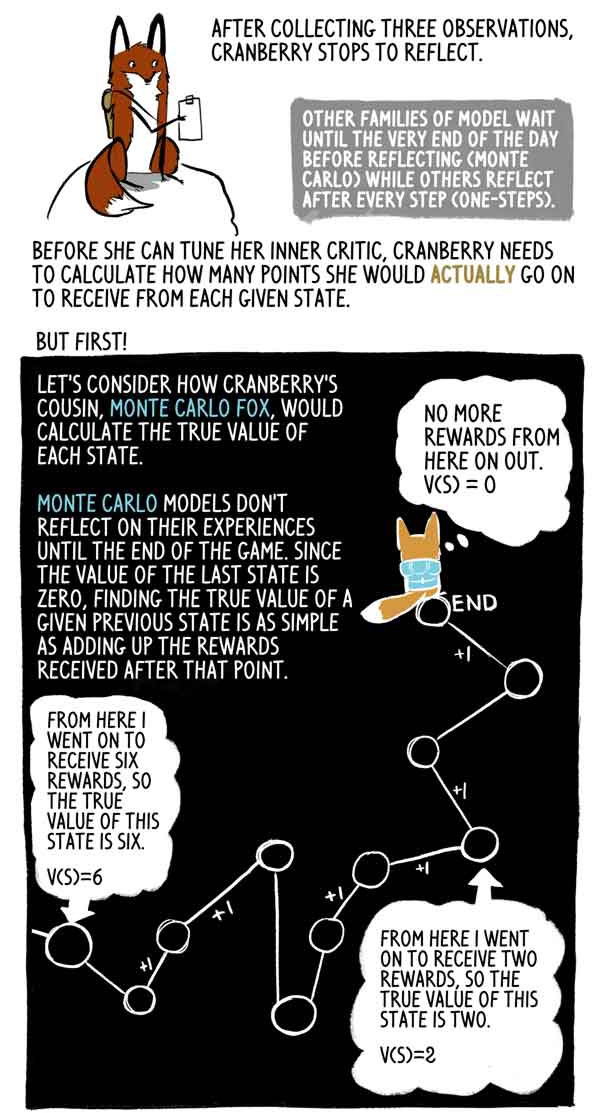
3つの観察結果を収集した後、Klyukovkaは思考を停止します。
他のモデルファミリーは1日の終わりまで待機します(モンテカルロ)が、他のモデルファミリーは各ステップ(1ステップ)の後に考えます。
内部評論家を立ち上げる前に、Klukovkaは、各州で実際に受け取るポイント数を計算する必要があります。
しかし、最初に!
KlukovkaのいとこLis Monte Carloが各状態の真の意味をどのように計算するかを見てみましょう。
モンテカルロモデルはゲームの終了まで経験を反映しません。また、最後の状態の値はゼロであるため、この前の状態の真の値をこの瞬間に受け取った報酬の合計として見つけることは非常に簡単です。
実際、これは単なる高分散サンプルV(S)です。 エージェントは、同じ状態から異なる軌道を簡単にたどることができ、それにより、異なる総報酬を受け取ることができます。
しかし、Klyukovkaは、一日が終わるまで何度も行き、立ち止まり、反射します。 ゲームの終了まで数時間残っているため、各州からゲームの終了までに実際に獲得できるポイント数を知りたいと考えています。
そこで、彼女は本当に賢いことをします。Klyukovkaキツネは、このセットで彼女が最後の幸運のためにどれだけのポイントを受け取るかを推定します。 幸いなことに、彼女は彼女の状態の正しい評価を持っています-彼女の批評家。
この評価により、Klyukovkaは、モンテカルロフォックスとまったく同じように、以前の状態の「正しい」値を計算できます。
Lis Monte Carloは目標マークを評価し、軌道の展開を行い、各州からの報酬を前方に追加します。 A2Cはこの軌道を切り、批評家の評価に置き換えます。 この初期ロードにより、スコアのばらつきが小さくなり、小さなバイアスが導入されますが、A2Cを継続的に実行できます。

