
タスク:
-Pythonの内部構造について学びます。
-抽象構文木(AST)を構築する原則を理解します。
-時間とメモリにより効率的なコードを記述します。
予備的な推奨事項:
-通訳者の仕事の基本的な理解(AST、トークンなど)。
-Pythonの知識。
-Cの基礎知識
batuhan@arch-pc ~/blogs/cpython/exec_model python --version Python 3.7.0
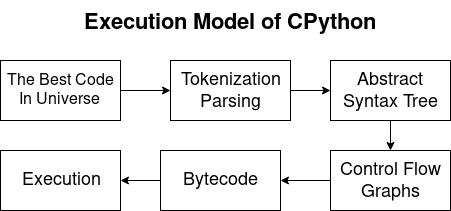
CPython実行モデル
Pythonは、コンパイルされ解釈された言語です。 したがって、Pythonコンパイラはバイトコードを生成し、インタープリターがそれらを実行します。 この記事では、次の問題について検討します。
- 解析とトークン化:
- ASTの変換。
- 制御フローグラフ(CFG);
- バイトコード
- CPython仮想マシンで実行します。
解析とトークン化。
文法。
文法は、Python言語のセマンティクスを定義します。 また、パーサーが言語を解釈する方法を示すのにも役立ちます。 Pythonの文法では、拡張バッカスナウア形式に似た構文を使用します。 ソース言語の翻訳者用の独自の文法があります。 文法ファイルは「cpython / Grammar / Grammar」ディレクトリにあります。
以下は文法の例です、
batuhan@arch-pc ~/cpython/Grammar master grep "simple_stmt" Grammar | head -n3 | tail -n1 simple_stmt: small_stmt (';' small_stmt)* [';'] NEWLINE
単純な式には小さな式と角かっこが含まれ、コマンドは新しい行で終了します。 小さな式は、インポートする式のリストのように見えます...
他のいくつかの表現:)
small_stmt: (expr_stmt | del_stmt | pass_stmt | flow_stmt | import_stmt | global_stmt | nonlocal_stmt | assert_stmt) ... del_stmt: 'del' exprlist pass_stmt: 'pass' flow_stmt: break_stmt | continue_stmt | return_stmt | raise_stmt | yield_stmt break_stmt: 'break' continue_stmt: 'continue'
トークン化(Lexing)
トークン化は、テキストデータストリームを取得し、追加のメタデータを使用して重要な(インタープリター用)単語のトークンに分割するプロセスです(たとえば、トークンの開始位置と終了位置、このトークンの文字列値など)。
トークン
トークンは、すべてのトークンの定義を含むヘッダーファイルです。 Pythonには59種類のトークン(Include / token.h)があります。
以下はその一部の例です。
#define NAME 1 #define NUMBER 2 #define STRING 3 #define NEWLINE 4 #define INDENT 5 #define DEDENT 6
いくつかのPythonコードをトークンに分割すると表示されます。
CLIによるトークン化
これがtests.pyファイルです
def greetings(name: str): print(f"Hello {name}") greetings("Batuhan")
次に、python -m tokenizeコマンドを使用してトークン化し、次のように出力します。
batuhan@arch-pc ~/blogs/cpython/exec_model python -m tokenize tests.py 0,0-0,0: ENCODING 'utf-8' ... 2,0-2,4: INDENT ' ' 2,4-2,9: NAME 'print' ... 4,0-4,0: DEDENT '' ... 5,0-5,0: ENDMARKER ''
ここで、数字(たとえば、1.4-1.13)は、トークンの開始位置と終了位置を示します。 エンコードトークンは、常に最初に受け取るトークンです。 ソースファイルのエンコードに関する情報を提供し、問題がある場合、インタープリターは例外をスローします。
tokenize.tokenizeによるトークン化
コードからファイルをトークン化する必要がある場合は、 stdlibの tokenizeモジュールを使用できます。
>>> with open('tests.py', 'rb') as f: ... for token in tokenize.tokenize(f.readline): ... print(token) ... TokenInfo(type=57 (ENCODING), string='utf-8', start=(0, 0), end=(0, 0), line='') ... TokenInfo(type=1 (NAME), string='greetings', start=(1, 4), end=(1, 13), line='def greetings(name: str):\n') ... TokenInfo(type=53 (OP), string=':', start=(1, 24), end=(1, 25), line='def greetings(name: str):\n') ...
