ごく最近、Highload ++カンファレンスは終了しました(主催者とオレグブニンのチーム全体に個人的に感謝します。とてもクールでした!)。
会議の前夜、Alexey fisherは会議で「ストーカー」のイニシアチブグループを作成することを提案しました。 レポートの間に、私たちは交換した小さなメモを書きました。 一部のメモは非常に詳細かつ詳細であることが判明しました。
ソーシャルネットワークのコミュニティはこの形式を積極的に評価したため、私は(許可を得て)最初のレポートの概要を公開することにしました。 この形式が興味深い場合は、さらにいくつかの記事を準備できます。

運転した
Avitoには多くのサービスがあり、それらの間には多くの接続があります。 これにより問題が発生します。
- リポジトリがたくさん。 どこでもコードを変更するのは難しい
- チームはコンテキストによって制限されます。 最大ではなくわずかに重複
- データの断片化が追加されます。
多数のインフラストラクチャ要素:
- ロギング
- 要求トレース(Jaeger)
- エラー集約(Sentry)
- Kubernetesからのステータス/メッセージ/イベント
- レース制限/サーキットブレーカー(Hystrix)
- サービス接続(Istio)
- モニタリング(Grafana)
- アセンブリー(Teamcity)
- コミュニケーション
- タスクトラッカー
- ドキュメント
- ...
レイヤーは多数あり、レポートでは1つのみ(PaaS)について説明しています。
プラットフォームには3つの主要部分があります。
- CLIによって制御されるジェネレーター
- ダッシュボードを介して制御されるアグリゲーター(コレクター)
- 特定のアクションのトリガーを備えたストレージ。
標準マイクロサービス開発パイプライン
CLI-push-> CI-> Bake-> Deploy-> Test-> Canary-> Production
CLIプッシュ
長い間、適切な開発者を指導していました。 それでも、それは弱点のままでした。
マイクロサービスの基盤を作成するのに役立つcliユーティリティにより自動化されます。
- テンプレートサービスを作成します(多くのPLのテンプレートがサポートされています)。
- ローカル開発用のインフラストラクチャを自動的に展開します
- データベースを接続します(構成は不要です。開発者はデータベースへのアクセスについては考えません)。
- ライブビルド
- ディスク生成の自動テスト。
構成はtomlファイルに記述されています。
サンプルファイル:
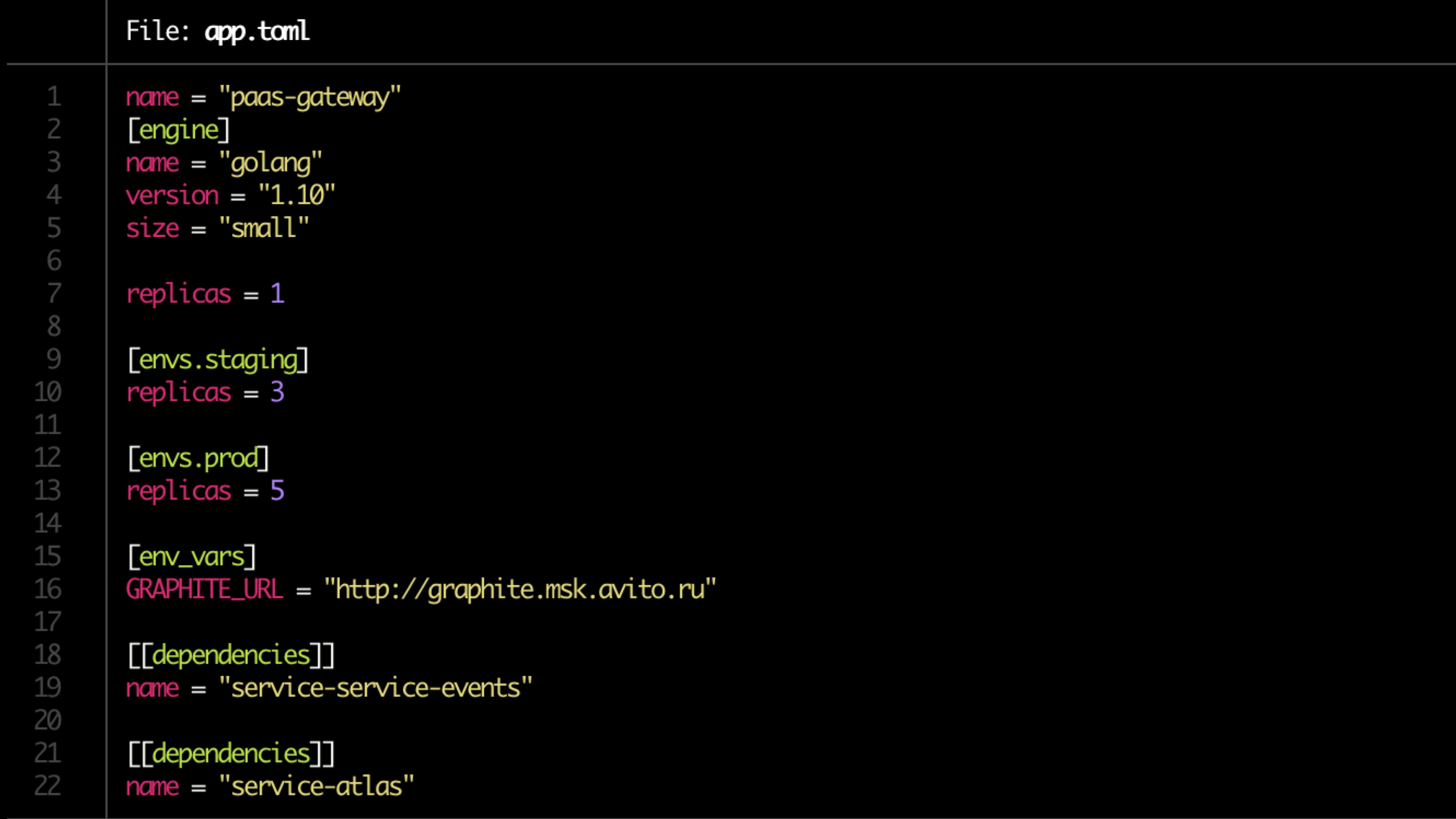
検証
基本的な検証チェック:
- Dockerfileの可用性
- app.toml
- ドキュメントの入手可能性
- 依存関係
- 監視のアラートルール(サービスの所有者が設定)
ドキュメント
誰もがドキュメントを持っているべきですが、ほとんど誰もそれを持っていません
ドキュメントには以下を含める必要があります。
- サービスの説明(短い)
- アーキテクチャ図へのリンク
- Runbook
- よくある質問
- エンドポイントAPIの説明
- ラベル(製品、機能、構造分割にバインド)
- サービスの所有者(複数の場合がありますが、ほとんどの場合、自動的に決定できます)。