報酬は、報酬が現在よりも将来的に優れているという事実を反映するためにしばしば削減されます。 簡単にするために、Klukovkaは報酬を減らしません。

これで、Klukovkaはデータの各行を調べて、状態値の推定値を実際の値と比較できます。 彼女はこれらの数値の差を利用して、予測スキルを完成させます。 1日3ステップごとに、Klyukovkaは検討する価値のある貴重な経験を収集します。
「州1と州2の評価が低かった。何を間違えたのか? うん! 次回このような羽を見たら、V(S)を増やします。
KlukovkaがV(S)評価を他の予測と比較するための基礎として使用できるのはおかしいかもしれません。 しかし、動物(私たちを含む)は常にこれを行います! 物事が順調に進んでいると感じた場合、この状態になったアクションを再トレーニングする必要はありません。

計算された出力をトリミングし、それらを初期負荷推定値に置き換えることにより、大きなモンテカルロ分散を小さなバイアスに置き換えました。 RLモデルは通常、高分散(考えられるすべてのパスを表す)に悩まされており、そのような置換は通常価値があります。
クルコフカはこのプロセスを終日繰り返し、状態アクション報酬の3つの観測を収集し、それらに反映します。
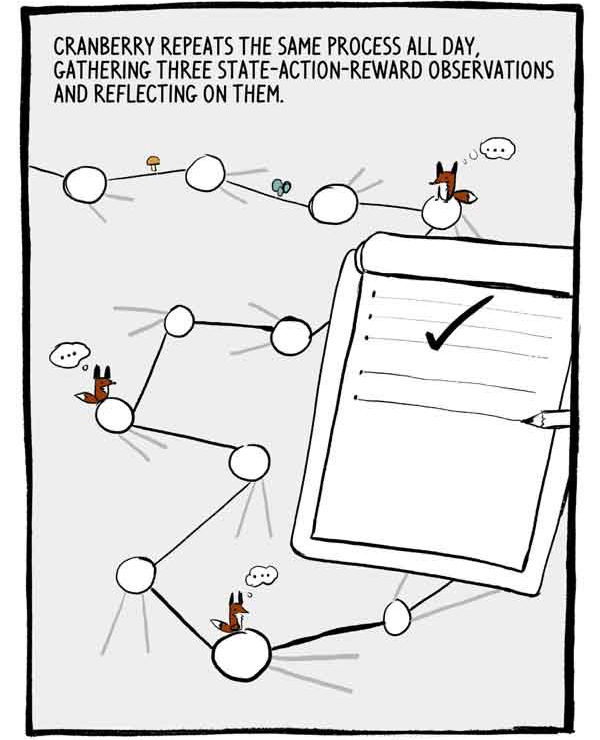
3つの観測値の各セットは、ラベル付けされたトレーニングデータの小さな自己相関シリーズです。 この自己相関を減らすために、多くのA2Cは多くのエージェントを並行して訓練し、共通のニューラルネットワークに送信する前にそれらの経験を合計します。

その日はついに終わりに近づいています。 あと2ステップだけです。
前に言ったように、Klukovkaの行動の推奨は、その能力についての確信度で表されます。 最も信頼できる選択肢を選択する代わりに、Klukovkaはこのアクションの分布から選択します。 これにより、彼女は常に安全ではあるが平凡な行動に常に同意するとは限りません。
私はそれを後悔することができました、しかし...時々、未知のものを探検して、あなたは刺激的な新しい発見に来ることができます...

研究をさらに促進するために、エントロピーと呼ばれる値が損失関数から差し引かれます。 エントロピーとは、アクションの分布の「範囲」を意味します。
-ゲームは報われたようです!

