コールセンターが効果的であることを念頭に置いて、コールスコアの自動化に取り組みました。 その結果、呼び出しを処理し、それらを疑わしいと中立の2つのグループに分配するアルゴリズムを思いつきました。 すべての疑わしい電話はすぐに品質評価チームに送信されました。

ディープニューラルネットワークのトレーニング方法
サンプルでは、1700個のオーディオファイルを取得し、その上でネットワークをトレーニングしました。 ニューロンは最初は何が疑わしく、何が中立であるかを知らなかったため、それに応じてすべてのファイルを手動でマークしました。
ニュートラルサンプルでは、オペレーターは以下を行います。
- 声を上げなかった。
- 顧客に要求されたすべての情報を提供します。
- クライアントからの挑発に応答しませんでした。
疑わしいパターンでは、オペレーターはしばしば次のことを行いました。
- わいせつな言葉を使用しました。
- 声を上げるか、顧客に向かって叫ぶ。
- 人に行きました。
- 問題に関する助言を拒否しました。
アルゴリズムがファイルの処理を完了すると、200個のファイルが無効としてマークされました。 これらのファイルには、疑わしいまたは中立的な兆候は含まれていませんでした。 これらの200個のファイルに含まれるものを見つけました。
- オペレーターが彼に答えた直後に、クライアントは電話を切りました。
- クライアントは、彼に答えた後、何も言わなかった。
- クライアント側またはオペレーター側でノイズが大きすぎました。
これらのファイルを削除したときに、残りの1,500個をトレーニングケースとテストケースに分割しました。 将来、これらのデータセットを使用して、ディープニューラルネットワークのトレーニングとテストを行いました。
ステップ1:特徴を抽出する
高レベルの特徴抽出は、機械学習で重要な役割を果たします。 アルゴリズムの効率に直接影響します。 考えられるすべてのソースを分析した後、次の症状を選択しました。
時間統計
- ゼロクロッシングレート :信号がプラスからマイナス、またはその逆に変化するレート。
- 中央フレームエネルギー :対応するフレーム長に二乗され正規化された信号の合計。