ドキュメントを確認する必要があります。
パイプラインの準備
- 調理リポジトリ
- TeamCityでパイプラインを作成する
- 権利を設定します
- 所有者を探しています(2、1は信頼できません)
- Atlasにサービスを登録する(内部製品)
- 移行を確認します。
焼く
- Dockerイメージでのアプリケーションの構築。
- サービス自体および関連リソース(DB、キャッシュ)のヘルムチャートの生成
- 管理者がポートを開くためのチケットが作成され、メモリとCPUの制限が考慮されます。
- 単体テストを実行します。 コードカバレッジは維持されています。 一定以下の場合、展開は終了します。 カバレッジが進行しない場合、通知がプッシュされます。
所有者検索は、プッシュ(プッシュの数とそれらのコードの量)によって決定されます。
潜在的に危険な移行(変更)がある場合、トリガーはAtlasに登録され、サービスは隔離されます。
検疫は、所有者へのプッシュを通じて解決されます(手動モード?)
コンベンションチェック
私たちはチェックします:
- サービスエンドポイント
- スキームへの回答のコンプライアンス
- ログ形式
- ヘッダーの設定(バスに接続を追跡するためにバスにメッセージを送信するときのX-Source-IDを含む)
テスト
テストは閉ループ(たとえば、hoverfly.io)で実行されます-典型的な負荷が記録されます。 次に、閉ループでエミュレートされます。
リソース消費の対応がチェックされ(極端な場合を別に見て-リソースが少なすぎる/多すぎる)、rpsによってカットオフされます。
負荷テストでは、バージョン間のパフォーマンスデルタも示されます。
カナリアテスト
非常に少数のユーザー(<0.1%)で起動を開始します。
最小負荷5分。 メインの2時間。 その後、すべてが正常であれば、ユーザーのボリュームが増加します。
私たちは見ます:
- 製品メトリック(まず第一に)-それらの多くがあります(100500)
- セントリーエラー
- 応答ステータス、
- 回答者の時間-正確な平均応答時間
- 待ち時間
- 例外(処理済みおよび未処理)
- メトリック言語に固有(例:php-fpmワーカー)
スクイズテスト
押出試験。
実際のユーザー1インスタンスを障害点までロードします。 その天井を見ます。 次に、別のインスタンスを追加してロードします。 次の天井を見ます。 回帰を見てみましょう。 Atlasの負荷テストのデータを強化または置換します。
スケーリング
CPUのみが悪いので、製品メトリックを追加する必要があります。
最終的なスキーム:
- CPU + RAM
- リクエスト数
- 応答時間
- 過去の予測
スケーリングするときは、サービスの依存関係を見ることを忘れないでください。 スケーリングのカスケード(+1レベル)を思い出してください。 初期化サービスの履歴データを確認します。
オプショナル
- トリガー処理-X未満のバージョンが残っていない場合の移行
- サービスは長い間更新されていません
- 検疫
- 安全な更新
ダッシュボード
上からすべてを集約した形で見て、結論を導き出します。
- サービスとラベルのフィルタリング
- トレース、ロギング、モニタリングとの統合
- シングルポイントサービスのドキュメント
- すべてのサービスイベントの単一ポイント
例:
