Sparkなどのツールは、数百ギガバイトから数テラバイトまでの大きなデータセットを効率的に処理できますが、その機能を十分に活用するには、通常、非常に強力で高価なハードウェアが必要です。 また、パンダと比較すると、高品質のクリーニング、研究、データ分析のための豊富なツールセットに違いはありません。 中規模のデータセットの場合、他のツールに切り替えるのではなく、パンダをより効率的に使用することをお勧めします。

今日公開している翻訳では、パンダを使用する際のメモリの操作の機能、および
DataFrame
表形式のデータ構造の列に格納されている適切なデータ型を選択するだけでメモリ消費をほぼ90%削減する方法について説明します。
野球の試合のデータを操作する
130年にわたって収集され、 Retrosheetから取得したメジャーリーグの野球ゲームに関するデータを処理します。
最初、このデータは127個のCSVファイルとして提示されていましたが、 csvkitを使用してそれらを1つのデータセットに結合し、結果のテーブルの最初の行として列名を持つ行を追加しました。 必要に応じて、このデータのバージョンをダウンロードして試して、記事を読むことができます。
データセットのインポートから始めて、最初の5行を見てみましょう。 これら
シートの
この表にあります。
import pandas as pd gl = pd.read_csv('game_logs.csv') gl.head()
以下は、このデータを含むテーブルの最も重要な列に関する情報です。 すべての列の説明を読みたい場合は、 ここでデータセット全体のデータディクショナリを検索できます。
-
date
ゲームの日付。 -
v_name
ゲストチームの名前。 -
v_league
訪問チームのリーグ。 -
h_name
ホームチームの名前。 -
h_league
ホームチームリーグ。 -
v_score
アウェイチームからのポイント。 -
h_score
チームのスコア。 -
v_line_score
ゲストチームのポイントの概要。たとえば010000(10)00
-
h_line_score
ホームチームのポイントの要約、例えば010000(10)0X
。 -
park_id
ゲームがプレイされたフィールドの識別子。 -
attendance
-視聴者の数。
DataFrame
オブジェクトに関する一般情報を調べるには、 DataFrame.info()メソッドを使用できます。 この方法のおかげで、オブジェクトのサイズ、データ型、およびメモリ使用量について学ぶことができます。
デフォルトでは、パンダは時間を節約するために、
DataFrame
メモリ使用量に関するおおよその情報を
DataFrame
。 正確な情報に関心があるため、
memory_usage
パラメーターを
'deep'
設定します。
gl.info(memory_usage='deep')
取得できた情報は次のとおりです。
<class 'pandas.core.frame.DataFrame'> RangeIndex: 171907 entries, 0 to 171906 Columns: 161 entries, date to acquisition_info dtypes: float64(77), int64(6), object(78) memory usage: 861.6 MB
結局のところ、171,907行と161列があります。 pandasライブラリは、データ型を自動的に検出しました。 数値データのある83列とオブジェクトのある78列があります。 オブジェクト列は、文字列データを保存するために使用され、列にさまざまなタイプのデータが含まれる場合に使用されます。
ここで、この
DataFrame
使用してメモリ使用量を最適化する方法をよりよく理解するために、パンダがメモリにデータを保存する方法について話しましょう。
DataFrameの内部ビュー
パンダ内部では、データ列は同じタイプの値を持つブロックにグループ化されます。
DataFrame
最初の12列がパンダに保存される方法の例を次に示します。