- サブフレームのエネルギーのエントロピー: サブフレームの正規化されたエネルギーのエントロピー。 これは、劇的な変化の尺度として解釈できます。
- フレームの平均/中央値/標準偏差 。
スペクトル統計(周波数間隔あり)
- スペクトル重心。
- スペクトル分布。
- スペクトルエントロピー。
- スペクトル放射。
- スペクトル減衰。
トーン周波数のケプストラム係数と飽和ベクトルは、入力信号の長さに敏感です。 一度にファイル全体からそれらを抽出することはできますが、そうすると、特性の開発が間に合わなくなります。 そのような方法は私たちに合わなかったので、信号を「ウィンドウ」(時間ブロック)に分割することにしました。
記号の品質を向上させるために、信号をチャンクに分割しました。チャンクは互いに部分的に重なり合っていました。 次に、各チャンクに対して順次タグを抽出しました。 したがって、属性マトリックスは各オーディオファイルに対して計算されました。
ウィンドウサイズ-0.2 s; ウィンドウステップ-0.1秒
ステップ2:個別のフレーズで声のトーンを定義する
問題を解決する最初のアプローチは、ストリーム内の各フレーズを個別に定義および処理することです。
最初に行ったのは、 LIUMライブラリを使用してダイアリゼーションを行い、すべてのフレーズを分離することでした 。 入力ファイルの品質は低かったので、出力では、各ファイルに平滑化と適応しきい値処理も適用しました。
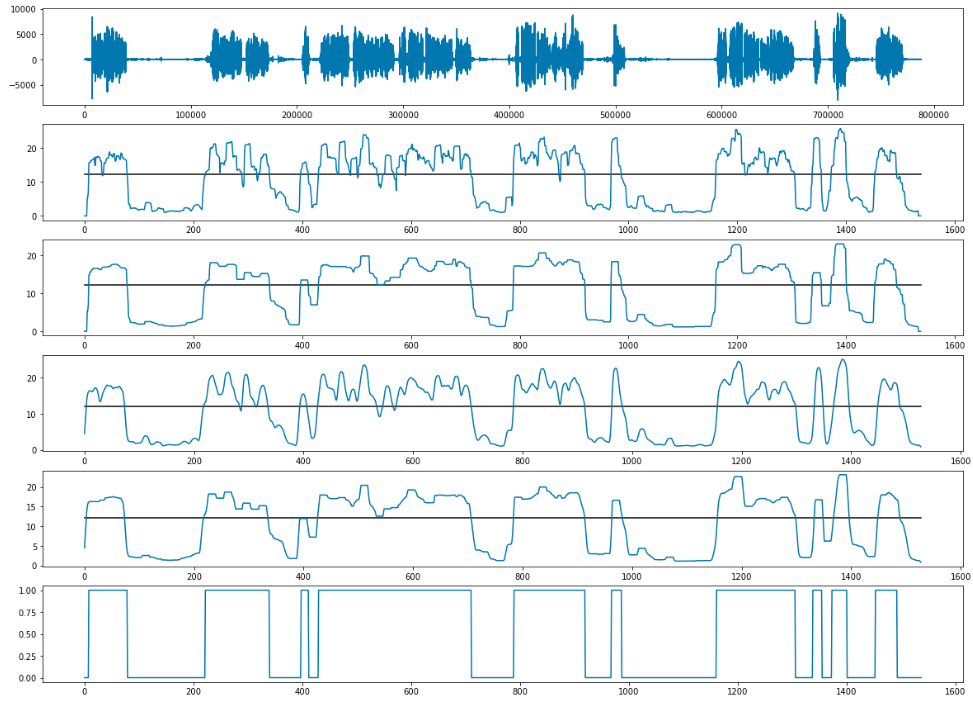
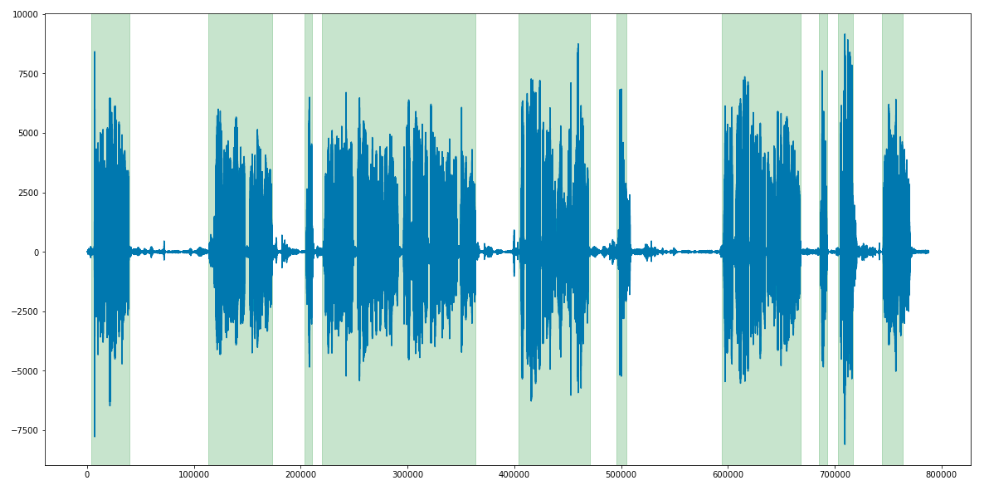
中断と長い沈黙の処理
各フレーズ(クライアントとオペレーターの両方)の時間制限を決定するとき、私たちはそれらを互いに重ね合わせ、両方の人が同時に話す場合と、両方が沈黙している場合を明らかにしました。 しきい値を決定するためだけに残った。 3秒以上参加者が同時に話す場合、これは中断と見なされることに同意しました。 無音の場合、3秒のしきい値が正確に設定されました。
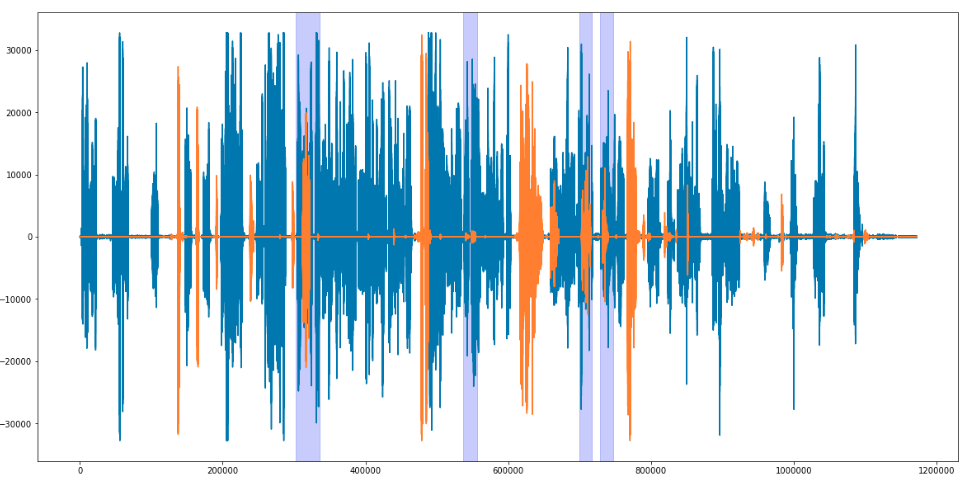

