私たちは機械学習コースの新しいストリームをオープンしましたので、近い将来、これに関連する記事、いわゆる規律を待ちます。 まあ、もちろん、公開セミナー。 次に、強化学習とは何かを見てみましょう。
強化学習は機械学習の重要な形態であり、エージェントはアクションを実行して結果を確認することにより、環境での行動を学習します。
近年、この魅力的な研究分野で多くの成功を収めています。 たとえば、2014年のDeepMindとDeep Q Learning Architecture 、2016年のAlphaGo 、2017年のOpenAIとPPOでのGoチャンピオンの勝利 。

DeepMind DQN
このシリーズの記事では、強化学習の問題を解決するために現在使用されているさまざまなアーキテクチャの研究に焦点を当てます。 これらには、Qラーニング、ディープQラーニング、ポリシーグラディエント、アクタークリティック、およびPPOが含まれます。
この記事では、次のことを学習します。
- 強化学習とは何か、報酬が中心的なアイデアである理由
- 3つの強化学習アプローチ
- 深層強化学習における「深い」とは
強化学習エージェントの実装に突入する前に、これらの側面を習得することは非常に重要です。
強化トレーニングのアイデアは、エージェントが環境と対話し、アクションを実行するための報酬を受け取ることで、環境から学習することです。

環境との相互作用を通して学ぶことは、私たちの自然な経験から来ています。 あなたが居間の子供だと想像してください。 暖炉が見えてそこに行きます。
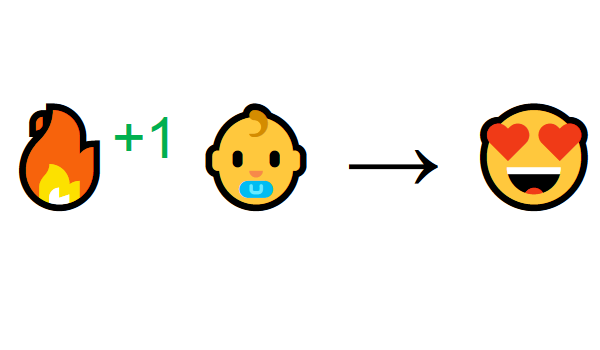
近くは暖かく、気分が良い(正の報酬+1)。 あなたは、火は前向きなものであることを理解しています。
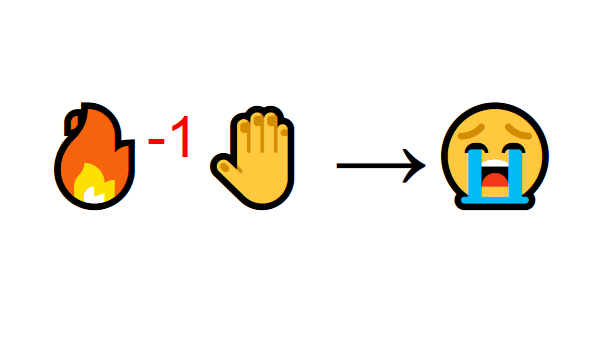
しかし、その後、火に触れようとします。 ああ! 彼は手を燃やした(負の報酬-1)。 火は熱を発するので十分な距離にいるとき、火はポジティブであることに気づきました。 しかし、彼に近づくと、やけどを負います。
これは、人々が相互作用を通じて学ぶ方法です。 強化学習は、アクションを通じて学習するための単純な計算アプローチです。
強化学習プロセス

例として、スーパーマリオブラザーズのプレイを学んでいるエージェントを想像してください。 強化学習(RL)プロセスは、次のように機能するサイクルとしてモデル化できます。
- エージェントは環境から状態S0を受け取ります(この場合、スーパーマリオブラザーズ(環境)からゲームの最初のフレーム(状態)を取得します)
- この状態S0に基づいて、エージェントはアクションA0を実行します(エージェントは右に移動します)
- 環境は新しい状態S1(新しいフレーム)に移行します
- 環境はR1エージェントに何らかの報酬を与えます(死んでいない:+1)
このRLサイクルは、一連の状態、アクション、および報酬を生成します。
エージェントの目標は、予想される累積報酬を最大化することです。
中央アイデア報酬仮説
予想される累積報酬を最大化するというエージェントの目標はなぜですか? まあ、強化学習は報酬仮説の考え方に基づいています。 予想される累積報酬を最大化することにより、すべての目標を説明できます。
したがって、強化トレーニングでは、最高の行動を達成するために、予想される累積報酬を最大化する必要があります。
各時間ステップtでの累積報酬は、次のように記述できます。

