シリーズ「Spring Bootでのアプリケーションのテスト駆動開発」の2番目の記事と今回は、統合テストの重要な側面であるデータベースへのアクセスのテストについて説明します。 テストによるデータアクセスの将来のサービスのインターフェイスを決定する方法、テストに組み込みのインメモリデータベースを使用する方法、トランザクションを操作する、データベースにテストデータをアップロードする方法について説明します。
一般にTDDとテストについてはあまり話しません。最初の記事- トランクにピラミッドを構築する方法、またはSpring Boot / geekマガジンのアプリケーションのテスト駆動開発について読んでください。
前回と同様に、小さな理論的な部分から始めて、エンドツーエンドのテストに進みます。
ピラミッドのテスト
まず、 テストピラミッドやテストピラミッドなど、テストにおける重要なエンティティの小さいながらも必要な説明。
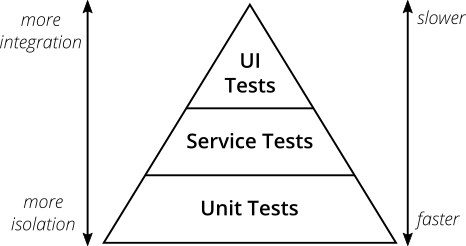
( 実地試験ピラミッドから取得)
テストピラミッドは、テストが複数のレベルで編成されている場合のアプローチです。
- UI (またはエンドツーエンド、 E2E )テストは少数であり、低速ですが、実際のアプリケーションをテストします-モックや対応するテストはありません。 ビジネスはしばしばこのレベルで考え、すべてのBDDフレームワークがここに存在します(前の記事のCucumberを参照)。
- その後、 統合テスト (サービス、コンポーネント-それぞれ独自の用語があります)が続き、システムの特定のコンポーネント(サービス)にすでに焦点を当て、moki / doublesを介して他のコンポーネントから分離しますが、実際の外部システムとの統合を確認します-これらのテストは接続されていますデータベースにRESTリクエストを送信し、メッセージキューを操作します。 実際、これらはビジネスロジックと外界との統合を検証するテストです。
- 一番下には、最小限のコードブロック(クラス、メソッド)を完全に分離してテストするクイックユニットテストがあります。
ユニットテストの世界ではフレームワークに関する知識がまったく存在しないため、Springは各レベルのテストの作成を支援します。 E2Eテストを作成した後、Springがコントローラーのような純粋に「統合」されたものでさえ、単独でテストできることを示します。
しかし、ピラミッドの最上部から始めましょう-本格的なアプリケーションを開始してテストする遅いUIテストです。
エンドツーエンドのテスト
そのため、新しい機能:
Feature: A list of available cakes Background: catalogue is updated Given the following items are promoted | Title | Price | | Red Velvet | 3.95 | | Victoria Sponge | 5.50 | Scenario: a user visiting the web-site sees the list of items Given a new user, Alice When she visits Cake Factory web-site Then she sees that "Red Velvet" is available with price £3.95 And she sees that "Victoria Sponge" is available with price £5.50
そして、ここにすぐに興味深い側面があります-メインページのあいさつについて、前のテストで何をすべきか? メインページでサイトを立ち上げた後は、挨拶ではなくディレクトリが既に存在するようになります。 単一の答えはありません、私は言うでしょう-それは状況に依存します。 しかし、主なアドバイス-テストに添付しないでください! 関連性が失われたら削除し、読みやすくするために書き直します。 特にE2Eテスト-これは、実際、 活発で最新の仕様であるべきです。 私の場合、以前のステップをいくつか使用し、存在しないテストを追加して、古いテストを削除し、新しいテストに置き換えました。
今、私は重要なポイントに来ました-データを保存するための技術の選択。 リーンアプローチに従って、私は選択を最後の瞬間まで延期したいと思います。リレーショナルモデルかどうか、一貫性の要件、トランザクション性が確実にわかるときです。 一般に、これには解決策があります。たとえば、 テストツインやさまざまなメモリ内ストレージの作成ですが、これまでは、記事を複雑にし、すぐにテクノロジを選択したくはありません-リレーショナルデータベース。 ただし、データベースを選択する可能性を少なくとも保持するために、抽象化-Spring Data JPAを追加します。 JPA自体はリレーショナルデータベースにアクセスするための非常に抽象的な仕様であり、Spring Dataはそれをさらに簡単に使用できるようにします。
