あるインタビューで、ある有名なロシアのミュージシャンが言った:「私たちは、嘘をついて天井に吐き出すことに取り組んでいます。」 怠inessが技術開発の原動力であるという事実は議論できないので、私はこの声明に反対することはできません。 実際、前世紀になってようやく蒸気機関からデジタル工業化に移行し、今では前世紀のSF作家や未来学者によって説明された人工知能が、日々私たちの世界のますます現実になりつつあります。 コンピューターゲーム、モバイルデバイス、スマートウォッチなど 基本的に、機械学習メカニズムに関連するアルゴリズムを使用します。
今日では、グラフィックプロセッサのコンピューティング機能の増加と大量のデータの出現により、ニューラルネットワークが人気を博し、それを使用して分類および回帰の問題を解決し、準備されたデータでトレーニングしています。 ニューラルネットワークのトレーニング方法と、これに使用するフレームワークについては、すでに多くの記事が執筆されています。 しかし、解決する必要がある初期のタスクもあります。これは、ニューラルネットワークをさらにトレーニングするためのデータ配列であるデータセットを形成するタスクです。 これについては、この記事で説明します。
少し前まで、一般的なオーディオストリームからデータを抽出できる音響カーノイズ分類器を構築する必要がありました。ガラスの破損、ドアの開け方、さまざまなモードでの車のエンジンの操作です。 分類子の開発は難しくありませんでしたが、すべての要件を満たすためにデータセットを取得する場所はどこですか?
Googleが助けになりました(Yandexに害はありません。その利点については後で説明します)。これにより、必要なデータを含むいくつかの主要なクラスターを特定することができました。 この記事で示したソースには、さまざまなクラスの音響情報が大量に含まれており、さまざまなタスクのデータセットを作成できることを事前にお知らせしておきます。 次に、これらのソースの概要に移りましょう。
Freesound.org

ほとんどの場合、 Freesound.orgが提供する音響データの最大量は、ライセンスされた音楽サンプルの共同リポジトリであり、現在230,000以上の効果音のコピーを持っています。 各サウンドサンプルは、異なるライセンスの下で配布できます。そのため、事前にライセンス契約に慣れておくことをお勧めします。 たとえば、 ゼロ(cc0)ライセンスには「著作権なし」ステータスがあり、商用利用を含めてコピー、変更、および配布を許可し、データを完全に合法的に使用できます。
さまざまなfreesound.orgで音響情報要素を見つけるために、開発者はリポジトリからデータを分析、検索、ダウンロードするために設計されたAPIを提供しています。 これを使用するには、アクセス権を取得する必要があります。そのためには、 フォームに移動し、必要なすべてのフィールドに入力する必要があります。その後、個々のキーが生成されます。

Freesound.org開発者はさまざまなプログラミング言語のAPIを提供しているため、異なるツールで同じ問題を解決できます。 サポートされている言語のリストと、GitHubでそれらにアクセスするためのリンクを以下に示します。
