プロジェクト管理およびタスク追跡システムでチケットを作成すると、私たちはそれぞれ、控訴に関する決定の推定条件を見て喜んでいます。
着信チケットのストリームを受信する場合、個人/チームは優先度と時間でそれらを並べる必要があります。これは各アピールを解決するのに時間がかかります。
これにより、両当事者の時間をより効果的に計画できます。
カットの下で、私たちのチームに発行されたチケットを解決するのにかかる時間を予測するMLモデルをどのように分析し、訓練したかについてお話します。
私自身は、LABというチームのSREポジションで働いています。 開発者とQAの両方から、新しいテスト環境の展開、最新リリースバージョンへの更新、発生するさまざまな問題の解決策などに関する問い合わせを受けています。 これらのタスクは非常に異質であり、論理的には、完了するまでに異なる時間がかかります。 私たちのチームは数年前から存在しており、この期間中にリクエストのベースが蓄積されました。 私はこのベースを分析し、それに基づいて、機械学習の助けを借りて、アピール(チケット)の予想閉店時間の予測を処理するモデルを作成することにしました。
私たちの仕事ではJIRAを使用しますが、この記事で紹介するモデルは特定の製品とは関係ありません。データベースから必要な情報を取得することは問題ありません。
それでは、言葉から行動に移りましょう。
予備データ分析
必要なものをすべてロードし、使用されているパッケージのバージョンを表示します。
import warnings warnings.simplefilter('ignore') %matplotlib inline import matplotlib.pyplot as plt import pandas as pd import numpy as np import datetime from nltk.corpus import stopwords from sklearn.model_selection import train_test_split from sklearn.metrics import mean_absolute_error, mean_squared_error from sklearn.neighbors import KNeighborsRegressor from sklearn.linear_model import LinearRegression from datetime import time, date for package in [pd, np, matplotlib, sklearn, nltk]: print(package.__name__, 'version:', package.__version__)
pandas version: 0.23.4 numpy version: 1.15.0 matplotlib version: 2.2.2 sklearn version: 0.19.2 nltk version: 3.3
csvファイルからデータをダウンロードします。 過去1.5年間に閉鎖されたチケットに関する情報が含まれています。 データをファイルに書き込む前に、それらはわずかに前処理されていました。 たとえば、説明付きのテキストフィールドからカンマとピリオドが削除されました。 ただし、これは予備処理に過ぎず、今後テキストはさらに消去されます。
データセットの内容を見てみましょう。 合計で10783枚のチケットが入ってきました。
| 作成しました | チケット作成日時 |
| 解決済み | チケット終了日時 |
| Resolution_time | チケットを作成してから閉じるまでに経過した分数。 カレンダー時間と見なされます、なぜなら 同社はさまざまな国にオフィスを持ち、さまざまなタイムゾーンで働いており、部門全体に決まった時間はありません。 |
| Engineer_N | エンジニアの「コード化された」名前(将来、個人情報や機密情報を不注意で漏らさないように、記事にはかなりの数の「エンコードされた」データがありますが、実際には単に名前が変更されます)。 これらのフィールドには、提示された日付セットの各チケットの受信時に「進行中」モードのチケットの数が含まれます。 記事の終わりに向かってこれらのフィールドについて個別に説明します。 特に注意が必要です。 |
| 譲受人 | 問題の解決に関与した従業員。 |
| Issue_type | チケットの種類。 |
| 環境 | チケットが作成されたテスト作業環境の名前(特定の環境またはデータセンターなどの場所全体を意味する場合があります)。 |
| 優先順位 | チケットの優先順位。 |
| ワークタイプ | このチケットに予想される作業の種類(サーバーの追加または削除、環境の更新、監視の操作など) |
| 説明 | 説明 |
| まとめ | チケットのタイトル。 |
| ウォッチャー | チケットを「見る」人の数、つまり チケットのアクティビティごとにメール通知を受け取ります。 |
| 投票 | チケットに「投票」し、チケットの重要性と関心を示した人の数。 |
| 記者 | チケットを発行した人。 |
| Engineer_N_vacation | チケットの発行時にエンジニアが休暇中だったかどうか。 |
df.info()
<class 'pandas.core.frame.DataFrame'> Index: 10783 entries, ENV-36273 to ENV-49164 Data columns (total 37 columns): Created 10783 non-null object Resolved 10783 non-null object Resolution_time 10783 non-null int64 engineer_1 10783 non-null int64 engineer_2 10783 non-null int64 engineer_3 10783 non-null int64 engineer_4 10783 non-null int64 engineer_5 10783 non-null int64 engineer_6 10783 non-null int64 engineer_7 10783 non-null int64 engineer_8 10783 non-null int64 engineer_9 10783 non-null int64 engineer_10 10783 non-null int64 engineer_11 10783 non-null int64 