トークンのタイプは、 token.hヘッダーファイルのIDです。 文字列はトークンの値です。 開始と終了は、それぞれトークンの開始位置と終了位置を示します。
他の言語では、ブロックは括弧または開始/終了ステートメントで示されますが、Pythonはインデントと異なるレベルを使用します。 INDENTおよびDEDENTトークンとインデントを示します。 これらのトークンは、リレーショナル解析ツリーおよび/または抽象構文ツリーを構築するために必要です。
パーサーの生成
パーサー生成-所定の文法に従ってパーサーを生成するプロセス。 パーサージェネレーターはPGenとして知られています。 Cpythonには2つのパーサージェネレーターがあります。 1つはオリジナル(
Parser/pgen
)で、もう1つはPython(
/Lib/lib2to3/pgen2
)で書き直されています。
「元のジェネレータは、私がPython向けに書いた最初のコードでした」
-ガイド
上記の引用から、 pgenはプログラミング言語で最も重要なものであることが明らかになります。 ( Parser / pgenで )pgenを呼び出すと、ヘッダーファイルとCファイル(パーサー自体)が生成されます。 生成されたCコードを見ると、意味のある外観はオプションであるため、無意味に見えるかもしれません。 多数の静的データと構造が含まれています。 さらに、その主なコンポーネントを説明しようとします。
DFA(定義済みステートマシン)
パーサーは、非端末ごとに1つのDFAを定義します。 各DFAは、状態の配列として定義されます。
static dfa dfas[87] = { {256, "single_input", 0, 3, states_0, "\004\050\340\000\002\000\000\000\012\076\011\007\262\004\020\002\000\300\220\050\037\202\000"}, ... {342, "yield_arg", 0, 3, states_86, "\000\040\200\000\002\000\000\000\000\040\010\000\000\000\020\002\000\300\220\050\037\000\000"}, };
各DFAには、特別な非ターミナルがどのトークンで開始できるかを示すスターターキットがあります。
状態
各状態は、遷移/エッジ(アーク)の配列によって定義されます。
static state states_86[3] = { {2, arcs_86_0}, {1, arcs_86_1}, {1, arcs_86_2}, };
遷移(アーク)
各遷移配列には2つの番号があります。 最初の番号は遷移の名前(アークラベル)で、シンボル番号を指します。 2番目の番号は宛先です。
static arc arcs_86_0[2] = { {77, 1}, {47, 2}, }; static arc arcs_86_1[1] = { {26, 2}, }; static arc arcs_86_2[1] = { {0, 2}, };
名前(ラベル)
これは、シンボルのIDを遷移の名前にマップする特別なテーブルです。
static label labels[177] = { {0, "EMPTY"}, {256, 0}, {4, 0}, ... {1, "async"}, {1, "def"}, ... {1, "yield"}, {342, 0}, };
番号1はすべての識別子に対応します。 したがって、それらがすべて同じ文字IDを持っている場合でも、それぞれが異なる遷移名を取得します。
簡単な例:
1-trueの場合、「Hi」を出力するコードがあるとします。
if 1: print('Hi')
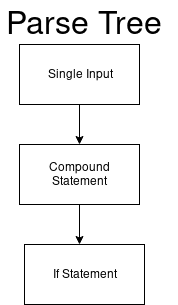
パーサーはこのコードをsingle_inputと見なします。
single_input: NEWLINE | simple_stmt | compound_stmt NEWLINE
次に、解析ツリーは、1回限りの入力のルートノードから始まります。

そして、DFA(single_input)の値は0です。
static dfa dfas[87] = { {256, "single_input", 0, 3, states_0, "\004\050\340\000\002\000\000\000\012\076\011\007\262\004\020\002\000\300\220\050\037\202\000"} ... }
次のようになります。
static arc arcs_0_0[3] = { {2, 1}, {3, 1}, {4, 2}, }; static arc arcs_0_1[1] = { {0, 1}, }; static arc arcs_0_2[1] = { {2, 1}, }; static state states_0[3] = { {3, arcs_0_0}, {1, arcs_0_1}, {1,
arcs_0_2}、