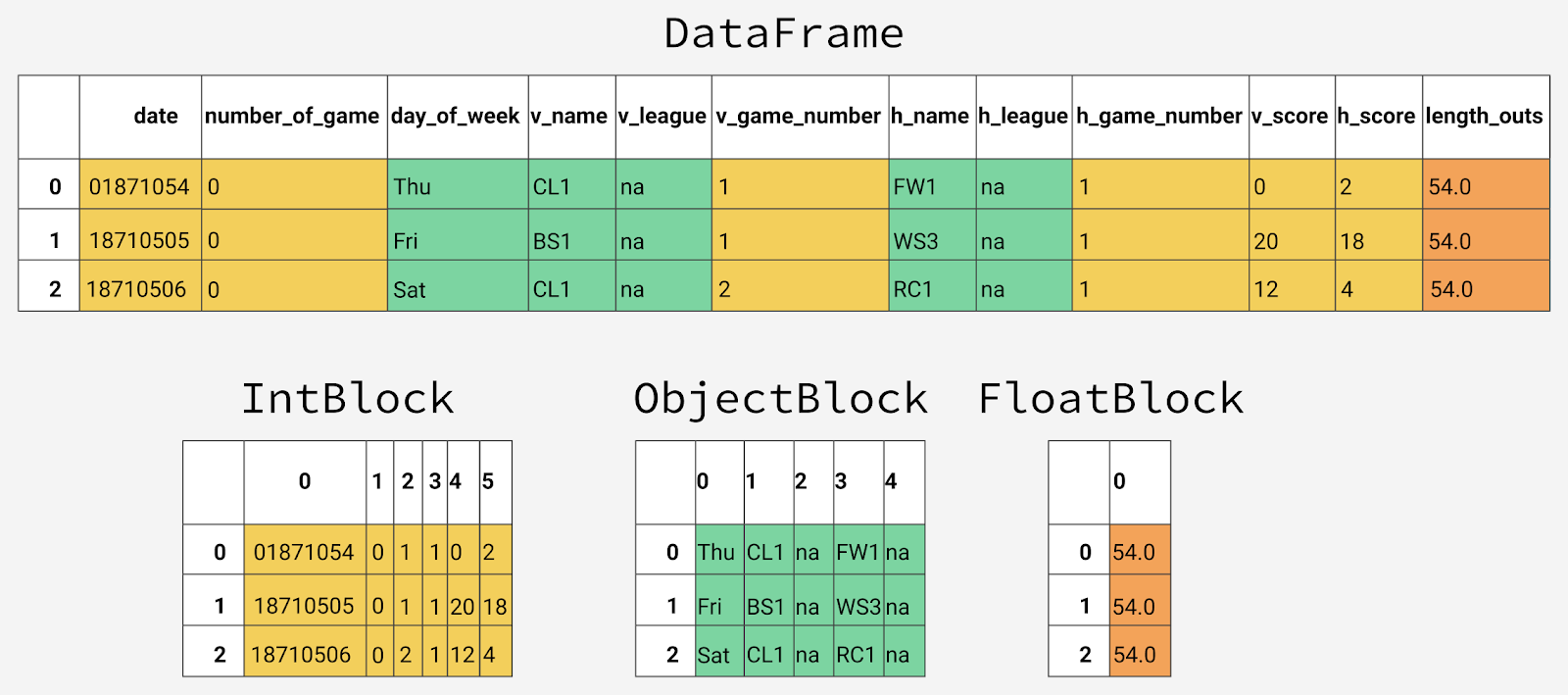
パンダのさまざまなタイプのデータの内部表現
ブロックには列名情報が保存されないことに気付くかもしれません。 これは、
DataFrame
オブジェクトのテーブルのセルで利用可能な値を格納するためにブロックが最適化されているという事実に
DataFrame
ものです。
BlockManager
クラスは、データセットの行インデックスと列インデックスの間の対応に関する情報、および同じタイプのデータのブロックに格納されるものに関する情報を格納する役割を果たします。 基本データへのアクセスを提供するAPIの役割を果たします。 値の読み取り、編集、または削除を行うと、
DataFrame
クラスは
BlockManager
クラスと対話して、リクエストを関数呼び出しとメソッド呼び出しに変換します。
各データ型には、
pandas.core.internals
モジュールに特別なクラスがあります。 たとえば、
ObjectBlock
は
ObjectBlock
クラスを使用して文字列列を含むブロックを表し、
ObjectBlock
クラスを使用して浮動小数点数を含む列を含むブロックを表します。 整数または浮動小数点数のように見える数値を表すブロックの場合、
ndarray
は列を結合し、NumPyライブラリの
ndarray
データ
ndarray
として保存します。 このデータ構造は配列Cに基づいて構築され、値は連続したメモリブロックに格納されます。 このデータストレージスキームのおかげで、データフラグメントへのアクセスは非常に高速です。
異なるタイプのデータは別々に保存されるため、異なるタイプのデータのメモリ使用量を調べます。 さまざまな種類のデータの平均メモリ使用量から始めましょう。
for dtype in ['float','int','object']: selected_dtype = gl.select_dtypes(include=[dtype]) mean_usage_b = selected_dtype.memory_usage(deep=True).mean() mean_usage_mb = mean_usage_b / 1024 ** 2 print("Average memory usage for {} columns: {:03.2f} MB".format(dtype,mean_usage_mb))
その結果、さまざまなタイプのデータのメモリ使用量の平均指標は次のようになります。
Average memory usage for float columns: 1.29 MB Average memory usage for int columns: 1.12 MB Average memory usage for object columns: 9.53 MB
この情報により、ほとんどのメモリがオブジェクト値を格納する78列に費やされていることがわかります。 これについては後で説明しますが、数値データを格納する列でメモリ使用量を改善できるかどうかを考えてみましょう。
サブタイプ
既に述べたように、パンダは
ndarray
NumPyデータ構造として数値を表し、連続したメモリブロックに格納します。 このデータストレージモデルにより、メモリを節約し、値にすばやくアクセスできます。 パンダは同じバイト数を使用して同じタイプの各値を表し、
ndarray
構造は値の数に関する情報を格納するため、パンダは数値を格納する列が消費するメモリ量を迅速かつ正確に
ndarray
できます。
パンダの多くのデータ型には、各バイトをより少ないバイト数で表すことができる多くのサブタイプがあります。 たとえば、
float
型にはサブタイプ
float16
、
float32
および
float64
ます。 タイプ名の数字は、サブタイプが値を表すために使用するビット数を示します。 たとえば、リストされたばかりのサブタイプでは、それぞれ2、4、8、および16バイトが使用されます。 以下の表は、パンダで最もよく使用されるデータ型のサブタイプを示しています。
| メモリ使用量、バイト
| 浮動小数点数
| 整数
