したがって、すべての雇用主が要求するため、これらの技術を研究する必要があります。 しかし、最初から最後まですべてのドキュメントを読むことから始めることはあまり面白くない。 私の意見では、導入部を読み、実用的なプロトタイプを作成し、エラーを修正し、問題にぶつかり、解決する方が生産的です。 そして、このすべての後、理解して、ドキュメント、または別の本を読んでください。

短期間でこれらの製品の基本的な機能を知りたいと思っている人は、読んでください。
トレーニングプログラムは数を考慮します。 それは、大きな番号ジェネレータ、番号プロセッサ、キュー、列ストレージ、およびWebサーバーで構成されます。
開発中に、次の設計パターンが適用されます。
システムアーキテクチャは次のようになります。
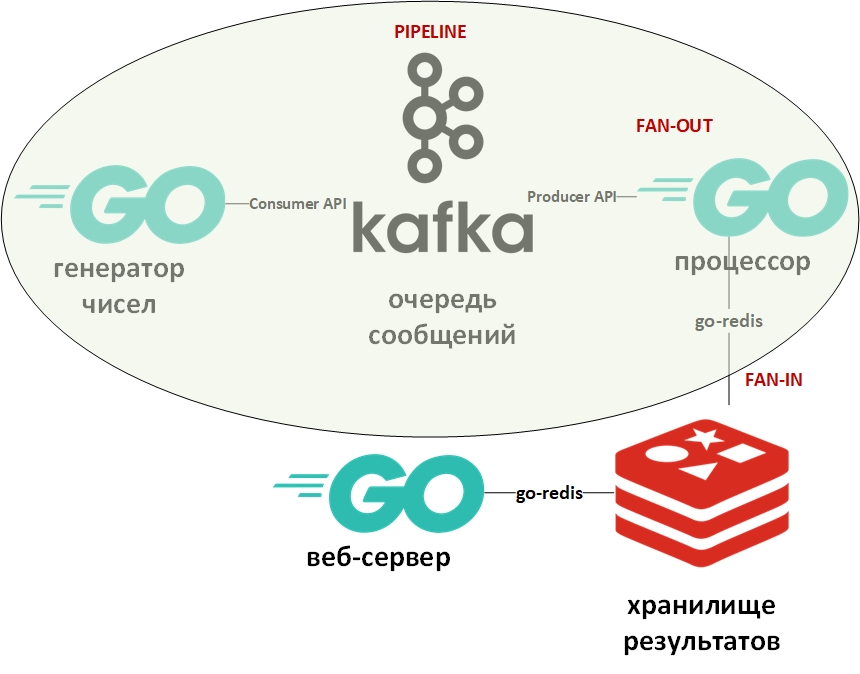
写真の楕円形は、コンベアの設計パターンを示しています。 これについて詳しく説明します。
テンプレート「コンベヤ」は、情報がストリームの形式で提供され、段階的に処理されることを前提としています。 通常、ジェネレーター(情報のソース)と1つ以上のプロセッサー(情報プロセッサー)があります。 この場合、ジェネレーターはGoのプログラムで、ランダムな大きな数字をキューに入れます。 そして、プロセッサ(唯一のプロセッサ)は、キューからデータを取得して因数分解を実行するプログラムになります。 純粋なGoでは、このパターンはchanチャンネルを使用して簡単に実装できます。 上の例には、私のgithubへのリンクがあります。 ここでは、メッセージキューがチャネルの役割を果たします。
ファンイン-ファンアウトテンプレートは通常一緒に使用され、Goに適用される場合、ゴルーチンを使用した計算の並列化を意味し、その後、結果を要約して、たとえばパイプラインのさらに下に転送します。 例へのリンクも上記にあります。 繰り返しになりますが、チャネルはキューに置き換えられ、ゴルーチンはそのまま残りました。
次に、Apache Kafkaについて少し説明します。 Kafkaは、トランザクションログ(RDBMSとまったく同じ)を使用してメッセージを保存し、キューモデルとパブリッシャー/サブスクライバーモデルの両方をサポートする優れたクラスタリングツールを備えたメッセージ管理システムです。 後者は、メッセージ受信者のグループを通じて実現されます。 各メッセージはグループのメンバーを1つだけ受信します(並列処理)が、メッセージは各グループに1回配信されます。 このようなグループは多数存在する可能性があり、各グループ内に受信者が存在する可能性があります。
Kafkaと連携するには、パッケージ「github.com/segmentio/kafka-go」を使用します。
一方、Redisは、データを永続的に保存する機能をサポートするメモリ内のキーと値のデータベース列です。 キーと値の主なデータ型は文字列ですが、他にもいくつかあります。 Redisは、このクラスで最速(またはほとんど)のデータベースの1つと見なされています。 あらゆる種類の統計、メトリック、メッセージフローなどを保存すると便利です。
Redisを使用するには、「github.com/go-redis/redis」パッケージを使用します。
この記事はクイックスタートなので、DockerHubで既製のイメージを使用して、Dockerを使用して両方のシステムを展開します。 次のように、このdocker-compose.ymlファイルを使用して、Linux VM(Docker VMによって自動的に作成されます)のコンテナーモードでWindows 10のdocker-composeを使用します。
version: '2' services: zookeeper: image: wurstmeister/zookeeper ports: - "2181:2181" kafka: image: wurstmeister/kafka:latest ports: - "9092:9092" environment: KAFKA_ADVERTISED_HOST_NAME: 127.0.0.1 KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181 KAFKA_CREATE_TOPICS: "Generated:1:1,Solved:1:1,Unsolved:1:1" KAFKA_DELETE_TOPIC_ENABLE: "true" volumes: - /var/run/docker.sock:/var/run/docker.sock redis: image: redis ports: - "6379:6379"
このファイルを保存し、そのディレクトリに移動して実行します:
docker-compose up -d
3つのコンテナーをダウンロードして開始する必要があります:Kafka(キュー)、Zookeeper(Kafkaの構成サーバー)、および(Redis)。
次のコマンドを使用して、コンテナが機能することを確認できます。
