
しかし、代替アーキテクチャがあります-接着アーキテクチャ。 デュアルプロセッサコンピューティングユニットは、ノードコントローラーを介して相互接続されています。 彼らの助けを借りて、サーバーあたりの上限しきい値は16以上のプロセッサに上昇します。 この投稿では、一般的な接着アーキテクチャと、それがサーバーにどのように実装されるかについて詳しく説明します。
接着されたアーキテクチャに移る前に、正直さのために、接着剤なしの長所と短所について説明します。
グルーレスアーキテクチャに従って作成されたソリューションが一般的です。 プロセッサは、追加のデバイスなしで、標準QPI \ UPIバスを介して相互に通信します。 結果は、接着剤を使用した場合よりも少し安くなります。 しかし、8台のプロセッサごとに多くのお金を費やさなければならない-新しいサーバーをインストールするために。

典型的なグルーレスアーキテクチャ
また、既に説明したように、接着アーキテクチャを使用すると、サーバーあたりのプロセッサ数が16以上になります。
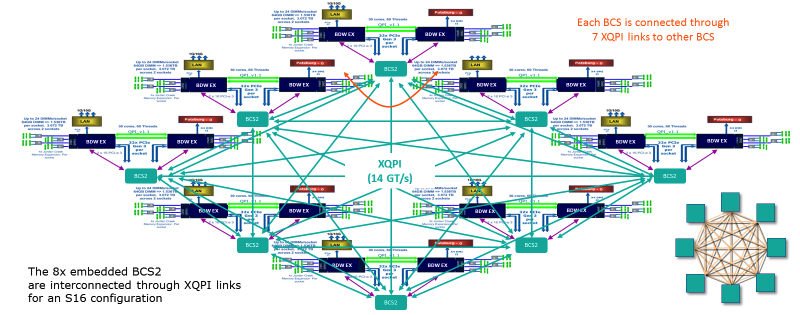
Bull BCS2接着アーキテクチャの仕組み
Bull BCS2アーキテクチャの利点は、2つのコンポーネント(Resilient eXternal Node-Controllerとプロセッサキャッシング)によって提供されます。 Intel Xeon E7-4800 / 8800 v4シリーズプロセッサと互換性のあるチームがサポートされています。

接着されたアーキテクチャBull BCS2。 サーバー内のすべての接続がここに表示されます。 各BCSノードには7つのXQPIリンクがあります。
キャッシングのおかげで、プロセッサー間の相互作用の量が減ります-各モジュールのプロセッサーは共通のキャッシュにアクセスできます。 したがって、RAMの負荷が軽減されます。 野田は、次に、トラフィックスイッチとして機能し、「狭いネック」の問題を解決します-最も使用されていないパスに沿ってトラフィックをリダイレクトします。
その結果、Bull BCS2アーキテクチャでは、グルーレスアーキテクチャの標準であるIntel QPIバス帯域幅の5〜10%しか消費されません。 ローカルメモリへのアクセス遅延に関しては、4ソケットのグルーレスシステムに匹敵し、8ソケットのグルーレスシステムよりも44%少ないです。 仕様によれば、BCSノードの合計データ転送速度は230 GB / sです-7ポートのそれぞれで25.6 GB / sが取得されます。 最大帯域幅は300 GB / sです。

Bullion Sの各サーバーには、マザーボードにそのようなスイッチがあります。 速度の点で1つのXQPIリンク(16ソケット)は、10個の10 GigEポートに相当します。

レンジブリオンS
4プロセッサと8プロセッサの構成では、接着アーキテクチャと接着なしアーキテクチャの違いはごくわずかです。 ただし、16プロセッサへの移行により状況は変わります。 グルーレスでは、このためにすでに2つのサーバーが必要であることを覚えています。 そして、接着されたアーキテクチャを備えたBullion Sサーバーでは、すべてが次のように侵入します。
デュアルプロセッサモジュールは、XQPIネットワークを介して相互接続され、スループットは14 GT / s(1秒あたり数十億トランザクション)
スロットは、デュアルプロセッサ構成でのみ使用できるE7-8893を除き、E7ファミリのすべてのプロセッサに対応しています。 ローカルメモリにアクセスする場合と比較して、NUMAシステムの遅延はモジュール内で約x1.5、モジュール間で約x4に達します。 ホストコントローラーはハードウェアパーティションを管理し、Bullion Sサーバーのオペレーティングシステムで実行する最大8つの個別のパーティションを作成できます。
その結果、1台のサーバーで最大384個のプロセッサコアをホストする機会が得られます。 RAMについては、ここでの上限は64 GBの384 DDR4モジュールです。 合計で24テラバイトになります。
説明されている構成は、当社の主力製品であるBullion Sサーバーに関連しています。それに加えて、Intel PurleyプラットフォームとSkylakeおよびCascadelakeアーキテクチャに基づく最大32個の物理プロセッサーを含むBullSequana Sラインがあります(2019年第1四半期)。
統合の例
Bullion Sは、SAP HANA、Oracle、MS SQL、Datalake(BullSequana SのCloudera認定を取得)、VMwareの仮想化/ VDI、およびVMware vSANに基づくハイパーコンバージドソリューションなどの厳しいタスク向けに設計されています。 部分的にBullion Sサーバー上で、シーメンスは世界最大のSAP HANAプラットフォームを作成しました。 また、Bullion Sに基づいて、PWCはHadoopと分析のための巨大なソリューションを構築しました。 合計で、世界の約300社がブルソリューションを使用しています。
サーバーの機能を把握するために、ロシアのある電気通信事業者の支店でOracleデータベースをPowerからx86に移行する計画を提示します。

おわりに
プロセッサキャッシングのおかげで、接着されたアーキテクチャにより、プロセッサはノード内の他のプロセッサと直接通信できます。 クイックリンク-他のクラスターとやり取りするときに速度を落とさないでください。 現在、最大16個のプロセッサ(384コア)と最大24 TBのRAMが1つのBullion Sサーバーに収まります。 スケーリングのステップは2つのプロセッサです。これにより、ITインフラストラクチャを作成する際の経済的負荷の分散が促進されます。
今後の資料では、サーバーをより詳細に解析する予定です。 コメントでご質問にお答えいたします。