| 符号なし整数
| 日時
| ブール値
| 対象
|
| 1
| int8
| uint8
| ブール
| |||
| 2
| float16
| int16
| uint16
| |||
| 4
| float32
| int32
| uint32
| |||
| 8
| float64
| int64
| uint64
| datetime64
| ||
| 可変メモリ容量
| 対象
|
タイプ
int8
の値は、1バイト(8ビット)を使用して数値を格納し、256のバイナリ値(2〜8度)を表すことができます。 これは、このサブタイプを使用して、-128〜127(0を含む)の範囲の値を格納できることを意味します。
各整数サブタイプを使用したストレージに適した最小値と最大値を確認するには、
numpy.iinfo()
メソッドを使用できます。 例を考えてみましょう:
import numpy as np int_types = ["uint8", "int8", "int16"] for it in int_types: print(np.iinfo(it))
このコードを実行すると、次のデータが取得されます。
Machine parameters for uint8 --------------------------------------------------------------- min = 0 max = 255 --------------------------------------------------------------- Machine parameters for int8 --------------------------------------------------------------- min = -128 max = 127 --------------------------------------------------------------- Machine parameters for int16 --------------------------------------------------------------- min = -32768 max = 32767 ---------------------------------------------------------------
ここでは、
uint
(符号なし整数)型と
int
(符号付き整数)型の違いに注意を払うことができます。 両方のタイプの容量は同じですが、列に正の値のみを格納する場合、符号なしのタイプではメモリをより効率的に使用できます。
サブタイプを使用した数値データのストレージの最適化
pd.to_numeric()
関数を使用して、数値型をダウンコンバートできます。 整数列を選択するには、
DataFrame.select_dtypes()
メソッドを使用し、それらを最適化し、最適化の前後でメモリ使用量を比較します。
# , , # , . def mem_usage(pandas_obj): if isinstance(pandas_obj,pd.DataFrame): usage_b = pandas_obj.memory_usage(deep=True).sum() else: # , DataFrame, Series usage_b = pandas_obj.memory_usage(deep=True) usage_mb = usage_b / 1024 ** 2 # return "{:03.2f} MB".format(usage_mb) gl_int = gl.select_dtypes(include=['int']) converted_int = gl_int.apply(pd.to_numeric,downcast='unsigned') print(mem_usage(gl_int)) print(mem_usage(converted_int)) compare_ints = pd.concat([gl_int.dtypes,converted_int.dtypes],axis=1) compare_ints.columns = ['before','after'] compare_ints.apply(pd.Series.value_counts)
メモリ消費の調査結果は次のとおりです。