docker-compose ps
次のようになります。
Name State Ports -------------------------------------------------------------------------------------- docker-compose_kafka_1 Up 0.0.0.0:9092->9092/tcp docker-compose_redis_1 Up 0.0.0.0:6379->6379/tcp docker-compose_zookeeper_1 Up 0.0.0.0:2181->2181/tcp, 22/tcp, 2888/tcp, 3888/tcp
ymlファイルによると、3つのキューが自動的に作成されるはずです。次のコマンドで確認できます。
docker exec kafka-container_kafka_1 /opt/kafka_2.12-2.1.0/bin/kafka-topics.sh --list --zookeeper zookeeper:2181
キュー(トピック-Kafkaの観点からのトピック)が生成され、解決され、未解決である必要があります。
データジェネレーターは、ランダムな遅延で無限に数を並べます。 そのコードは非常に簡単です。 次のコマンドを使用して、生成されたキュー内のメッセージの存在を確認できます。
docker exec kafka-container_kafka_1 /opt/kafka_2.12-2.1.0/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic Generated --from-beginning
次はプロセッサです。ここでは、次のコードブロックのキューからの値の処理を並列化することに注意する必要があります。
var wg sync.WaitGroup c := 0 //counter for { // 15 ctx, cancel := context.WithTimeout(context.Background(), 15*time.Second) defer cancel() // // - m, err := r.ReadMessage(ctx) if err != nil { fmt.Println("3") fmt.Println(err) break } wg.Add(1) // 10 goCtx, goCcancel := context.WithTimeout(context.Background(), 10*time.Millisecond) defer goCcancel() // () go process(goCtx, c, &wg, m) c++ } // wg.Wait()
メッセージキューから読み取るとプログラムがブロックされるため、15秒のタイムアウトでcontext.Contextオブジェクトを作成しました。 このタイムアウトは、キューが長時間空の場合にプログラムを終了します。
また、数値を因数分解するゴルチンごとに、最大動作時間も設定されます。 因数分解できる数値を1つのデータベースに書き込む必要がありました。 そして、割り当てられた時間で因数分解できなかった数値は、別のデータベースに転送されました。
おおよその時間を決定するために、ベンチマークが使用されました。
func BenchmarkFactorize(b *testing.B) { ch := make(chan []int) var factors []int for i := 1; i < bN; i++ { num := 2345678901234 go factorize(num, ch) factors = <-ch b.Logf("\n%d %+v\n\n", num, factors) } }
Goのベンチマークはさまざまなテストであり、テストと共にファイルに配置されます。 この測定に基づいて、乱数ジェネレーターの最大数が選択されました。 私のコンピューターでは、数字の一部に因数分解する時間があり、一部ではありません。
分解できる数値はDB No. 0に、分解されない数値はDB No. 1に書き込まれました。
ここで、Redisには古典的な意味でのスキーマとテーブルは存在しないと言わなければなりません。 デフォルトでは、DBMSにはプログラマが使用できる16個のデータベースが含まれています。 これらのベースは、0から15までの数が異なります。
プロセッサ内のゴルーチンの時間制限は、コンテキストとselectステートメントを使用して提供されました。
