データ
k-meansクラスタリングアルゴリズムを説明するために、ニューヨークの無料パブリックWiFiに地理データベースを使用します。 データセットはNYC Open Dataで入手できます。 特に、k-meansクラスタリングアルゴリズムを使用して、緯度と経度のデータに基づいてWiFi使用クラスターを形成します。
緯度と経度のデータは、プログラミング言語Rを使用してデータセット自体から抽出されます。
#1. Prepare data newyork<-read.csv("NYC_Free_Public_WiFi_03292017.csv") attach(newyork) newyorkdf<-data.frame(newyork$LAT,newyork$LON)
データの一部は次のとおりです。
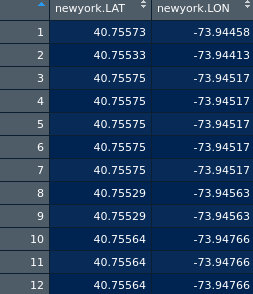
クラスターの数を決定します
次に、以下のコードを使用してクラスターの数を決定します。このコードは結果をグラフで示します。
#2. Determine number of clusters wss <- (nrow(newyorkdf)-1)*sum(apply(newyorkdf,2,var)) for (i in 2:20) wss[i] <- sum(kmeans(newyorkdf, centers=i)$withinss) plot(1:20, wss, type="b", xlab="Number of Clusters", ylab="Within groups sum of squares")
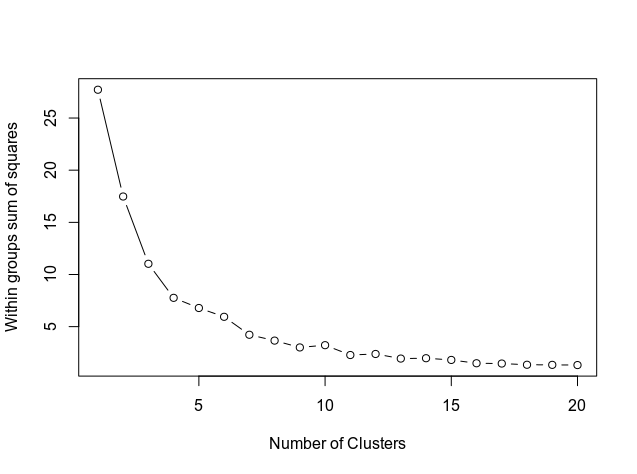
グラフは、曲線が約11でどのように整列するかを示しています。したがって、これはk-meansモデルで使用されるクラスターの数です。
K平均分析
K-meansの分析が実行されます。
#3. K-Means Cluster Analysis set.seed(20) fit <- kmeans(newyorkdf, 11) # 11 cluster solution # get cluster means aggregate(newyorkdf,by=list(fit$cluster),FUN=mean) # append cluster assignment newyorkdf <- data.frame(newyorkdf, fit$cluster) newyorkdf newyorkdf$fit.cluster <- as.factor(newyorkdf$fit.cluster) library(ggplot2) ggplot(newyorkdf, aes(x=newyork.LON, y=newyork.LAT, color = newyorkdf$fit.cluster)) + geom_point()
newyorkdfデータセットには、緯度、経度、クラスターラベルに関する情報が含まれています。
> newyorkdf
newyork.lat newyork.lon fit.cluster
1 40.75573 -73.94458 1
2 40.75533 -73.94413 1
3 40.75575 -73.94517 1
4 40.75575 -73.94517 1
5 40.75575 -73.94517 1
6 40.75575 -73.94517 1
...
80 40.84832 -73.82075 11
明確な説明を次に示します。
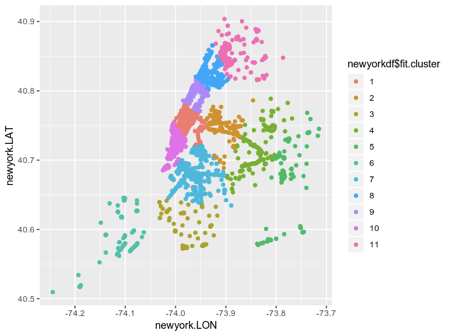
この図は役立ちますが、ニューヨーク自体の地図にオーバーレイすると、レンダリングはさらに価値があります。
# devtools::install_github("zachcp/nycmaps") library(nycmaps) map(database="nyc") #this should also work with ggplot and ggalt nyc <- map_data("nyc") gg <- ggplot() gg <- gg + geom_map( data=nyc, map=nyc, aes(x=long, y=lat, map_id=region)) gg + geom_point(data = newyorkdf, aes(x = newyork.LON, y = newyork.LAT), colour = newyorkdf$fit.cluster, alpha = .5) + ggtitle("New York Public WiFi")

このタイプのクラスタリングは、都市のWiFiネットワークの構造に関する優れたアイデアを提供します。 これは、クラスター1でマークされた地理的領域が多くのWiFiトラフィックを示していることを示しています。 一方、クラスター6の接続が少ない場合は、WiFiトラフィックが少ないことを示している可能性があります。
K-Meansクラスタリングだけでは、特定のクラスターのトラフィックが高いまたは低い理由がわかりません。 たとえば、クラスター6の人口密度は高いが、インターネット速度が低いと接続数が少なくなる場合。
ただし、このクラスタリングアルゴリズムは、さらなる分析のための優れた出発点となり、追加情報の収集を容易にします。 たとえば、このマップを例として使用すると、個々の地理的クラスターに関する仮説を立てることができます。 元の記事はこちらです。