7.87 MB
1.48 MB
| に
| 後
| |
| uint8
| ナン
| 5.0
|
| uint32
| ナン
| 1.0
|
| int64
| 6.0
| ナン
|
その結果、メモリ使用量が7.9メガバイトから1.5メガバイトに減少したことがわかります。つまり、メモリ消費を80%以上削減しました。 ただし、元の
DataFrame
に対するこの最適化の全体的な影響は、整数列が非常に少ないため特に強くありません。
浮動小数点数を含む列についても同じことをしましょう。
gl_float = gl.select_dtypes(include=['float']) converted_float = gl_float.apply(pd.to_numeric,downcast='float') print(mem_usage(gl_float)) print(mem_usage(converted_float)) compare_floats = pd.concat([gl_float.dtypes,converted_float.dtypes],axis=1) compare_floats.columns = ['before','after'] compare_floats.apply(pd.Series.value_counts)
結果は次のとおりです。
100.99 MB
50.49 MB
| に
| 後
| |
| float32
| ナン
| 77.0
|
| float64
| 77.0
| ナン
|
その結果、データ型が
float64
浮動小数点数を格納するすべての列に、
float64
型の数値が格納されるようになり、メモリ使用量が50%削減されました。
元の
DataFrame
コピーを作成し、元々存在していたものの代わりにこれらの最適化された数値列を使用し、最適化後の全体的なメモリ使用量を調べます。
optimized_gl = gl.copy() optimized_gl[converted_int.columns] = converted_int optimized_gl[converted_float.columns] = converted_float print(mem_usage(gl)) print(mem_usage(optimized_gl))
取得したものは次のとおりです。
861.57 MB
804.69 MB
数値データを格納する列によるメモリ消費を大幅に削減しましたが、一般的には
DataFrame
全体で、メモリ消費は7%しか減少しませんでした。 はるかに深刻な改善の原因は、オブジェクトタイプのストレージの最適化です。
この最適化を行う前に、文字列がパンダにどのように保存されるかを詳しく見て、これを数字がここに保存される方法と比較します。
数字と文字列を保存するメカニズムの比較
object
タイプは、Python文字列オブジェクトを使用して値を表します。 これは、NumPyが欠落している文字列値の表現をサポートしていないためです。 Pythonは高レベルのインタープリタ型言語であるため、プログラマがデータをメモリに格納する方法を微調整するためのツールを提供しません。
この制限により、文字列はメモリの連続したフラグメントに格納されず、メモリ内の文字列の表現はフラグメント化されます。 これにより、メモリ消費が増加し、文字列値の速度が低下します。 実際、オブジェクトのデータ型を格納する列の各要素は、実際の値がメモリ内にある「アドレス」を含むポインターです。
以下は、NumPyデータ型を使用した数値データの保存とPythonの組み込みデータ型を使用した文字列の保存を比較した、 この資料に基づく図です。

数値および文字列データの保存
ここで、オブジェクトタイプのデータを格納するために可変量のメモリが使用されることが、上記の表の1つで示されたことを思い出すことができます。 各ポインターは1バイトのメモリを占有しますが、特定の各文字列値は、Pythonで単一の文字列を格納するために使用されるメモリと同じ量を占有します。 これを確認するために、
