
Badooでは、毎日170億のイベント、6,000万のユーザーセッション、膨大な数の仮想デートが行われています。 各イベントはリレーショナルデータベースにきちんと保存され、その後のSQL以降の分析に使用できます。
数十テラバイトのデータを持つ最新の分散トランザクションデータベース-エンジニアリングの真の奇跡。 しかし、SQLは、ほとんどの標準実装でのリレーショナル代数の具体化として、順序付けられたタプルの観点からクエリを定式化することをまだ許可していません。
仮想 マシンに関するシリーズの最後の記事では、興味深いセッションを見つけるための代替アプローチ、イベントのシーケンスに対して定義された正規表現エンジン( Pig Match )について説明します。
仮想マシン、バイトコード、コンパイラは無料で含まれています!
イベントとセッションについて
各ユーザーセッションのイベントをすばやく連続して表示できるデータウェアハウスが既にあるとします。
「イベントの指定されたサブシーケンスがあるすべてのセッションをカウントする」、「特定のパターンで記述されたセッションの一部を検索する」、「特定のパターンの後に発生したセッションの一部を返す」、「特定の部分に到達したセッションの数をカウントする」などのリクエストでセッションを検索しますテンプレート。」 これは、疑わしいセッションの検索、ファンネル分析など、さまざまなタイプの分析に役立ちます。
必要なサブシーケンスを何らかの形で説明する必要があります。 最も単純な形式では、このタスクはテキスト内のサブストリングを見つけることに似ています。 より強力なツールである正規表現が必要です。 正規表現エンジンの最新の実装では、ほとんどの場合仮想マシンを使用します(ご想像のとおりです!)。
セッションを正規表現と照合するための小さな仮想マシンの作成については、以下で説明します。 しかし、最初に、定義を明確にします。
イベントは、イベントタイプ、時間、コンテキスト、および各タイプに固有の一連の属性で構成されます。
各イベントのタイプとコンテキストは 、事前定義されたリストの整数です。 イベントのタイプがすべて明確な場合、コンテキストは、たとえば、特定のイベントが発生した画面の番号です。
イベント属性は、イベントのタイプによって意味が決まる任意の整数です。 イベントには属性がない場合や、いくつかある場合があります。
