
12月3日、 Quora は 、「悪意のある第三者」の行為により、コメントやプライベートメッセージのマイナスなどの個人的な活動を含め、1億のユーザーアカウントが侵害されたと発表しました。
データリークは、オンラインサービスのライフサイクルの厄介な部分です。人気が高まるほど、目標になります。 ほぼすべての主要なオンラインサービスにはセキュリティホールがあります。Facebook、Google、Twitter、Yahoo、Tumblr、Uber、Evernote、eBay、Adobe、Target、Twitter、Sonyは、過去数年にわたってユーザーデータを漏らしています。
このようなセキュリティ侵害は、パスワードマネージャーを使用するための強力な議論ですが、インターネットから完全に切断する場合を除き、お気に入りのサービスの使用に対する説得力のある議論とは言えません。
ただし、Quoraサービスを使用してはならない他のすべての理由を思い出すのに最適な時期のようです。
知識の心の蓄積
4年前、 エリックミルは知識の精神的な蓄積へのサービスの傾向について書いたが、それ以来何も変わっていない。 「 プロジェクトについて」ページによると、「Quoraの使命は、世界と情報を共有し、増やすことです。」 1か月に3億人のユーザーとサービス開始から寄せられた4,000万の質問により、プロジェクトは世界の知識を完全に増やすことができますが、彼らはそれをなんとか共有しています。
このサービスの全体的な価値は、ユーザーが提供する回答にあります。サービスは、質問を検索して回答するための優れたプラットフォームを作成するために多くのことを行います。 しかし、彼らはあなたがこのユーザー入力を抽出できないことを確実にするためにすべてをします。 Quoraで:
- パブリックAPIはありません。
- バックアップまたはエクスポート用のツールはありません。
- アカウントなしで回答へのアクセスは制限されています。
- 自動化されたスクリプトと非公式のAPIはブロックされ、Webサイトからの情報のダウンロードに関する質問は削除されました。
API 、膨大な数のユーザー作成ツール、サポートコミュニティ 、 データのクエリとエクスポート用の強力なデータエクスプローラーツール、リベラルな自動ダウンロードポリシーを提供する競合他社のStack OverflowとStack Exchangeと状況を比較してください。 さらに、サービスは承認のための質問と回答を隠そうとしません。 さらに、ユーザーが作成したデータの匿名化されたデータベースを 、Creative Commonsライセンスの下で後世のためにオンラインアーカイブに積極的にアップロードします 。
はい、 Ask MetaFilterでさえ、歴史をざっと調べることができます。このサイトの大部分は1人が作成しました。
ロックを保存
もちろん、APIやエクスポートなどのツールはこのサービスの優先順位ではないと主張することで、特にそれらがまだほとんど利益を上げていないことを考えると、それらを正当化できます。
ただし、長年にわたって、Quoraサイトは、オンラインアーカイブがサイトのインデックスを作成することを特に禁止しています。 Wayback Machineインデックスでページを検索すると、次のように表示されます。
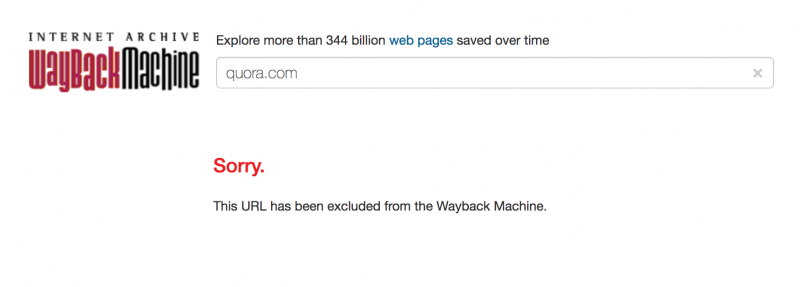
Quoraは文字通り何もできず、インターネットアーカイブは数百万人のユーザーを将来にわたって稼働させ続けますが、彼らは自分のサイトをアーカイブから除外することにしました。
robots.txtファイルでは、Wayback Machineをブロックしている理由を説明し、作成者を保護するためにこれを実行していると述べています。
人々はQuoraに関する大量のデリケートな資料を共有しています-物議を醸す政治的見解、仕事からの噂、企業に関する否定的な意見。 年が経つと、彼らは心を変えたり仕事をしたりします。以前の答えを削除したり、非人格化したりできるようにすることが重要です。