engineer_12 10783 non-null int64 Assignee 10783 non-null object Issue_type 10783 non-null object Environment 10771 non-null object Priority 10783 non-null object Worktype 7273 non-null object Description 10263 non-null object Summary 10783 non-null object Watchers 10783 non-null int64 Votes 10783 non-null int64 Reporter 10783 non-null object engineer_1_vacation 10783 non-null int64 engineer_2_vacation 10783 non-null int64 engineer_3_vacation 10783 non-null int64 engineer_4_vacation 10783 non-null int64 engineer_5_vacation 10783 non-null int64 engineer_6_vacation 10783 non-null int64 engineer_7_vacation 10783 non-null int64 engineer_8_vacation 10783 non-null int64 engineer_9_vacation 10783 non-null int64 engineer_10_vacation 10783 non-null int64 engineer_11_vacation 10783 non-null int64 engineer_12_vacation 10783 non-null int64 dtypes: float64(12), int64(15), object(10) memory usage: 3.1+ MB
合計で、10個の「オブジェクト」フィールド(つまり、テキスト値を含む)と27個の数値フィールドがあります。
まず第一に、すぐにデータで排出量を探してください。 ご覧のとおり、決定時間が数百万分のチケットがあります。 これは明らかに関連情報ではありません。そのようなデータはモデルの構築を妨げるだけです。 JIRAからのデータ収集は、作成済みではなく、解決済みフィールドのクエリによって実行されたため、ここに来ました。 したがって、過去1.5年以内に閉鎖されたチケットはここに到着しましたが、もっと早く開くことができました。 それらを取り除く時間です。 2017年6月1日より前に作成されたチケットは破棄します。 残り9493枚のチケットがあります。
理由として-私は各プロジェクトで、さまざまな状況のためにかなり長い間ぶらぶらしているリクエストを簡単に見つけることができ、多くの場合、問題自体を解決するのではなく、「制限法の期限切れ」によって閉じられると思います。
df[['Created', 'Resolved', 'Resolution_time']].sort_values('Resolution_time', ascending=False).head()

df = df[df['Created'] >= '2017-06-01 00:00:00'] print(df.shape)
(9493, 33)
それでは、データで何が面白いかを見てみましょう。 まず、最もシンプルなものを見つけましょう-チケットの中で最も人気のある環境、最もアクティブな「レポーター」など。
df.describe(include=['object'])

df['Environment'].value_counts().head(10)
Environment_104 442 ALL 368 Location02 367 Environment_99 342 Location03 342 Environment_31 322 Environment_14 254 Environment_1 232 Environment_87 227 Location01 202 Name: Environment, dtype: int64
df['Reporter'].value_counts().head()
Reporter_16 388 Reporter_97 199 Reporter_04 147 Reporter_110 145 Reporter_133 138 Name: Reporter, dtype: int64
df['Worktype'].value_counts()
Support 2482 Infrastructure 1655 Update environment 1138 Monitoring 388 QA 300 Numbers 110 Create environment 95 Tools 62 Delete environment 24 Name: Worktype, dtype: int64
df['Priority'].value_counts().plot(kind='bar', figsize=(12,7), rot=0, fontsize=14, title=' ');
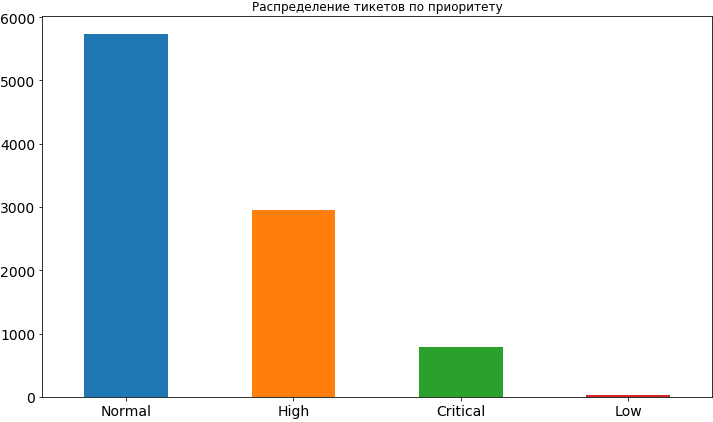
まあ、私たちがすでに学んだこと。 ほとんどの場合、チケットの優先度は通常であり、約2倍低い頻度であり、重要度はさらに低くなっています。 優先度が低いことはめったにありません。明らかに人々はそれを公開することを恐れています。この場合、キューでかなり長い時間ハングし、その決定の時間が遅れる可能性があると信じています。 後で、モデルをすでに構築してその結果を分析するとき、優先順位が低いとタスクの時間枠に影響を与え、もちろん加速化には影響しないため、このような恐れは根拠がないかもしれません。
最も人気のある環境と最もアクティブなレポーターの列から、Reporter_16が大幅に伸び、Environment_104が環境で最初に来ることがわかります。 まだ推測していない場合でも、少し秘密をお伝えします。この記者は、この特定の環境に取り組んでいるチームの出身です。
最も重要なチケットがどのような環境から来ているのか見てみましょう。
df[df['Priority'] == 'Critical']['Environment'].value_counts().index[0]
'Environment_91'
次に、優先度の異なるチケットが同じ「クリティカル」環境から何枚来るかについての情報を印刷します。
