それでは、認識の観点からクラスタリングとは何ですか? 例を挙げましょう。おばあさんのコテージの花の素敵な写真があるとしましょう。

問題は、この写真のほぼ同じ色で塗りつぶされている領域の数を判断することです。 まあ、それはまったく難しくありません:白い花びら-1つ、黄色のセンター-2つ(私は生物学者ではありません、私はそれらが何と呼ばれるかわかりません)、3つの緑。 これらのセクションはクラスターと呼ばれます。 クラスターは、共通の特徴(色、位置など)を持つデータの組み合わせです。 このようなクラスター-セクション内のデータの各コンポーネントを決定して配置するプロセスは、クラスタリングと呼ばれます。
多くのクラスタリングアルゴリズムがありますが、最も単純なものはk-中程度のもので、これについては後で説明します。 K-meansは、ソフトウェアメソッドを使用して簡単に実装できるシンプルで効率的なアルゴリズムです。 クラスタに分散するデータはピクセルです。 ご存じのとおり、カラーピクセルには3つのコンポーネント(赤、緑、青)があります。 これらのコンポーネントの面付けにより、既存の色のパレットが作成されます。
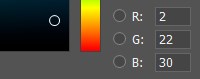
コンピュータのメモリでは、各色成分は0〜255の数字で特徴付けられます。つまり、赤、緑、青の異なる値を組み合わせて、画面上にカラーパレットを取得します。
例としてピクセルを使用して、アルゴリズムを実装します。 K-meansは反復アルゴリズムです。つまり、いくつかの数学的計算を一定回数繰り返した後、正しい結果が得られます。
アルゴリズム
- データを配信するために必要なクラスターの数を事前に知る必要があります。 これはこの方法の重大な欠点ですが、この問題はアルゴリズムの改善された実装によって解決されますが、これは彼らが言うように、まったく異なる話です。
- クラスターの初期中心を選択する必要があります。 どうやって? はい、ランダムに。 なんで? 各ピクセルをクラスターの中心にスナップできるようにします。 中心は王のようなもので、その周りに彼の主題が集まっています-ピクセル。 各ピクセルが誰に従うかを決定するのは、中心からピクセルまでの「距離」です。
- 各中心から各ピクセルまでの距離を計算します。 この距離は、空間内のポイント間のユークリッド距離と見なされ、この場合、3つの色成分間の距離と見なされます。
$$表示$$ \ sqrt {(R_ {2} -R_ {1})^ 2 +(G_ {2} -G_ {1})^ 2 +(B_ {2} -B_ {1})^ 2} 。$$表示$$
最初のピクセルから各中心までの距離を計算し、このピクセルと中心の間の最小距離を決定します。 中心である最小距離は、ピクセルの各コンポーネント-キングとピクセル-被写体の間の算術平均として座標を再計算します。 私たちのセンターは、計算に従って空間をシフトします。 - すべての中心を再計算した後、ピクセルをクラスターに分配し、各ピクセルから中心までの距離を比較します。 ピクセルはクラスターに配置され、その中心は他の中心よりも近くにあります。
- ピクセルが同じクラスター内にある限り、すべてが最初から始まります。 大量のデータでは中心が小さな半径で移動し、クラスターの端に沿ったピクセルが一方または他方のクラスターにジャンプするため、これは頻繁に発生しません。 これを行うには、反復の最大数を決定します。
実装
このプロジェクトをC ++で実装します。 最初のファイルは「k_means.h」です。その中で、主なデータ型、定数、および作業用のメインクラス「K_means」を定義しました。
各ピクセルを特徴付けるには、3つのピクセルコンポーネントで構成される構造を作成します。より正確な計算のためにdoubleタイプを選択し、プログラムの定数を決定しました。
const int KK = 10; // const int max_iterations = 100; // typedef struct { double r; double g; double b; } rgb;
K_meansクラス自体:
class K_means { private: std::vector<rgb> pixcel; int q_klaster; int k_pixcel; std::vector<rgb> centr; void identify_centers(); inline double compute(rgb k1, rgb k2) { return sqrt(pow((k1.r - k2.r),2) + pow((k1.g - k2.g), 2) + pow((k1.b - k2.b), 2)); } inline double compute_s(double a, double b) { return (a + b) / 2; }; public: K_means() : q_klaster(0), k_pixcel(0) {}; K_means(int n, rgb *mas, int n_klaster); K_means(int n_klaster, std::istream & os); void clustering(std::ostream & os); void print()const; ~K_means(); friend std::ostream & operator<<(std::ostream & os, const K_means & k); };