// go factorize(n, outChan) var item data select { case factors = <-outChan: { fmt.Printf("\ngoroutine #%d, input: %d, factors: %+v\n", counter, n, factors) item.Number = n item.Factors = factors err = storeSolved(item) if err != nil { fmt.Println("6") log.Fatal(err) } } case <-ctx.Done(): { fmt.Printf("\ngoroutine #%d, input: %d, exited on context timeout\n", counter, n) err = storeUnsolved(n) if err != nil { fmt.Println("7") log.Fatal(err) } return nil } }
これは、Goでの典型的な開発トリックの1つです。 その意味は、selectステートメントがチャネルを反復処理し、最初のアクティブなチャネルに対応するコードを実行することです。 この場合、ゴルーチンは結果をそのチャネルに出力するか、タイムアウトのあるコンテキストチャネルを閉じます。 コンテキストの代わりに、マネージャーとして機能し、ゴルーチンの強制終了を提供する任意のチャネルを使用できます。
データベースに書き込むためのサブルーチンは、コマンドを実行して目的のデータベース(0または1)を選択し、解析された数値の形式(数値-因子)または分解されていない数値の(数値-数値)のペアを書き込みます。
func storeSolved(item data) (err error) { // 0 cmd := redis.NewStringCmd("select", 0) err = client.Process(cmd) b, err := json.Marshal(item.Factors) err = client.Set(strconv.Itoa(item.Number), string(b), 0).Err() return err }
最後の部分はWebサーバーになり 、jsonの形式で分解された数値と未分解の数値のリストが表示されます。 彼には2つのエンドポイントがあります。
http.HandleFunc("/solved", solvedHandler) http.HandleFunc("/unsolved", unsolvedHandler)
Redisからデータを受信し、jsonとしてデータを返すhttpリクエストハンドラは次のようになります。
func solvedHandler(w http.ResponseWriter, r *http.Request) { w.Header().Set("Content-Type", "application/json") w.Header().Set("Access-Control-Allow-Origin", "*") w.Header().Set("Access-Control-Allow-Methods", "GET") w.Header().Set("Access-Control-Allow-Headers", "Accept, Content-Type, Content-Length, Accept-Encoding, X-CSRF-Token, Authorization") // №0 - cmd := redis.NewStringCmd("select", 0) err := client.Process(cmd) if err != nil { w.WriteHeader(http.StatusInternalServerError) return } // keys := client.Keys("*") var solved []data var item data // for _, key := range keys.Val() { item.Key = key val, err := client.Get(key).Result() if err != nil { w.WriteHeader(http.StatusInternalServerError) return } item.Val = val solved = append(solved, item) } // JSON err = json.NewEncoder(w).Encode(solved) if err != nil { w.WriteHeader(http.StatusInternalServerError) return } }
リクエストの結果: localhost /解決済み
[{ "Key": "1604388558816", "Val": "[1,2,3,227]" }, { "Key": "545232916387", "Val": "[1,545232916387]" }, { "Key": "1786301239076", "Val": "[1,2]" }, { "Key": "698495534061", "Val": "[1,3,13,641,165331]" }]
これで、ドキュメントと専門文献を詳しく調べることができます。 記事がお役に立てば幸いです。
専門家に怠けすぎないように頼み、私の間違いを指摘します。