sys.getsizeof()
メソッドを使用します。 まず、個々の行を見てから、文字列データを保存する
Series
pandasオブジェクトを見てください。
そのため、最初に通常の行を調べます。
from sys import getsizeof s1 = 'working out' s2 = 'memory usage for' s3 = 'strings in python is fun!' s4 = 'strings in python is fun!' for s in [s1, s2, s3, s4]: print(getsizeof(s))
ここで、メモリ使用量データは次のようになります。
60
65
74
74
それでは、
Series
オブジェクトでの文字列の使用方法を見てみましょう。
obj_series = pd.Series(['working out', 'memory usage for', 'strings in python is fun!', 'strings in python is fun!']) obj_series.apply(getsizeof)
ここでは次のものを取得します。
0 60 1 65 2 74 3 74 dtype: int64
ここで、
Series
pandasオブジェクトに格納されている行のサイズは、Pythonで作業するとき、および個別のエンティティとして表すときのサイズに似ていることがわかります。
カテゴリー変数を使用したオブジェクトタイプのデータのストレージの最適化
カテゴリ変数は、pandasバージョン0.15で登場しました。 対応する型
category
は、テーブル列に格納されている元の値の代わりに、内部メカニズムで整数値を使用します。 Pandasは、整数と初期値の対応を設定する別の辞書を使用します。 このアプローチは、列に限定セットの値が含まれる場合に役立ちます。 列に格納されたデータが
category
タイプに変換されると、pandasは
int
サブタイプを使用します。これにより、メモリを最も効率的に使用でき、列で見つかったすべての一意の値を表すことができます。
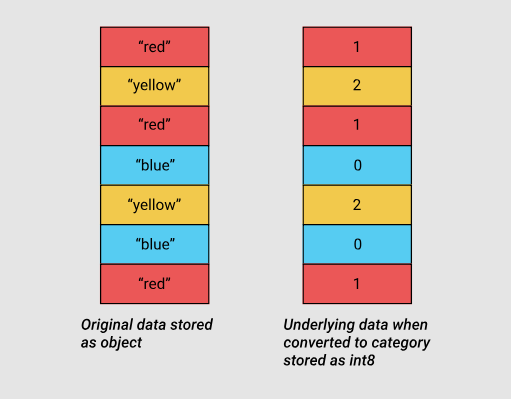
int8サブタイプを使用したソースデータとカテゴリデータ
カテゴリデータを使用してメモリ消費を削減できる場所を正確に理解するために、オブジェクトタイプの値を格納する列の一意の値の数を調べます。
gl_obj = gl.select_dtypes(include=['object']).copy() gl_obj.describe()
この表には、
シート
。
たとえば、ゲームがプレイされた
day_of_week
である
day_of_week
列には、171907の値があります。 それらのうち、7つだけが一意です。 全体として、このレポートを一目見るだけで、約172,000ゲームのデータを表すために多くの列で非常に少数の一意の値が使用されていることを理解できます。
本格的な最適化を行う前に、少なくとも
day_of_week
オブジェクトデータを格納する列を1つ選択し、プログラムがカテゴリ型に変換されたときにプログラム内で何が起こるかを見てみましょう。
すでに述べたように、この列には7つの一意の値のみが含まれています。 カテゴリ型に変換するには、
.astype()
メソッドを使用します。
dow = gl_obj.day_of_week print(dow.head()) dow_cat = dow.astype('category') print(dow_cat.head())
取得したものは次のとおりです。
0 Thu 1 Fri 2 Sat 3 Mon 4 Tue Name: day_of_week, dtype: object 0 Thu 1 Fri 2 Sat 3 Mon 4 Tue Name: day_of_week, dtype: category Categories (7, object): [Fri, Mon, Sat, Sun, Thu, Tue, Wed]