これは次と同等です:
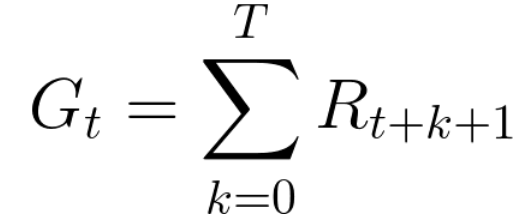
ただし、実際には、単にそのような報酬を追加することはできません。 より早く(ゲームの開始時に)到着する報酬は、将来の報酬よりも予測可能なため、より可能性が高くなります。

あなたのエージェントが小さなネズミで、あなたの対戦相手が猫だとします。 あなたの目標は、猫があなたを食べる前に最大量のチーズを食べることです。 図からわかるように、ネズミの近くのチーズよりも、ネズミのほうがチーズを食べる可能性が高くなります(近くにいるほど危険です)。
その結果、猫の報酬は、たとえそれが大きい(チーズが多い)場合でも減少します。 食べられるかどうかはわかりません。 報酬を減らすために、次のことを行います。
- ガンマと呼ばれる割引率を決定します。 0から1の間でなければなりません。
- ガンマが大きいほど、割引は低くなります。 これは、学習エージェントが長期的な報酬により関心があることを意味します。
- 一方、ガンマが小さいほど、割引は大きくなります。 これは、短期的な報酬(最も近いチーズ)が優先されることを意味します。
割引を考慮した累積予想対価は次のとおりです。
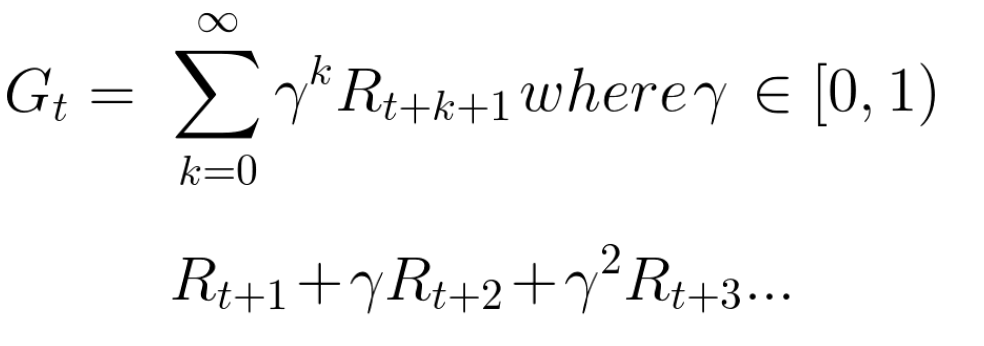
大まかに言えば、時間インジケータにガンマを使用することにより、各報酬が減少します。 時間ステップが増加するにつれて、猫は私たちに近づき、将来の報酬はますます少なくなります。
時折または継続的なタスク
タスクは、強化を伴う学習問題のインスタンスです。 一時的なタスクと連続的なタスクの2種類があります。
エピソードタスク
この場合、開始点と終了点(最終状態)があります。 これにより、エピソードが作成されます。状態、アクション、報酬、および新しい状態のリストです。
たとえば、スーパーマリオブラザーズを取り上げます。エピソードは新しいマリオの発売から始まり、殺されるかレベルの終わりに達すると終了します。

新しいエピソードの始まり
継続的なタスク
これらは永遠に(最終状態なしで)実行されるタスクです 。 この場合、エージェントは最適なアクションを選択すると同時に、環境と対話することを学習する必要があります。
たとえば、自動化された株式取引を実行するエージェント。 このタスクの開始点と終了状態はありません。 エージェントは、停止するまで作業を続けます。

