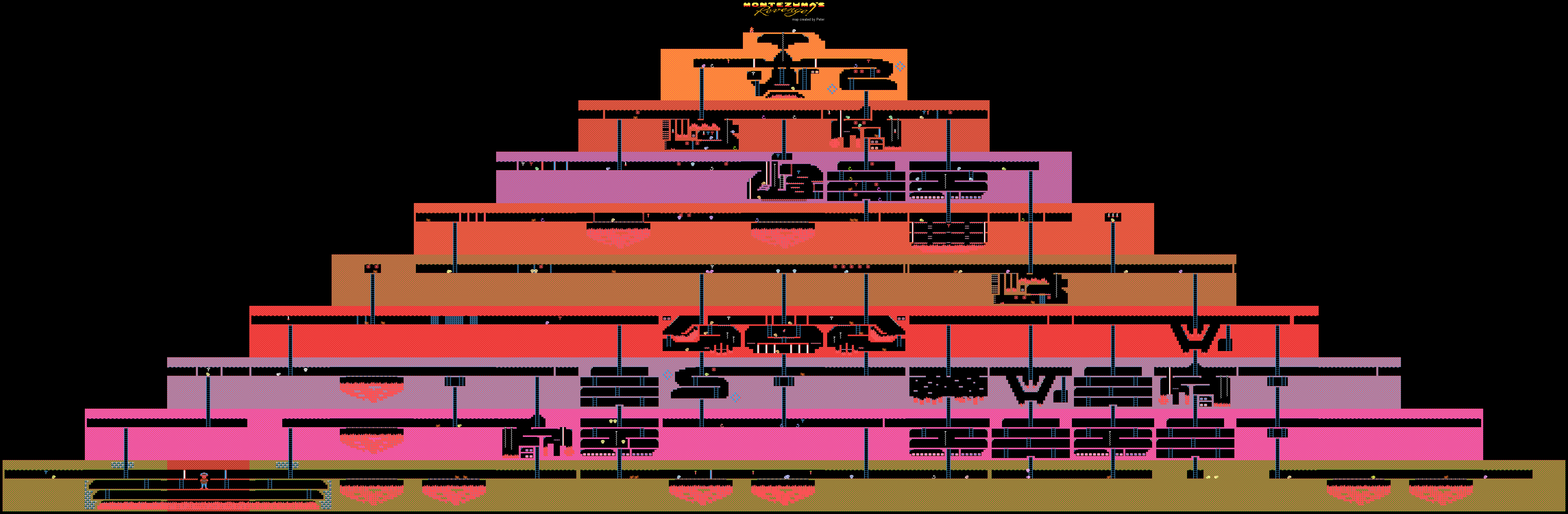
モンテスマのアブレの復Reゲームについてはあまり書かれていません。 これは以前は非常に人気があった複雑な古典的なゲームですが、今ではノスタルジックな感情を喚起する人やAIを開発している研究者によってプレイされています。
この夏、DeepMindがAIに、モンテズマの復playを含むアタリのゲームのプレイ方法を教えることができたと報告されました。 同じゲームの例を使用して、OpenAIの作成者も開発を教えました。 現在、Uberは同様のプロジェクトを始めています。
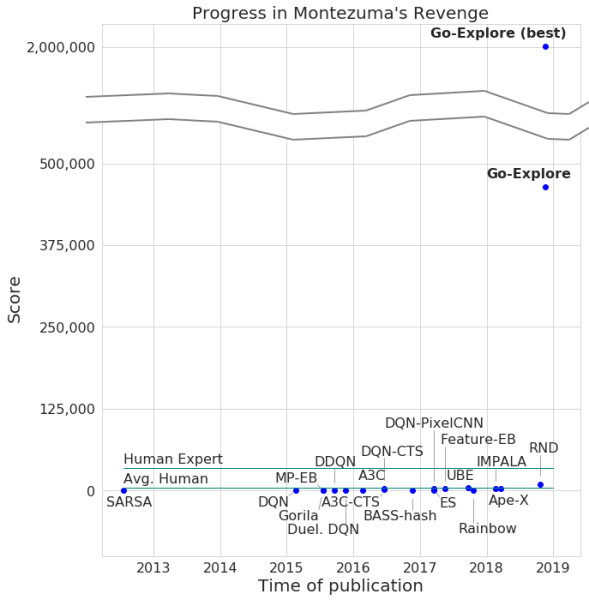
開発者は、最大数が200万に達するニューラルネットワークによるゲームの通過を発表しましたが、平均して、システムは各試行で40万を超えませんでした。 通路については、コンピューターはレベル159に達しました。
さらに、Go-Exploreは、他のAIエージェントは言うまでもなく、Pitfallを通過する方法を学びました。これは、平均的なゲーマーよりも優れた優れた結果をもたらしました。 このゲームでGo-Exploreが獲得したポイント数は21,000です。
Go-Exploreと「同僚」の違いは、ニューラルネットワークがトレーニングのために異なるレベルの合格を示す必要がないことです。 システムはゲーム中にすべてを学習し、視覚トレーニングを必要とするニューラルネットワークで示される結果よりもはるかに高い結果を示します。 Go-Exploreの開発者によると、この技術は他のすべての技術とは大きく異なり、その機能により、ロボット工学を含む多くの分野でニューラルネットワークを使用できます。
ほとんどのアルゴリズムは、ゲームに明確なフィードバックがないため、MontezumaのRevengeに対処するのが困難です。 たとえば、レベルを通過する過程で報酬を受け取るために「シャープ」にされたニューラルネットワークは、出口につながるはしごにジャンプしてより速く前進できるようにするよりも、むしろ敵と戦うでしょう。 他のAIシステムは、今ここで報酬を受け取ることを好み、それ以上の「希望」で前進することを好みません。
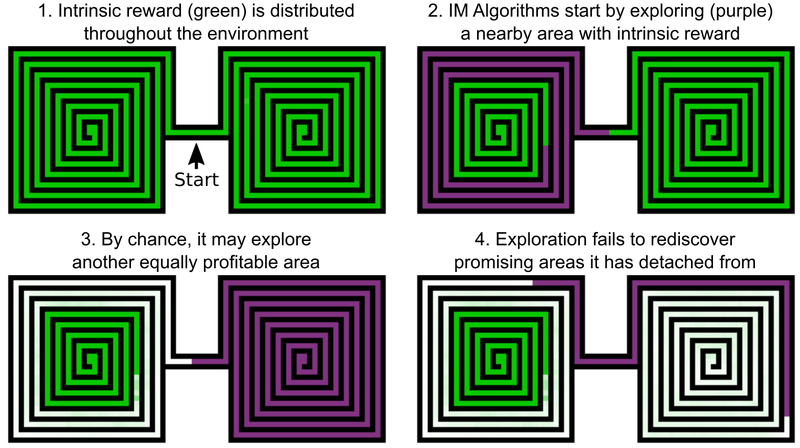
Uberエンジニアの決定事項の1つは、ゲームの世界を探索するためのボーナスを追加することです。これはAIの内部的な動機と呼ばれます。 しかし、固有の動機付けが追加されたAI要素でさえ、モンテズマの復venと落とし穴ではうまくいきません。 問題は、AIが有望な場所を通過した後に「忘れる」ことです。 その結果、AIエージェントはすべてが調査されたと思われるレベルでスタックします。
たとえば、AIエージェントは、東と西の2つの迷路を研究する必要があります。 彼はそれらの1つを通過し始めますが、突然2番目を通過する可能性があると判断します。 最初は50%で、2番目は100%で研究されています。 そして、エージェントは最初の迷路に戻りません-単に彼が最後まで完了していなかったことを「忘れた」からです。 そして、東と西の迷路の間の通路はすでに研究されているので、AIに戻る動機はありません。
Uberの開発者によると、この問題の解決策には、研究と増幅という2つの段階があります。 最初の部分に関しては、ここでAIはさまざまなゲーム状態(セル(セル))とそれらにつながるさまざまな軌道のアーカイブを作成します。 AIは、最適な軌道を検出するときに最大数のポイントを取得する機会を選択します。
セルは、ゲームのさらなる通過を妨げないように、フレームが十分に異なる、8ピクセル強度のグレーの濃淡の11 x 8画像である単純化されたゲームフレームです。