df[df['Environment'] == df[df['Priority'] == 'Critical']['Environment'].value_counts().index[0]]['Priority'].value_counts()
High 62 Critical 57 Normal 46 Name: Priority, dtype: int64
優先順位のコンテキストでチケットの実行時間を見てみましょう。 たとえば、優先度の低いチケットの平均実行時間は7万分(約1.5か月)以上であることに気付くのは楽しいことです。 チケットの実行時間の優先度への依存も簡単に追跡できます。
df.groupby(['Priority'])['Resolution_time'].describe()
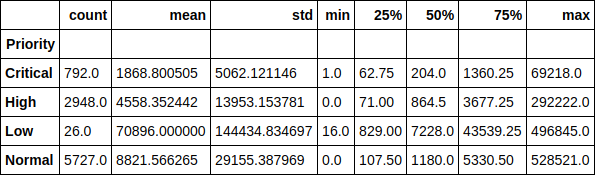
または、ここではグラフとして、中央値。 ご覧のとおり、状況はそれほど変化していないため、排出量は実際には分布に影響しません。
df.groupby(['Priority'])['Resolution_time'].median().sort_values().plot(kind='bar', figsize=(12,7), rot=0, fontsize=14);

次に、その時点でエンジニアが持っていたチケットの数に応じて、各エンジニアの平均チケット解決時間を見てみましょう。 実際、これらのグラフは、驚いたことに、単一の画像を表示していません。 作業中の現在のチケットが増加するにつれて実行時間が長くなる人もいれば、この関係が反対になる人もいます。 一部の中には、中毒はまったく追跡可能ではありません。
ただし、今後の展望を見ると、データセットにこの機能が存在すると、モデルの精度が2倍以上向上し、実行時間に確実に影響を与えると言えます。 私たちはただ彼を見ません。 そして、モデルは見ています。
engineers = [i.replace('_vacation', '') for i in df.columns if 'vacation' in i] cols = 2 rows = int(len(engineers) / cols) fig, axes = plt.subplots(nrows=rows, ncols=cols, figsize=(16,24)) for i in range(rows): for j in range(cols): df.groupby(engineers[i * cols + j])['Resolution_time'].mean().plot(kind='bar', rot=0, ax=axes[i, j]).set_xlabel('Engineer_' + str(i * cols + j + 1)) del cols, rows, fig, axes

次の機能のペアワイズ相互作用の小さなマトリックスを作成しましょう:チケットの解決時間、投票数、オブザーバーの数。 対角ボーナスを使用すると、各属性の分布が得られます。
おもしろいものから、チケットの解決時間を短縮することは、増え続けるオブザーバーへの依存性を見ることができます。 また、人々は票を使うことにあまり積極的ではないこともわかります。
pd.scatter_matrix(df[['Resolution_time', 'Watchers', 'Votes']], figsize=(15, 15), diagonal='hist');
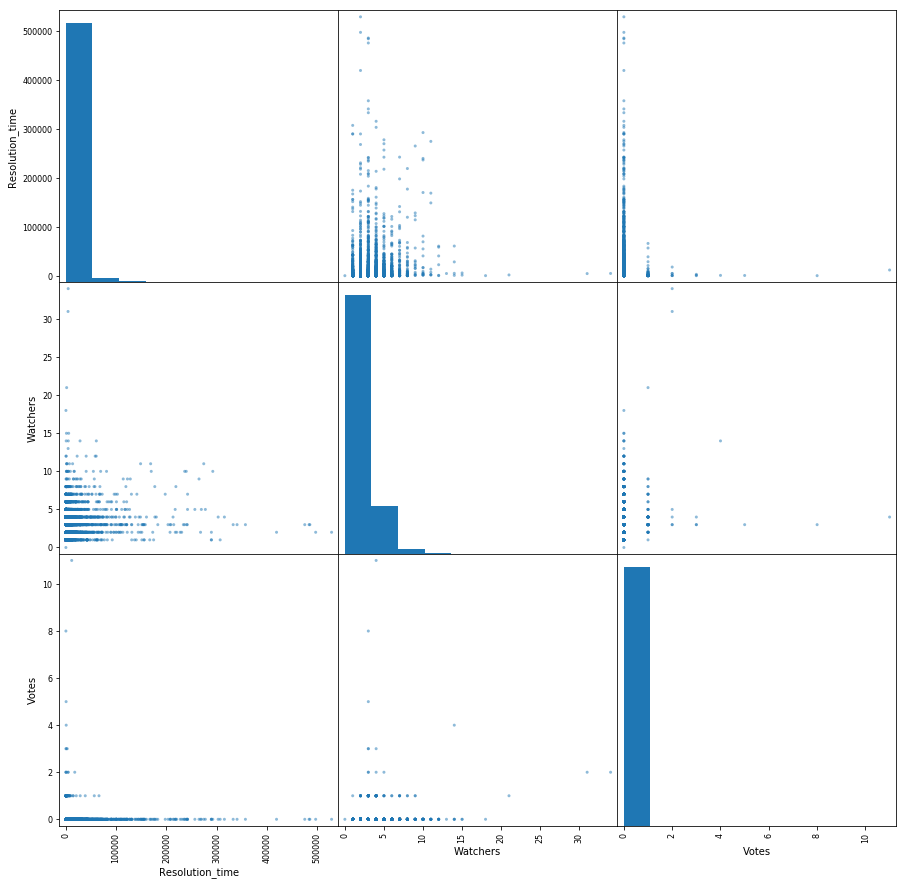
そこで、データの小さな予備分析を行い、ターゲット属性(チケットを解決するのにかかる時間)と、チケットの投票数、その背後にある「オブザーバー」の数、優先度などの兆候の間の既存の依存関係を確認しました。 先に進みます。
モデルの構築。 建物の標識
次は、モデル自体の構築に進みます。 ただし、最初に、モデルに理解できる形式に機能を組み込む必要があります。 つまり カテゴリー記号をスパースベクトルに分解し、過剰を取り除きます。 たとえば、チケットがモデルで作成およびクローズされた時間のフィールド、および担当者フィールドは必要ありません。 最終的にこのモデルを使用して、まだ誰にも割り当てられていない(「暗殺」)チケットの実行時間を予測します。
先ほど述べたように、ターゲットサインは問題を解決するときです。したがって、それを別のベクトルとして取り、一般的なデータセットから削除します。 さらに、チケットを発行する際にレポーターが説明フィールドに常に入力するとは限らないため、一部のフィールドは空でした。 この場合、pandasは値をNaNに設定し、空の文字列に置き換えます。
y = df['Resolution_time'] df.drop(['Created', 'Resolved', 'Resolution_time', 'Assignee'], axis=1, inplace=True) df['Description'].fillna('', inplace=True) df['Summary'].fillna('', inplace=True)
カテゴリの特徴をスパースベクトルに分解します( ワンホットエンコーディング )。 チケットの説明と目次でフィールドに触れるまで。 それらを少し異なる方法で使用します。 一部のレポーター名には[X]が含まれます。 そのため、JIRAは、会社で働いていない非アクティブな従業員をマークします。 将来的にはモデルを使用するときにこれらの従業員からのチケットが表示されなくなるため、それらからデータをクリアすることは可能ですが、私はそれらを標識の中に残すことにしました。
def create_df(dic, feature_list): out = pd.DataFrame(dic) out = pd.concat([out, pd.get_dummies(out[feature_list])], axis = 1) out.drop(feature_list, axis = 1, inplace = True) return out X = create_df(df, df.columns[df.dtypes == 'object'].drop(['Description', 'Summary'])) X.columns = X.columns.str.replace(' \[X\]', '')