クラスのコンポーネントを調べてみましょう。
vectorpixcel-ピクセルのベクトル。
q_klaster-クラスターの数。
k_pixcel-ピクセル数。
vectorcentr-クラスタリング中心のベクトル。その中の要素の数はq_klasterによって決定されます。
identity_centers()-入力ピクセル間で初期中心をランダムに選択する方法。
compute()およびcompute_s()は、それぞれピクセル間の距離を計算し、中心を再計算するための組み込みメソッドです。
3つのコンストラクター:最初はデフォルトで、2番目は配列からピクセルを初期化するため、3番目はテキストファイルからピクセルを初期化するためです(私の実装では、ファイルが最初に誤ってデータで満たされ、次にこのファイルからピクセルが読み込まれます。ちょうど私の場合に必要な);
クラスタリング(std :: ostream&os)-クラスタリング方法;
メソッドを作成し、出力ステートメントをオーバーロードして結果を公開します。
メソッドの実装:
void K_means::identify_centers() { srand((unsigned)time(NULL)); rgb temp; rgb *mas = new rgb[q_klaster]; for (int i = 0; i < q_klaster; i++) { temp = pixcel[0 + rand() % k_pixcel]; for (int j = i; j < q_klaster; j++) { if (temp.r != mas[j].r && temp.g != mas[j].g && temp.b != mas[j].b) { mas[j] = temp; } else { i--; break; } } } for (int i = 0; i < q_klaster; i++) { centr.push_back(mas[i]); } delete []mas; }
これは、初期クラスタリング中心を選択して中心ベクトルに追加する方法です。 これらの場合、センターを繰り返して交換するためにチェックが実行されます。
K_means::K_means(int n, rgb * mas, int n_klaster) { for (int i = 0; i < n; i++) { pixcel.push_back(*(mas + i)); } q_klaster = n_klaster; k_pixcel = n; identify_centers(); }
配列からピクセルを初期化するためのコンストラクター実装。
K_means::K_means(int n_klaster, std::istream & os) : q_klaster(n_klaster) { rgb temp; while (os >> temp.r && os >> temp.g && os >> temp.b) { pixcel.push_back(temp); } k_pixcel = pixcel.size(); identify_centers(); }
ファイルとコンソールの両方からデータを入力できるように、このコンストラクターに入力オブジェクトを渡します。
void K_means::clustering(std::ostream & os) { os << "\n\n :" << std::endl; /* : , - , , , .*/ std::vector<int> check_1(k_pixcel, -1); std::vector<int> check_2(k_pixcel, -2); int iter = 0; /* .*/ while(true) { os << "\n\n---------------- №" << iter << " ----------------\n\n"; { for (int j = 0; j < k_pixcel; j++) { double *mas = new double[q_klaster]; /* : . , .*/ for (int i = 0; i < q_klaster; i++) { *(mas + i) = compute(pixcel[j], centr[i]); os << " " << j << " #" << i << ": " << *(mas + i) << std::endl; } /* m_k .