};
ここで、
arc_0_0
は3つの要素で構成されています。 最初は
NEWLINE
、2番目は
simple_stmt
、最後は
compound_stmt
です。
simple_stmt
の初期セットを考えると、
simple_stmt
は
if
開始できないと結論付けることができます。 ただし、
if
が新しい行ではない
if
でも、
compound_stmt
は
if
開始できます。 したがって、最後の
arc ({4;2})
から行って、
compound_stmt
ノードを解析ツリーに追加し、2番目に移動する前に新しいDFAに切り替えます。 更新された解析ツリーを取得します。

新しいDFAは複合ステートメントを解析します。
compound_stmt: if_stmt | while_stmt | for_stmt | try_stmt | with_stmt | funcdef | classdef | decorated | async_stmt
そして、次のものが得られます。
static arc arcs_39_0[9] = { {91, 1}, {92, 1}, {93, 1}, {94, 1}, {95, 1}, {19, 1}, {18, 1}, {17, 1}, {96, 1}, }; static arc arcs_39_1[1] = { {0, 1}, }; static state states_39[2] = { {9, arcs_39_0}, {1, arcs_39_1}, };
if
始まるのは最初のジャンプのみ
if
。 更新された解析ツリーを取得します。
次に、DFAを再度変更し、次のDFAがifsを解析します。
if_stmt: 'if' test ':' suite ('elif' test ':' suite)* ['else' ':' suite]
その結果、指定97の遷移のみが取得されます。これは
if
トークンと一致します。
static arc arcs_41_0[1] = { {97, 1}, }; static arc arcs_41_1[1] = { {26, 2}, }; static arc arcs_41_2[1] = { {27, 3}, }; static arc arcs_41_3[1] = { {28, 4}, }; static arc arcs_41_4[3] = { {98, 1}, {99, 5}, {0, 4}, }; static arc arcs_41_5[1] = { {27, 6}, }; static arc arcs_41_6[1] = { {28, 7}, }; ...
同じDFAのままで次の状態に切り替えると、次のarcs_41_1にも1つの遷移しかありません。 これはテスト端末にも当てはまります。 数字(たとえば、1)で始まる必要があります。
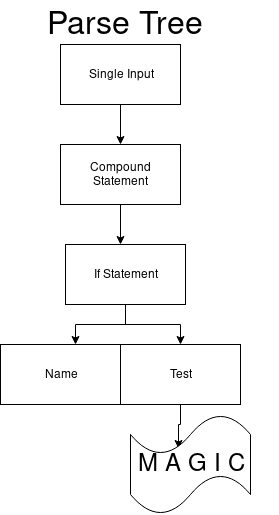
コロントークン(:)を受け取るarc_41_2には遷移が1つしかありません。

したがって、印刷値で開始できるセットを取得します。 最後に、arcs_41_4に移動します。 セット内の最初の遷移はelif式であり、2番目はelseであり、3番目は最後の状態です。 そして、解析ツリーの最終ビューを取得します。

パーサー用のPythonインターフェイス。
Pythonでは、パーサーと呼ばれるモジュールを使用して、式の解析ツリーを編集できます。
>>> import parser >>> code = "if 1: print('Hi')"
parser.suiteを使用して、特定の構文ツリー(Concrete Syntax Tree、CST)を生成できます。
>>> parser.suite(code).tolist() [257, [269, [295, [297, [1, 'if'], [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [2, '1']]]]]]]]]]]]]]]], [11, ':'], [304, [270, [271, [272, [274, [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [1, 'print']], [326, [7, '('], [334, [335, [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [3, "'Hi'"]]]]]]]]]]]]]]]]]], [8, ')']]]]]]]]]]]]]]]]]]], [4, '']]]]]], [4, ''], [0, '']]
出力値はネストされたリストになります。 構造内の各リストには2つの要素があります。 最初は文字のID(0-256-端末、256 +-非端末)で、2番目は端末のトークンの文字列です。
抽象構文ツリー
実際、抽象構文ツリー(AST)は、各頂点が異なる種類の言語構成要素(式、変数、演算子など)を表すツリー形式のソースコードの構造表現です。
木とは何ですか?