Spring Data JPAはデフォルトでプロバイダーとしてHibernateを使用しますが、EclipseLinkやMyBatisなどの他のテクノロジーもサポートします。 Java Persistence APIにあまり慣れていない人にとっては、JPAはインターフェースのようなものであり、Hibernateはそれを実装するクラスです。
そこで、JPAのサポートを追加するために、いくつかの依存関係を追加しました。
implementation('org.springframework.boot:spring-boot-starter-data-jpa') runtime('com.h2database:h2')
データベースとして、 H2 -Javaで作成された組み込みデータベースを使用します。これは、インメモリモードで動作する機能を備えています。
Spring Data JPAを使用して、データにアクセスするためのインターフェースをすぐに定義します。
interface CakeRepository extends CrudRepository<CakeEntity, String> { }
そしてその本質:
@Entity @Builder @AllArgsConstructor @Table(name = "cakes") class CakeEntity { public CakeEntity() { } @Id @GeneratedValue(strategy = GenerationType.IDENTITY) Long id; @NotBlank String title; @Positive BigDecimal price; @NotBlank @NaturalId String sku; boolean promoted; @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; CakeEntity cakeEntity = (CakeEntity) o; return Objects.equals(title, cakeEntity.title); } @Override public int hashCode() { return Objects.hash(title); } }
エンティティの説明には、それほど明白ではないものがいくつかあります。
-
sku
フィールドの@NaturalId
。 このフィールドは、エンティティの等価性をチェックするための「自然な識別子」として使用されます@Id
/hashCode
メソッドですべてのフィールドまたは@Id
フィールドを使用することは、むしろアンチパターンです。 エンティティの等価性を正しく検証する方法については、たとえばここで説明されています 。 - 定型コードの数を少なくともわずかに減らすために、 Project Lombok -Java用の注釈プロセッサを使用します。
@Builder
クラスのビルダーを自動的に生成する@Builder
など、さまざまな便利なものを追加して、すべてのフィールドのコンストラクターを作成できます。
インターフェイスの実装は、Spring Dataによって自動的に提供されます。
ピラミッドを下りて
今こそ、ピラミッドの次のレベルに行くときです。 経験則として、「最終目標」と新機能の境界を決定できるようにするため、常にe2eテストから始めることをお勧めしますが 、これ以上厳密なルールはありません。 ユニットレベルに移行する前に、まず統合テストを作成する必要はありません。 たいていの場合、より便利でシンプルになります-ダウンするのはごく自然なことです。
しかし、具体的には、このルールをすぐに破り、まだ存在しない新しいコンポーネントのインターフェイスとコントラクトを決定するのに役立つ単体テストを作成したいと思います。 コントローラーは、特定のコンポーネントXから生成されるモデルを返す必要があり、このテストを作成しました。
@ExtendWith(MockitoExtension.class) class IndexControllerTest { @Mock CakeFinder cakeFinder; @InjectMocks IndexController indexController; private Set<Cake> cakes = Set.of(new Cake("Test 1", "£10"), new Cake("Test 2", "£10")); @BeforeEach void setUp() { when(cakeFinder.findPromotedCakes()).thenReturn(cakes); } @Test void shouldReturnAListOfFoundPromotedCakes() { ModelAndView index = indexController.index(); assertThat(index.getModel()).extracting("cakes").contains(cakes); } }
これは純粋な単体テストです-ここにはコンテキストもデータベースもありません。Mokito専用です。 また、このテストは、Springが単体テストにどのように役立つかを示す優れたデモンストレーションです。SpringMVCのコントローラーは、メソッドが通常の型のパラメーターを受け取り、POJOオブジェクトを返すクラスです 。 HTTPリクエスト、レスポンス、ヘッダー、JSON、XMLはありません。これらはすべて、コンバーターとシリアライザーの形式で自動的にスタックに適用されます。 はい、SpringにはModelAndView
の形式のModelAndView
な「ヒント」がありますが、これは通常のPOJOであり、必要に応じてModelAndView
することもできますModelAndView
コントローラーに特に必要です。
Mockitoについてはあまり触れません。公式ドキュメントですべてを読むことができます。 具体的には、このテストには興味深い点のみがありますMockitoExtension.class
をテストMockitoExtension.class
として使用すると、@Mock
によって注釈が付けられたフィールドのmokaが自動的に生成され、@Mock
とマークされたフィールドのオブジェクトのコンストラクターにこれらのmokaが依存関係として挿入され@InjectMocks
。Mockito.mock()
メソッドを使用してこれらすべてを手動で行い、クラスを作成できます。
また、このテストは、新しいコンポーネントのメソッドfindPromotedCakes
、メインページに表示するケーキのリストの決定に役立ちます。 彼は、それが何であるか、またはデータベースでどのように機能するかを決定しません。 コントローラーの唯一の責任は、転送されたものを受け取り、特定のフィールドでモデル(「ケーキ」)を返すことです。 それにもかかわらず、 CakeFinder
すでに私のインターフェイスに最初のメソッドがあります。つまり、統合テストを書くことができます。
cakes
パッケージ内のすべてのクラスを故意にプライベートにして、パッケージ外の誰も使用できないようにしました。 データベースからデータを取得する唯一の方法は、CakeFinderを使用することです。これは、データベースにアクセスするための私の「コンポーネントX」です。 それは自然な「コネクタ」になります。何かを分離してテストし、ベースに触れないようにする必要がある場合は、簡単にロックオンできます。 そして、唯一の実装はJpaCakeFinderです。 また、たとえば、将来、データベースまたはデータソースのタイプが変更された場合、使用するコードを変更せずにCakeFinder
インターフェースの実装を追加する必要があります。
@DataJpaTestを使用したJPAの統合テスト
統合テストはSpring bread and butterです。 実際、統合テストではすべてが非常にうまく行われているため、開発者はユニットレベルに移動したり、UIレベルを無視したりしたくない場合があります。 これは悪いことでも良いことでもありません。テストの主な目標は自信であることを繰り返します。 そして、この信頼性を提供するには、迅速で効果的な統合テストのセットで十分かもしれません。 ただし、時間の経過とともに、これらのテストが遅くなったり遅くなったり、統合ではなくコンポーネントのテストを開始したりする危険があります。
統合テストでは、アプリケーションをそのまま実行するか( @SpringBootTest
)、またはその個別のコンポーネント(JPA、Web)を実行できます。 私の場合、JPAに焦点を当てたテストを作成したいので、コントローラーや他のコンポーネントを構成する必要はありません。 @DataJpaTest
アノテーションは、Spring Boot Testでこれを担当します。 これはメタ注釈です。つまり、 テストのさまざまな側面を構成するいくつかの異なる注釈を組み合わせます。
- @AutoConfigureDataJpa
- @AutoConfigureTestDatabase
- @AutoConfigureCache
- @AutoConfigureTestEntityManager
- @Transactional
まず、それぞれについて個別に説明し、次に、完成したテストを示します。
@AutoConfigureDataJpa
構成のセット全体をロードし、リポジトリ( CrudRepositories
の実装の自動生成)、FlyWayおよびLiquibaseデータベースの移行ツール、DataSourceを使用したデータベースへの接続、トランザクションマネージャー、最後にHibernateを構成します。 実際、データへのアクセスに関連する設定のセットにすぎませんDispatcherServlet
も他のコンポーネントもここには含まれていません。
@AutoConfigureTestDatabase
これは、JPAテストの最も興味深い側面の1つです。 この構成は、クラスパスでサポートされている組み込みデータベースの1つを検索し、データソースがランダムに作成されたメモリ内データベースを指すようにコンテキストを再構成します 。 H2ベースに依存関係を追加したので、他に何もする必要はありません。テストの実行ごとにこのアノテーションを自動的に持つだけで、空のベースが提供され、これは非常に便利です。
このベースはスキームなしで完全に空になることを覚えておく価値があります。 回路を生成するには、いくつかのオプションがあります。
- Hibernateの自動DDL機能を使用します。 Spring Boot Testはこの値を
create-drop
自動的に設定し、Hibernateがエンティティの説明からスキーマを生成し、セッションの終了時にスキーマを削除するようにします。 これは、テストに非常に役立つHibernateの非常に強力な機能です。 - FlywayまたはLiquibaseによって作成された移行を使用します 。
データベースでデータベースを初期化するさまざまなアプローチについて詳しくは、 ドキュメントを参照してください 。
@AutoConfigureCache
NoOpCacheManagerを使用するようにキャッシュを構成するだけです-つまり 何もキャッシュしないでください。 これは、テストでの驚きを避けるのに役立ちます。
@AutoConfigureTestEntityManager
特別なTestEntityManager
オブジェクトをTestEntityManager
に追加します。それ自体は興味深い獣です。 EntityManager
はJPAのメインクラスであり、セッションへのエンティティの追加、削除などの処理を行います。 たとえば、Hibernateが動作し始めたときにのみ、エンティティをセッションに追加してもデータベースへのリクエストが実行されることを意味せず、セッションからのロードは選択リクエストが実行されることを意味しません。 Hibernateの内部メカニズムにより、データベースの実際の操作は適切なタイミングで実行され、フレームワーク自体が決定します。 ただし、テストの目的は統合をテストすることであるため、テストでは、データベースに何かを強制的に送信する必要がある場合があります。 また、 TestEntityManager
は、データベースの一部の操作を強制的に実行するための単なるヘルパーです。たとえば、 persistAndFlush()
は、Hibernateにすべての要求を強制的に実行させます。
@Transactional
この注釈により、クラス内のすべてのテストがトランザクションになり、テストの完了時にトランザクションが自動的にロールバックされます。 これは、各テストの前にデータベースを「クリーニング」するためのメカニズムにすぎません。そうしないと、各テーブルからデータを手動で削除する必要があります。
テストでトランザクションを管理するかどうかは、見かけほど単純で明白な問題ではありません。 データベースの「クリーン」状態の便利さにもかかわらず、「バトル」コードがトランザクション自体を開始せず、既存のものを必要とする場合、テストでの@Transactional
の存在は不快な驚きです。 これは統合テストに合格するという事実につながる可能性がありますが、実際のコードがテストではなくコントローラーから実行されると、サービスにはアクティブなトランザクションがなく、メソッドは例外をスローします。 これは危険に見えますが、UIテストの高レベルのテストでは、トランザクションテストはそれほど悪くありません。 私の経験では、統合テストに合格すると実動コードがクラッシュし、既存のトランザクションが明らかに必要になったときに、一度しか見ませんでした。 ただし、サービスとコンポーネント自体がトランザクションを正しく管理していることを確認する必要がある場合は、目的のモードでテストの@Transactional
アノテーションを「ブロック」できます(たとえば、トランザクションを開始しない)。
@SpringBootTestとの統合テスト
また、 @DataJpaTest
はフォーカル統合テストのユニークな例ではなく、 @WebMvcTest
、 @DataMongoTest
など多くのものがあることに注意してください。 ただし、最も重要なテストアノテーションの1つは@SpringBootTest
ままで、テスト用にアプリケーションを「そのまま」起動します-構成されたすべてのコンポーネントと統合を使用します。 論理的な問題が発生します-アプリケーション全体を実行できる場合、たとえば、なぜDataJpaの焦点テストを行うのでしょうか? ここでも厳格なルールはありません。
毎回アプリケーションを実行し、テストでクラッシュを切り分け、過負荷にならず、テストのセットアップを複雑にしないことが可能な場合は 、もちろん@SpringBootTestを使用できます。
ただし、実際には、アプリケーションは多くの異なる設定を必要とし、異なるシステムに接続する可能性があり、データベースアクセステストが失敗することは望ましくありません。 メッセージキューへの接続は設定されていません。 したがって、常識を使用することが重要です。@ SpringBootTestアノテーションを使用してテストを機能させるには、システムの半分をロックする必要があります。@ SpringBootTestでそれはまったく意味がありますか?
