家に着いた後、私は再び慎重に課題を読み直し、アーカイブをダウンロードし、中身を調べ始めました。 そしてその中には:
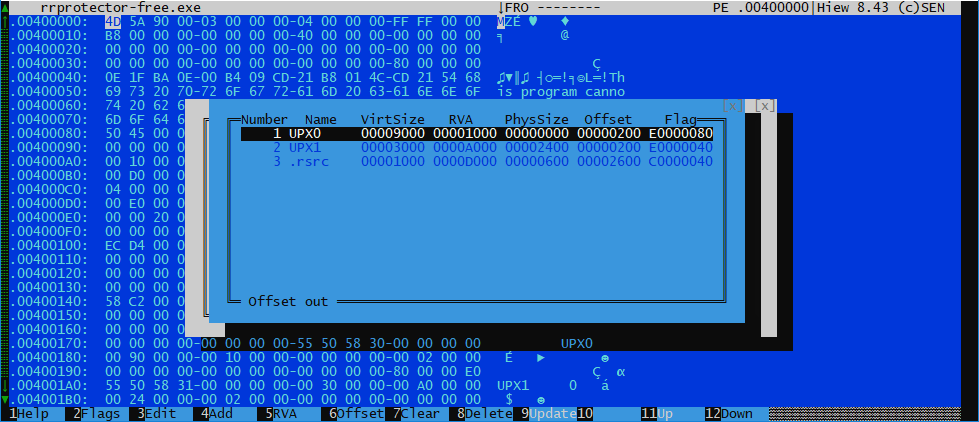
x64dbgを起動し、アンパック後にダンプし、実際に内部にあるものを確認します。
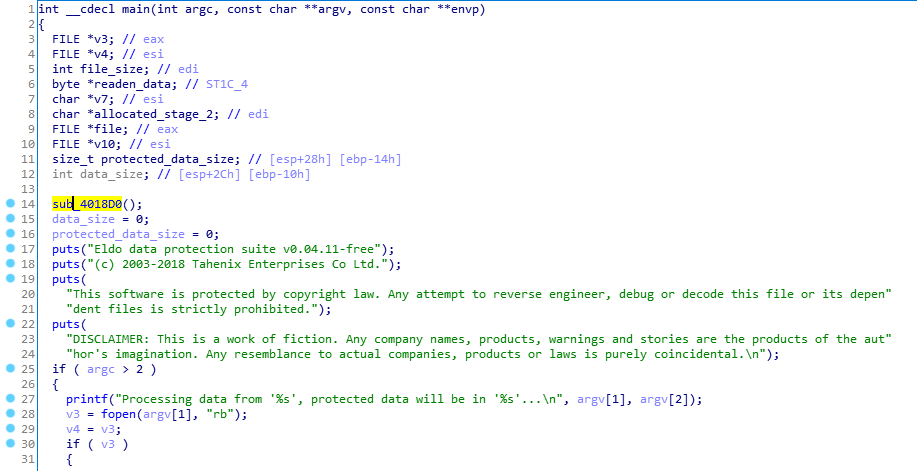

コマンドライン引数からファイル名を取得します->開く、読み取る->最初のステップを暗号化する-> 2番目のステップを暗号化する->新しいファイルに書き込みます。
簡単です。暗号化を見てみましょう。
stage1から始めましょう
アドレス0x4033f4には、crypt_64bit_upと呼ばれる関数があります(後で理由がわかります)。stage1内のどこかのループから呼び出されます。

そして、少し曲がった逆コンパイル結果
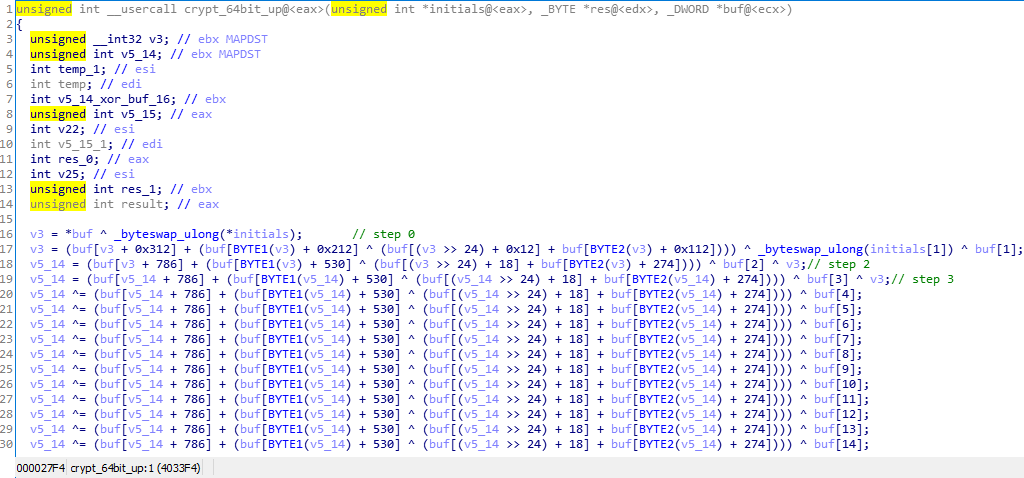
最初に私はPythonで同じアルゴリズムを書き換えようとし、数時間それを殺しましたが、それはこのようなものになりました(get_dwordとbyteswapは名前から明確になるはずです)
def _add(x1, x2): return (x1+x2) & 0xFFFFFFFF def get_buf_val(t, buffer): t_0 = t & 0xFF t_1 = (t >> 8) & 0xFF t_2 = (t >> 16) & 0xFF t_3 = (t >> 24) & 0xFF res = _add(get_dword(buffer, t_0 + 0x312), (get_dword(buffer, t_1 + 0x212) ^ _add(get_dword(buffer, t_2+0x112), get_dword(buffer, t_3+0x12)))) # print('Got buf val: 0x%X' % res) return res def crypt_64bit_up(initials, buffer): steps = [] steps.append(get_dword(buffer, 0) ^ byteswap(initials[0])) # = z steps.append(get_buf_val(steps[-1], buffer) ^ byteswap(initials[1]) ^ get_dword(buffer, 1)) for i in range(2, 17): steps.append(get_buf_val(steps[-1], buffer) ^ get_dword(buffer, i) ^ steps[i-2]) res_0 = steps[15] ^ get_dword(buffer, 17) res_1 = steps[16] print('Res[0]=0x%X, res[1]=0x%X' % (res_0, res_1))
しかし、その後、定数0x12、0x112、0x212、0x312に注意を払うことにしました(16進数18、274、536なし...異常なものとはあまり似ていません)。 私たちはそれらをグーグルで試し、暗号化および復号化機能の実装を含むリポジトリ全体(ヒント:NTR)を見つけようとします。これは幸運です。 元のプログラムのランダムなコンテンツでテストファイルを暗号化し、それをダンプし、小さなスクリプトで同じファイルを暗号化しようとします。すべてが機能し、結果が同じになるはずです。 その後、私たちはそれを復号化しようとします(詳細に立ち入らず、ソースから復号化関数をコピーアンドペーストすることにしました)
def crypt_64bit_down(initials, keybuf): x = initials[0] y = initials[1] for i in range(0x11, 1, -1): z = get_dword(keybuf, i) ^ x x = get_buf_val(z, keybuf) x = y ^ x y = z res_0 = x ^ get_dword(keybuf, 0x01) # x - step[i], y - step[i-1] res_1 = y ^ get_dword(keybuf, 0x0) return (res_1, res_0) def stage1_unpack(packed_data, state): res = bytearray() for i in range(0, len(packed_data), 8): ciphered = struct.unpack('>II', packed_data[i:i+8]) res += struct.pack('>II', *crypt_64bit_down(ciphered, state)) return res
