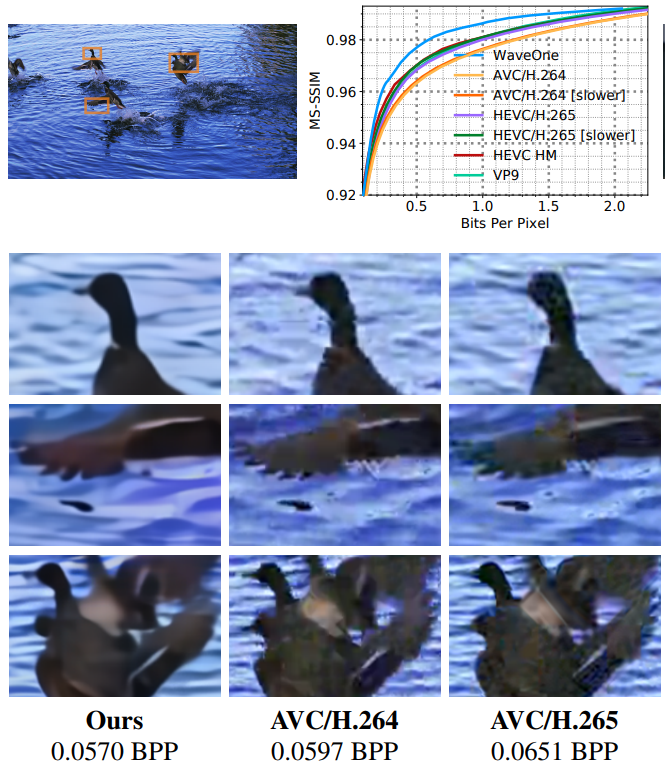
ほぼ同じBPP値(ピクセルあたりのビット数)を持つ異なるコーデックで圧縮されたビデオフラグメントの再構築の例。 比較テストの結果は猫の下で見る
WaveOneの研究者は、ビデオ圧縮の革命に近いと主張しています。 1080pの高解像度ビデオを処理する場合、 新しい機械学習コーデックは、H.265やVP9などの最新の従来のビデオコーデックよりも約20%優れた圧縮率でビデオを圧縮します。 また、「標準解像度」ビデオ(SD / VGA、640×480)では、差は60%に達します。
開発者は、H.265およびVP9で実装されている現在のビデオ圧縮方法を、最新の技術の標準に従って「古代」と呼びます:「過去20年にわたって、既存のビデオ圧縮アルゴリズムの基盤は大幅に変更されていません」 「それらは非常にうまく設計され、慎重に調整されていますが、ハードコーディングされたままであるため、ソーシャルメディア、オブジェクト検出、バーチャルリアリティストリーミングなどの交換を含む、ビデオマテリアルの需要の増加や用途の拡大に適応できません。」
機械学習は、最終的にビデオ圧縮技術を21世紀にもたらします。 新しい圧縮アルゴリズムは、既存のビデオコーデックよりも大幅に優れています。 「私たちが知る限り、これはそのような結果を示した最初の機械学習方法です」と彼らは言います。
ビデオ圧縮の主なアイデアは、冗長なデータを削除し、後でビデオを再生できる短い説明に置き換えることです。 ほとんどのビデオ圧縮は2段階で行われます。
コーデックが移動オブジェクトを検索し、次のフレームのどこに移動するかを予測しようとする場合、最初の段階はモーション圧縮です。 次に、この移動オブジェクトに関連付けられたピクセルを各フレームで記録する代わりに、アルゴリズムはオブジェクトの形状のみを移動方向とともにエンコードします。 実際、いくつかのアルゴリズムは将来のフレームを見て動きをさらに正確に決定していますが、これは明らかにライブ放送では機能しません。
2番目の圧縮ステップは、1つのフレームと次のフレームとの間の他の冗長性を削除します。 したがって、青い空の各ピクセルの色を記録する代わりに、圧縮アルゴリズムはこの色の領域を判別し、次の数フレームにわたって変化しないことを示すことができます。 したがって、これらのピクセルは、変更するよう指示されるまで同じ色のままです。 これは残留圧縮と呼ばれます。
科学者が導入した新しいアプローチでは、機械学習を初めて使用して、これらの圧縮方法の両方を改善しています。 そのため、動きを圧縮するときに、チームの機械学習方法は、動きに基づく新しい冗長性を発見しました。これは、従来のコーデックでは検出できなかった、はるかに少ない使用量です。 たとえば、人の頭を正面から見たものをプロファイルに変更すると、「従来のコーデックでは正面から見た人のプロファイルを予測できない」という結果が常に得られます。 それどころか、新しいコーデックはこれらのタイプの時空間パターンを研究し、それらを使用して将来のフレームを予測します。