モンテカルロ法と時間差法
学習する方法は2つあります。
- エピソードの最後に報酬を収集してから、予想される最大の報酬を計算する-モンテカルロアプローチ
- すべてのステップでの報酬の評価-一時的な違い
モンテカルロ
エピソードが終了すると(エージェントが「最終状態」に達すると)、エージェントは合計報酬を見て、自分がどれだけうまくいったかを確認します。 モンテカルロアプローチでは、報酬はゲームの終了時にのみ受け取られます。
次に、知識を増やして新しいゲームを開始します。 エージェントは、反復ごとに最適な決定を下します。
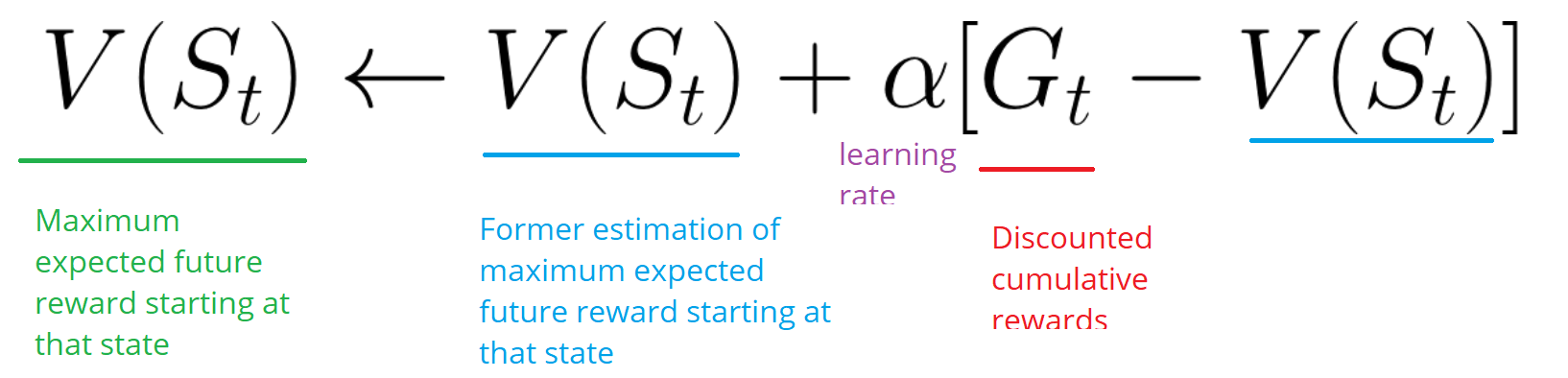
以下に例を示します。
環境として迷路をとる場合:
- 私たちは常に同じ出発点から始めます。
- 猫が私たちを食べるか、20歩以上移動すると、エピソードを停止します。
- エピソードの最後に、状態、アクション、報酬、および新しい状態のリストがあります。
- エージェントはGtの総報酬を要約します(Gtの成績を確認するため)。
- 次に、上記の式に従ってV(st)を更新します。
- その後、新しいゲームが新しい知識から始まります。
ますます多くのエピソードを実行して、 エージェントはより良くプレイすることを学びます。
時差:すべてのタイムステップで学習
時間差学習法は、可能な限り最大の報酬を更新するためにエピソードの終わりを待たないでしょう。 得られた経験に応じてVを更新します。
このメソッドは、TD(0)またはステップワイズTDと呼ばれます(シングルステップ後にユーティリティ関数を更新します)。

