学習曲線
28バイアスと散布の診断:学習曲線
エラーを回避可能なバイアスと散布に分割するいくつかのアプローチを検討しました。 これを行うには、エラーの最適な割合を評価し、アルゴリズムのトレーニングサンプルと検証サンプルでエラーを計算しました。 より有益なアプローチ、つまり曲線グラフの学習について説明しましょう。
学習曲線のグラフは、トレーニングサンプルの例の数に対する誤差の割合の依存関係です。
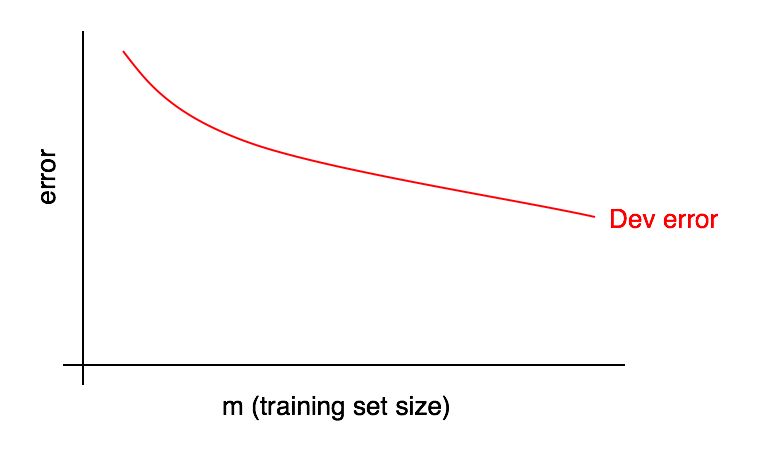
トレーニングサンプルのサイズが大きくなると、検証サンプルのエラーが減少します。
多くの場合、最終的にアルゴリズムに到達することを期待する「エラーの望ましい共有」に焦点を当てます。 例:
- 人間がアクセスできる品質のレベルを達成したい場合、ヒューマンエラーの割合は「エラーの望ましい割合」になるはずです。
- 学習アルゴリズムが一部の製品(猫画像プロバイダーなど)で使用されている場合、ユーザーが最大限の利益を得るために、どのレベルの品質を達成する必要があるかを理解している場合があります
- 重要なアプリケーションに長い間取り組んでいる場合、次の四半期/年にどのような進歩を遂げられるかについて合理的な理解があるかもしれません。
希望する品質レベルを学習曲線に追加します。

検証サンプルの赤いエラーカーブを視覚的に推定し、さらにデータを追加することで希望の品質レベルにどれだけ近づけることができるかを推測できます。 写真に示されている例では、トレーニングサンプルのサイズを2倍にすると、目的のレベルの品質が得られる可能性があります。
ただし、検証サンプルの誤差の割合の曲線がプラトーに達した場合(つまり、横軸に平行な直線になった場合)、追加のデータを追加しても目標の達成に役立たないことがすぐに示されます:
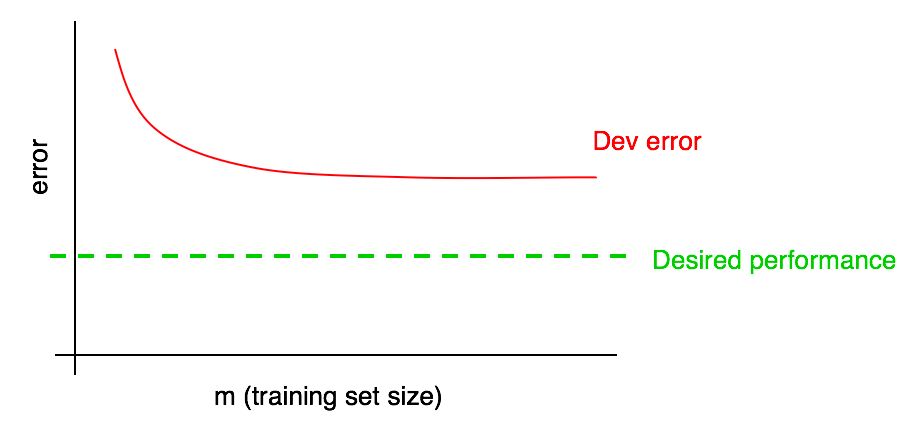
したがって、学習曲線を見ると、追加しても効果がないことを理解するためだけに、2倍のトレーニングデータを収集するという無駄な月を避けることができます。
このアプローチの欠点の1つは、検証サンプルのエラーカーブだけを見ると、データを追加した場合に赤いカーブがどのように動作するかを外挿して正確に予測することが困難な場合があることです。 したがって、エラーの割合に対する追加のトレーニングデータの影響を評価するのに役立つ別の追加のグラフ、学習エラーがあります。