セッションは、時間でソートされた一連のイベントです。
しかし、ついにビジネスに取りかかりましょう。 彼らが言うように、バズはなくなり、私はステージに出ました。
一枚の紙で比較する
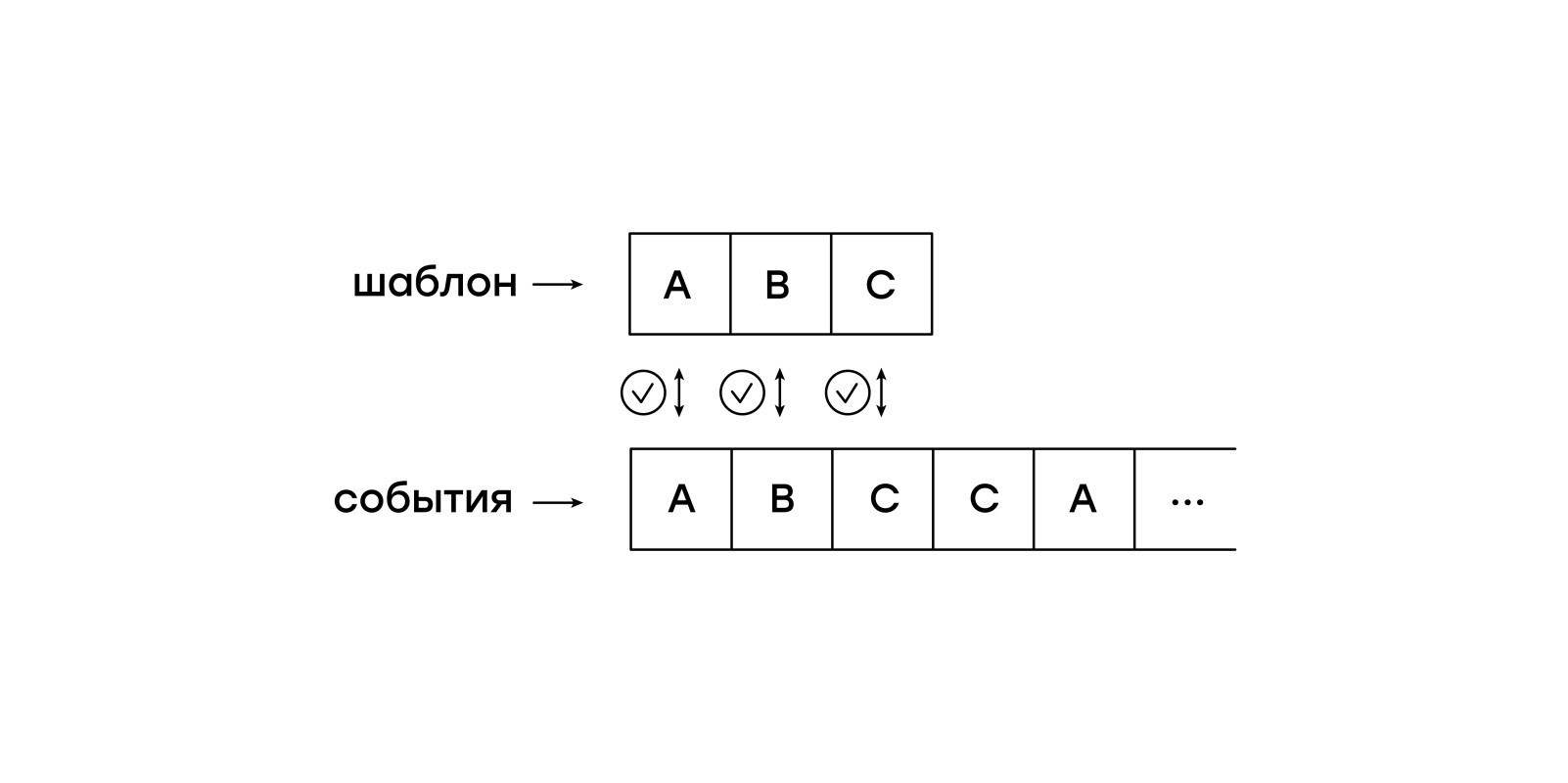
この仮想マシンの特徴は、入力イベントに対する受動性です。 セッション全体をメモリに保持し、仮想マシンがイベントからイベントに独立して切り替えられるようにする必要はありません。 代わりに、セッションから仮想マシンにイベントを1つずつフィードします。
インターフェイス関数を決定します。
matcher *matcher_create(uint8_t *bytecode); match_result matcher_accept(matcher *m, uint32_t event); void matcher_destroy(matcher *matcher);
matcher_create関数とmatcher_destroy関数ですべてが明らかな場合、matcher_acceptはコメントする価値があります。 matcher_accept関数は、仮想マシンのインスタンスと次のイベント(イベントのタイプに16ビット、コンテキストに16ビット)を受け取り、ユーザーコードが次に何をすべきかを説明するコードを返します。
typedef enum match_result { // MATCH_NEXT, // , MATCH_OK, // , MATCH_FAIL, // MATCH_ERROR, } match_result;
仮想マシンのオペコード:
typedef enum matcher_opcode { // , OP_ABORT, // ( - ) OP_NAME, // ( - ) OP_SCREEN, // OP_NEXT, // OP_MATCH, } matcher_opcode;
仮想マシンのメインループ:
match_result matcher_accept(matcher *m, uint32_t next_event) { #define NEXT_OP() \ (*m->ip++) #define NEXT_ARG() \ ((void)(m->ip += 2), (m->ip[-2] << 8) + m->ip[-1]) for (;;) { uint8_t instruction = NEXT_OP(); switch (instruction) { case OP_ABORT:{ return MATCH_ERROR; } case OP_NAME:{ uint16_t name = NEXT_ARG(); if (event_name(next_event) != name) return MATCH_FAIL; break; } case OP_SCREEN:{ uint16_t screen = NEXT_ARG(); if (event_screen(next_event) != screen) return MATCH_FAIL; break; } case OP_NEXT:{ return MATCH_NEXT; } case OP_MATCH:{ return MATCH_OK; } default:{ return MATCH_ERROR; } } } #undef NEXT_OP #undef NEXT_ARG }
この単純なバージョンでは、仮想マシンはバイトコードで記述されたパターンと着信イベントを順番に照合します。 この形式では、これは単に2つの行のプレフィックス(目的のテンプレートと入力行)の非常に簡潔な比較ではありません。
プレフィックスはプレフィックスですが、目的のパターンを最初だけでなく、セッションの任意の場所でも見つけたいと思います。 単純な解決策は、各セッションイベントからマッチングを再開することです。 しかし、これは各イベントの複数の視聴とアルゴリズムの赤ちゃんを食べることを意味します。
シリーズの最初の記事 の例は、実際には、ロールバック(英語のバックトラッキング)を使用して試合を再開することをシミュレートしています。 もちろん、この例のコードはここで示したものよりもスリムに見えますが、問題は解消されていません。各イベントを何度もチェックする必要があります。
あなたはそのように生きることはできません。
私、私、そしてまた私

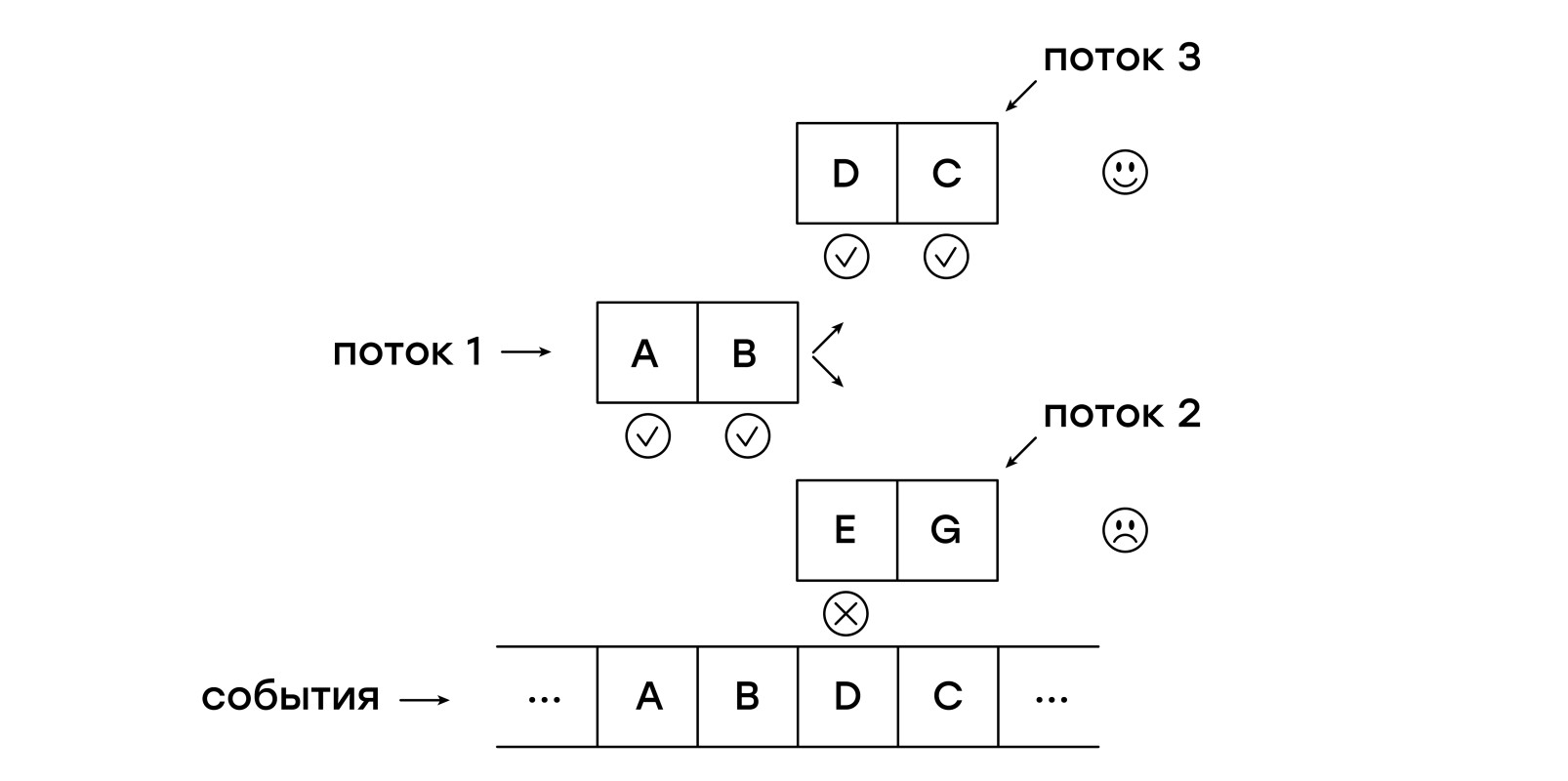
もう一度問題の概要を説明します。新しい比較を開始する各イベントからテンプレートを受信イベントに一致させる必要があります。 では、なぜそれをしないのでしょうか? 仮想マシンは、いくつかのスレッドで着信イベントを調べましょう!