ツリーは、始点としてルート頂点を持つデータ構造です。 ルート頂点は、分岐(遷移)によって他の頂点まで下げられます。 ルートを除く各頂点には、一意の親頂点が1つあります。
抽象構文ツリーと構文解析ツリーの間には一定の違いがあります。
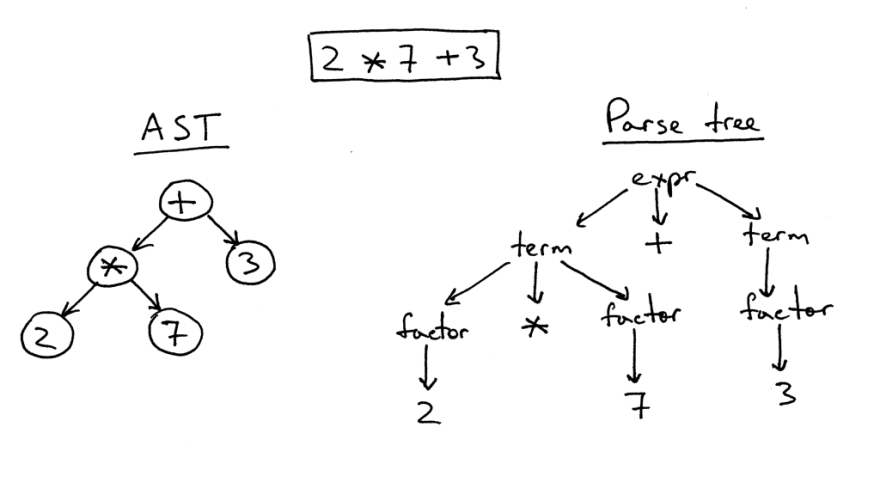
右側には、式2 * 7 + 3の解析ツリーがあります。 これは文字通り、ツリー内のソースコードの1対1のイメージです。 すべての式、用語、値が表示されます。 ただし、このようなイメージは単純なコードでは複雑すぎるため、計算のためにコードで定義する必要があったすべての構文表現を単純に削除できます。
このような単純化されたツリーは、抽象構文ツリー(AST)と呼ばれます。 図の左側には、同じコードに対して正確に示されています。 すべての構文表現は理解を容易にするために破棄されましたが、特定の情報が失われたことを覚えておいてください。
例
Pythonは、ASTを操作するための組み込みASTモジュールを提供します。 ASTツリーからコードを生成するには、 Astorなどのサードパーティモジュールを使用できます。
たとえば、以前と同じコードを考えます。
>>> import ast >>> code = "if 1: print('Hi')"
ASTを取得するには、ast.parseメソッドを使用します。
>>> tree = ast.parse(code) >>> tree <_ast.Module object at 0x7f37651d76d8>
ast.dump
メソッドを使用して、より読みやすい抽象構文ツリーを取得してください。
>>> ast.dump(tree) "Module(body=[If(test=Num(n=1), body=[Expr(value=Call(func=Name(id='print', ctx=Load()), args=[Str(s='Hi')], keywords=[]))], orelse=[])])"
ASTは一般に、構文解析ツリーよりも視覚的で理解しやすいと考えられています。
制御フローグラフ(CFG)
制御フローグラフは、中間表現を含むベースブロックを使用してプログラムのフローをモデル化する方向グラフです。
通常、CFGはコード出力値を取得する前の前の手順です。 コードは、CFGの後方からの深さ検索を使用して、先頭から順にベースブロックから直接生成されます。
バイトコード
Pythonバイトコードは、Python仮想マシンで動作する命令の中間セットです。 ソースコードを実行すると、Pythonは__pycache__というディレクトリを作成します。 コンパイルを再開する場合に時間を節約するために、コンパイルされたコードを保存します。
func.pyの単純なPython関数を考えてください。
def say_hello(name: str): print("Hello", name) print(f"How are you {name}?")
>>> from func import say_hello >>> say_hello("Batuhan") Hello Batuhan How are you Batuhan?