ポイントは、各フレーズに独自の長さがあることです。 その結果、各フレーズに対して抽出される特徴の数は異なります。
LSTMニューラルネットワークはこの問題を処理できます。 この種のネットワークは、長さの異なるシーケンスを処理できるだけでなく、フィードバックを含めることもできるため、情報を保存することができます。 以前に話されたフレーズには、後に話されたフレーズに影響する情報が含まれているため、これらの機能は非常に重要です。

次に、各フレーズのイントネーションを決定するためにLSTMネットワークをトレーニングしました。
トレーニングセットとして、平均30フレーズ(各側15フレーズ)の70ファイルを取りました。
主な目標は、コールセンターのオペレーターのフレーズを評価することでした。そのため、トレーニングにはクライアントの音声を使用しませんでした。 750個のフレーズをトレーニングデータセットとして使用し、250個のフレーズをテストとして使用しました。 その結果、ニューロンは72%の精度で音声を分類することを学びました。
しかし、最終的には、LSTMネットワークのパフォーマンスに満足できませんでした。LSTMネットワークの操作には時間がかかりすぎ、結果は完全にはほど遠い状態です。 したがって、異なるアプローチを使用することが決定されました。
XGBoostに加えてLSTMとXGBの組み合わせを使用して、声のトーンをどのように決定したかを説明します。
ファイル全体の音声トーンを決定する
ルールに違反するフレーズが少なくとも1つ含まれている場合、ファイルを疑わしいとマークしました。 そこで、2500個のファイルにタグを付けました。
属性を抽出するために、同じメソッドと同じANNアーキテクチャを使用しましたが、1つの違いがあります。属性の新しい次元に合わせてアーキテクチャをスケーリングしました。
最適なパラメーターを使用して、ニューラルネットワークは85%の精度を実現しました。

XGBoost
XGBoostモデルでは、各ファイルに固定数の属性が必要です。 この要件を満たすために、いくつかの信号とパラメーターを作成しました。
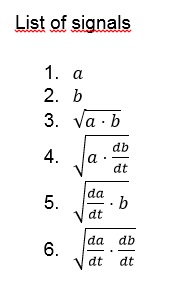

次の統計が使用されました。
- 信号の平均値。
- 信号の最初の10秒の平均値。
- 信号の最後の3秒間の平均値。
- 信号の極大値の平均値。
- 信号の最初の10秒間の局所的な最大値の平均値。
- 信号の最後の3秒間の極大値の平均値。
すべての指標は、各信号に対して個別に計算されました。 レコードの長さを除いて、属性の総数は36です。 その結果、各レコードに37個の数値記号がありました。
このアルゴリズムの予測精度は0.869です。
LSTMとXGBの組み合わせ
分類子を結合するために、これら2つのモデルを交差させました。 出力では、これにより精度が2%向上しました。

つまり、予測精度を0.9 ROC - AUC (Area Under Curve)に高めることができました。
結果
205個のファイル(177個のニュートラル、28個の疑わしいファイル)でディープニューラルネットワークをテストしました。 ネットワークは各ファイルを処理し、そのファイルが属するグループを決定する必要がありました。 結果は次のとおりです。
- 170個のニュートラルファイルが正しく識別されました。
- 7つのニュートラルファイルが疑わしいと識別されました。
- 13の疑わしいファイルが正しく識別されました。
- 15の疑わしいファイルが中立として識別されました。
正しい/誤った結果の割合を推定するために、2x2テーブル形式のエラーマトリックスを使用しました。