*/ double min_dist = *mas; int m_k = 0; for (int i = 0; i < q_klaster; i++) { if (min_dist > *(mas + i)) { min_dist = *(mas + i); m_k = i; } } os << " #" << m_k << std::endl; os << " #" << m_k << ": "; centr[m_k].r = compute_s(pixcel[j].r, centr[m_k].r); centr[m_k].g = compute_s(pixcel[j].g, centr[m_k].g); centr[m_k].b = compute_s(pixcel[j].b, centr[m_k].b); os << centr[m_k].r << " " << centr[m_k].g << " " << centr[m_k].b << std::endl; delete[] mas; } /* .*/ int *mass = new int[k_pixcel]; os << "\n : "<< std::endl; for (int k = 0; k < k_pixcel; k++) { double *mas = new double[q_klaster]; /* .*/ for (int i = 0; i < q_klaster; i++) { *(mas + i) = compute(pixcel[k], centr[i]); os << " №" << k << " #" << i << ": " << *(mas + i) << std::endl; } /* .*/ double min_dist = *mas; int m_k = 0; for (int i = 0; i < q_klaster; i++) { if (min_dist > *(mas + i)) { min_dist = *(mas + i); m_k = i; } } mass[k] = m_k; os << " №" << k << " #" << m_k << std::endl; } /* .*/ os << "\n : \n"; for (int i = 0; i < k_pixcel; i++) { os << mass[i] << " "; check_1[i] = *(mass + i); } os << std::endl << std::endl; os << " : " << std::endl; int itr = KK + 1; for (int i = 0; i < q_klaster; i++) { os << " #" << i << std::endl; for (int j = 0; j < k_pixcel; j++) { if (mass[j] == i) { os << pixcel[j].r << " " << pixcel[j].g << " " << pixcel[j].b << std::endl; mass[j] = ++itr; } } } delete[] mass; /* .*/ os << " : \n" ; for (int i = 0; i < q_klaster; i++) { os << centr[i].r << " " << centr[i].g << " " << centr[i].b << " - #" << i << std::endl; } } /* – .*/ iter++; if (check_1 == check_2 || iter >= max_iterations) { break; } check_2 = check_1; } os << "\n\n ." << std::endl; }
クラスタリングの主な方法。
std::ostream & operator<<(std::ostream & os, const K_means & k) { os << " : " << std::endl; for (int i = 0; i < k.k_pixcel; i++) { os << k.pixcel[i].r << " " << k.pixcel[i].g << " " << k.pixcel[i].b << " - №" << i << std::endl; } os << std::endl << " : " << std::endl; for (int i = 0; i < k.q_klaster; i++) { os << k.centr[i].r << " " << k.centr[i].g << " " << k.centr[i].b << " - #" << i << std::endl; } os << "\n : " << k.q_klaster << std::endl; os << " : " << k.k_pixcel << std::endl; return os; }
初期データの出力。
出力例
出力例
開始ピクセル:
255140 50-No. 0
100 70 1-No. 1
150 20200-2番
251141 51-No.3
104 69 3-No. 4
153 22210-No. 5
252138 54-第6