目標を達成するために、Pythonが使用されました。この美しい動的タイピングプログラミング言語は使いやすさから人気を博し、ソフトウェア開発の複雑さの神話を完全に消去しました。 Python用のfreesound.orgを操作するためのモジュールは 、github.comリポジトリから複製できます。
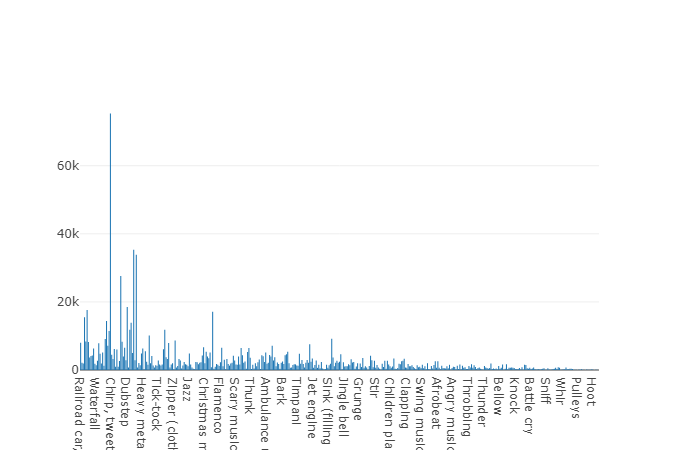
以下は、このAPIの使いやすさを示す2つの部分からなるコードです。 プログラムコードの最初の部分はデータ分析のタスクを実行し、その結果は要求された各クラスのデータ分布の密度です。2番目の部分は選択したクラスのfreesound.orgリポジトリからデータをアップロードします。 キーワードglass、engine、doorを使用して音響情報を検索する場合の分布密度を、例として円グラフで以下に示します。
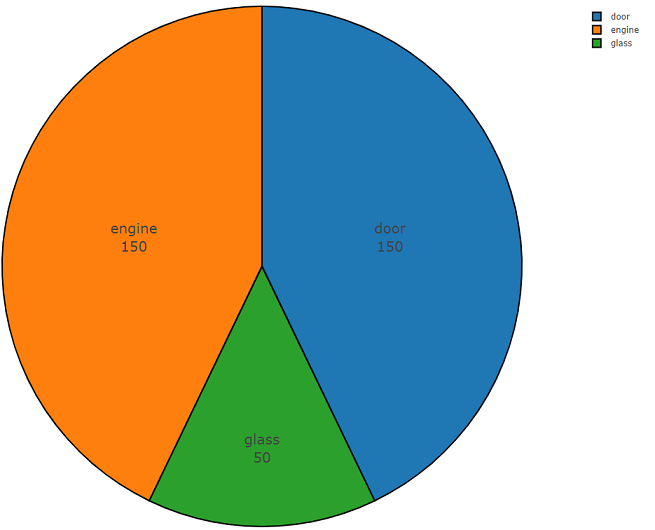
Freesound.orgデータ分析のサンプルコード
import plotly import plotly.graph_objs as go import freesound import os import termcolor # def histogram(data, filename = "tmp_histogram.html"): data = [ go.Histogram( histfunc="count", x=data, name="count",textfont=dict(size=15) ), ] plotly.offline.plot({ "data": data, "layout": go.Layout(title="Histogram") }, auto_open=True, filename=filename) pass # freesound.org def freesound_analysis(search_tokens, output, lim_page_count = 1, key = None): lim_page_count = int(lim_page_count) try: client = freesound.FreesoundClient() client.set_token(key,"token") print(termcolor.colored("Authorisation successful ", "green")) except: print(termcolor.colored("Authorisation failed ", "red")) classes = list() for token in search_tokens: try: results = client.text_search(query=token,fields="id,name,previews") output_catalog = os.path.normpath(output) if not os.path.exists(output_catalog): os.makedirs(output_catalog) page_count = int(0) while True: for sound in results: try: classes.append(token) info = "Data has been getter: " + str(sound.name) print(termcolor.colored(info, "green")) except: info = "Data has not been getter: " + str(sound.name) print(termcolor.colored(info, "red")) page_count += 1 if (not results.next) or (lim_page_count == page_count): page_count = 0 break results = results.next_page() except: print(termcolor.colored(" Search is failed ", "red")) histogram(classes) pass
freesound.orgデータをダウンロードするためのサンプルコード
# def freesound_download(search_tokens, output, lim_page_count = 1, key = None): lim_page_count = int(lim_page_count) # . try: client = freesound.FreesoundClient() client.set_token(key,"token") print(termcolor.colored("Authorisation successful ", "green")) except: print(termcolor.colored("Authorisation failed ", "red")) for token in search_tokens: try: results = client.text_search(query=token,fields="id,name,previews") output_catalog = os.path.normpath(output + "\\" + str(token)) if not os.path.exists(output_catalog): os.makedirs(output_catalog) page_count = int(0) while True: for sound in results: try: sound.retrieve_preview(output_catalog) info = "Saved file: " + str(output_catalog) + str(sound.name) print(termcolor.colored(info, "green")) except: info = str("Sound can`t be saved to " + str(output_catalog) + str(sound.name) ) print(termcolor.colored(info, "red")) page_count += 1 if not results.next or lim_page_count == page_count: page_count = 0 break results = results.next_page() except: print(termcolor.colored(" Search is failed ", "red"))
freesoundの機能は、オーディオファイルをダウンロードせずにオーディオデータの分析を実行できることです。これにより、MFCC、スペクトルエネルギー、スペクトルセントロイド、その他の係数を取得できます。 freesound.ordのドキュメントで低レベル情報の詳細をお読みください。