次に、チケットの説明フィールドを扱います。 おそらく最も簡単な方法の1つで作業します-チケットで使用されているすべての単語を収集し、それらの中で最も人気のあるものをカウントし、「余分な」単語-たとえば単語などの結果に明らかに影響を与えない単語を破棄します「please」(JIRAでのすべての通信は厳密に英語で行われます)、これは最も人気があります。 はい、これらは私たちの礼儀正しい人々です。
また、nltkライブラリに従って「 ストップワード 」を削除し、不要な文字のテキストをより完全にクリアします。 これがテキストでできる最も簡単なことであることを思い出させてください。 単語を「 スタンプ 」しません。最も人気のあるN-gramの単語もカウントできますが、それだけに制限します。
all_words = np.concatenate(df['Description'].apply(lambda s: s.split()).values) stop_words = stopwords.words('english') stop_words.extend(['please', 'hi', '-', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '(', ')', '=', '{', '}']) stop_words.extend(['h3', '+', '-', '@', '!', '#', '$', '%', '^', '&', '*', '(for', 'output)']) stop_symbols = ['=>', '|', '[', ']', '#', '*', '\\', '/', '->', '>', '<', '&'] words_series = pd.Series(list(all_words)) del all_words words_series = words_series[~words_series.isin(stop_words)] for symbol in stop_symbols: words_series = words_series[~words_series.str.contains(symbol, regex=False, na=False)]
このすべての後、使用されたすべての単語を含むpandas.Seriesオブジェクトを取得しました。 最も人気のあるものを見て、リストから最初の50個を取り出して標識として使用してみましょう。 チケットごとに、この単語が説明で使用されているかどうかを確認し、使用されている場合は対応する列に1を入れ、それ以外の場合は0を入れます。
usefull_words = list(words_series.value_counts().head(50).index) print(usefull_words[0:10])
['error', 'account', 'info', 'call', '{code}', 'behavior', 'array', 'update', 'env', 'actual']
一般的なデータセットでは、選択した単語に対して個別の列を作成します。 これで、説明フィールド自体を取り除くことができます。
for word in usefull_words: X['Description_' + word] = X['Description'].str.contains(word).astype('int64') X.drop('Description', axis=1, inplace=True)
チケットのタイトルフィールドにも同じことを行います。
all_words = np.concatenate(df['Summary'].apply(lambda s: s.split()).values) words_series = pd.Series(list(all_words)) del all_words words_series = words_series[~words_series.isin(stop_words)] for symbol in stop_symbols: words_series = words_series[~words_series.str.contains(symbol, regex=False, na=False)] usefull_words = list(words_series.value_counts().head(50).index) for word in usefull_words: X['Summary_' + word] = X['Summary'].str.contains(word).astype('int64') X.drop('Summary', axis=1, inplace=True)
特徴行列Xと応答ベクトルyで結果を確認してみましょう。
print(X.shape, y.shape)
((9493, 1114), (9493,))
次に、このデータをトレーニング(トレーニング)サンプルとテストサンプルに75/25の割合で分割します。 合計7119の例でトレーニングを行い、2374の例でモデルを評価します。 また、カテゴリ記号のレイアウトにより、属性のマトリックスの次元が1114に増加しました。
X_train, X_holdout, y_train, y_holdout = train_test_split(X, y, test_size=0.25, random_state=17) print(X_train.shape, X_holdout.shape)
((7119, 1114), (2374, 1114))
モデルをトレーニングします。
線形回帰
最軽量で(予想される)最も精度の低いモデルである線形回帰から始めましょう。 トレーニングデータの精度と、遅延(ホールドアウト)サンプル(モデルには見られなかったデータ)の両方で評価します。
線形回帰の場合、モデルは多かれ少なかれ許容範囲でトレーニングデータに表示されますが、遅延サンプルの精度は非常に低くなります。 すべてのチケットの通常の平均を予測するよりもさらに悪い。
ここで、短い休憩を取り、スコアメソッドを使用してモデルが品質を評価する方法を伝える必要があります。
評価は、決定係数によって行われます。
どこで モデルaによって予測された結果ですか -サンプル全体の平均値。
係数についてはあまり詳しく説明しません。 関心のあるモデルの精度を完全に反映していないことに注意してください。 したがって、同時に、平均絶対誤差(MAE)を使用して評価し、それに依存します。
lr = LinearRegression() lr.fit(X_train, y_train) print('R^2 train:', lr.score(X_train, y_train)) print('R^2 test:', lr.score(X_holdout, y_holdout)) print('MAE train', mean_absolute_error(lr.predict(X_train), y_train)) print('MAE test', mean_absolute_error(lr.predict(X_holdout), y_holdout))
R^2 train: 0.3884389470220214 R^2 test: -6.652435243123196e+17 MAE train: 8503.67256637168 MAE test: 1710257520060.8154
勾配ブースト
さて、それなしで、勾配ブーストなしで? モデルをトレーニングして、何が起こるか見てみましょう。 これには悪名高いXGBoostを使用します。 標準のハイパーパラメーター設定から始めましょう。
import xgboost xgb = xgboost.XGBRegressor() xgb.fit(X_train, y_train) print('R^2 train:', xgb.score(X_train, y_train)) print('R^2 test:', xgb.score(X_holdout, y_holdout)) print('MAE train', mean_absolute_error(xgb.predict(X_train), y_train)) print('MAE test', mean_absolute_error(xgb.predict(X_holdout), y_holdout))
R^2 train: 0.5138516547636054 R^2 test: 0.12965507684512545 MAE train: 7108.165167471887 MAE test: 8343.433260957032
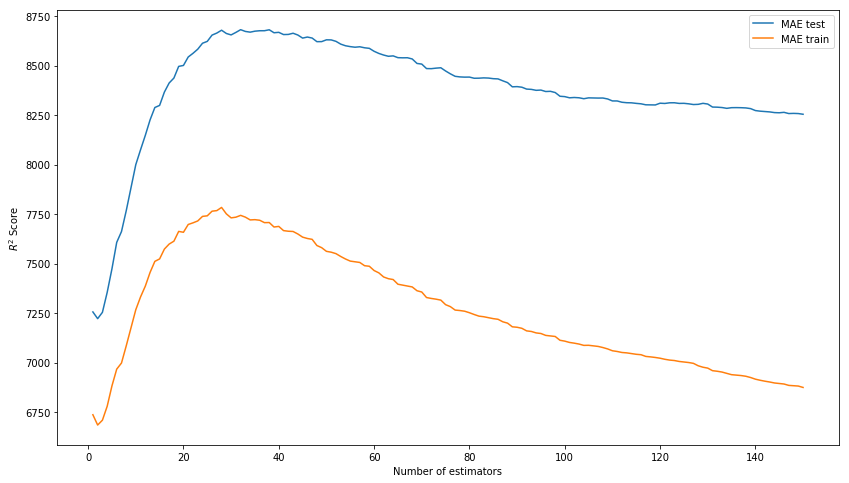
箱から出してすぐに結果は悪くありません。 ハイパーパラメーター(n_estimators、learning_rate、max_depth)を選択して、モデルを調整してみましょう。 その結果、トレーニングデータに対するモデルのオーバートレーニングがない場合のテストサンプルで最良の結果を示すため、それぞれ150、0.1、および3の値を使用します。
* R ^ 2の代わりに、写真のスコアはMAEである必要があります。
xgb_model_abs_testing = list() xgb_model_abs_training = list() rng = np.arange(1,151) for i in rng: xgb = xgboost.XGBRegressor(n_estimators=i) xgb.fit(X_train, y_train) xgb.score(X_holdout, y_holdout) xgb_model_abs_testing.append(mean_absolute_error(xgb.predict(X_holdout), y_holdout)) xgb_model_abs_training.append(mean_absolute_error(xgb.predict(X_train), y_train)) plt.figure(figsize=(14, 8)) plt.plot(rng, xgb_model_abs_testing, label='MAE test'); plt.plot(rng, xgb_model_abs_training, label='MAE train'); plt.xlabel('Number of estimators') plt.ylabel('$R^2 Score$') plt.legend(loc='best') plt.show();
xgb_model_abs_testing = list() xgb_model_abs_training = list() rng = np.arange(0.05, 0.65, 0.05) for i in rng: xgb = xgboost.XGBRegressor(n_estimators=150, random_state=17, learning_rate=i) xgb.fit(X_train, y_train) xgb.score(X_holdout, y_holdout) xgb_model_abs_testing.append(mean_absolute_error(xgb.predict(X_holdout), y_holdout)) xgb_model_abs_training.append(mean_absolute_error(xgb.predict(X_train), y_train)) plt.figure(figsize=(14, 8)) plt.plot(rng, xgb_model_abs_testing, label='MAE test'); plt.plot(rng, xgb_model_abs_training, label='MAE train'); plt.xlabel('Learning rate') plt.ylabel('MAE') plt.legend(loc='best') plt.show();
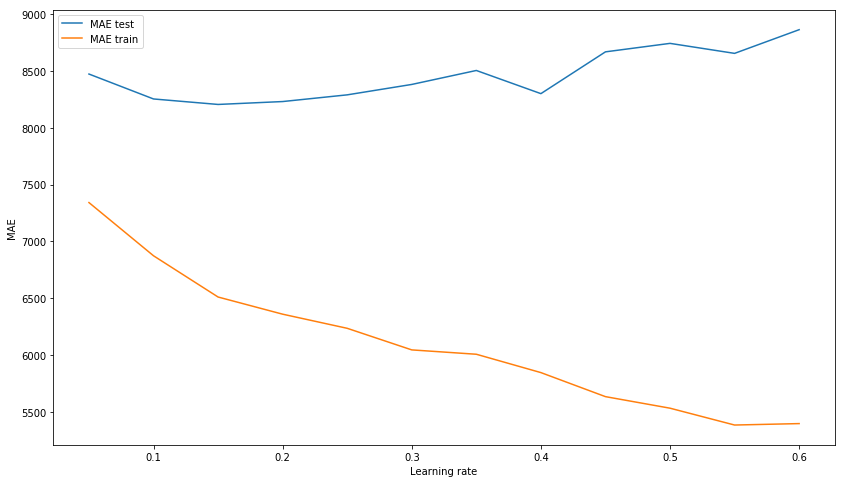
xgb_model_abs_testing = list() xgb_model_abs_training = list() rng = np.arange(1, 11) for i in rng: xgb = xgboost.XGBRegressor(n_estimators=150, random_state=17, learning_rate=0.1, max_depth=i) xgb.fit(X_train, y_train) xgb.score(X_holdout, y_holdout) xgb_model_abs_testing.append(mean_absolute_error(xgb.predict(X_holdout), y_holdout)) xgb_model_abs_training.append(mean_absolute_error(xgb.predict(X_train), y_train)) plt.figure(figsize=(14, 8)) plt.plot(rng, xgb_model_abs_testing, label='MAE test'); plt.plot(rng, xgb_model_abs_training, label='MAE train'); plt.xlabel('Maximum depth') plt.ylabel('MAE') plt.legend(loc='best') plt.show();