別の問題は、モーション圧縮と残留圧縮の間の利用可能な帯域幅の割り当てです。 一部のシーンではモーション圧縮がより重要ですが、その他のシーンでは残差圧縮が最大のゲインを提供します。 それらの間の最適な妥協点は、フレームごとに異なります。
従来のアルゴリズムは、両方のプロセスを別々に処理します。 これは、どちらかに利点を与えて妥協を見つける簡単な方法がないことを意味します。
著者は、両方の信号を同時に圧縮することでこれを回避し、フレームの複雑さに基づいて、2つの信号間に最も効率的な方法で帯域幅を割り当てる方法を決定します。
これらおよびその他の改善により、研究者は従来のコーデックをはるかに超える圧縮アルゴリズムを作成できました(以下のベンチマークを参照)。

ほぼ同じBPP値を持つ異なるコーデックで圧縮されたフラグメントの再構築の例は、WaveOneコーデックの大きな利点を示しています
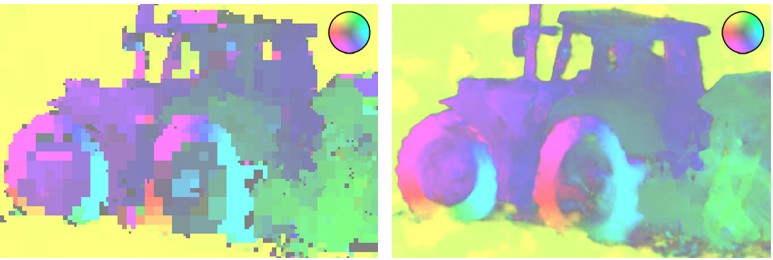
同じビットレートのH.265光ストリームカード(左)とWaveOneコーデック(右)
しかし、新しいアプローチにはいくつかの欠点がないわけではない、とMIT Technology Reviewは 指摘しています 。 おそらく主な欠点は、計算効率が低いこと、つまり、ビデオのエンコードとデコードに必要な時間です。 Nvidia Tesla V100プラットフォームおよびVGAサイズのビデオでは、新しいデコーダーは1秒あたり約10フレームの平均速度で動作し、エンコーダーは1秒あたり約2フレームの速度で動作します。 このような速度をライブビデオブロードキャストで使用することはまったく不可能であり、素材のオフラインエンコーディングでは、新しいエンコーダのスコープは非常に限られます。
さらに、デコーダーの速度は、通常のパソコンでこのコーデックで圧縮されたビデオを見るのにも十分ではありません。 つまり、これらのビデオを視聴するには、最低のSD品質であっても、いくつかのグラフィックアクセラレータを備えたコンピューティングクラスタ全体が現在必要です。 HD(1080p)品質でビデオを視聴するには、コンピューターファーム全体が必要です。
将来のグラフィックプロセッサの能力の向上と技術の向上が期待できます。「現在の速度はリアルタイムでの展開には十分ではありませんが、将来の作業では大幅に改善する必要があります」と書いています。
ベンチマーク
HEVC/H.265, AVC/H.264, VP9 HEVC HM 16.0 . Ffmpeg, — . , . , B- H.264/5
bframes=0
,
-auto-alt-ref 0 -lag-in-frames 0
. MS-SSIM, ,
-ssim
.
SD HD, . SD- VGA e Consumer Digital Video Library (CDVL). 34 15 650 . HD Xiph 1080p: 22 11 680 . 1080p 1024 ( , 32 ).
:
- MS-SSIM ;
- MS-SSIM ;
- WaveOne ( ).
