 「pi」の数値をカウントしないでください。
「pi」の数値をカウントしないでください。
「E」は無限に同じです。
そして、あなたが最後からそれらを書くならば、さらに何がありますか?
マーティン・ガードナー「チックタックトー」
この記事では、別のエピグラフを選択したかったのですが、あまりにも哀れなものでした。 次のリリースは再び遅れました。 この間に、なんとか転職できました! 新しい場所での仕事には多くのエネルギーが必要ですが、私の小さな趣味の時間を見つけ続けています。 そして、私は言わなければならない、私はプロセスで直面しなければならないことはますます困難になっています。 それについてお話します。 別のエピグラフから始めたいと思いましたが、これも悪くありません。
今回は、新しいマンカルと「 移行ゲーム 」がありました(これらはハルマと彼女の親relativeです)。 対戦相手の家を自分の駒の前に連れて行かなければならない一種のレース。 ピース( チェッカーのように)は飛び越えることができますが、キャプチャはありません。 私はあなたに何を説明していますか? 確かに、あなたの多くはあなたの子供時代にコーナーをプレイしました。
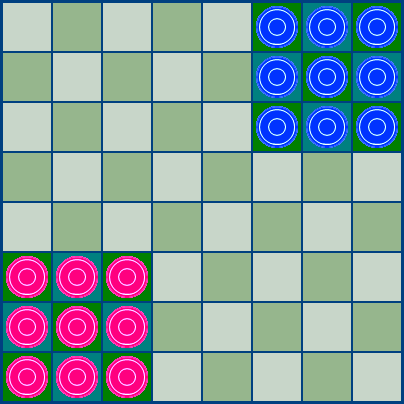
一見、ゲームはシンプルに見えますが、問題はすでにカーネルレベルで始まっています。 覚えておいて、私は複合的な動きについて話しましたか? 多くの理由から、それらを複合的なものとして表現する方が便利です-部分的な動きのシーケンスとしてではなく、単一の全体として。 これはAIにとってより便利であり、設計の観点から、複合的な動きの形での記述がより自然に見えるゲームがあります。 しかし、1つの問題があります。
チェッカーでは、複合移動を実行すると、ピースがボードから削除されます(おそらく移動の最後に)。 コーナーで-自分や相手の駒を無限に飛び越えることができます。 文字通り。 そして、ここでは拡張機能が保存されていません。なぜなら、移動リストを生成する段階でさえ、カーネル内ではすべてがそれらに到達することなく循環するからです。 このロジックを変更し、オプション( detect-loops )を実装する必要がありました。これは事前に検討する価値があります。
ボットでも簡単ではありませんでした
このゲームファミリの主な問題は、ボード上の状況を適切に表す評価関数を選択するのがそれほど簡単ではないことです。 ゲームの目的は対戦相手の「ホーム」に到達することなので、すべてのピースからターゲットフィールド( マンハッタンまたはユークリッド -差なし)までの合計距離を推定することは可能ですが、ハルムでは、成功した状況下でピースは一度にボード全体をジャンプできます。少し与えます。
ターゲットフィールドでは、すべてが明確ではありません。 すべての図を同じフィールドに送ることはできません。 すぐそこに彼に到達し、それを取る最初の図。 各図の最適なターゲットフィールドを決定し、それらに移動することが理想的ですが、これは計算の観点からは困難です。 さらに、ボード上の状況は移動ごとに変わります。 一般的に、私はずっと先を見て、純粋に発見的なアルゴリズムに自分自身を制限することを決めました。
理想的なソリューションではありませんが、そもそもそれは非常に効果的です。 ボットが敵の「家」に「飛び込む」ことができる動きを見つけた場合、彼はそれを選択します。 それ以外の場合は、輻輳を回避しようとして、ターゲットまでの距離を徐々に短くします。 最も悲しい状況は、1人のプレイヤーが(偶然または意図的に)自分の作品を「家」に置き、もう1人が2列の作品で「ロック」した場合に起こります。
念のために、敵の「ロック」の動きを禁止します(多くの動きを先読みする必要がなければ、非常に複雑なヒューリスティックを許可できます)負の評価を設定します純粋に直交する動きを持つ古典的なハルマで顕著です)。 一般に、このボットには成長の余地があります。