テスト用データの準備
テストの重要なポイントの1つは、データの準備です。 各テストは分離して実行し、開始する前に環境を準備して、システムを元の望ましい状態にする必要があります。 これを行う最も簡単なオプションは、 @BeforeEach
/ @BeforeAll
アノテーションを使用し、リポジトリ、 EntityManager
またはTestEntityManager
を使用してデータベースにエントリを追加することTestEntityManager
。 ただし、準備済みのスクリプトを実行したり、目的のSQLクエリを実行したりできる別のオプションがあります。これは@Sql
アノテーションです。 テストを実行する前に、Spring Boot Testは指定されたスクリプトを自動的に実行し、 @BeforeAll
ブロックを追加する必要がなくなり、 @BeforeAll
がデータ@Transactional
を処理し@Transactional
。
@DataJpaTest class JpaCakeFinderTest { private static final String PROMOTED_CAKE = "Red Velvet"; private static final String NON_PROMOTED_CAKE = "Victoria Sponge"; private CakeFinder finder; @Autowired CakeRepository cakeRepository; @Autowired TestEntityManager testEntityManager; @BeforeEach void setUp() { this.testEntityManager.persistAndFlush(CakeEntity.builder().title(PROMOTED_CAKE) .sku("SKU1").price(BigDecimal.TEN).promoted(true).build()); this.testEntityManager.persistAndFlush(CakeEntity.builder().sku("SKU2") .title(NON_PROMOTED_CAKE).price(BigDecimal.ONE).promoted(false).build()); finder = new JpaCakeFinder(cakeRepository); } ... }
赤緑リファクタリングサイクル
開発者にとって、この量のテキストにもかかわらず、テストは@DataJpaTestアノテーションを使用した単純なクラスのように見えますが、開発者が考えることのできない内部でどれほど有用なことが起こっているかを示すことができたと思います。 これでTDDサイクルに進むことができます。今回は、リファクタリングと最小限のコードの例とともに、TDDの反復をいくつか示します。 わかりやすくするために、Gitの履歴を確認することを強くお勧めします。Gitでは、各コミットは、それが何をどのように行うのかを説明する別個の重要なステップです。
データ準備
@BeforeAll
/ @BeforeEach
アプローチを使用し、データベース内のすべてのレコードを手動で作成します。 @Sql
アノテーションを使用した例は、別のクラスJpaCakeFinderTestWithScriptSetup
移動します。テストを複製します。もちろん、テストは複製されるべきではなく、アプローチを示すためだけに存在します。
システムの初期状態-システムには2つのエントリがあり、1つのケーキがプロモーションに参加し、メソッドによって返される結果に含まれる必要があります。2つ目-いいえ。
最初のテスト統合テスト
最初のテストは最も簡単ですfindPromotedCakes
は、プロモーションに参加しているケーキの説明と価格を含める必要があります。
赤
@Test void shouldReturnPromotedCakes() { Iterable<Cake> promotedCakes = finder.findPromotedCakes(); assertThat(promotedCakes).extracting(Cake::getTitle).contains(PROMOTED_CAKE); assertThat(promotedCakes).extracting(Cake::getPrice).contains("£10.00"); }
もちろん、テストはクラッシュします-デフォルトの実装は空のSetを返します。
緑色
当然、すぐにフィルタリングを記述しwhere
データベースをリクエストするのwhere
などが必要になります。 しかし、TDDの実践に従って、テストが合格するための最小限のコードを記述する必要があります 。 そして、この最小限のコードは、データベース内のすべてのレコードを返すことです。 はい、とてもシンプルで陳腐です。
public Set<Cake> findPromotedCakes() { Spliterator<CakeEntity> cakes = this.cakeRepository.findAll() .spliterator(); return StreamSupport.stream(cakes, false).map( cakeEntity -> new Cake(cakeEntity.title, formatPrice(cakeEntity.price))) .collect(Collectors.toSet()); } private String formatPrice(BigDecimal price) { return "£" + price.setScale(2, RoundingMode.DOWN).toPlainString(); }
おそらく、ここでは、ベースがなくてもテストをグリーンにできると主張するでしょう。テストで期待される結果をハードコードするだけです。 私は時折そのような議論を耳にしますが、TDDは教義でも宗教でもないことを誰もが理解していると思います。これを不条理な点に持ち込むことは意味がありません。 しかし、本当にしたい場合は、たとえば、インストール上のデータをランダム化して、ハードコーディングされないようにすることができます。
リファクタリング
ここではあまりリファクタリングを行っていないので、この特定のテストではこのフェーズをスキップできます。 しかし、私はまだこの段階を無視することはお勧めしません。システムの「グリーン」状態で毎回停止して考えることをお勧めします-何かをリファクタリングしてより良く簡単にすることは可能ですか?
二次試験
ただし、2番目のテストでは、プロモーションされていないケーキがfindPromotedCakes
によって返される結果に該当しないことを既に検証しています。
@Test void shouldNotReturnNonPromotedCakes() { Iterable<Cake> promotedCakes = finder.findPromotedCakes(); assertThat(promotedCakes).extracting(Cake::getTitle) .doesNotContain(NON_PROMOTED_CAKE); }
赤
テストは予想通りクラッシュします-データベースには2つのレコードがあり、コードはそれらすべてを単に返します。
緑色
繰り返しになりますが、テストに合格するために記述できる最小コードは何ですか? ストリームとそのアセンブリが既に存在するため、そこにfilter
ブロックを追加するだけです。
public Set<Cake> findPromotedCakes() { Spliterator<CakeEntity> cakes = this.cakeRepository.findAll() .spliterator(); return StreamSupport.stream(cakes, false) .filter(cakeEntity -> cakeEntity.promoted) .map(cakeEntity -> new Cake(cakeEntity.title, formatPrice(cakeEntity.price))) .collect(Collectors.toSet()); }
テストを再開します-統合テストは緑色になりました。 重要な瞬間が来ました-コントローラーの単体テストとデータベースを操作するための統合テストの組み合わせにより、私の機能の準備ができました-そしてUIテストに合格しました!
リファクタリング
そして、すべてのテストが緑色であるため、リファクタリングの時間です。 メモリ内でのフィルタリングは良いアイデアではないことを明確にする必要はないと思います。データベースでこれを行うことをお勧めします。 これを行うために、 CakesRepository
新しいメソッドfindByPromotedIsTrue
を追加しました。
interface CakeRepository extends CrudRepository<CakeEntity, String> { Iterable<CakeEntity> findByPromotedIsTrue(); }
このメソッドの場合、Spring Dataは、 select from cakes where promoted = true
フォームselect from cakes where promoted = true
クエリを実行するメソッドを自動的に生成しました。 クエリ生成の詳細については、Spring Dataのドキュメントをご覧ください。
public Set<Cake> findPromotedCakes() { Spliterator<CakeEntity> cakes = this.cakeRepository.findByPromotedIsTrue() .spliterator(); return StreamSupport.stream(cakes, false).map( cakeEntity -> new Cake(cakeEntity.title, formatPrice(cakeEntity.price))) .collect(Collectors.toSet()); }
これは、統合テストとブラックボックスアプローチが提供する柔軟性の良い例です。 リポジトリがロックされている場合、テストを変更せずに新しいメソッドを追加することは不可能ではありませんでした。
生産拠点への接続
「リアリズム」を少し追加し、テストとメインアプリケーションの構成を分離する方法を示すために、「実稼働」アプリケーションのデータアクセス構成を追加します。
伝統的にはすべてapplication.yml
のセクションによって追加されapplication.yml
:
datasource: url: jdbc:h2:./data/cake-factory
これにより、ファイルシステムのデータが./data
フォルダーに自動的に保存されます。 このフォルダーはテストでは作成されないことに注意してください- @DataJpaTest
は、 @AutoConfigureTestDatabase
アノテーションの存在により、ファイルデータベースへの接続をメモリ内のランダムデータベースに自動的に置き換えます。
便利になる可能性がある2つの便利なものは、data.sql
schema.sql
とschema.sql
。アプリケーションが起動すると、Spring Bootはリソース内にこれらのファイルが存在するかどうかを確認し、存在する場合はこれらのスクリプトを実行します。この機能は、実際のデータベースでのローカル開発およびプロトタイピングに役立ちます。もちろん、移行ツールを使用する必要があります。
おわりに
したがって、今回は、テストを使用してデータにアクセスするためのサービスのインターフェイスを決定する方法、統合テストを作成する方法、およびTDDサイクルで最小限のコードを作成する方法を示しました。
次の記事では、Spring Securityを追加します-さまざまなユーザーとロールに対してアプリケーションをテストする方法と、Springがこれに提供するツールと、テストの境界を決定する方法を示します。