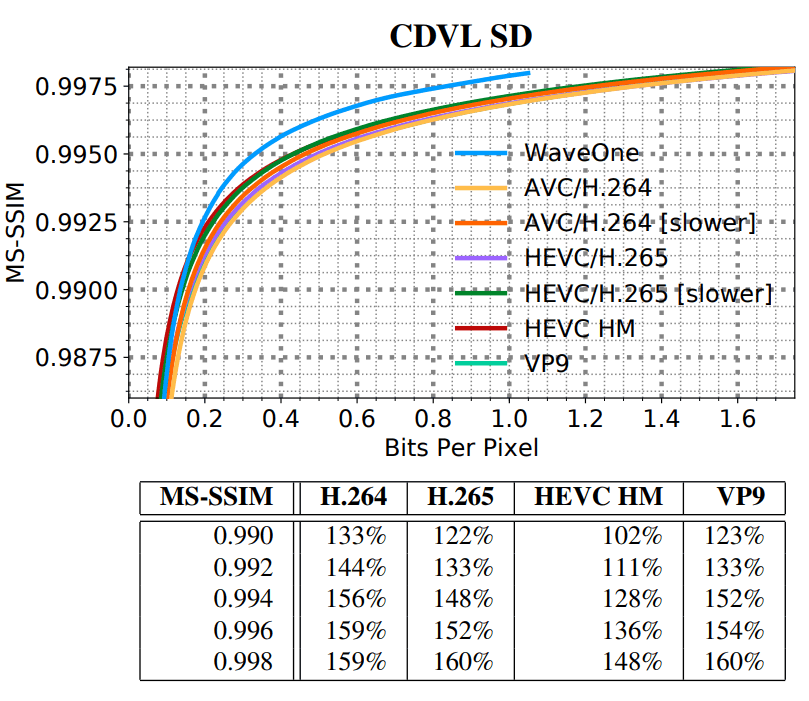
(SD)
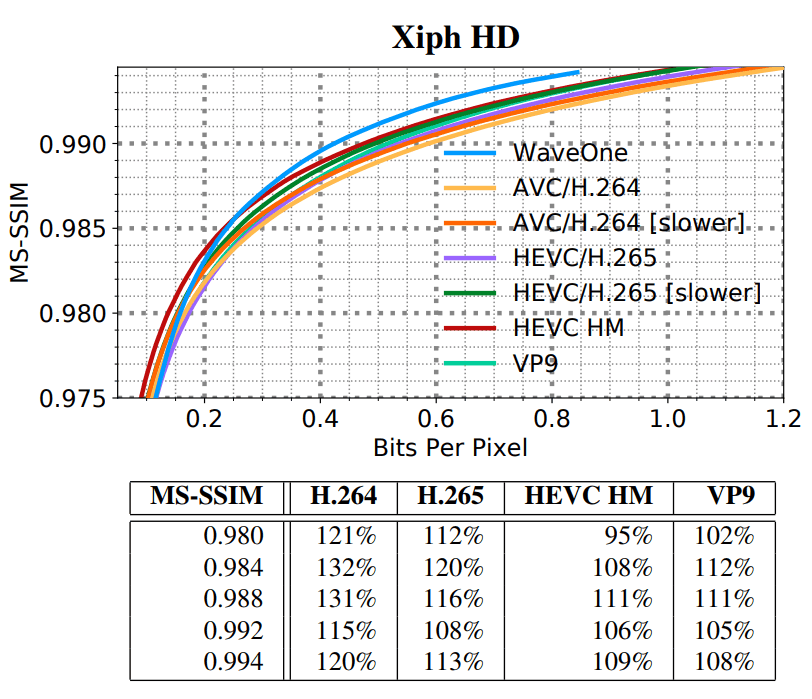
(HD)
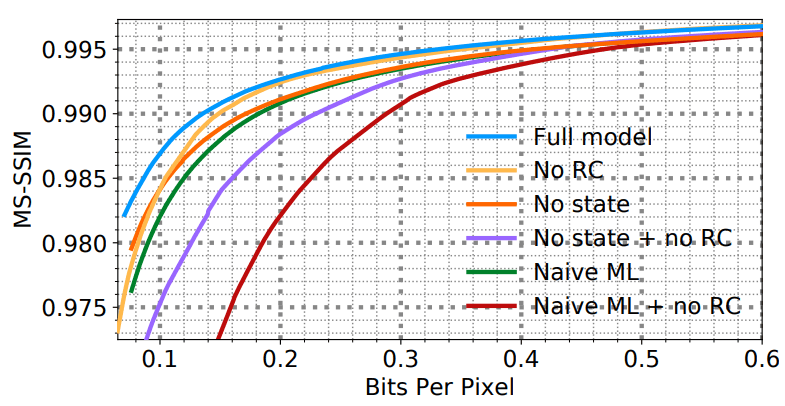
WaveOne
. , . . , . G. Toderici, S. M. O’Malley, S. J. Hwang, D. Vincent, D. Minnen, S. Baluja, M. Covell, R. Sukthankar. Variable rate image compression with recurrent neural networks, 2015; G. Toderici, D. Vincent, N. Johnston, S. J. Hwang, D. Minnen, J. Shor, M. Covell. Full resolution image compression with recurrent neural networks, 2016; J. Balle, V. Laparra, E. P. Simoncelli. End-to-end optimized image compression, 2016; N. Johnston, D. Vincent, D. Minnen, M. Covell, S. Singh, T. Chinen, S. J. Hwang, J. Shor, G. Toderici. Improved lossy image compression with priming and spatially adaptive bit rates for recurrent networks, 2017 . , , .
ML- , . . . C.-Y. Wu, N. Singhal, and P. Krahenbuhl. Video compression through image interpolation, ECCV (2018). , . AVC/H.264. , .
« » 16 2018 arXiv.org (arXiv:1811.06981). — (Oren Rippel), (Sanjay Nair), (Carissa Lew), (Steve Branson), (Alexander G. Anderson), (Lubomir Bourdev).
Stas911:
Altaisky: . ?
Stas911: . .