挑戦する
この記事では、小切手およびショッピングアシスタントの会計費用の申請で、領収書から商品名を分類するソリューションを作成した方法について説明します。 スキャンされた領収書に基づいて自動的に収集された購入に関する統計を表示する、つまり、ユーザーが購入したすべての商品をカテゴリ別に配布する機会をユーザーに提供したかったのです。 ユーザーに製品を個別にグループ化するように強制するのは、すでに前世紀です。 この問題を解決するには、いくつかのアプローチがあります。単語のベクトル表現や古典的な分類アルゴリズムのさまざまな方法でクラスタリングアルゴリズムを適用しようとすることができます。 新しいものは何も発明していません。この記事では、問題の可能な解決策、これを行わない方法の例、他の方法が機能しなかった理由の分析、プロセスで発生する可能性のある問題についての小さなガイドを共有したいと思います。
クラスタリング
問題の1つは、小切手から得られる商品の名前が、たとえ人であっても、必ずしも簡単に解読できるとは限らないことでした。 ロシアの店舗で「UTRUSTA krnsht」という名前の商品がどのように購入されたかを知ることはまずありません。 スウェーデンのデザインの真の愛好家は、すぐに私たちに答えます:Utrustのオーブン用ブラケット、しかしそのような専門家を本部に置くことは非常に高価です。 さらに、データに適した既製のラベル付きサンプルがなく、その上でモデルをトレーニングできました。 したがって、最初に、トレーニング用のデータがない場合にクラスタリングアルゴリズムを適用した方法と、それが好きではなかった理由について説明します。
同様のアルゴリズムは、オブジェクト間の距離の測定に基づいています。これには、ベクトル表現または単語の類似性を測定するメトリックの使用(レーベンシュタイン距離など)が必要です。 このステップでの難点は、名前の意味のあるベクトル表現にあります。 製品および他の製品との関係を完全かつ包括的に説明する名前のプロパティから抽出するのは問題です。
最も単純なオプションはTf-Idfを使用することですが、この場合、ベクトル空間の次元は非常に大きく、空間自体は疎です。 さらに、このアプローチでは、名前から追加情報を抽出しません。 したがって、1つのクラスターには、たとえば「ポテト」や「サラダ」などの一般的な単語で結合された、さまざまなカテゴリの多くの製品が存在する可能性があります。

また、どのクラスターを組み立てるかを制御することもできません。 示すことができる唯一のことは、クラスターの数です(空間内の非密度ピークに基づくアルゴリズムが使用されている場合)。 ただし、指定する数量が少なすぎると、1つの巨大なクラスターが形成され、他のクラスターに収まらないすべての名前が含まれます。 十分に大きいものを指定した場合、アルゴリズムが機能した後、数百のクラスターを調べて、それらを手作業でセマンティックカテゴリに結合する必要があります。
以下の表は、ベクトル表現にKMeansおよびTf-Idfアルゴリズムを使用したクラスターに関する情報を提供します。 これらの表から、クラスターの中心間の距離は、オブジェクトとそれらが属するクラスターの中心間の平均距離よりも短いことがわかります。 このようなデータは、ベクトルの空間に明らかな密度ピークがなく、クラスターの中心が円上にあり、ほとんどのオブジェクトがこの円の外側にあるという事実によって説明できます。 さらに、ほとんどのベクターを含む1つのクラスターが形成されます。 このクラスターで最も可能性が高いのは、さまざまなカテゴリのすべての製品の中で他の単語よりも頻繁に見つかる単語を含む名前です。