freesound.org APIを使用すると、データのサンプリングとアップロードにかかる時間が最小限に抑えられ、高精度の音響分類器にはさまざまな高調波を持つデータを表す大きなデータセットが必要になるため、他の情報ソースの調査に費やす時間を節約できます。同じクラスのイベント。
YouTube-8MおよびAudioSet

プレゼンテーションではyoutubeは特に必要ではないと思いますが、それでもwikipediaは、youtubeはビデオ表示サービスをユーザーに提供するビデオホスティングサイトであり、youtubeは巨大なデータベースであると言うことを忘れており、このソースは機械学習で使用する必要があることを示しています、Google IncはYouTube-8M Datasetというプロジェクトを提供します。
YouTube-8Mデータセットは、より正確な情報を提供するために、YouTubeからの100万を超えるビデオファイルを高品質で含むデータセットです。2018年5月の時点で、3862クラスの6.1Mビデオがありました。 このデータセットは、 Creative Commons Attribution 4.0 International(CC BY 4.0)ライセンスの下でライセンスされています。 このようなライセンスにより、任意の媒体および形式で資料をコピーおよび配布できます。
あなたはおそらく疑問に思うでしょう:タスクに音響情報が必要なとき、ビデオデータはどこから来るのか、あなたは非常に正しいでしょう。 実際、Googleはビデオコンテンツだけでなく、 AudioSetと呼ばれる音声データを含むサブプロジェクトを個別に割り当てています。
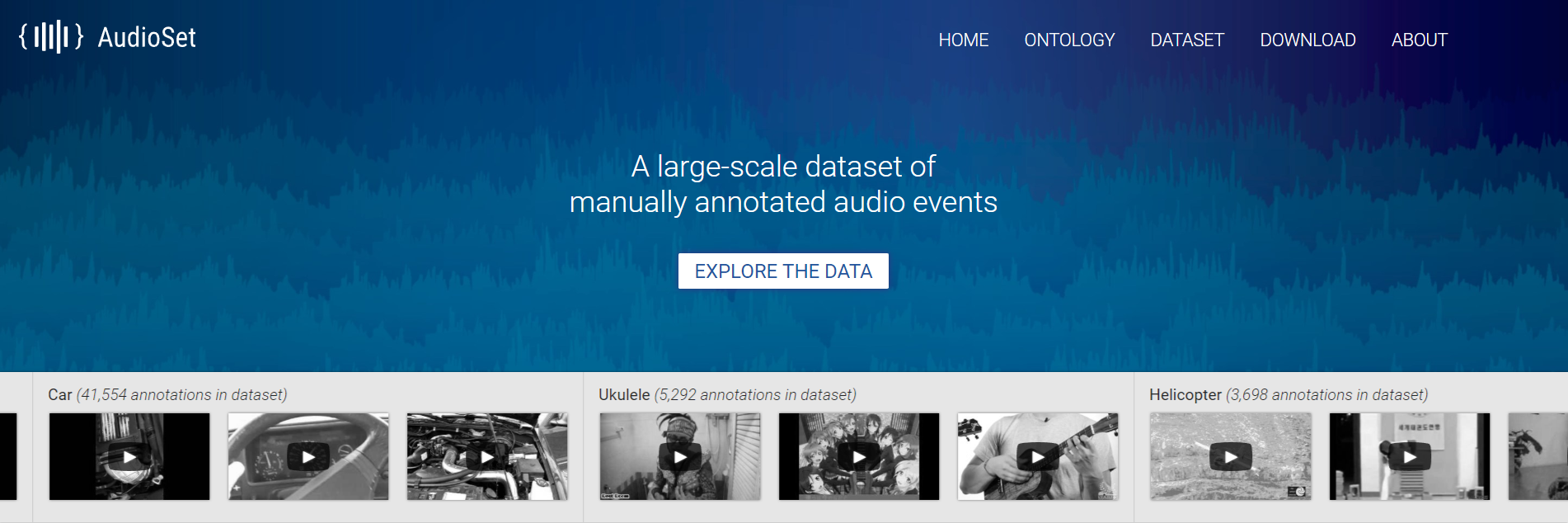
AudioSet -YouTubeビデオから取得したデータセットを提供します。多くのデータがオントロジーファイルを使用してクラス階層で表示されます 。そのグラフィック表現は下にあります。
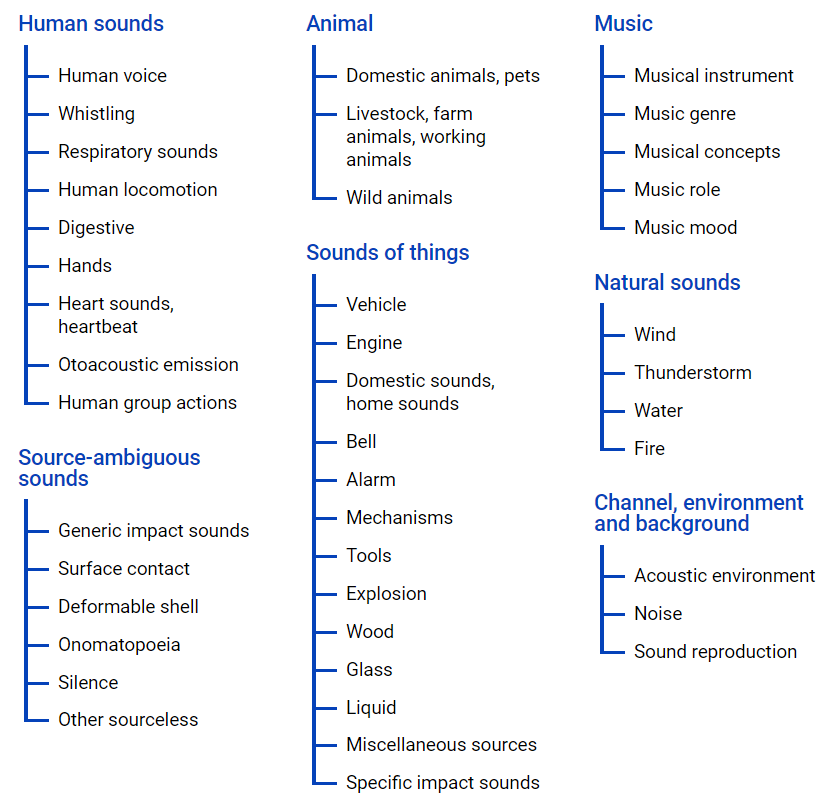
このファイルを使用すると、クラスのネストと、YouTubeビデオへのアクセスについて理解できます。 インターネットスペースからデータをアップロードするには、pythonモジュール-youtube-dlを使用できます。これにより、必要なタスクに応じて、オーディオまたはビデオコンテンツをダウンロードできます。
AudioSetは、テスト、トレーニング(バランス)およびトレーニング(アンバランス) データセットの 3つのセットに分割されたクラスターを表します。
このクラスターを見て、これらの各セットを個別に分析して、含まれているクラスの概念を把握しましょう。
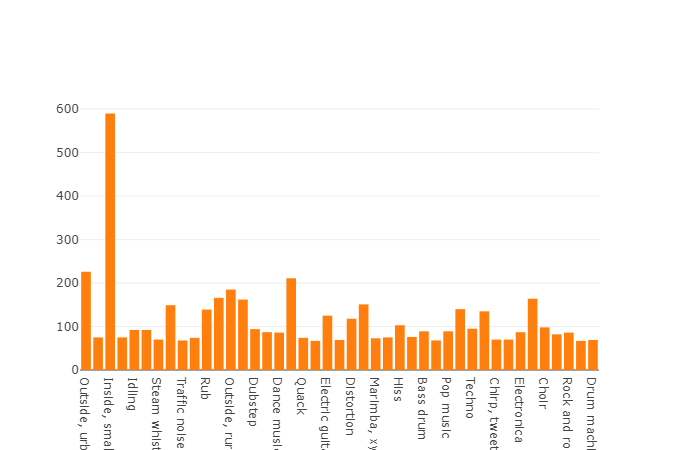
トレーニング(バランス)
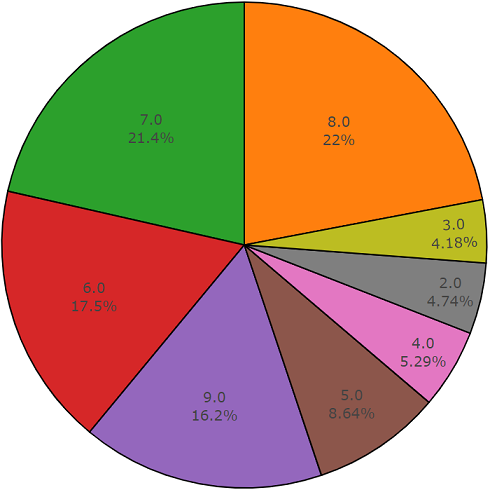
ドキュメントによると、このデータセットは、キーワードで選択されたさまざまなビデオから取得した22,176個のセグメントで構成され、各クラスに少なくとも59個のコピーを提供します。 セットの階層内のルートクラスの分布密度を見ると、Musicクラスがオーディオファイルの最大のグループであることがわかります。