ご覧のとおり、列のタイプは変更されていますが、そこに格納されているデータは以前と同じに見えます。 それでは、プログラム内で何が起こっているのか見てみましょう。
次のコードでは、
Series.cat.codes
属性を使用して、
category
タイプが各曜日を表すために使用する整数値を見つけます。
dow_cat.head().cat.codes
私たちは次のことを見つけることができます。
0 4 1 0 2 2 3 1 4 5 dtype: int8
ここで、各一意の値に整数値が割り当てられ、列の型が
int8
いることがわかります。 欠損値はありませんが、その場合、-1を使用してそのような値を示します。
次に、
day_of_week
列を
category
タイプに変換する前後のメモリ消費量を比較しましょう。
print(mem_usage(dow)) print(mem_usage(dow_cat))
結果は次のとおりです。
9.84 MB
0.16 MB
ご覧のとおり、最初は9.84メガバイトのメモリが消費されていましたが、最適化後はわずか0.16メガバイトでした。これは、このインジケーターが98%改善されたことを意味します。 この列を使用すると、約172,000の要素を含む列で7つの一意の値のみが使用される場合に、最も収益性の高い最適化シナリオの1つを示すことができます。
すべての列をこのデータ型に変換するという考えは魅力的に見えますが、これを行う前に、このような変換の悪影響を考慮してください。 したがって、この変換の最も深刻なマイナス面は、カテゴリデータで算術演算を実行できないことです。 これは、通常の算術演算にも適用され、
Series.min()
や
Series.max()
などの
Series.max()
を、最初にデータを実数型に変換せずに使用する場合にも適用されます。
category
タイプの使用を、主に値の50%未満が一意であるタイプ
object
データを格納する列に制限する必要があり
category
。 列のすべての値が一意である場合、
category
タイプを使用するとメモリ使用量のレベルが上がります。 これは、数値カテゴリコードに加えて、元の文字列値をメモリに保存する必要があるためです。
category
タイプ制限の詳細はパンダのドキュメントで見つけることができます 。
object
型のデータを格納するすべての列を反復処理するループを作成し、列の一意の値の数が50%を超えているかどうかを確認し、そうであればそれらをtype
category
変換し
category
。
converted_obj = pd.DataFrame() for col in gl_obj.columns: num_unique_values = len(gl_obj[col].unique()) num_total_values = len(gl_obj[col]) if num_unique_values / num_total_values < 0.5: converted_obj.loc[:,col] = gl_obj[col].astype('category') else: converted_obj.loc[:,col] = gl_obj[col]
次に、最適化後に何が起こったのかを前に何が起こったのかと比較します。
print(mem_usage(gl_obj)) print(mem_usage(converted_obj)) compare_obj = pd.concat([gl_obj.dtypes,converted_obj.dtypes],axis=1) compare_obj.columns = ['before','after'] compare_obj.apply(pd.Series.value_counts)
次のものが得られます。
752.72 MB
51.67 MB
| に
| 後
| |
| 対象
| 78.0
| ナン
|
| カテゴリー
| ナン
| 78.0
|
category
, , , , , , , , .