その結果、AIは有望な場所を記憶し、ゲーム世界の他の部分を調べた後にそれらに戻ります。 Go-Exploreでゲームの世界と有望な場所を探索する「欲望」は、今ここで賞を受賞したいという願望よりも強いです。 Go-Exploreは、AIエージェントがトレーニングされているセルに関する情報も使用します。 Montezuma's Revengeの場合、XおよびY座標、現在の部屋、見つかったキーの数などのピクセルデータです。
増幅段階は、「ノイズ」に対する保護として機能します。 AIソリューションが「ノイズ」に対して不安定な場合、AIは、人間の脳ニューロンの例で動作するマルチレベルニューラルネットワークの助けを借りてそれらを強化します。

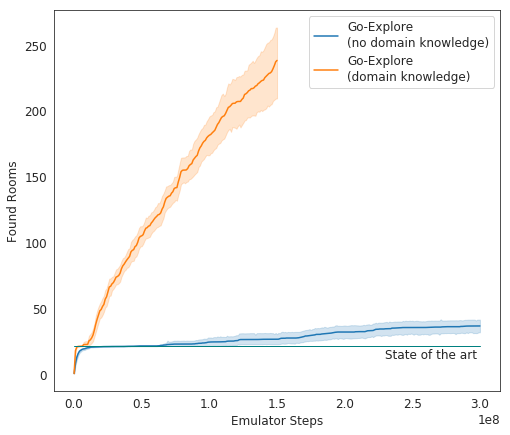
テストでは、Go-Exploreは非常に優れたパフォーマンスを発揮します。平均して、AIは37の部屋を調査し、第1レベルのパズルの65%を解決します。 これは、ゲームを征服する以前の試みよりもはるかに優れています-その後、AIは平均して第1レベルの22部屋を調査しました。

既存のアルゴリズムにゲインを追加すると、AIは平均29レベル(部屋ではなく)で正常に完了し始め、平均ポイント数は469.209になりました。
UberのAIの最終的な化身は、他のAIエージェントよりもはるかに優れたゲームを実行し始め、人間よりも優れています。 現在、開発者はシステムを改善して、さらに印象的な結果を示しています。