ピースの受け取りが許可されているゲームでは、さらに複雑です。 そして、そのようなゲームはたくさんあります! おそらく最も有名なのは、1930年にジョージパーカーによって発明されたキャメロットです。 しかし個人的には、同じメカニズムに基づいて構築されたあまり知られていないゲームが好きです。
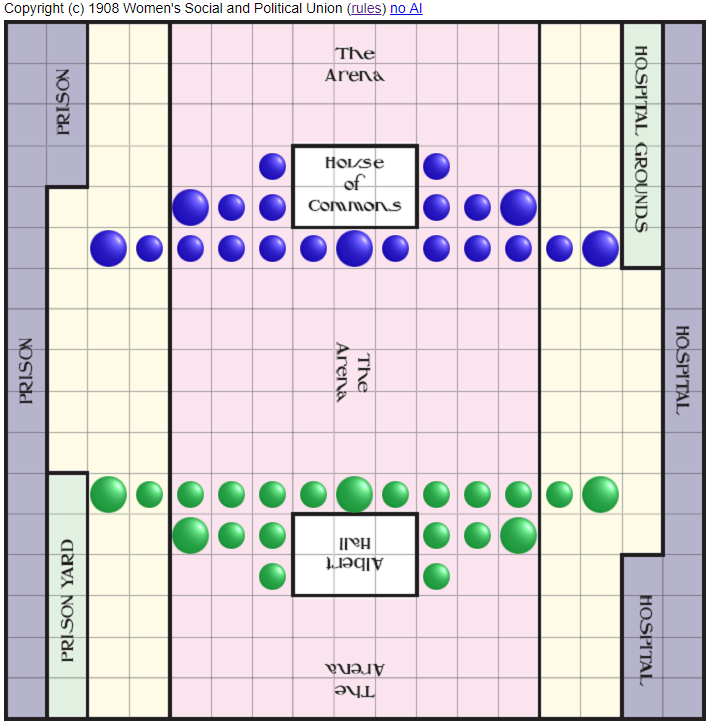
このゲームは物語そのものです! 1908年に、参政権者は政治的見解を前進させるためにそれを思いついた。 下院、 アルバートホール 、市刑務所、病院など、すべてがここにあります。 警官と戦う女性参政権者 。 彼らの目標は、6人の人々を下院に連れて行くことです。 彼らは本部のアルバートホールに入ることができません。 シェイプは任意の方向に移動します。 友好的で敵の駒を飛び越えることも許可されています。
ただし、一連のジャンプは任意に長くすることができます。 事件が「アリーナ」で行われた場合、敵のフィギュアは、飛び越えたときに切り倒され、刑務所または病院に送られます。 通常の人物は、斜め(斜め)にのみカットされます(巡査と参政権の指導者)。あらゆる方向に。 刑務所と病院で6人の人物が募集された場合、ゲームに再び参加することで「交換」できます。 したがって、 将Shoや柱のような作品は決してゲームから離れません。
ターゲットフィールドでは、すべてが明確ではありません。 すべての図を同じフィールドに送ることはできません。 すぐそこに彼に到達し、それを取る最初の図。 各図の最適なターゲットフィールドを決定し、それらに移動することが理想的ですが、これは計算の観点からは困難です。 さらに、ボード上の状況は移動ごとに変わります。 一般的に、私はずっと先を見て、純粋に発見的なアルゴリズムに自分自身を制限することを決めました。
ストローク品質のこのような評価で
Dagaz.AI.heuristic = function(ai, design, board, move) { var t = getTargets(design, board, board.player); var m = getMove(move); var r = 1; if (m !== null) { if (!design.inZone(0, board.player, m.start)) { if (_.indexOf(t.first, m.end) >= 0) { r = 1000 + getDistance(t.first, m.start) - getDistance(t.first, m.end); } if (_.indexOf(t.goal, m.end) >= 0) { r = 700 + getDistance(t.first, m.start) - getDistance(t.first, m.end); } if ((r == 1) && (_.indexOf(t.second, m.end) >= 0)) { r = 500 - getDistance(t.second, m.end); } } if (r == 1) { if (design.inZone(2, board.player, m.end) && !design.inZone(2, board.player, m.start)) { r = 300; } } if (bestFound(design, board, 300)) return -1; if (r == 1) { var goals = getGoals(design, board, board.player); if (!_.isUndefined(goals[m.start])) { var goal = goals[m.start]; if (m.next == goal.next) { r = 100 + distance(goal.end, m.start) - distance(goal.end, m.end); } } } if (notBest(design, board, r)) return -1; var b = board.apply(move); if (isRestricted(design, b, board.player)) return -1; } return r; }