そうでないと、人々は機密性の高い回答を書いた著者の身元を明らかにすることができ、それらを匿名化した後、そして著者がそれを公開することに心を変えた後にインターネットからコンテンツを削除することが不可能になるため、ウェイバックマシンを拒否します。 私たちが知る限り、アーカイブからコンテンツを選択的に削除する方法はないため、これがライターを保護する唯一の方法です。 作成者がQuoraからコンテンツを削除し、残りを残すときにコンテンツを削除できるAPIをアーカイブが開いた場合、喜んでアーカイブに参加します。
インターネットアーカイブは公共インターネットの歴史的なアーカイブであり、アーカイブを選択的に変更する機能に対するQuoraの要求はばかげています。 このようなAPIは、悪用の理想的なターゲットになります。
インターネットアーカイブは、思いがけないスタートアップビジネスプラン、非常に不幸な状況、または合併の保険として意図せずに機能します。 ユーザーが生成したコンテンツを含むソーシャルプラットフォームを管理することにより、ユーザーの集合作業が無駄にならないようにする責任があります。 責任の一部は、ウェブの生活に参加し、あなたがそれから取ったものをそれを返すことです。
FAQ Wayback Machineからの抜粋:
インターネットアーカイブがインターネットからサイトを収集するのはなぜですか? この情報が役立つのはなぜですか?Quoraサイトを閉じることは、ありそうもない機会ではなく、個人的なストーリーと知識のこのユニークなコレクションを維持する説得力のある理由があります。 ベンチャー資金を受け取るほとんどのソーシャルプラットフォームは閉鎖され、多くの場合、残っているのはボランティアアーキビストとインターネットアーカイブが保存しているものだけです。
ほとんどの社会では、文化遺産の遺物を保存することが重要であると考えられています。 そのようなアーティファクトがなければ、文明には成功と失敗に基づく記憶と学習のメカニズムがありません。 私たちの文化はますます多くのデジタル成果物を生み出しています。 アーカイブの使命は、これらのアーティファクトを保存し、研究者、歴史家、学者向けのオンラインライブラリを作成することです。
コミュニティの貢献を閉じるQuoraによるすべての試みは、サイトがダウンした後にコンテンツを保存するタスクを非常に複雑にします。 Quoraに貢献したい場合、彼らはあなたの作品へのアクセスを制限するために積極的に戦います。
ライブラリの書き込み
サイトの設立からほぼ10年が経過しており、Quoraの長期的な見通しはまだ定義されていません。 彼はすでに4ラウンドの資金調達で2億2,500万ドル以上を受け取っており、前回は2017年4月に8,500万ドルの貢献で、その推定額は17億ドルでした。
昨年、このサイトは独自の広告プラットフォームを立ち上げましたが、その収入をまだ発表していません。 そして、これは彼が少なくとも何かを獲得した9年ぶりの存在であり、これは何よりも優れていますが、そのようなモデルがプロジェクトを支援するかどうかの問題は未解決のままです。
ある時点で、25億ドルを投資した投資家は、お金を取り戻したいと思うでしょう。 昨年、プロジェクトの創設者であるアダム・ダンジェロは、遅かれ早かれ公開すると発表しました。 ただし、市場の状態は、広告プラットフォームの成果と相まって、別の方向に進む可能性があり、合併や売却は常に機会のリストに残ります。
Quoraが閉じて、このサイトがいつか閉じると、プロジェクトが孤立主義者の性格を変更しない限り、収集されたこの知識はすべて失われます。
2012年、Adam Dianjedloは次のように書きました。「インターネット上のアレクサンドリアライブラリになることを願っています。」 しかし、Quoraが出口を煮詰め続ける限り、まったく同じ運命に苦しむ可能性があります。