101 74 4-No. 7
ランダムな初期クラスタリングセンター:
150 20200-#0
104 69 3-#1
100 70 1-#2
クラスターの数:3
ピクセル数:8
クラスター開始:
反復番号0
ピクセル0から中心#0までの距離:218.918
ピクセル0から中心#1までの距離:173.352
ピクセル0から中心#2までの距離:176.992
最小中心距離#1
センターの再計算#1:179.5 104.5 26.5
ピクセル1から中心#0までの距離:211.189
ピクセル1から中心#1までの距離:90.3369
ピクセル1から中心#2までの距離:0
最小中心距離#2
センターの再計算#2:100 70 1
ピクセル2から中心#0までの距離:0
ピクセル2から中心#1までの距離:195.225
ピクセル2から中心#2までの距離:211.189
最小中心距離#0
センターを数える#0:150 20 200
ピクセル3から中心#0までの距離:216.894
ピクセル3から中心#1までの距離:83.933
ピクセル3から中心#2までの距離:174.19
最小中心距離#1
センターを数える#1:215.25 122.75 38.75
ピクセル4から中心#0までの距離:208.149
ピクセル4から中心#1までの距離:128.622
ピクセル4から中心#2までの距離:4.58258
最小中心距離#2
センターを数える#2:102 69.5 2
ピクセル5から中心#0までの距離:10.6301
ピクセル5から中心#1までの距離:208.212
ピクセル5から中心#2までの距離:219.366
最小中心距離#0
センターを数える#0:151.5 21 205
ピクセル6から中心#0までの距離:215.848
ピクセル6から中心#1までの距離:42.6109
ピクセル6から中心#2までの距離:172.905
最小中心距離#1
センターの再計算#1:233.625 130.375 46.375
ピクセル7から中心#0までの距離:213.916
ピクセル7から中心#1までの距離:150.21
ピクセル7から中心#2までの距離:5.02494
最小中心距離#2
センターの再計算#2:101.5 71.75 3
ピクセルを分類しましょう:
ピクセルNo. 0から中心#0までの距離:221.129
ピクセルNo. 0から中心までの距離#1:23.7207
ピクセルNo. 0から中心までの距離#2:174.44
センター#1に最も近いピクセル#0
ピクセル1から中心までの距離#0:216.031
ピクセル1から中心までの距離#1:153.492
ピクセルNo. 1から中心までの距離#2:3.05164
センター#2に最も近いピクセル#1
ピクセルNo. 2から中心までの距離#0:5.31507
ピクセル2から中心までの距離#1:206.825
ピクセル2から中心までの距離#2:209.378
センター#0に最も近いピクセル#2
ピクセル番号3から中心#0までの距離:219.126
ピクセル3から中心までの距離#1:20.8847
ピクセルNo. 3から中心までの距離#2:171.609
センター#1に最も近いピクセル#3
ピクセルNo. 4から中心までの距離#0:212.989
ピクセル4から中心までの距離#1:149.836
ピクセル4から中心までの距離#2:3.71652
センター#2に最も近いピクセル#4
ピクセルNo. 5から中心までの距離#0:5.31507
ピクセル5から中心までの距離#1:212.176
ピクセル5から中心までの距離#2:219.035
センター#0に最も近いピクセル#5
ピクセル番号6から中心#0までの距離:215.848
ピクセルNo. 6から中心までの距離#1:21.3054
ピクセル6から中心までの距離#2:172.164
センター#1に最も近いピクセル#6
ピクセルNo. 7から中心までの距離#0:213.916
ピクセル番号7から中心までの距離#1:150.21
ピクセルNo. 7から中心までの距離#2:2.51247
センター#2に最も近いピクセル#7
一致するピクセルと中心の配列:
1 2 0 1 2 0 1 2
クラスタリング結果:
クラスター#0
150 20 200
153 22 210
クラスター#1
255 140 50
251 141 51
252138 54
クラスター#2
100 70 1
104 69 3
101 74 4
新しいセンター:
151.5 21205-#0
233.625 130.375 46.375-#1
101.5 71.75 3-#2
反復番号1
ピクセル0から中心#0までの距離:221.129
ピクセル0から中心#1までの距離:23.7207
ピクセル0から中心#2までの距離:174.44
最小中心距離#1
センターを数える#1:244.313 135.188 48.1875
ピクセル1から中心#0までの距離:216.031
ピクセル1から中心#1までの距離:165.234
ピクセル1から中心#2までの距離:3.05164
最小中心距離#2
センターの再計算#2:100.75 70.875 2