重要な注意:リポジトリ内のキーはプログラム内のキーとは異なります(非常に論理的です)。 したがって、キーが初期化された後、私はそれをファイルにダンプしました、これはバッファ/ keybufです
第二部に進みます
ここではすべてが非常に簡単です:最初に、範囲(33、118)(印刷可能な文字)のサイズ0x55バイトで一意の文字の配列が作成され、次に32ビット値が以前に作成された配列から5つの印刷可能な文字にパックされます。
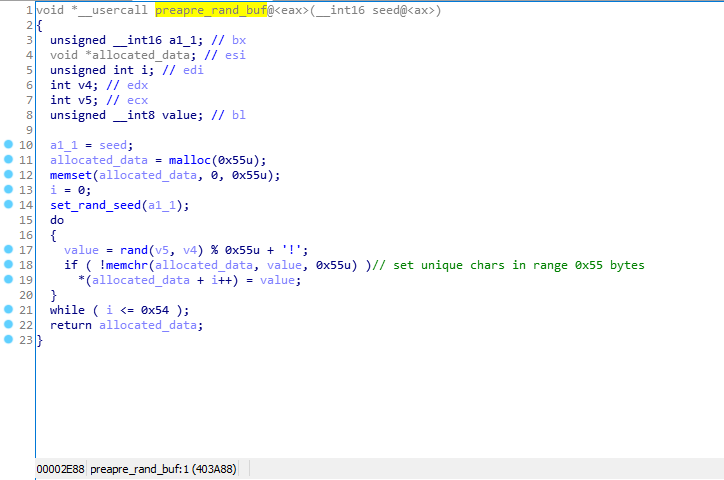
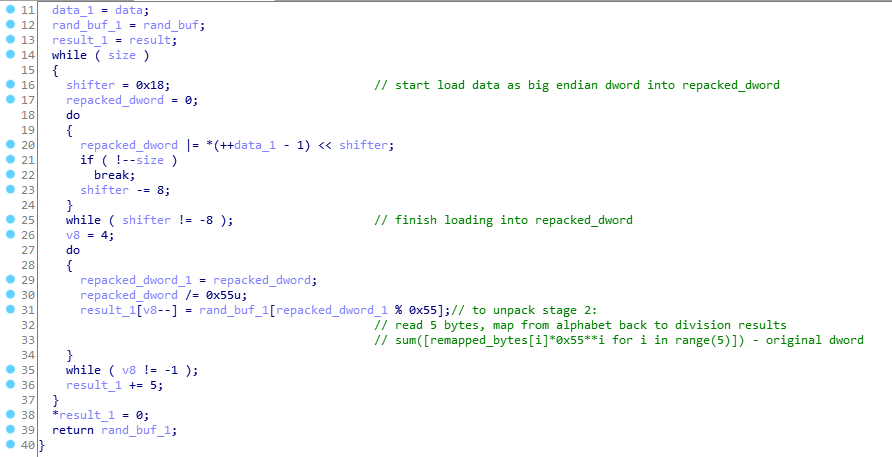
上記の配列を作成する際にランダム性がないため、プログラムが起動するたびに、この配列は同じになります。初期化後にダンプし、単純な関数でstage_2を解凍できます。
def stage2_unpack(packed_data, state): # checked! res = bytearray() for j in range(0, len(packed_data), 5): mapped = [state.index(packed_data[j+i]) for i in range(5)] res += struct.pack('>I', sum([mapped[4-i]*0x55**i for i in range(5)])) return res
このようなことをします:
f = open('stage1.state.bin', 'rb') stage1 = f.read() f.close() f = open('stage2.state.bin', 'rb') stage2 = f.read() f.close() f = open('rprotected.dat', 'rb') packed = f.read() f.close() unpacked_from_2 = stage2_unpack(packed, stage2) f = open('unpacked_from_2', 'wb') f.write(unpacked_from_2) f.close() unpacked_from_1 = stage1_unpack(unpacked_from_2, stage1) f = open('unpacked_from_1', 'wb') f.write(unpacked_from_1) f.close()
そして結果が得られます