理想的なソリューションではありませんが、そもそもそれは非常に効果的です。 ボットが敵の「家」に「飛び込む」ことができる動きを見つけた場合、彼はそれを選択します。 それ以外の場合は、輻輳を回避しようとして、ターゲットまでの距離を徐々に短くします。 最も悲しい状況は、1人のプレイヤーが(偶然または意図的に)自分の作品を「家」に置き、もう1人が2列の作品で「ロック」した場合に起こります。
もちろん、そのような状況の可能性は非常に低いです。
ニューヨークのゲームの発明者兼コレクターであるシドニー・サクソンが提案したルールのおかげです。 彼の提案は次のとおりです。ピースが「ホーム」を離れる能力を持っている場合、相手のピースをジャンプするか、そのような動きから始まる一連のジャンプによって、そうする必要があります。 独自の「家」に数字をロックする可能性を除いて、さまざまなバージョンのルールを試してみたところ、シドニーサクソンのルールが最も成功していることがわかりました。 彼の「家」を出た後、作品はもはやそこに戻ることができません(ただし、移動を完了する過程で通過する権利があります)。
念のために、敵の「ロック」の動きを禁止します(多くの動きを先読みする必要がなければ、非常に複雑なヒューリスティックを許可できます)負の評価を設定します純粋に直交する動きを持つ古典的なハルマで顕著です)。 一般に、このボットには成長の余地があります。
ピースの受け取りが許可されているゲームでは、さらに複雑です。 そして、そのようなゲームはたくさんあります! おそらく最も有名なのは、1930年にジョージパーカーによって発明されたキャメロットです。 しかし個人的には、同じメカニズムに基づいて構築されたあまり知られていないゲームが好きです。
このゲームは物語そのものです! 1908年に、参政権者は政治的見解を前進させるためにそれを思いついた。 下院、 アルバートホール 、市刑務所、病院など、すべてがここにあります。 警官と戦う女性参政権者 。 彼らの目標は、6人の人々を下院に連れて行くことです。 彼らは本部のアルバートホールに入ることができません。 シェイプは任意の方向に移動します。 友好的で敵の駒を飛び越えることも許可されています。
ただし、一連のジャンプは任意に長くすることができます。 事件が「アリーナ」で行われた場合、敵のフィギュアは、飛び越えたときに切り倒され、刑務所または病院に送られます。 通常の人物は、斜め(斜め)にのみカットされます(巡査と参政権の指導者)。あらゆる方向に。 刑務所と病院で6人の人物が募集された場合、ゲームに再び参加することで「交換」できます。 したがって、 将Shoや柱のような作品は決してゲームから離れません。
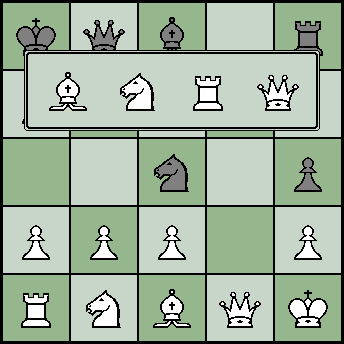
一般に、このリリース全体は、このようなオプションのトピックにのみ基づいています。 例えば、私はチェスの駒の正しい変形をようやく習得しました(今までは、すべてのポーンがクイーンにしかなりませんでしたが、これは一般的に間違っています)。 私はこれをあまり気にせず、キャンバス上に選択ダイアログを描きました。 それはかなりうまくいきました(マットから手を区別できるように手を離せたら、一般的には素晴らしいことでした)。
もう1つの「核」改良点は、ユーザーインターフェイスの改善に関連しており、独自の背景があります。 プロジェクトには、URLを介して現在の位置を渡すことで現在の位置をエンコードできるメカニズムがかなり前からあります。 この形式のすべてのゲームの状態の説明がログに書き込まれることを考慮すると、デバッグに非常に役立ちます。 それは、ブラウザのログについて何も知らないユーザーであり、ほとんど役に立ちません。
いや、いや、これはすべて良いことではありません!