ピクセル2から中心#0までの距離:5.31507
ピクセル2から中心#1までの距離:212.627
ピクセル2から中心#2までの距離:210.28
最小中心距離#0
中心の再計算#0:150.75 20.5 202.5
ピクセル3から中心#0までの距離:217.997
ピクセル3から中心#1までの距離:9.29613
ピクセル3から中心#2までの距離:172.898
最小中心距離#1
センターを数える#1:247.656 138.094 49.5938
ピクセル4から中心#0までの距離:210.566
ピクセル4から中心#1までの距離:166.078
ピクセル4から中心#2までの距離:3.88306
最小中心距離#2
センターを数える#2:102.375 69.9375 2.5
ピクセル5から中心#0までの距離:7.97261
ピクセル5から中心#1までの距離:219.471
ピクセル5から中心#2までの距離:218.9
最小中心距離#0
センターのカウント#0:151.875 21.25 206.25
ピクセル6から中心#0までの距離:216.415
ピクセル6から中心#1までの距離:6.18805
ピクセル6から中心#2までの距離:172.257
最小中心距離#1
センターの再計算#1:249.828 138.047 51.7969
ピクセル7から中心#0までの距離:215.118
ピクセル7から中心#1までの距離:168.927
ピクセル7から中心#2までの距離:4.54363
最小中心距離#2
センターの再計算#2:101.688 71.9688 3.25
ピクセルを分類しましょう:
ピクセルNo. 0から中心#0までの距離:221.699
ピクセルNo. 0から中心までの距離#1:5.81307
ピクセルNo. 0から中心までの距離#2:174.122
センター#1に最も近いピクセル#0
ピクセルNo. 1から中心#0までの距離:217.244
ピクセル1から中心までの距離#1:172.218
ピクセル#1から中心#2までの距離:3.43309
センター#2に最も近いピクセル#1
ピクセル2から中心までの距離#0:6.64384
ピクセルNo. 2から中心までの距離#1:214.161
ピクセル2から中心までの距離#2:209.154
センター#0に最も近いピクセル#2
ピクセルNo. 3から中心#0までの距離:219.701
ピクセルNo. 3から中心までの距離#1:3.27555
ピクセル3から中心までの距離#2:171.288
センター#1に最も近いピクセル#3
ピクセルNo. 4から中心までの距離#0:214.202
ピクセル4から中心までの距離#1:168.566
ピクセル4から中心までの距離#2:3.77142
センター#2に最も近いピクセル#4
ピクセル5から中心までの距離#0:3.9863
ピクセル5から中心までの距離#1:218.794
ピクセル5から中心までの距離#2:218.805
センター#0に最も近いピクセル#5
ピクセル番号6から中心までの距離#0:216.415
ピクセルNo. 6から中心までの距離#1:3.09403
ピクセル6から中心までの距離#2:171.842
センター#1に最も近いピクセル#6
ピクセル番号7から中心#0までの距離:215.118
ピクセルNo. 7から中心までの距離#1:168.927
ピクセルNo. 7から中心までの距離#2:2.27181
センター#2に最も近いピクセル#7
一致するピクセルと中心の配列:
1 2 0 1 2 0 1 2
クラスタリング結果:
クラスター#0
150 20 200
153 22 210
クラスター#1
255 140 50
251 141 51
252138 54
クラスター#2
100 70 1
104 69 3
101 74 4
新しいセンター:
151.875 21.25 206.25-#0
249.828 138.047 51.7969-#1
101.688 71.9688 3.25-#2
クラスタリングの終わり。
255140 50-No. 0
100 70 1-No. 1
150 20200-2番
251141 51-No.3
104 69 3-No. 4
153 22210-No. 5
252138 54-第6
101 74 4-No. 7
ランダムな初期クラスタリングセンター:
150 20200-#0
104 69 3-#1
100 70 1-#2
クラスターの数:3
ピクセル数:8
クラスター開始:
反復番号0
ピクセル0から中心#0までの距離:218.918
ピクセル0から中心#1までの距離:173.352
ピクセル0から中心#2までの距離:176.992
最小中心距離#1
センターの再計算#1:179.5 104.5 26.5
ピクセル1から中心#0までの距離:211.189
ピクセル1から中心#1までの距離:90.3369
ピクセル1から中心#2までの距離:0
最小中心距離#2
センターの再計算#2:100 70 1
ピクセル2から中心#0までの距離:0
ピクセル2から中心#1までの距離:195.225
ピクセル2から中心#2までの距離:211.189
最小中心距離#0
センターを数える#0:150 20 200
ピクセル3から中心#0までの距離:216.894
ピクセル3から中心#1までの距離:83.933
ピクセル3から中心#2までの距離:174.19
最小中心距離#1
センターを数える#1:215.25 122.75 38.75
ピクセル4から中心#0までの距離:208.149
ピクセル4から中心#1までの距離:128.622
ピクセル4から中心#2までの距離:4.58258
最小中心距離#2
センターを数える#2:102 69.5 2
ピクセル5から中心#0までの距離:10.6301
ピクセル5から中心#1までの距離:208.212
ピクセル5から中心#2までの距離:219.366
最小中心距離#0
センターを数える#0:151.5 21 205
ピクセル6から中心#0までの距離:215.848
ピクセル6から中心#1までの距離:42.6109
ピクセル6から中心#2までの距離:172.905
最小中心距離#1
センターの再計算#1:233.625 130.375 46.375
ピクセル7から中心#0までの距離:213.916
ピクセル7から中心#1までの距離:150.21
ピクセル7から中心#2までの距離:5.02494
最小中心距離#2
センターの再計算#2:101.5 71.75 3
ピクセルを分類しましょう:
ピクセルNo. 0から中心#0までの距離:221.129
ピクセルNo. 0から中心までの距離#1:23.7207
ピクセルNo. 0から中心までの距離#2:174.44
センター#1に最も近いピクセル#0
ピクセル1から中心までの距離#0:216.031
ピクセル1から中心までの距離#1:153.492
ピクセルNo. 1から中心までの距離#2:3.05164
センター#2に最も近いピクセル#1
ピクセルNo. 2から中心までの距離#0:5.31507
ピクセル2から中心までの距離#1:206.825
ピクセル2から中心までの距離#2:209.378
センター#0に最も近いピクセル#2
ピクセル番号3から中心#0までの距離:219.126
ピクセル3から中心までの距離#1:20.8847
ピクセルNo. 3から中心までの距離#2:171.609
センター#1に最も近いピクセル#3
ピクセルNo. 4から中心までの距離#0:212.989
ピクセル4から中心までの距離#1:149.836
ピクセル4から中心までの距離#2:3.71652
センター#2に最も近いピクセル#4
ピクセルNo. 5から中心までの距離#0:5.31507
ピクセル5から中心までの距離#1:212.176
ピクセル5から中心までの距離#2:219.035
センター#0に最も近いピクセル#5
ピクセル番号6から中心#0までの距離:215.848
ピクセルNo. 6から中心までの距離#1:21.3054
ピクセル6から中心までの距離#2:172.164
センター#1に最も近いピクセル#6
ピクセルNo. 7から中心までの距離#0:213.916
ピクセル番号7から中心までの距離#1:150.21
ピクセルNo. 7から中心までの距離#2:2.51247
センター#2に最も近いピクセル#7
一致するピクセルと中心の配列:
1 2 0 1 2 0 1 2
クラスタリング結果:
クラスター#0
150 20 200
153 22 210
クラスター#1
255 140 50
251 141 51
252138 54
クラスター#2
100 70 1
104 69 3
101 74 4
新しいセンター:
151.5 21205-#0
233.625 130.375 46.375-#1
101.5 71.75 3-#2
反復番号1
ピクセル0から中心#0までの距離:221.129
ピクセル0から中心#1までの距離:23.7207
ピクセル0から中心#2までの距離:174.44
最小中心距離#1
センターを数える#1:244.313 135.188 48.1875
ピクセル1から中心#0までの距離:216.031
ピクセル1から中心#1までの距離:165.234
ピクセル1から中心#2までの距離:3.05164
最小中心距離#2
センターの再計算#2:100.75 70.875 2
ピクセル2から中心#0までの距離:5.31507
ピクセル2から中心#1までの距離:212.627
ピクセル2から中心#2までの距離:210.28
最小中心距離#0
中心の再計算#0:150.75 20.5 202.5
ピクセル3から中心#0までの距離:217.997
ピクセル3から中心#1までの距離:9.29613
ピクセル3から中心#2までの距離:172.898
最小中心距離#1
センターを数える#1:247.656 138.094 49.5938
ピクセル4から中心#0までの距離:210.566
ピクセル4から中心#1までの距離:166.078
ピクセル4から中心#2までの距離:3.88306
最小中心距離#2
センターを数える#2:102.375 69.9375 2.5
