
以前の記事では、 価格設定の基本と、従来の小売業向けの顧客意思決定ツリーの構築について説明しようとしました。 この記事では、非常に非標準的なケースについて説明し、機械学習を使用することは見かけほど難しくないことを納得させようとします。 この記事はあまり技術的ではなく、小規模から始めることができることを示す可能性が高く、これはすでにビジネスに具体的なメリットをもたらします。
初期問題
大陸には、週に1回品揃えを変更するチェーン店があります。たとえば、最初にオーバーロックを販売し、次にメンズスポーツウェアを販売します。 売れ残りの商品はすべて倉庫に送られ、6か月後に再び店舗に戻されます。 同時に、ストアには約6種類の商品カテゴリがあります。 つまり 各週の店舗の品揃えは次のとおりです。
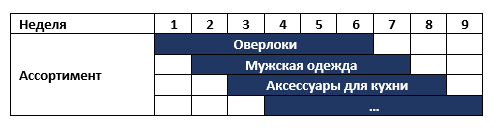
ネットワークは、カテゴリマネージャーの分析的意思決定支援の前提条件を備えた範囲計画システムを要求しました。 ビジネスと話し合った後、計画システムの展開中に結果をもたらすことができる2つの非常に迅速な潜在的なソリューションを提案しました。
- 主な販売中に販売されなかった商品の販売
- 店舗の需要予測の精度を向上させる
顧客の最初のポイントは満足していませんでした-会社は販売を手配せず、一定のマージンを維持することを誇りにしています。 同時に、商品の物流と保管に莫大なお金が費やされています。 その結果、店舗と倉庫のより正確な分布のために需要予測の精度を改善することが決定されました。
現在のプロセス
ビジネスの性質上、個々の製品は長い間販売されておらず、古典的な分析のために十分な履歴を取得することは問題です。 現在の予測プロセスは非常に単純で、次のように構成されています-店舗の一部の主要な販売が開始される数週間前に、テスト販売が開始されます。 テスト販売の結果に基づいて、ネットワーク全体に商品を導入することが決定され、各店舗はテスト店舗で販売されたのと同じくらいの平均で販売されると想定されます。
顧客に到着して、現在のデータを分析し、何が起こっているのかを認識し、予測の精度を向上させるための非常に簡単なソリューションを提案しました。
データの分析
提供されたデータから:
- 1年2か月の取引履歴
- 計画のための製品階層。 残念ながら、商品の属性はほぼ完全に欠けていましたが、それについては後で詳しく説明します
- 特定の週の品揃えと価格に関する情報
- 店舗が所在する都市に関する情報
天びんに関する情報を短時間でアンロードすることはできませんでしたが、これはこの種の分析に不可欠です(この情報を保存しない場合は、開始してください)。したがって、将来は商品が棚にあり、商品が不足していないという仮定を使用しました。
すぐに2か月をテストサンプルに分けて、結果を示しました。 次に、利用可能なすべてのデータを1つの大きなショーケースにまとめて、返品と奇妙な販売をクリアしました(たとえば、小切手の金額は商品ごとに0.51です)。 数日かかりました。 陳列ケースを準備した後、商品[ユニット]の販売を最高レベルで見て、次の写真を見ました。
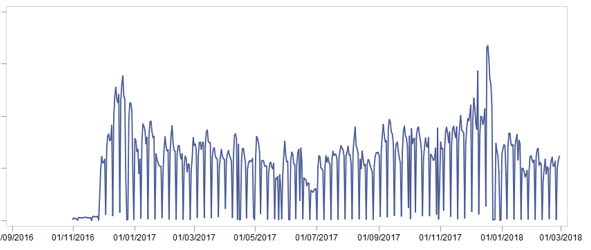
この写真はどのように役立ちますか?