これを行うには、新しいエンティティ-ストリームを取得する必要があります。 各スレッドには、現在の命令への単一のポインターが格納されます。
typedef struct matcher_thread { uint8_t *ip; } matcher_thread;
当然、今では仮想マシン自体に明示的なポインターを保存しません。 ストリームの2つのリストに置き換えられます(詳細については以下を参照)。
typedef struct matcher { uint8_t *bytecode; /* Threads to be processed using the current event */ matcher_thread current_threads[MAX_THREAD_NUM]; uint8_t current_thread_num; /* Threads to be processed using the event to follow */ matcher_thread next_threads[MAX_THREAD_NUM]; uint8_t next_thread_num; } matcher;
そして、更新されたメインループは次のとおりです。
match_result matcher_accept(matcher *m, uint32_t next_event) { #define NEXT_OP(thread) \ (*(thread).ip++) #define NEXT_ARG(thread) \ ((void)((thread).ip += 2), ((thread).ip[-2] << 8) + (thread).ip[-1]) /* - */ add_current_thread(m, initial_thread(m)); // for (size_t thread_i = 0; thread_i < m->current_thread_num; thread_i++ ) { matcher_thread current_thread = m->current_threads[thread_i]; bool thread_done = false; while (!thread_done) { uint8_t instruction = NEXT_OP(current_thread); switch (instruction) { case OP_ABORT:{ return MATCH_ERROR; } case OP_NAME:{ uint16_t name = NEXT_ARG(current_thread); // , , // next_threads, if (event_name(next_event) != name) thread_done = true; break; } case OP_SCREEN:{ uint16_t screen = NEXT_ARG(current_thread); if (event_screen(next_event) != screen) thread_done = true; break; } case OP_NEXT:{ // , .. // next_threads add_next_thread(m, current_thread); thread_done = true; break; } case OP_MATCH:{ return MATCH_OK; } default:{ return MATCH_ERROR; } } } } /* , */ swap_current_and_next(m); return MATCH_NEXT; #undef NEXT_OP #undef NEXT_ARG }
受信した各イベントで、最初に新しいスレッドをcurrent_threadsリストに追加し、最初からテンプレートをチェックします。その後、各スレッドの指示に従って、current_threadsリストのクロールを開始します。
NEXT命令が検出されると、スレッドはリストnext_threadsに配置されます。つまり、次のイベントが受信されるまで待機します。
スレッドパターンが受信したイベントと一致しない場合、そのようなスレッドはnext_threadsリストに追加されません。
MATCH命令はすぐに関数を終了し、パターンがセッションに一致することを示すリターンコードを報告します。
ストリームリストのクロールが完了すると、現在のリストと次のリストが交換されます。
実際には、それだけです。 文字通り、私たちが望んでいたことをやっていると言えます:同時に、いくつかのテンプレートをチェックし、各セッションイベントに対して1つの新しいマッチングプロセスを起動します。
テンプレート内の複数のアイデンティティとブランチ
もちろん、イベントの線形シーケンスを記述するテンプレートを検索することは便利ですが、完全な正規表現を取得する必要があります。 前の段階で作成したフローもここで役立ちます。
興味のある2つまたは3つのイベントのシーケンスを検索するとします。行の正規表現のようなものです: "a?Bc"。 このシーケンスでは、記号「a」はオプションです。 バイトコードで表現するには? 簡単!