| クラスター | C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 |
|---|---|---|---|---|---|---|---|---|---|
| C1 | 0.0 | 0.502 | 0.354 | 0.475 | 0.481 | 0.527 | 0.498 | 0.501 | 0.524 |
| C2 | 0.502 | 0.0 | 0.614 | 0.685 | 0.696 | 0.728 | 0.706 | 0.709 | 0.725 |
| C3 | 0.354 | 0.614 | 0.0 | 0.590 | 0.597 | 0.635 | 0.610 | 0.613 | 0.632 |
| C4 | 0.475 | 0.685 | 0.590 | 0.0 | 0.673 | 0.709 | 0.683 | 0.687 | 0.699 |
| C5 | 0.481 | 0.696 | 0.597 | 0.673 | 0.0 | 0.715 | 0.692 | 0.694 | 0.711 |
| C6 | 0.527 | 0.727 | 0.635 | 0.709 | 0.715 | 0.0 | 0.726 | 0.728 | 0.741 |
| C7 | 0.498 | 0.706 | 0.610 | 0.683 | 0.692 | 0.725 | 0.0 | 0.707 | 0.714 |
| C8 | 0.501 | 0.709 | 0.612 | 0.687 | 0.694 | 0.728 | 0.707 | 0.0 | 0.725 |
| C9 | 0.524 | 0.725 | 0.632 | 0.699 | 0.711 | 0.741 | 0.714 | 0.725 | 0.0 |
| クラスター | オブジェクトの数 | 平均距離 | 最小距離 | 最大距離 |
|---|---|---|---|---|
| C1 | 62530 | 0.999 | 0.041 | 1.001 |
| C2 | 2159 | 0.864 | 0.527 | 0.964 |
| C3 | 1099 | 0.934 | 0.756 | 0.993 |
| C4 | 1292 | 0.879 | 0.733 | 0.980 |
| C5 | 746 | 0.875 | 0.731 | 0.965 |
| C6 | 2451 | 0.847 | 0.719 | 0.994 |
| C7 | 1133 | 0.866 | 0.724 | 0.986 |
| C8 | 876 | 0.863 | 0.704 | 0.999 |
| C9 | 1879 | 0.849 | 0.526 | 0.981 |
しかし、たとえば下の画像のように、クラスターはかなりまともな場所もあります。ほとんどすべての商品がキャットフードです。

Doc2Vecは、ベクトル形式でテキストを表すことができるもう1つのアルゴリズムです。 このアプローチを使用すると、各名前はTf-Idfを使用するよりも小さな次元のベクトルで記述されます。 結果のベクトル空間では、類似したテキストは互いに近く、異なるテキストは遠くにあります。
このアプローチは、Tf-Idf法によって得られる大きな次元と放電空間の問題を解決できます。 このアルゴリズムでは、トークン化の最も単純なオプションを使用しました。名前を別の単語に分割し、それらの初期形式を取りました。 彼はこの方法でデータのトレーニングを受けました:
max_epochs = 100 vec_size = 20 alpha = 0.025 model = doc2vec.Doc2Vec(vector_size=vec_size, alpha=alpha, min_alpha=0.00025, min_count=1, dm =1) model.build_vocab(train_corpus) for epoch in range(max_epochs): print('iteration {0}'.format(epoch)) model.train(train_corpus, total_examples=model.corpus_count, epochs=model.iter) # decrease the learning rate model.alpha -= 0.0002 # fix the learning rate, no decay model.min_alpha = model.epochs
しかし、このアプローチでは、名前に関する情報を持たないベクターが得られました-同じ成功で、ランダムな値を使用できます。 アルゴリズムの操作の一例を次に示します。画像は、「n pn 0.45k形式のボロジノパン」によるアルゴリズムに類似した製品を示しています。

おそらく問題は、名前の長さとコンテキストです:名前のパス「__ club。Banana 200ml」は、ヨーグルト、ジュース、または大きなクリーム缶のいずれかです。 名前のトークン化に別のアプローチを使用すると、より良い結果を得ることができます。 この方法を使用した経験はなく、最初の試行が失敗するまでに、製品名の付いたマーク付きセットが既にいくつか見つかっていたため、この方法をしばらくそのままにして、分類アルゴリズムに切り替えることにしました。
分類
データの前処理
小切手からの商品の名前は、必ずしも明確な方法ではありません。ラテン語とキリル文字は言葉で混ざり合っています。 たとえば、文字 "a"はラテン語 "a"に置き換えることができ、これにより一意の名前の数が増えます。たとえば、単語 "milk"と "milk"は異なると見なされます。 名前には、他にも多くのタイプミスや略語があります。
データベースを調べたところ、名前に典型的なエラーが見つかりました。 この段階で、正規表現を使用せずに、名前を整理して特定の一般的なビューを表示しました。 このアプローチを使用すると、結果は約7%増加します。 ツイスターパラメーターを使用したフーバー損失関数に基づく単純なSGD Classifierオプションと合わせて、F1の精度は81%(すべての製品カテゴリーの平均精度)になりました。
sgd_model = SGDClassifier() parameters_sgd = { 'max_iter':[100], 'loss':['modified_huber'], 'class_weight':['balanced'], 'penalty':['l2'], 'alpha':[0.0001] } sgd_cv = GridSearchCV(sgd_model, parameters_sgd,n_jobs=-1) sgd_cv.fit(tf_idf_data, prod_cat) sgd_cv.best_score_, sgd_cv.best_params_
また、人々の一部のカテゴリは他のカテゴリよりも頻繁に購入することを忘れないでください。たとえば、「お茶とお菓子」と「野菜と果物」は「サービス」と「化粧品」よりもはるかに人気があります。 このようなデータの分布では、各クラスの重み(重要度)を設定できるアルゴリズムを使用することをお勧めします。 クラスの重みは、クラス内の製品の数と製品の合計数の比に等しい値で逆に決定できます。 ただし、これらのアルゴリズムの実装では、カテゴリの重みを自動的に決定することができるため、考える必要はありません。