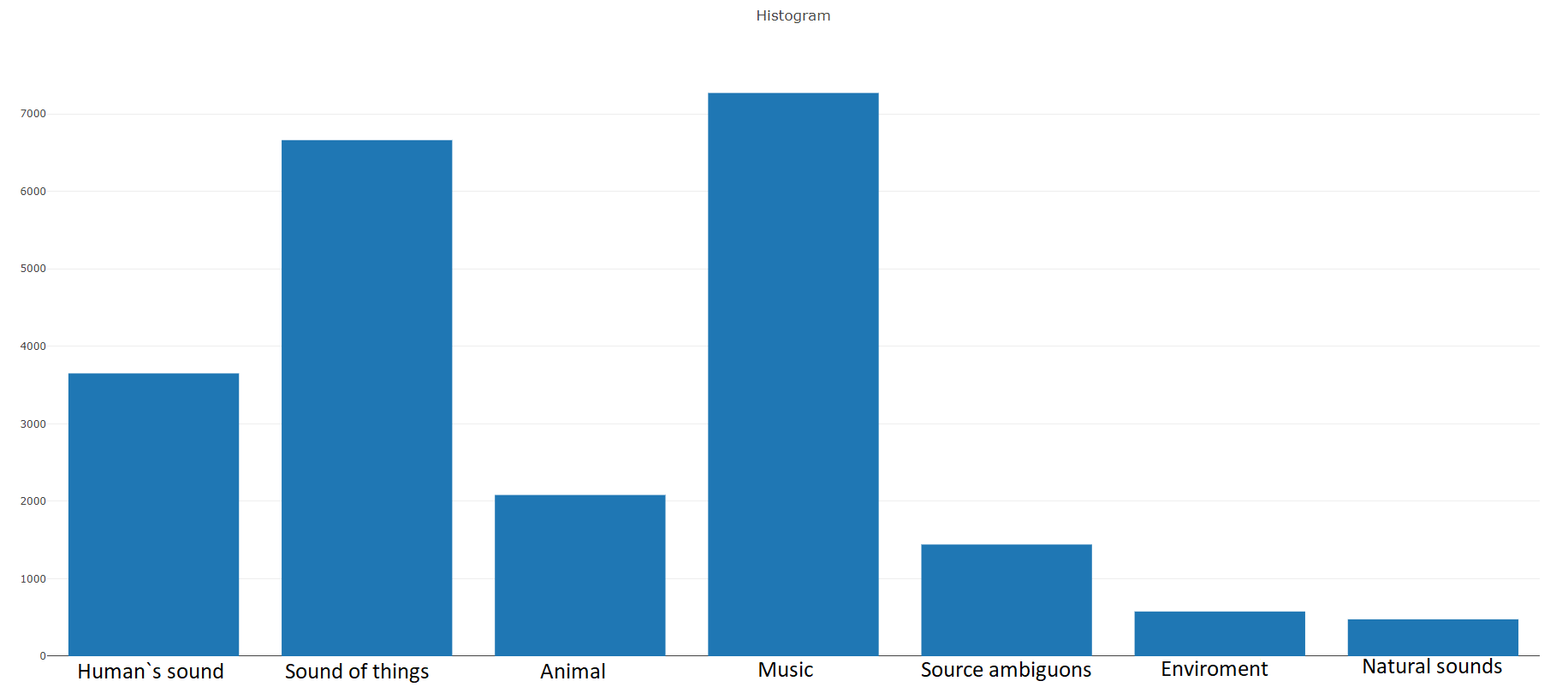
組織化されたクラスはクラスのサブセットに分解され、使用時により詳細な情報を取得できます。 このバランスの取れたトレーニングセットには、バランスが存在することがわかる分布密度がありますが、一般的な観点からは個々のクラスも際立っています。
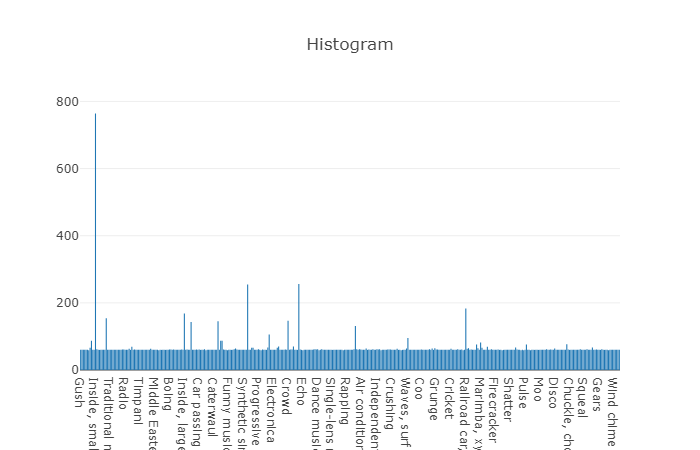
要素数が平均値を超えるクラスの分布
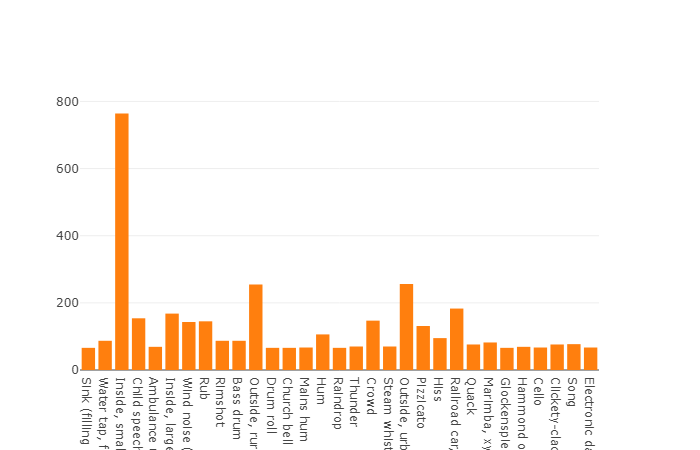
各オーディオファイルの平均所要時間は10秒です。ディスクダイアグラムには、一部のファイルの所要時間がメインセットと異なることを示す詳細な情報が表示されます。 このチャートも表示されます。
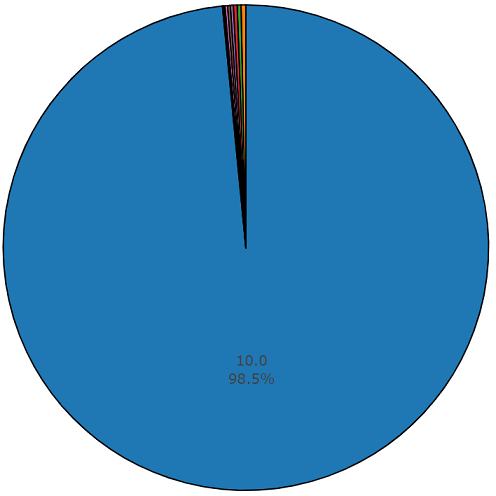
オーディオセットのバランスの取れたセットからの1.5パーセントの非平均持続時間の図
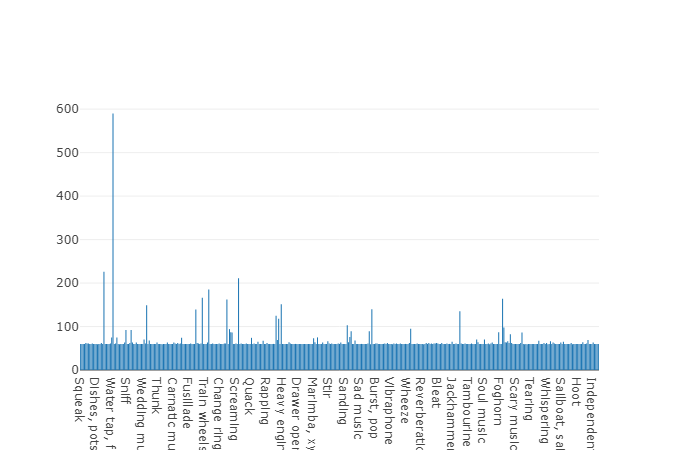
トレーニング(アンバランス)
このデータセットの利点は、そのサイズです。 ドキュメンテーションによると、このセットには2,042,985個のセグメントが含まれており、バランスの取れたデータセットと比較して、多くのばらつきがあることを想像してください。しかし、このセットのエントロピーははるかに高いです。
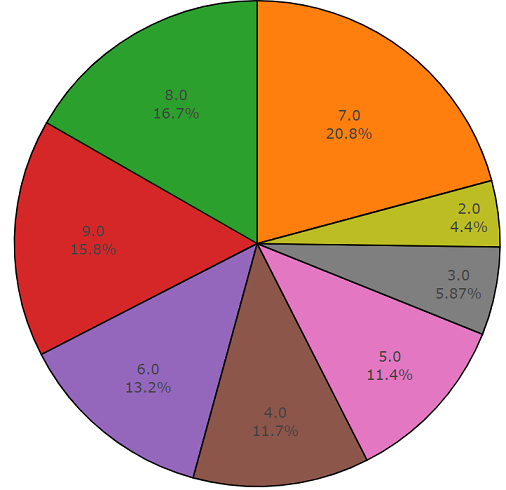
このセットでは、各オーディオファイルの平均期間も10秒に等しく、このデータセットのディスクダイアグラムを以下に示します。
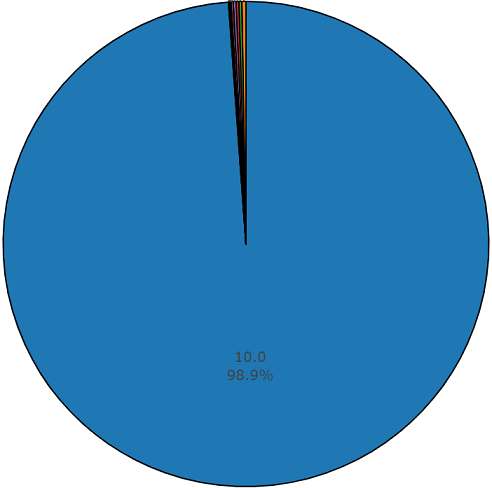
不均衡なオーディオセットのセットからの非平均デュレーションチャート
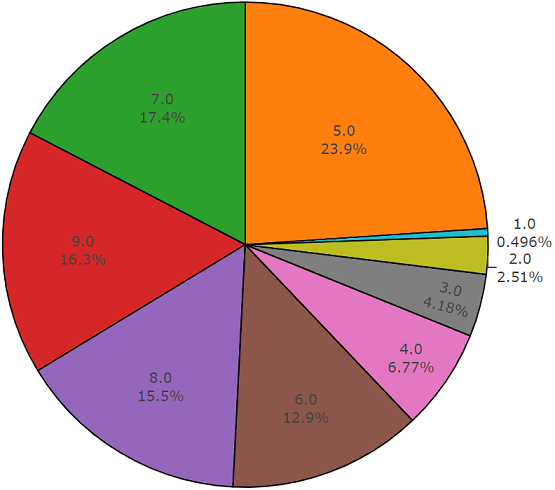
テストセット
このセットはバランスのとれたセットに非常に似ており、これらのセットの要素が交差しないという利点があります。 それらの分布を以下に示します。
要素数が平均値を超えるクラスの分布
このデータセットの1つのセグメントの平均期間も10秒に等しい
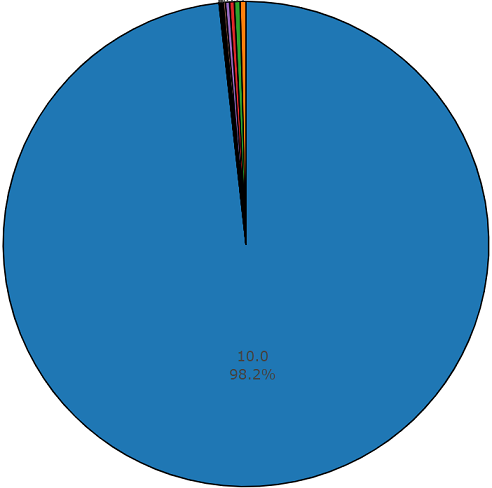
残りはディスクダイアグラムに表示される期間を持ちます
選択したデータセットに従って音響データを分析およびダウンロードするためのサンプルコード:
import plotly import plotly.graph_objs as go from collections import Counter import numpy as np import os import termcolor import csv import json import youtube_dl import subprocess # def histogram(data,hist_mean= True, filename = "tmp_histogram.html"): if hist_mean == True: cdata = Counter(data) mean_number_classes = np.asarray([cdata[x] for x in cdata]).mean() ldata = list() for name in cdata: if cdata[name] > mean_number_classes: ldata += list(Counter({name:cdata[name]}).elements()) trace_mean_data = go.Histogram(histfunc="count", x=ldata, name="count" ) trace_data = go.Histogram(histfunc="count", x=data, name="count", text="" ) trace = [ trace_data, trace_mean_data] plotly.offline.plot({ "data": trace, "layout": go.Layout(title="stack") }, auto_open=True, filename=filename) pass # def pie_chart(labels, values = None, filename = "tmp_pie_chart.html", textinfo = 'label+value'): if labels == None: raise Exception("Can not create pie chart, because labels is None") if values == None: data = Counter(labels) labels = list() values = list() for name in data: labels.append(name) values.append(data[name]) trace = go.Pie(labels=labels, values=values,textfont=dict(size=20),hoverinfo='label+percent', textinfo=textinfo, marker=dict(line=dict(color='#000000', width=2)) ) plotly.offline.plot([trace], filename='basic_pie_chart') pass # def audioset_analysis(audioset_file, inputOntology): if not os.path.exists(inputOntology) or not os.path.exists(audioset_file): raise Exception("Can not found file") with open(audioset_file, 'r') as fe: csv_data = csv.reader(fe) sx = list() with open(inputOntology) as f: data = json.load(f) duration_hist = list() for row in csv_data: if row[0][0] == '#': continue classes = row[3:] try: color = "green" tmp_duration = str(float(row[2]) - float(row[1])) info = str("id: ") + str(row[0]) + str(" duration: ") + tmp_duration duration_hist.append(tmp_duration) for cl in classes: for dt in data: cl = str(cl).strip().replace('"',"") if cl == dt['id'] and len(dt['child_ids']) == 0: sx.append(dt['name']) info += str(" ")+str(dt['name']) + str(",") except: color = "red" info = "File has been pass: " + str(row[0]) continue print(termcolor.colored(info, color)) histogram(sx, filename="audioset_class") pie_chart(duration_hist, textinfo="percent + label", filename="audioset_duration")
# youtube def youtube_download(filepath, ytid): ydl_opts = { 'format': 'bestaudio/best', 'outtmpl': os.path.normpath(filepath), 'postprocessors': [{ 'key': 'FFmpegExtractAudio', 'preferredcodec': 'wav', 'preferredquality': '192', }], } with youtube_dl.YoutubeDL(ydl_opts) as ydl: ydl.download(['https://www.youtube.com/watch?v={}'.format(ytid)]) pass # ffmpeg def cutOfPartFile(filename,outputFile, start, end, frequency = 44100): duration = float(end) - float(start) command = 'ffmpeg -i ' command += str(filename)+" " command += " -ar " + str(frequency) command += " -ss " + str(start) command += " -t " + str(duration) + " " command += str(outputFile) subprocess.call(command,shell=True) pass # yotube def audioset_converter(incatalog,outcatalog, token = "*.wav", frequency = 44100): find_template = os.path.join(incatalog,token) files = glob(find_template); for file in files: _,name = os.path.split(file) name = os.path.splitext(name)[0] duration = str(name).split("_")[1:3] filename = name.split("_")[0] +"."