- 明らかに、季節性があります-年末の売上は中間よりも高くなっています
- 月内には季節性があります-月の半ばでは、売上は開始時と終了時よりも高くなっています
- 週内に季節性があります-それはそれほど面白くないです、なぜなら その結果、予測は週に基づいていました
説明された項目はビジネスを確認しました。 しかし、予測を改善するための優れた機能もあります! それらを予測モデルに追加する前に、販売の他の特徴を考慮すべきかを考えてみましょう...「明白な」アイデアが思い浮かびます:
- 売上は製品グループごとに平均して異なります
- 販売は店舗によって異なります
- (前の段落と同様)売上は都市によって異なります
- (それほど明白ではないアイデア)ビジネスの詳細により、次の関係が見られます:将来の品揃えと以前の品揃えが類似している場合、新しい品揃えの売上は低くなります。
これについて、モデルを停止して構築することにしました。
ABTの構築( 分析ベーステーブル )
モデルの構築の一環として、見つかったすべての機能がモデルの「機能」に変換されました。 結果として使用される機能のリストは次のとおりです。
- 現在の予測、すなわち すべての店舗に分配された[単位]のテスト店舗の平均売上
- 月の月番号と週番号
- すべてのカテゴリ変数(都市、店舗、製品カテゴリ)は平滑化された尤度を使用してエンコードされました (有用な手法-まだ使用していない人は使用してください)
- 計算されたラグ4製品カテゴリの平均売上。 つまり 会社が青いTシャツの販売を計画している場合、Tシャツカテゴリの平均売上の遅れが計算されました。
ABTは単純であることが判明し、各パラメーターはビジネスに理解可能であり、誤解や拒否を引き起こしませんでした。 次に、予測の品質を比較する方法を理解する必要がありました。
メトリック選択
顧客は、 MAPEメトリックを使用して現在の予測精度を測定しました。 このメトリックは一般的でシンプルですが、需要の予測に関してはいくつかの欠点があります。 実際、MAPEを使用する場合、予測タイプのエラーは最終的な指標に最大の影響を及ぼします。

900%の相対的な予測エラー-それは大きいようですが、別の製品の売上高を見てみましょう。

相対的な予測誤差は33%であり、900%を大きく下回っていますが、100 [units]の偏差の絶対偏差は、18 [units]の偏差よりもビジネスにとってはるかに重要です。 これらの機能を考慮するには、独自の興味深い指標を考え出すか、需要の予測に別の一般的な指標であるWAPEを使用できます。 この方法は、売り上げの多い商品により大きな重みを与え、タスクに最適です。
予測エラーを測定するためのさまざまなアプローチについて会社に話し、顧客はこのタスクでWAPEを使用する方が合理的であることに喜んで同意しました。 その後、ハイパーパラメータをほとんど調整せずにランダムフォレストを起動し、次の結果を得ました。
結果
テスト期間を予測した後、予測値を実際の値と会社の予測と比較しました。 その結果、 MAPEは15%以上、WAPEは10%以上減少しました 。 改善された予測がビジネス指標に与える影響を計算すると、かなり大きな金額の数百万ドルのコスト削減が得られました。
すべての作業に1週間かかりました!
さらなるステップ
顧客へのボーナスとして、小規模なDQ実験を実施しました。 製品名の1つの製品グループについて、特性(色、製品のタイプ、組成など)を解析し、予測に追加しました。 結果は刺激的でした-このカテゴリでは、両方のエラー測定値がさらに8%以上改善されました。
その結果、顧客には各機能の説明、モデルパラメーター、ABTショーケースのアセンブリパラメーターが与えられ、予測を改善するためのさらなる手順が説明されました(1年以上の履歴データの使用、残高の使用、商品の特性の使用など)。
おわりに
顧客との1週間のコラボレーションで、ビジネスプロセスを実際に変更することなく、予測の精度を大幅に向上させることができました。
確かに多くの人が、このケースは非常に単純であり、会社でこのアプローチを採用することはできないと考えています。 経験によれば、ほとんどの場合、基本的な仮定と専門家の意見だけが使用される場所があります。 これらの場所から、機械学習の使用を開始できます。 これを行うには、データを慎重に準備して調査し、ビジネスと話し、長いチューニングを必要としない一般的なモデルを使用する必要があります。 そして、スタッキング、埋め込み機能、複雑なモデル-それはすべて後のものです。 思ったほど難しいことではなく、少し考えるだけで始めることを恐れないでください。
機械学習を恐れず、プロセスで使用できる場所を探し、データを調査することを恐れないでください。
PS経験豊富なジェダイの指導の下、小売インターンシップのために若いパダワンの学生を募集しています。 まず、SQLの常識と知識で十分であるため、残りは教えます。 ビジネスの専門家または技術コンサルタントのうち、どちらか興味深い方に発展できます。 興味や推奨事項がある場合-個人的に書きます