29トレーニングエラーグラフ
検証(およびテスト)サンプルのエラーは、トレーニングサンプルが増加するにつれて減少するはずです。 しかし、トレーニングサンプルでは、通常、データを追加する際のエラーが大きくなります。
この効果を例で説明しましょう。 トレーニングサンプルが2つの例のみで構成されているとします。1枚は猫の写真、もう1枚は猫の写真ではありません。 この場合、学習アルゴリズムは、トレーニングサンプルの両方の例を簡単に記憶し、トレーニングサンプルで0%のエラーを示すことができます。 両方のトレーニング例のラベルが間違っていても、アルゴリズムはクラスを簡単に記憶します。
ここで、トレーニングセットが100の例で構成されているとします。 特定の数の例が誤って分類されているか、人が画像に猫がいるかどうかを判断できない場合、一部の例、たとえばぼやけた画像ではクラスを確立できないと仮定します。 学習アルゴリズムがまだほとんどのトレーニングサンプル例を「記憶」していると仮定しますが、今では100%の精度を得ることがより困難になっています。 トレーニングサンプルを2から100の例に増やすと、トレーニングサンプルのアルゴリズムの精度が徐々に低下することがわかります。
最後に、トレーニングセットが10,000の例で構成されているとします。 この場合、特にトレーニングセットにぼやけた画像と分類エラーが含まれている場合、アルゴリズムがすべての例を理想的に分類することがますます難しくなります。 したがって、このようなトレーニングサンプルでは、アルゴリズムの動作が悪くなります。
学習エラーグラフを以前のものに追加しましょう。
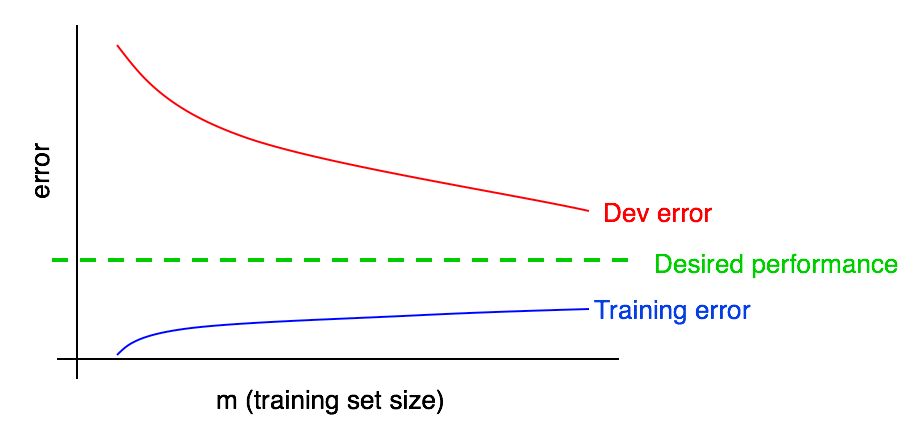
青の「学習エラー」曲線は、トレーニングサンプルが増えると大きくなることがわかります。 さらに、学習アルゴリズムは通常、検証サンプルよりもトレーニングサンプルの方が優れた品質を示します。 したがって、検証サンプルの赤いエラー曲線は、トレーニングサンプルの青いエラー曲線よりも厳密に上にあります。
次に、これらのグラフの解釈方法について説明します。
継続する