TDメソッドは、次のタイムステップで値が更新されることのみを想定しています。 時間t + 1 で、報酬Rt + 1と現在の評価V(St + 1)を使用してTDターゲットが形成されます。
TD目標は、予想される推定値です。実際、1ステップ以内に以前のV(St)評価を目標に更新します。
侵害の調査/運用
強化訓練問題を解決するためのさまざまな戦略を検討する前に、もう1つの非常に重要なトピックを検討する必要があります。それは、探査と開発のトレードオフです。
- インテリジェンスは、環境に関する詳細情報を検索します。
- 悪用では、既知の情報を使用して報酬を最大化します。
RLエージェントの目標は、予想される累積報酬を最大化することです。 ただし、一般的なトラップに陥ることがあります。
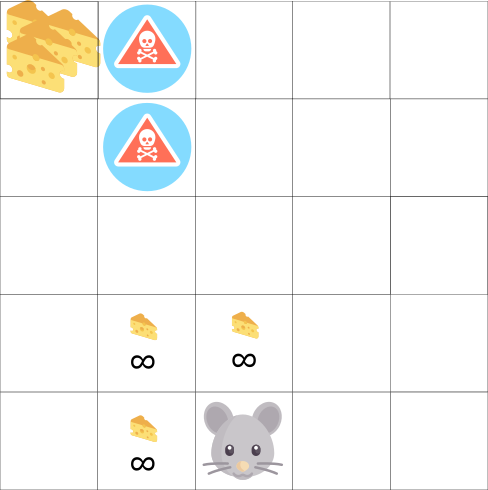
このゲームでは、マウスに無数の小さなチーズの破片を入れることができます(各+1)。 しかし、迷路の上部には巨大なチーズ(+1000)があります。 ただし、報酬のみに注目すると、エージェントは巨大な塊に到達することはありません。 その代わりに、彼は報酬の最も近いソースのみを使用します。たとえこのソースが小さい場合でも(搾取)。 しかし、私たちのエージェントが少し偵察するなら、彼は大きな報酬を見つけることができます。
これは、探査と開発の間の妥協と呼ばれるものです。 この妥協に対処するのに役立つルールを定義する必要があります。 今後の記事では、これを行うさまざまな方法を学習します。
3つの強化学習アプローチ
強化学習の主要な要素を特定したので、強化学習を解決するための3つのアプローチ(コストベース、ポリシーベース、モデルベース)に進みましょう。
コストに基づいて
コストベースのRLの目標は、効用関数V(s)を最適化することです。
ユーティリティ関数は、エージェントが各状態で受け取る最大の期待報酬を通知する関数です。
各状態の値は、この状態から開始して、エージェントが将来蓄積することが期待できる報酬の合計額です。
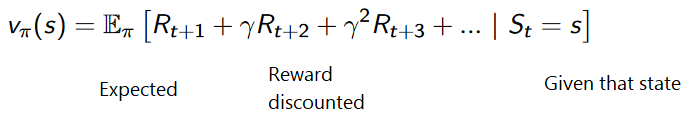
エージェントはこのユーティリティ機能を使用して、各ステップで選択する状態を決定します。 エージェントは、最も高い値を持つ状態を選択します。
各ステップの迷路の例では、目標を達成するために、-7、次に-6、-5などの最高値を取ります。
ポリシーベース
ポリシーベースのRLでは、ユーティリティ関数を使用せずにπ(s)ポリシー関数を直接最適化します。 ポリシーは、特定の時点でのエージェントの動作を決定するものです。
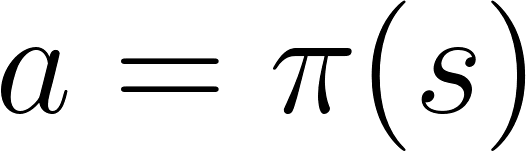
アクション=ポリシー(状態)
政治の機能を研究しています。 これにより、各状態を最適なアクションに関連付けることができます。
ポリシーには2つのタイプがあります。
- 確定的:特定の状態の政治は常に同じアクションを返します。
- 確率的:アクションによる分布の確率を表示します。