多くのゲームがあり、そのゲームプレイは多くの(おそらく異種の)ステージで構成されています。 例として、2008年の人気ゲームである上佐渡を引用できます。 このゲームの各ステージ(最後の水平に数字の1つを渡す前)は比較的短いですが、完了するとゲームは続行します。 プレイヤーは、合意されたルールに従って、最初の行でピースを再配置し、対戦相手(前のステージで勝利をもたらした人物が新しい能力を獲得する)の前に最後の水平に到達しようとします。

「 プログレッシブレベル 」オプションが自動化されるのは、ゲームのこの側面です。プレーヤーの1人が勝ったときに、ゲームの次のステージに自動的に移行します。 また、フィギュアの初期配置はステージごとに異なるため、 共通セットアップモジュールによって計算され、 URLを介してゲームの次のステージに渡されます 。

この機会と手をつなぐことも、最初の図の配置を多様化できる別の方法です。 「 セレクタ 」オプションを使用すると、単一のJSファイル内で複数の初期配置(およびボード構成)をエンコードできます 。 リバーシのホームページを更新すると、私が言っていることを理解できます。
「 プログレッシブレベル 」オプションが自動化されるのは、ゲームのこの側面です。プレーヤーの1人が勝ったときに、ゲームの次のステージに自動的に移行します。 また、フィギュアの初期配置はステージごとに異なるため、 共通セットアップモジュールによって計算され、 URLを介してゲームの次のステージに渡されます 。
この機会と手をつなぐことも、最初の図の配置を多様化できる別の方法です。 「 セレクタ 」オプションを使用すると、単一のJSファイル内で複数の初期配置(およびボード構成)をエンコードできます 。 リバーシのホームページを更新すると、私が言っていることを理解できます。
新しいプラグインは 、問題を解決するように設計されています。 構造的には、これは通常のツリーであり、ゲームセッションでこれまでに取り上げられたすべてのゲーム状態が保存されます(このツリーは将来、ゲームの全履歴をSGFファイルにアップロードできます)。 ユーザーは、画面の上部に表示されるボタンを使用して、これらの状態を「フリップ」することができます。
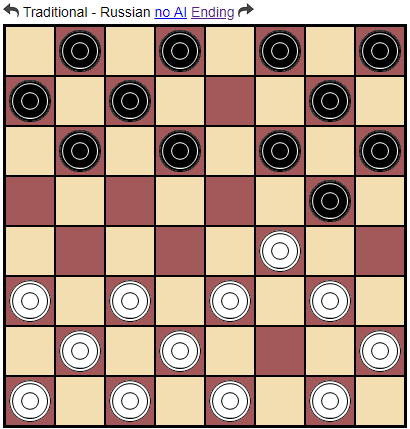
これは非常に便利ですが、上部の2つの矢印からさらに多くの利点を得ることができます。 これはまさに「 advisor-mode 」オプションの機能です。 ユーザーが指定された時間よりも長く考えている場合、彼がプレイするボットは、彼のためにコースを計算し、「セッションマネージャー」に新しいゲーム状態を入れます。 提案された移動は、「進む」ボタンを押すだけで受け入れられます。 移動が気に入らない場合は、いつでもロールバックできます。
開発プロセスでは、多くの喜びが音をもたらしました(それは、はるかに簡単です)。 最初の実装はあまりにも素朴でした。 これが何に関係しているのかわかりませんが、ゲームの途中で、ログにメッセージが表示されずにサウンドの再生が停止しました。 これは、作成したSoundオブジェクトをメモリにキャッシュし始めるまで、私が持っていたすべてのブラウザーで現れました。 しかし、その後、別のトラブルが発生しました。
音が長時間再生され、ボットが十分に速く考えた場合 (たとえばおとりなど)、その動きの音は単に「飲み込まれた」だけで、非常に不快に見えました。 ここで長い間シャーマンをしなければならなかったが、 松葉杖で終わった。 「クローン可能」フラグを設定しても、各プレーヤーに1つ(同じサウンドが失われた場合でも)サウンドのインスタンスをいくつか作成します。 もちろん、これはIEではまったく役に立ちませんでした。IEは(明らかに宗教上の理由で)「wav」ファイルと「ogg」ファイルの両方の処理を拒否しました。 私にとって、このブラウザは静かに動作します!
それ以外の場合、リリースは問題なく行われました。 Halmeとmankalamは、 チェスの ゲームで構成されていました。また、次のIl fogliaccio degli astrattiで読んだ将Shoの 非常に 多くの バリエーションと 、中国の同志の別の簡単なゲームで構成されていました。 そうそう、もう一つ別のものがあります。

短期記憶のほんの小さなシミュレーター。 同じ色の同じペア(クイーンとクイーン、キングとキングなど)を開く必要があります。 この点と、200回のクリックすべてに関するポイントが付与されます。 ボーナスはポイントに授与されるため(たとえば、赤と黒のスーツの交代に対して)、より良い記憶力を持っている人について友人と競うことができます。 がんばれ!
そして明けましておめでとうございます!