ピクセル5から中心#0までの距離:7.97261
ピクセル5から中心#1までの距離:219.471
ピクセル5から中心#2までの距離:218.9
最小中心距離#0
センターのカウント#0:151.875 21.25 206.25
ピクセル6から中心#0までの距離:216.415
ピクセル6から中心#1までの距離:6.18805
ピクセル6から中心#2までの距離:172.257
最小中心距離#1
センターの再計算#1:249.828 138.047 51.7969
ピクセル7から中心#0までの距離:215.118
ピクセル7から中心#1までの距離:168.927
ピクセル7から中心#2までの距離:4.54363
最小中心距離#2
センターの再計算#2:101.688 71.9688 3.25
ピクセルを分類しましょう:
ピクセルNo. 0から中心#0までの距離:221.699
ピクセルNo. 0から中心までの距離#1:5.81307
ピクセルNo. 0から中心までの距離#2:174.122
センター#1に最も近いピクセル#0
ピクセルNo. 1から中心#0までの距離:217.244
ピクセル1から中心までの距離#1:172.218
ピクセル#1から中心#2までの距離:3.43309
センター#2に最も近いピクセル#1
ピクセル2から中心までの距離#0:6.64384
ピクセルNo. 2から中心までの距離#1:214.161
ピクセル2から中心までの距離#2:209.154
センター#0に最も近いピクセル#2
ピクセルNo. 3から中心#0までの距離:219.701
ピクセルNo. 3から中心までの距離#1:3.27555
ピクセル3から中心までの距離#2:171.288
センター#1に最も近いピクセル#3
ピクセルNo. 4から中心までの距離#0:214.202
ピクセル4から中心までの距離#1:168.566
ピクセル4から中心までの距離#2:3.77142
センター#2に最も近いピクセル#4
ピクセル5から中心までの距離#0:3.9863
ピクセル5から中心までの距離#1:218.794
ピクセル5から中心までの距離#2:218.805
センター#0に最も近いピクセル#5
ピクセル番号6から中心までの距離#0:216.415
ピクセルNo. 6から中心までの距離#1:3.09403
ピクセル6から中心までの距離#2:171.842
センター#1に最も近いピクセル#6
ピクセル番号7から中心#0までの距離:215.118
ピクセルNo. 7から中心までの距離#1:168.927
ピクセルNo. 7から中心までの距離#2:2.27181
センター#2に最も近いピクセル#7
一致するピクセルと中心の配列:
1 2 0 1 2 0 1 2
クラスタリング結果:
クラスター#0
150 20 200
153 22 210
クラスター#1
255 140 50
251 141 51
252138 54
クラスター#2
100 70 1
104 69 3
101 74 4
新しいセンター:
151.875 21.25 206.25-#0
249.828 138.047 51.7969-#1
101.688 71.9688 3.25-#2
クラスタリングの終わり。
この例は前もって計画されており、ピクセルはデモ用に選択されています。 プログラムがデータを3つのクラスターにグループ化するには、2回の反復で十分です。 最後の2回の繰り返しの中心を見ると、それらが実際に所定の位置に残っていることがわかります。
さらに興味深いのは、ランダムに生成されたピクセルの場合です。 10個のクラスターに分割する必要がある50個のポイントを生成したので、5回繰り返しました。 3つのクラスターに分割する必要のある50個のポイントを生成したので、最大100回の反復が許可されました。 クラスターが多いほど、プログラムが最も類似したピクセルを見つけてそれらをより小さなグループにまとめるのが簡単になり、逆も同様です-クラスターが少なく、ポイントが多い場合、アルゴリズムは多くの場合、最大反復数を超えたときにのみ終了しますあるクラスターから別のクラスターへ。 ただし、バルクはクラスター内で完全に決定されます。
それでは、クラスタリングの結果を確認しましょう。 10個のクラスターあたり50ポイントの例からいくつかのクラスターの結果を取得し、これらのデータの結果をIllustratorに送り込みました。
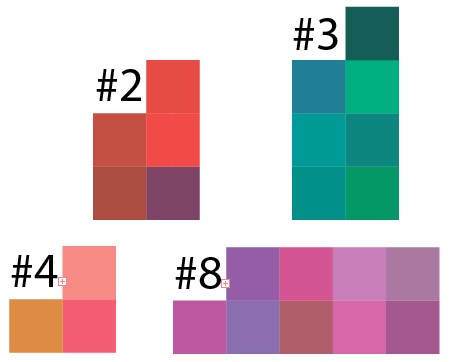
各クラスターでは色の濃淡が優勢であることがわかります。ここでは、ピクセルがランダムに選択されたことを理解する必要があります。実際の生活でのそのような画像の類似物は、すべての色が誤って吹き付けられた何らかの種類の画像であり、同様の色の領域を選択することは困難です
このような写真があるとしましょう。 島を1つのクラスターとして定義することもできますが、増加すると、さまざまな緑の陰影で構成されることがわかります。

これはクラスター8ですが、小さいバージョンでは結果は同様です:

プログラムのフルバージョンは、私のGitHubで表示できます。