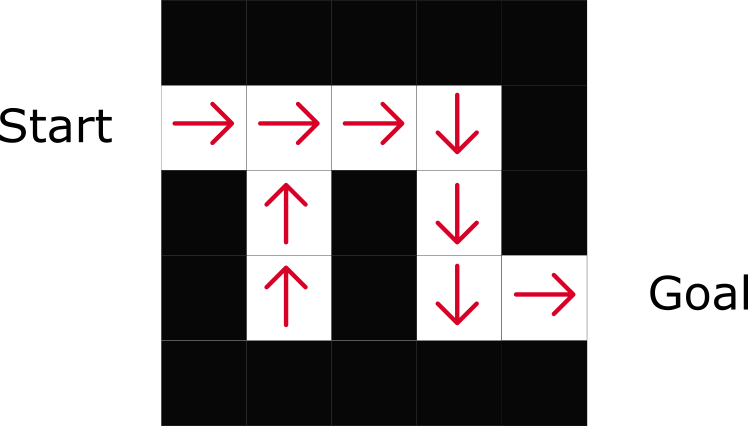
ご覧のとおり、ポリシーは各ステップに最適なアクションを直接示しています。
モデルに基づいて
モデルベースのRLでは、環境をモデル化します。 これは、環境行動のモデルを作成していることを意味します。 問題は、各環境でモデルの異なるビューが必要になることです。 そのため、次の記事ではこの種のトレーニングにあまり焦点を当てません。
深層強化学習の紹介
Deep Reinforcement Learningでは、強化学習の問題を解決するためにディープニューラルネットワークを導入しています。そのため、「ディープ」という名前が付けられています。
たとえば、次の記事では、Qラーニング(クラシック強化学習)とディープQラーニングに取り組みます。
最初のアプローチでは、従来のアルゴリズムを使用してQテーブルを作成します。これにより、各状態に対して実行するアクションを見つけることができます。
2番目のアプローチでは、ニューラルネットワークを使用します(状態ベースの報酬を近似するために:q値)。
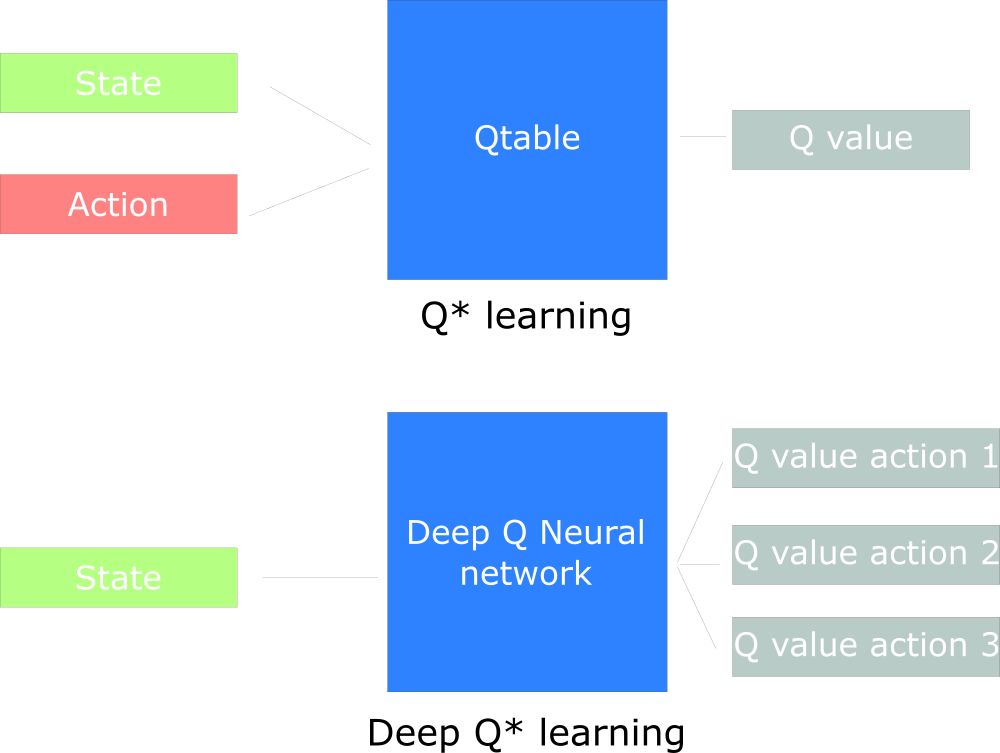
Udacity Inspired Q設計チャート
以上です。 いつものように、私たちはここであなたのコメントや質問を待っています、またはあなたはネットワーキングの公開レッスンでコース教師アーサー・カドゥリンにそれらを尋ねることができます。