ここで、選択したハイパーパラメーターを使用してモデルをトレーニングします。
xgb = xgboost.XGBRegressor(n_estimators=150, random_state=17, learning_rate=0.1, max_depth=3) xgb.fit(X_train, y_train) print('R^2 train:', xgb.score(X_train, y_train)) print('R^2 test:', xgb.score(X_holdout, y_holdout)) print('MAE train', mean_absolute_error(xgb.predict(X_train), y_train)) print('MAE test', mean_absolute_error(xgb.predict(X_holdout), y_holdout))
R^2 train: 0.6745967150462303 R^2 test: 0.15415143189670344 MAE train: 6328.384400466232 MAE test: 8217.07897417256
選択されたパラメーターと視覚化機能の重要性を持つ最終結果-モデルに応じた標識の重要性。 そもそもチケットオブザーバーの数ですが、4人のエンジニアがすぐに行きます。 したがって、チケットの雇用時間は、エンジニアの雇用によって非常に強く影響を受ける可能性があります。 そして、それらのいくつかの自由時間がより重要であることは論理的です。 チームにシニアエンジニアとミドルがいるという理由だけで(チームにジュニアがいない場合)。 ちなみに、秘密裏に、最初の場所のエンジニア(オレンジ色のバー)は、チーム全体で最も経験豊富なエンジニアの1人です。 さらに、これらのエンジニアの4人全員の役職にシニアプレフィックスが付いています。 モデルがこれをもう一度確認したことがわかります。
features_df = pd.DataFrame(data=xgb.feature_importances_.reshape(1, -1), columns=X.columns).sort_values(axis=1, by=[0], ascending=False) features_df.loc[0][0:10].plot(kind='bar', figsize=(16, 8), rot=75, fontsize=14);
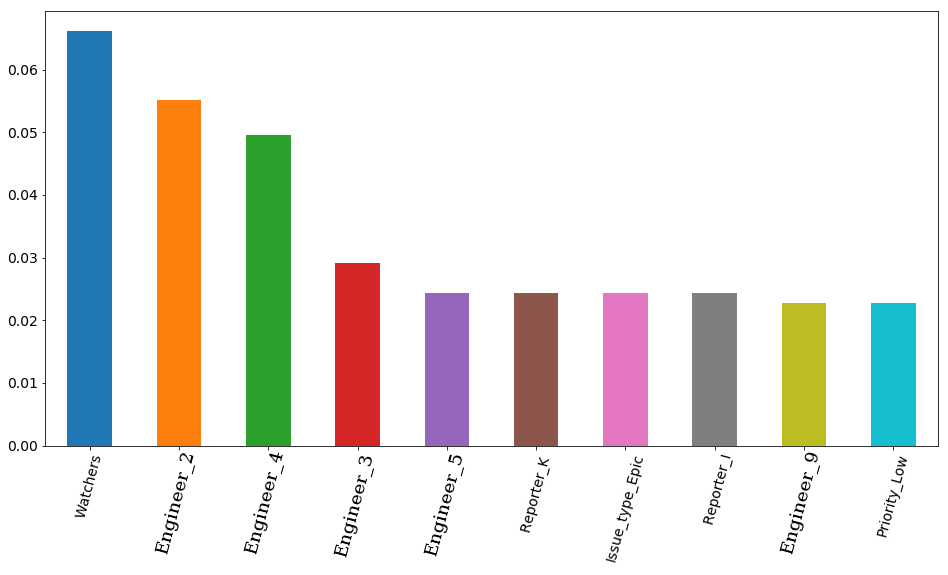
ニューラルネットワーク
しかし、1つの勾配ブーストで停止することはせず、ニューラルネットワーク、またはむしろ完全に接続された直接分布ニューラルネットワークである多層パーセプトロンを訓練しようとします。 今回は、ハイパーパラメーターの標準設定では開始しません。 使用するsklearnライブラリーでは、デフォルトで100個のニューロンを持つ隠れ層が1つだけであり、トレーニング中にモデルは標準の200回の反復の不一致に関する警告を出します。 すぐに、それぞれ300、200、100のニューロンを持つ3つの隠れ層を使用します。
その結果、トレーニングサンプルでモデルがオーバートレーニングされていないことがわかりますが、テストサンプルで適切な結果が表示されるのを防ぐことはできません。 この結果は、勾配ブーストの結果よりもかなり劣っています。
from sklearn.neural_network import MLPRegressor nn = MLPRegressor(random_state=17, hidden_layer_sizes=(300, 200 ,100), alpha=0.03, learning_rate='adaptive', learning_rate_init=0.0005, max_iter=200, momentum=0.9, nesterovs_momentum=True) nn.fit(X_train, y_train) print('R^2 train:', nn.score(X_train, y_train)) print('R^2 test:', nn.score(X_holdout, y_holdout)) print('MAE train', mean_absolute_error(nn.predict(X_train), y_train)) print('MAE test', mean_absolute_error(nn.predict(X_holdout), y_holdout))
R^2 train: 0.9771443840549647 R^2 test: -0.15166596239118246 MAE train: 1627.3212161350423 MAE test: 8816.204561947616
ネットワークの最適なアーキテクチャを選択することで達成できることを見てみましょう。 最初に、1つの隠れ層と2つの隠れ層を持つ複数のモデルをトレーニングします.1つの層を持つモデルが200回の反復で収束する時間がないことをもう一度確認し、グラフからわかるように、非常に長い時間収束できることを確認します。 別のレイヤーを追加することは、すでに非常に役立ちます。
plt.figure(figsize=(14, 8)) for i in [(500,), (750,), (1000,), (500,500)]: nn = MLPRegressor(random_state=17, hidden_layer_sizes=i, alpha=0.03, learning_rate='adaptive', learning_rate_init=0.0005, max_iter=200, momentum=0.9, nesterovs_momentum=True) nn.fit(X_train, y_train) plt.plot(nn.loss_curve_, label=str(i)); plt.xlabel('Iterations') plt.ylabel('MSE') plt.legend(loc='best') plt.show()

そして今、私たちは完全に異なるアーキテクチャでより多くのモデルを訓練します。 3 10 .