トレーニング用の新しいデータを取得する
私たちのアプリケーションは、競技会で使用されたものとはわずかに異なるカテゴリーを必要とし、データベースからの製品の名前は、コンテストで提示されたものとは著しく異なっていました。 したがって、領収書から商品をマークする必要がありました。 私たちはこれを自分でやろうとしましたが、チーム全体をつなげても非常に長い時間がかかることに気付きました。 そのため、Yandexの「Toloka」を使用することにしました。
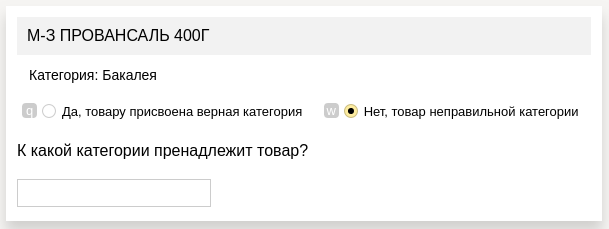
そこで、この形式の割り当てを使用しました。
- 各セルで製品を提示しました。製品のカテゴリを定義する必要があります
- 以前のモデルの1つによって定義された仮想カテゴリ
- 応答フィールド(提案されたカテゴリが正しくなかった場合)
各カテゴリの機能を説明する例とともに詳細な手順を作成し、品質管理方法も使用しました:通常のタスクと一緒に表示される標準的な回答のセット(標準的な回答を自分で実装し、数百の製品をマークアップしました)。 これらのタスクに対する回答の結果によれば、データを誤ってマークアップしたユーザーは除外されました。 ただし、プロジェクト全体では、600人以上のユーザーのうち3人のみを禁止しました。
新しいデータにより、データにより適したモデルが得られ、精度がわずかに(約11%向上)、すでに92%が得られました。
最終モデル
Kaggleのいくつかのデータセットからのデータの組み合わせで分類プロセスを開始しました-74%、その後、前処理を改善-81%、新しいデータセットを収集-92%、最後に分類プロセスを改善:最初に、ロジスティック回帰を使用して、商品の予備確率を取得SGDは、製品名に基づいてカテゴリの精度を高めましたが、損失関数に大きな値が残っていたため、最終的な分類器の結果に悪影響がありました。 さらに、取得したデータを製品の他のデータ(製品の価格、購入した店舗、店舗の統計、チェックおよびその他のメタ情報)と組み合わせ、XGBoostはこのすべてのデータ量でトレーニングされ、98%の精度が得られました(増加さらに6%)。 判明したように、トレーニングサンプルの品質が最大の貢献をしました。
サーバーで実行中
展開を高速化するために、Flaskの単純なサーバーをDockerに上げました。 サーバーから商品を受け取り、既にカテゴリに分類して商品を返品する必要がある商品を受け取りました。 そのため、Tomcatを中心とした既存のシステムに簡単に統合できました。アーキテクチャを変更する必要はありませんでした。もう1ブロック追加するだけです。
発売日
数週間前に、Google Playに分類されたリリースを投稿しました(しばらくするとApp Storeに表示されます)。 次のようになりました。
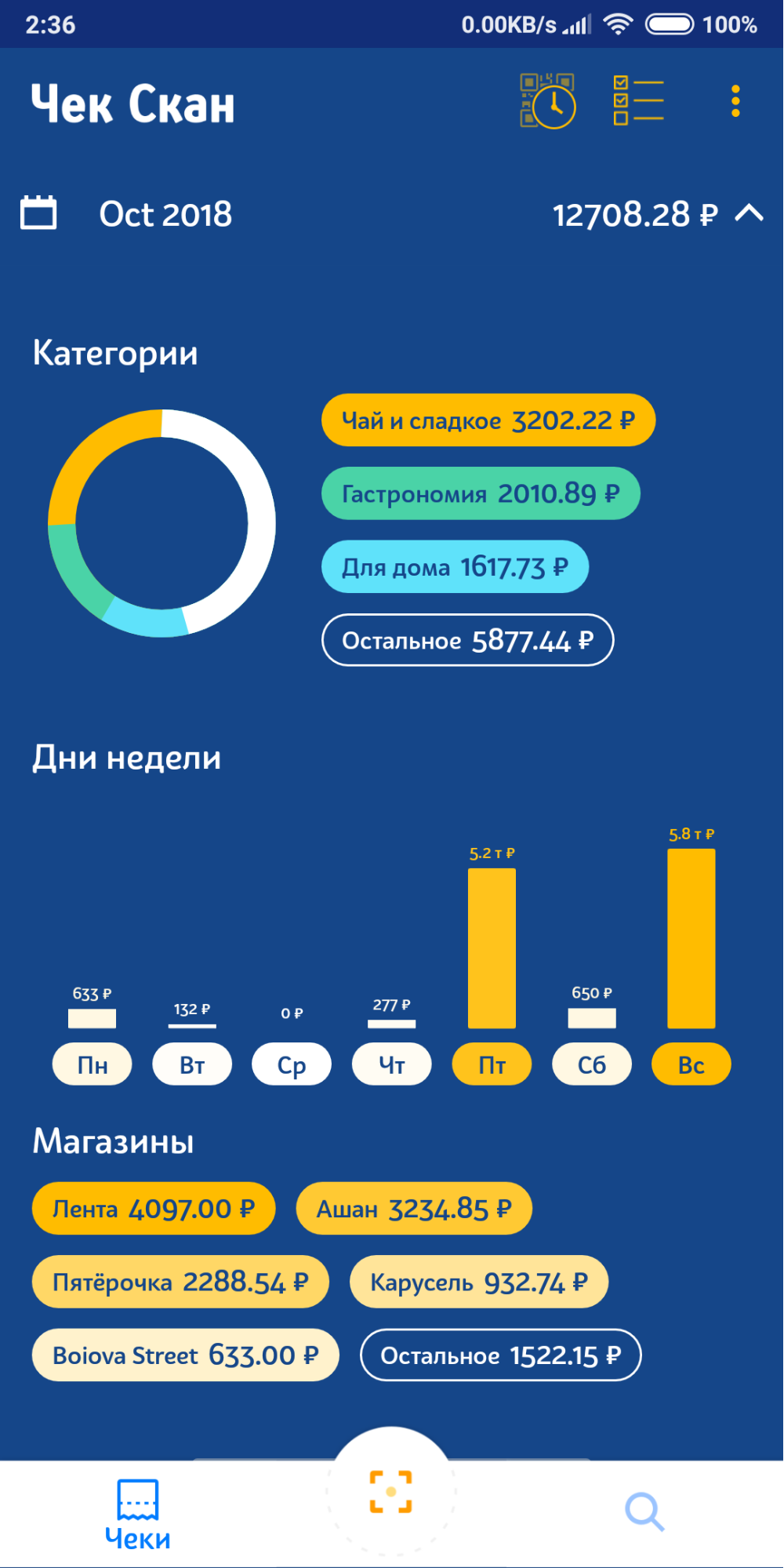
将来のリリースでは、カテゴリを修正する機能を追加する予定です。これにより、カテゴリ化エラーを迅速に収集し、カテゴリ化モデルを(自分自身で)再トレーニングできるようになります。
Kaggleで言及されたコンテスト:
www.kaggle.com/c/receipt-categorisation
www.kaggle.com/c/market-basket-analysis
www.kaggle.com/c/prod-price-prediction