かどうか?
エージェントは、すべてのアクションがネガティブな結果につながる状態にある場合があります。 ただし、A2Cは悪い状況にうまく対処します。


太陽が沈むと、Klyukovkaは最後の解決策について考えました。

クリュコフカが彼の内なる批評家をどのように設定するかについて話しました。 しかし、彼女はどのように彼女の内側の「主題」を微調整しますか? 彼女はどのようにそのような絶妙な選択をすることを学ぶのですか?
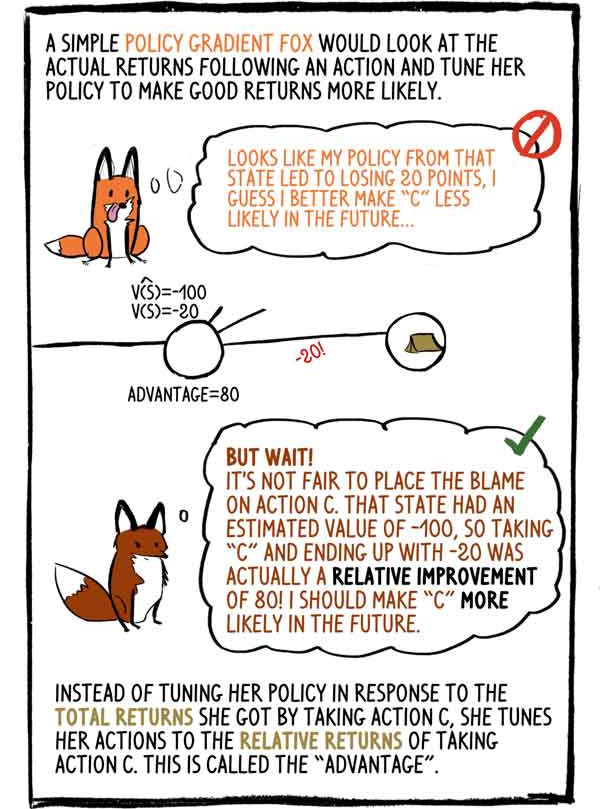
シンプルなフォックスグラディエントポリシーは、アクション後の実際の収入を見て、そのポリシーを調整して、より良い収入が得られるようにします。-この状態の私のポリシーは20ポイントの損失につながったようです。少ない可能性。
-しかし、待ってください! アクション「C」を非難するのは不公平です。 この条件の推定値は-100であったため、「C」を選択して-20で終了すると、実際には80の相対的な改善になりました。 将来的には「C」をもっと可能にしなければなりません。
アクションCを選択して受け取った総収入に応じてポリシーを調整する代わりに、アクションCからの相対的な収入に合わせてアクションを調整します。これは「利点」と呼ばれます。
私たちがアドバンテージと呼んだのは、単なる間違いです。 利点として、Klukovkaはそれを使用して、驚くほど良い、より可能性の高いアクションを作成します。 ミスとして、彼女は同じ量を使用して内部評論家を押し、ステータス値の評価を改善します。
被験者は以下を活用します。
-「うわー、これは思ったよりうまくいった。アクションCは良いアイデアだろう」
評論家はエラーを使用します:
「しかし、なぜ私は驚きましたか? この状態をそれほど否定的に評価すべきではなかったでしょう。」
これで、総損失の計算方法を示すことができます-この関数を最小化してモデルを改善します。
「総損失=アクションの損失+価値の損失-エントロピー」
3つの質的に異なるタイプの勾配を計算するために、「1を介して」値を取ることに注意してください。 これは効果的ですが、収束をより困難にする可能性があります。

すべての動物と同様に、クリコフカが成長するにつれて、彼は国家の価値を予測する能力を磨き、自分の行動に対する自信を高め、賞に驚くことも少なくなります。
KlukovkaなどのRLエージェントは、必要なすべてのデータを生成するだけでなく、単に環境と対話するだけでなく、ターゲットラベル自体を評価します。 そうです、RLモデルは以前のグレードを更新して、新しいグレードと改善されたグレードによりよく一致するようにします。
Google DeepmindのRLグループの責任者であるDavid Silver博士は次のように述べています。AI= DL + RL。 クリュコフカのようなエージェントが彼自身の知性を設定できるとき、可能性は無限です...