plt.figure(figsize=(14, 8)) for i in [(500,300,100), (80, 60, 60, 60, 40, 40, 40, 40, 20, 10), (80, 60, 60, 40, 40, 40, 20, 10), (150, 100, 80, 60, 40, 40, 20, 10), (200, 100, 100, 100, 80, 80, 80, 40, 20), (80, 40, 20, 20, 10, 5), (300, 250, 200, 100, 80, 80, 80, 40, 20)]: nn = MLPRegressor(random_state=17, hidden_layer_sizes=i, alpha=0.03, learning_rate='adaptive', learning_rate_init=0.001, max_iter=200, momentum=0.9, nesterovs_momentum=True) nn.fit(X_train, y_train) plt.plot(nn.loss_curve_, label=str(i)); plt.xlabel('Iterations') plt.ylabel('MSE') plt.legend(loc='best') plt.show()
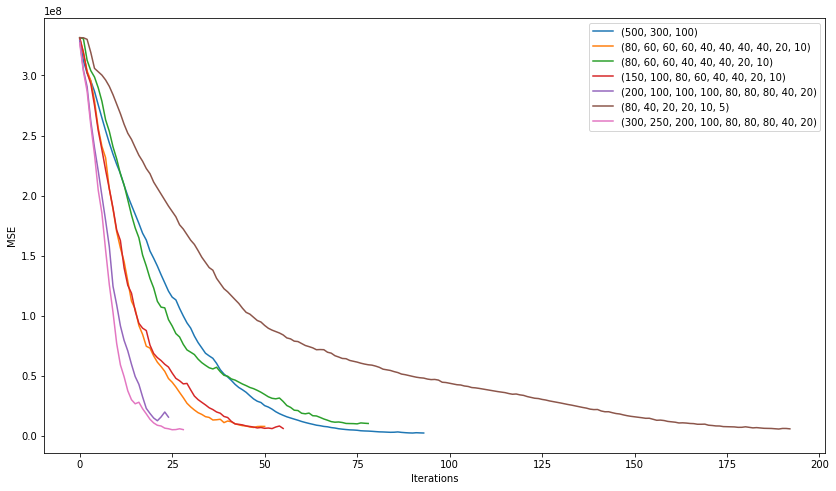
"" (200, 100, 100, 100, 80, 80, 80, 40, 20) :
2506
7351
, , . learning rate .
nn = MLPRegressor(random_state=17, hidden_layer_sizes=(200, 100, 100, 100, 80, 80, 80, 40, 20), alpha=0.1, learning_rate='adaptive', learning_rate_init=0.007, max_iter=200, momentum=0.9, nesterovs_momentum=True) nn.fit(X_train, y_train) print('R^2 train:', nn.score(X_train, y_train)) print('R^2 test:', nn.score(X_holdout, y_holdout)) print('MAE train', mean_absolute_error(nn.predict(X_train), y_train)) print('MAE test', mean_absolute_error(nn.predict(X_holdout), y_holdout))
R^2 train: 0.836204705204337 R^2 test: 0.15858607391959356 MAE train: 4075.8553476632796 MAE test: 7530.502826043687
, . , . , , .