say_hello
オブジェクト
say_hello
は関数です。
>>> type(say_hello) <class 'function'>
__code__
属性があります。
>>> say_hello.__code__ <code object say_hello at 0x7f13777d9150, file "/home/batuhan/blogs/cpython/exec_model/func.py", line 1>
コードオブジェクト
コードオブジェクトは、コードの実行に必要な命令またはメタデータを含む不変のデータ構造です。 簡単に言えば、これらはPythonコードの表現です。 compileメソッドを使用して抽象構文ツリーをコンパイルすることにより、コードオブジェクトを取得することもできます。
>>> import ast >>> code = """ ... def say_hello(name: str): ... print("Hello", name) ... print(f"How are you {name}?") ... say_hello("Batuhan") ... """ >>> tree = ast.parse(code, mode='exec') >>> code = compile(tree, '<string>', mode='exec') >>> type(code) <class 'code'>
各コードオブジェクトには、特定の情報(co_で始まる)を含む属性があります。 ここでは、そのうちのほんのいくつかについて言及します。
co_name
手始めに、名前。 関数が存在する場合は、それぞれ名前を付ける必要があります。この名前は関数の名前になります。クラスと同様の状況です。 ASTの例では、モジュールを使用し、コンパイラーにそれらの名前を正確に伝えることができます。 それらを単なる
module
。
>>> code.co_name '<module>' >>> say_hello.__code__.co_name 'say_hello'
co_varnames
これは、引数を含むすべてのローカル変数を含むタプルです。
>>> say_hello.__code__.co_varnames ('name',)
co_conts
関数の本体でアクセスしたすべてのリテラルと定数値を含むタプル。 値Noneに注目する価値があります。 関数の本体にはNoneを含めませんでしたが、Pythonはそれを示しました。関数が実行を開始し、戻り値を受け取らずに終了すると、Noneを返すためです。
>>> say_hello.__code__.co_consts (None, 'Hello', 'How are you ', '?')
バイトコード(co_code)
以下は関数のバイトコードです。
>>> bytecode = say_hello.__code__.co_code >>> bytecode b't\x00d\x01|\x00\x83\x02\x01\x00t\x00d\x02|\x00\x9b\x00d\x03\x9d\x03\x83\x01\x01\x00d\x00S\x00'
これは文字列ではなく、バイトオブジェクト、つまりバイトのシーケンスです。
>>> type(bytecode) <class 'bytes'>
印刷される最初の文字は「t」です。 数値を求めると、次のようになります。
>>> ord('t') 116
116はバイトコード[0]と同じです。
>>> assert bytecode[0] == ord('t')
私たちにとって、値116は何も意味しません。 幸いなことに、Pythonはdis(from disassembly)という標準ライブラリを提供しています。 opnameリストを使用する場合に役立ちます。 これは、すべてのバイトコード命令のリストです。各インデックスは命令の名前です。
>>> dis.opname[ord('t')] 'LOAD_GLOBAL'
別のより複雑な関数を作成しましょう。
>>> def multiple_it(a: int): ... if a % 2 == 0: ... return 0 ... return a * 2 ... >>> multiple_it(6) 0 >>> multiple_it(7) 14 >>> bytecode = multiple_it.__code__.co_code
そして、バイトコードの最初の命令を見つけます。
>>> dis.opname[bytecode[0]] 'LOAD_FAST
LOAD_FASTステートメントは2つの要素で構成されます。
>>> dis.opname[bytecode[0]] + ' ' + dis.opname[bytecode[1]] 'LOAD_FAST <0>'
Loadfast 0命令は、タプル内の変数名を検索し、ゼロインデックスを持つ要素を実行スタック内のタプルにプッシュします。
>>> multiple_it.__code__.co_varnames[bytecode[1]] 'a'
コードはdis.disを使用して逆アセンブルし、バイトコードを使い慣れた形式に変換できます。 ここで、数字(2,3,4)は行番号です。 Pythonの各コード行は、一連の命令として展開されます。
>>> dis.dis(multiple_it) 2 0 LOAD_FAST 0 (a) 2 LOAD_CONST 1 (2) 4 BINARY_MODULO 6 LOAD_CONST 2 (0) 8 COMPARE_OP 2 (==) 10 POP_JUMP_IF_FALSE 16 3 12 LOAD_CONST 2 (0) 14 RETURN_VALUE 4 >> 16 LOAD_FAST 0 (a) 18 LOAD_CONST 1 (2) 20 BINARY_MULTIPLY 22 RETURN_VALUE
リードタイム
CPythonはスタック指向の仮想マシンであり、レジスタのコレクションではありません。 これは、スタックアーキテクチャの仮想マシン用にPythonコードがコンパイルされることを意味します。
関数を呼び出すとき、Pythonは2つのスタックを一緒に使用します。 1つ目は実行スタックで、2つ目はブロックのスタックです。 ほとんどの呼び出しは実行スタックで発生します。 ブロックスタックは、現在アクティブなブロックの数、およびブロックとスコープに関連する他のパラメーターを追跡します。
マテリアルに関するコメントをお待ちしており、トピック「公開:信頼できるソフトウェアのリリースの実用的側面」に関する公開ウェビナーにご招待します。これは、教師-Mail.Ru- Stanislav Stupnikovの広告システムのプログラマーによって実施されます。