各場合に1つずつ、 2つのスレッドを開始できます。シンボル「a」の有無にかかわらず。 これを行うために、指定されたアドレスから2つのスレッドを開始する(SPLITタイプaddr1、addr2の)追加の命令を導入します。 SPLITに加えて、JUMPも役立ちます。JUMPは、直接引数で指定された命令で実行を継続します。
typedef enum matcher_opcode { OP_ABORT, OP_NAME, OP_SCREEN, OP_NEXT, // OP_JUMP, // OP_SPLIT, OP_MATCH, // OP_NUMBER_OF_OPS, } matcher_opcode;
ループ自体と残りの命令は変更されません-2つの新しいハンドラーを導入するだけです。
// ... case OP_JUMP:{ /* , */ uint16_t offset = NEXT_ARG(current_thread); add_current_thread(m, create_thread(m, offset)); break; } case OP_SPLIT:{ /* */ uint16_t left_offset = NEXT_ARG(current_thread); uint16_t right_offset = NEXT_ARG(current_thread); add_current_thread(m, create_thread(m, left_offset)); add_current_thread(m, create_thread(m, right_offset)); break; } // ...
命令はスレッドを現在のリストに追加することに注意してください。つまり、現在のイベントのコンテキストで引き続き動作します。 分岐が発生したスレッドは、次のスレッドのリストには入りません。
この正規表現の仮想マシンで最も驚くべきことは、スレッドとこの命令のペアで、文字列を一致させるときに一般に受け入れられるほぼすべての構造を表現できることです。
イベントの正規表現
適切な仮想マシンとツールが用意できたので、正規表現の構文を実際に処理できます。
より深刻なプログラムのオペコードを手動で記録すると、すぐに疲れてしまいます。 前回は本格的なパーサーを実行しませんでしたが、 本物の ユーザーは、 例 として PigletCミニ言語を使用して 、 raddslライブラリの機能を示しました。 コードの簡潔さに非常に感銘を受けたので、raddslの助けを借りて、Pythonで120個の文字列の正規表現の小さなコンパイラを作成しました。 コンパイラーとその使用方法はGitHubにあります。 アセンブリ言語のコンパイラの結果は、2つのファイル(仮想マシンのプログラムと検証用のセッションイベントのリスト)を読み取るユーティリティによって理解されます。
まず、イベントのタイプとコンテキストに限定します。 イベントのタイプは単一の数字で示されます。 コンテキストを指定する必要がある場合は、コロンで指定します。 最も簡単な例:
> python regexp/regexp.py "13" # , 13 NEXT NAME 13 MATCH
コンテキスト付きの例:
python regexp/regexp.py "13:12" # 13, 12 NEXT NAME 13 SCREEN 12 MATCH
連続するイベントは、何らかの方法で(たとえば、スペースで)区切る必要があります。
> python regexp/regexp.py "13 11 10:9" 08:40:52 NEXT NAME 13 NEXT NAME 11 NEXT NAME 10 SCREEN 9 MATCH
より興味深いテンプレート:
> python regexp/regexp.py "12|13" SPLIT L0 L1 L0: NEXT NAME 12 JUMP L2 L1: NEXT NAME 13 L2: MATCH
コロンで終わる行に注意してください。 これらはタグです。 SPLIT命令は、ラベルL0とL1から実行を継続する2つのスレッドを作成し、実行の最初のブランチの終わりにあるJUMPは、単にブランチの終わりに進みます。
サブシーケンスを括弧でグループ化することにより、より純粋に式のチェーンから選択できます。
> python regexp/regexp.py "(1 2 3)|4" SPLIT L0 L1 L0: NEXT NAME 1 NEXT NAME 2 NEXT NAME 3 JUMP L2 L1: NEXT NAME 4 L2: MATCH
任意のイベントはドットで示されます:
> python regexp/regexp.py ". 1" NEXT NEXT NAME 1 MATCH
サブシーケンスがオプションであることを示したい場合は、その後に疑問符を付けます:
> python regexp/regexp.py "1 2 3? 4" NEXT NAME 1 NEXT NAME 2 SPLIT L0 L1 L0: NEXT NAME 3 L1: NEXT NAME 4 MATCH
もちろん、正規表現では複数の正規の繰り返し(プラスまたはアスタリスク)も一般的です。
> python regexp/regexp.py "1+ 2" L0: NEXT NAME 1 SPLIT L0 L1 L1: NEXT NAME 2 MATCH
ここでは、SPLIT命令を何回も実行し、各サイクルで新しいスレッドを開始します。
同様にアスタリスクの場合:
> python regexp/regexp.py "1* 2" L0: SPLIT L1 L2 L1: NEXT NAME 1 JUMP L0 L2: NEXT NAME 2 MATCH

遠近法
説明した仮想マシンの他の拡張機能が役立つ場合があります。
たとえば、イベント属性をチェックすることで簡単に拡張できます。 実際のシステムでは、「1:2 {3:4、5:> 3}」のような構文を使用することを想定しています。これは、コンテキスト2のイベント1で、属性3の値4と属性値5が3より大きい単純に配列でmatcher_accept関数に渡すことができます。
イベント間の時間間隔もmatcher_acceptに渡す場合、イベント間の時間をスキップできる構文をテンプレート言語に追加できます。「1 mindelta(120)2」、つまり、イベント1、最小120秒、イベント2これにより、サブシーケンスの保存と組み合わせて、イベントの2つのサブシーケンス間のユーザーの行動に関する情報を収集できます。
比較的簡単に追加できるその他の便利な機能には、正規表現のサブシーケンスの保持、貪欲なアスタリスクとプラス演算子の分離などがあります。 オートマトンの理論に関しては、私たちの仮想マシンは非決定的な有限オートマトンであり、その実装のためにそのようなことを行うことは難しくありません。
おわりに
私たちのシステムは高速なユーザーインターフェース用に開発されているため、セッションストレージエンジンはすべてのセッションを通過するように特に記述され、最適化されています。 セッションで分割された数十億のイベントはすべて、単一サーバーで数秒でパターンと照合されます。
速度がそれほど重要でない場合は、従来のリレーショナルデータベースや分散ファイルシステムなど、より標準的なデータストレージシステムの拡張機能として同様のシステムを設計できます。
ところで、 SQL標準の最新バージョンでは 、この記事で説明されている機能に似た機能が既に登場しており、別のデータベース( OracleとVertica )がすでに実装しています。 Yandex ClickHouseは、独自のSQLライクな言語を実装していますが、 同様の機能も備えています 。
イベントや正規表現から注意をそらして、仮想マシンの適用範囲は一見すると思われるよりもはるかに広いことを繰り返します。 この手法は、システムエンジンが理解するプリミティブと「フロント」サブシステム、つまりDSLやプログラミング言語とを明確に区別する必要があるすべての場合に適し、広く使用されています。
これで、バイトコードインタープリターと仮想マシンのさまざまな使用に関する一連の記事を締めくくります。 Habrの読者がこのシリーズを気に入ってくれたことを願っています。もちろん、このトピックに関する質問に喜んでお答えします。
非公式の参照
プログラミング言語のバイトコードインタプリタは特定のトピックであり、それらに関する文献はほとんどありません。 個人的には、Ian Craig の書籍Virtual Machinesが好きでしたが、インタープリターの実装は抽象的なマシンほどではありません。さまざまなプログラミング言語の基礎となる数学モデルです。
より広い意味で、別の本が仮想マシンに捧げられています- 「仮想マシン:システムおよびプロセス用の柔軟なプラットフォーム」 (「仮想マシン:システムおよびプロセス用の汎用プラットフォーム」)。 これは、仮想化のさまざまなアプリケーションの紹介であり、一般的な言語、プロセス、およびコンピューターアーキテクチャの仮想化をカバーしています。
正規表現エンジンの開発の実際的な側面は、一般的なコンパイラの文献でめったに議論されません。 Pig Matchと最初の記事の例は、Google RE2エンジンの開発者の1人であるRuss Cox による一連のすばらしい記事のアイデアに基づいています。
正規表現の理論は、コンパイラに関するすべての学術教科書に記載されています。 有名な「ドラゴンブック」を参照するのが慣習ですが、上記のリンクから始めることをお勧めします。
この記事に取り組んでいる間、私は最初にPython raddslのコンパイラーを迅速に開発するために興味深いシステムを使用しました。これはユーザーtrue-grue (ありがとう、Peter!)のペンに属します。 言語のプロトタイピングや、ある種のDSLの迅速な開発のタスクに直面している場合は、それに注意を払う必要があります。