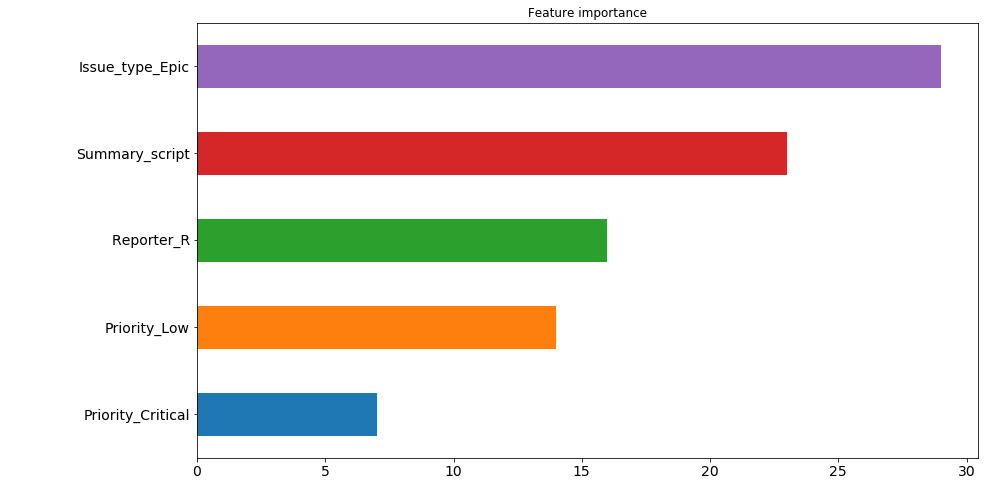
. : ( , 200 ). , "" . , 30 200 , issue type: Epic . , .. , , , , . 4 5 . , . , .
— 9 , . , , , .
pd.Series([X_train.columns[abs(nn.coefs_[0][:,i]).argmax()] for i in range(nn.hidden_layer_sizes[0])]).value_counts().head(5).sort_values().plot(kind='barh', title='Feature importance', fontsize=14, figsize=(14,8));
. なんで? 7530 8217. (7530 + 8217) / 2 = 7873, , , ? いいえ、そうではありません。 , . , 7526.
, kaggle . , , .
nn_predict = nn.predict(X_holdout) xgb_predict = xgb.predict(X_holdout) print('NN MSE:', mean_squared_error(nn_predict, y_holdout)) print('XGB MSE:', mean_squared_error(xgb_predict, y_holdout)) print('Ensemble:', mean_squared_error((nn_predict + xgb_predict) / 2, y_holdout)) print('NN MAE:', mean_absolute_error(nn_predict, y_holdout)) print('XGB MSE:', mean_absolute_error(xgb_predict, y_holdout)) print('Ensemble:', mean_absolute_error((nn_predict + xgb_predict) / 2, y_holdout))
NN MSE: 628107316.262393 XGB MSE: 631417733.4224195 Ensemble: 593516226.8298339 NN MAE: 7530.502826043687 XGB MSE: 8217.07897417256 Ensemble: 7526.763569558157
結果分析
? 7500 . つまり 5 . . . , .
( ):
((nn_predict + xgb_predict) / 2 - y_holdout).apply(np.abs).sort_values(ascending=False).head(10).values
[469132.30504392, 454064.03521379, 252946.87342439, 251786.22682697, 224012.59016987, 15671.21520735, 13201.12440327, 203548.46460229, 172427.32150665, 171088.75543224]
. , .
df.loc[((nn_predict + xgb_predict) / 2 - y_holdout).apply(np.abs).sort_values(ascending=False).head(10).index][['Issue_type', 'Priority', 'Worktype', 'Summary', 'Watchers']]
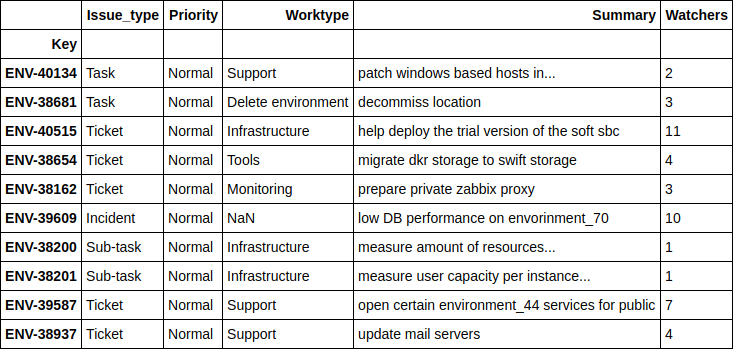
, - , . 4 .
, .
print(((nn_predict + xgb_predict) / 2 - y_holdout).apply(np.abs).sort_values().head(10).values) df.loc[((nn_predict + xgb_predict) / 2 - y_holdout).apply(np.abs).sort_values().head(10).index][['Issue_type', 'Priority', 'Worktype', 'Summary', 'Watchers']]
[ 1.24606014, 2.6723969, 4.51969139, 10.04159236, 11.14335444, 14.4951508, 16.51012874, 17.78445744, 21.56106258, 24.78219295]
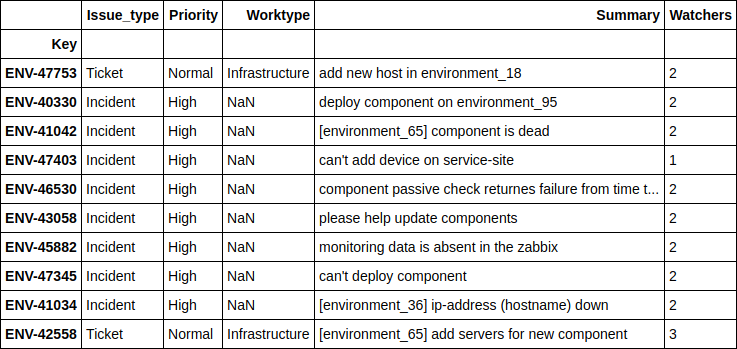
, , - , - . , , , .
Engineer
, 'Engineer', , , ? .
, 2 . , , , , . , , , "" , ( ) , , , . , " ", .
, . , , 12 , ( JQL JIRA):
assignee was engineer_N during (ticket_creation_date) and status was "In Progress"
10783 * 12 = 129396 , … . , , , .. 5 .
, , , , 2 . .
結果と将来の計画
. SLO , .
, , ( : - , - , - ) , .