会話で特定のフレーズを見つける
音声ファイル内の単語やフレーズを認識するために、このアプローチを試してみました。 目標は、会話の最初の10秒間にコールセンターのオペレーターが顧客に提示されなかったファイルを見つけることでした。
平均長1.5秒で200のフレーズを取りました。オペレーターは自分の名前と会社名を呼び出します。
そのようなファイルを手動で検索するのには時間がかかりました。 各ファイルを聞いて、必要なフレーズが含まれているかどうかを確認する必要がありました。 さらにトレーニングを高速化するために、「人工的に」データセットを増やしました。各ファイルをランダムに6回変更しました-ノイズを追加し、頻度やボリュームを変更しました。 そこで、1,500個のファイルのデータセットを取得しました。
まとめ
オペレーターの応答の最初の10秒を使用して分類子をトレーニングしました。これは、この間隔で目的のフレーズが発音されたためです。 各パッセージはウィンドウに分割され(ウィンドウ長1.5秒、ウィンドウステップ1秒)、入力ファイルとしてニューラルネットワークによって処理されました。 出力ファイルとして、選択したウィンドウで各フレーズを発音する確率を受け取りました。
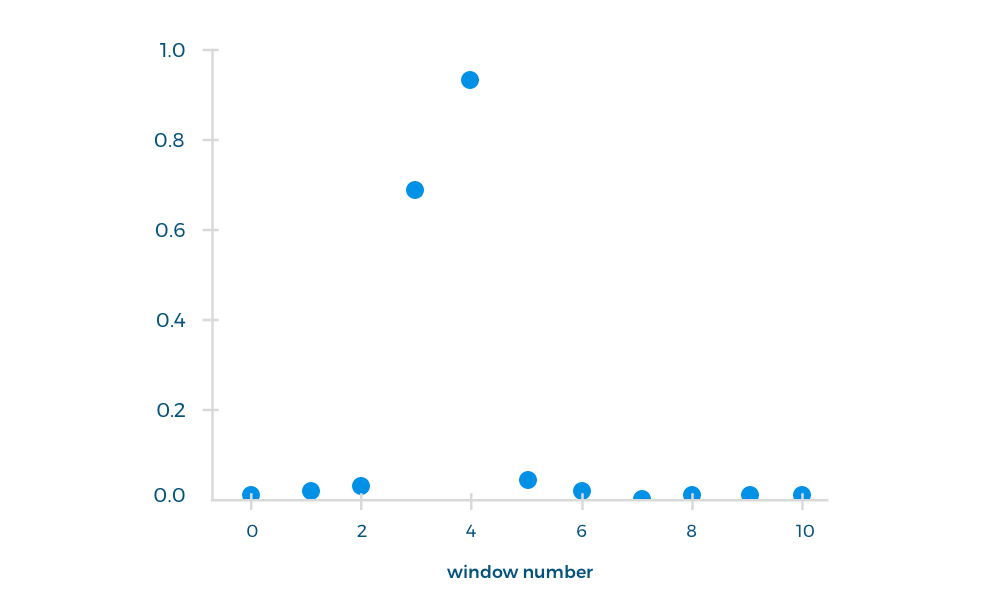
ネットワークを介してさらに300ファイルを実行し、最初の10秒間に目的のフレーズが話されたかどうかを確認しました。 これらのファイルの精度は87%でした。
実際、これは何のためですか?
自動コールアセスメントは、コールセンターオペレーターの明確なKPIを決定し、ベストプラクティスを強調して従い、コールセンターのパフォーマンスを向上させるのに役立ちます。 しかし、音声認識ソフトウェアはより広範なタスクに使用できることに注意してください。
以下は、音声認識が組織にどのように役立つかを示すいくつかの例です。
- データを収集および分析して、音声UXを改善します。
- 通話記録を分析して、関係と傾向を特定します。
- 音声で人を認識する。
- 顧客の感情を見つけて特定し、ユーザーの満足度を向上させる
- 通話あたりの平均収益を増やします。
- 流出を減らす。
- などなど!