, , ,
object
, 752 52 , 93%. , . , , , , 891 .
optimized_gl[converted_obj.columns] = converted_obj mem_usage(optimized_gl)
:
'103.64 MB'
. - . ,
datetime
, , , .
date = optimized_gl.date print(mem_usage(date)) date.head()
:
0.66 MB
:
0 18710504 1 18710505 2 18710506 3 18710508 4 18710509 Name: date, dtype: uint32
,
uint32
. -
datetime
, 64 .
datetime
, , , .
to_datetime()
,
format
,
YYYY-MM-DD
.
optimized_gl['date'] = pd.to_datetime(date,format='%Y%m%d') print(mem_usage(optimized_gl)) optimized_gl.date.head()
:
104.29 MB
:
0 1871-05-04 1 1871-05-05 2 1871-05-06 3 1871-05-08 4 1871-05-09 Name: date, dtype: datetime64[ns]
DataFrame
. , , , , , , , . , . , , , . , ,
DataFrame
, .
, . pandas.read_csv() , . ,
dtype
, , , , — NumPy.
, , . , .
dtypes = optimized_gl.drop('date',axis=1).dtypes dtypes_col = dtypes.index dtypes_type = [i.name for i in dtypes.values] column_types = dict(zip(dtypes_col, dtypes_type)) # 161 , # 10 / # preview = first2pairs = {key:value for key,value in list(column_types.items())[:10]} import pprint pp = pp = pprint.PrettyPrinter(indent=4) pp.pprint(preview) : { 'acquisition_info': 'category', 'h_caught_stealing': 'float32', 'h_player_1_name': 'category', 'h_player_9_name': 'category', 'v_assists': 'float32', 'v_first_catcher_interference': 'float32', 'v_grounded_into_double': 'float32', 'v_player_1_id': 'category', 'v_player_3_id': 'category', 'v_player_5_id': 'category'}
, , .
- :
read_and_optimized = pd.read_csv('game_logs.csv',dtype=column_types,parse_dates=['date'],infer_datetime_format=True) print(mem_usage(read_and_optimized)) read_and_optimized.head()
:
104.28 MB
,
.
,
, , , . pandas 861.6 104.28 , 88% .
, , , . .
optimized_gl['year'] = optimized_gl.date.dt.year games_per_day = optimized_gl.pivot_table(index='year',columns='day_of_week',values='date',aggfunc=len) games_per_day = games_per_day.divide(games_per_day.sum(axis=1),axis=0) ax = games_per_day.plot(kind='area',stacked='true') ax.legend(loc='upper right') ax.set_ylim(0,1) plt.show()

,
, 1920- , , 50 , .
, , , 50 , .
, .
game_lengths = optimized_gl.pivot_table(index='year', values='length_minutes') game_lengths.reset_index().plot.scatter('year','length_minutes') plt.show()
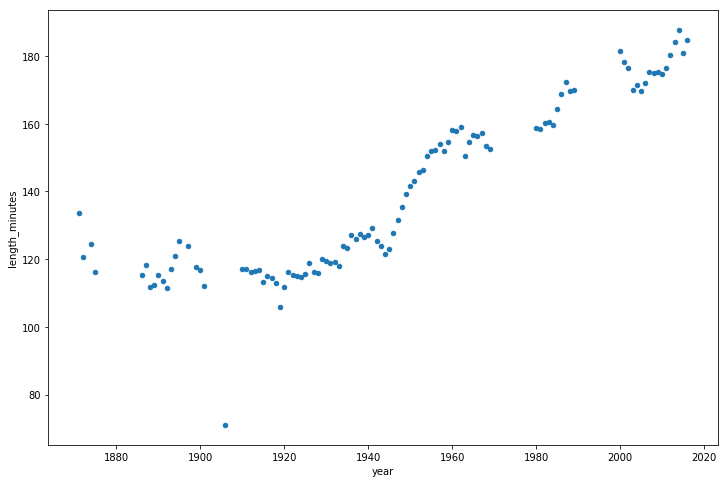
, 1940- .
まとめ
pandas, ,
DataFrame
, 90%. :
- , , , , .
- .
, , , , , , pandas, , .
親愛なる読者! eugene_bb . - , — .