+ token.split(".")[1]; outfile = os.path.join(outcatalog,filename) cutOfPartFile(file,outfile,start=duration[0],end=duration[1]) # audioset def audioset_download(audioset_file, outputDataset, frequency = 44100): t,h = os.path.split(audioset_file) h = h.split(".") outputDataset_full = os.path.join(outputDataset,str(h[0])+"_full") outputDataset = os.path.join(outputDataset,str(h[0])) if not os.path.exists(outputDataset): os.makedirs(outputDataset) if not os.path.exists(outputDataset_full): os.makedirs(outputDataset_full) with open(audioset_file, 'r') as fe: csv_data = csv.reader(fe) duration_hist = list() for row in csv_data: if row[0][0] == '#': continue try: color = "green" tmp_duration = str(float(row[2]) - float(row[1])) info = str("id: ") + str(row[0]) + str(" duration: ") + tmp_duration duration_hist.append(tmp_duration) save_full_file = str(outputDataset_full) + str("//")+ str(row[0]).lstrip()+str("_") +str(row[1]).lstrip() + str("_").lstrip() + str(row[2]).lstrip() + str('.%(ext)s') youtube_download(save_full_file,row[0]) except: color = "red" info = "File has been pass: " + str(row[0]) continue print(termcolor.colored(info, color)) audioset_converter(outputDataset_full,outputDataset, frequency = frequency)
オーディオセットデータの分析に関するより詳細な情報を取得するため、またはオントロジーファイルと選択したオーディオセットのセットに従ってこのデータをyotubeスペースからアップロードするために、プログラムコードはGitHubリポジトリで自由に利用できます 。
アーバンサウンド
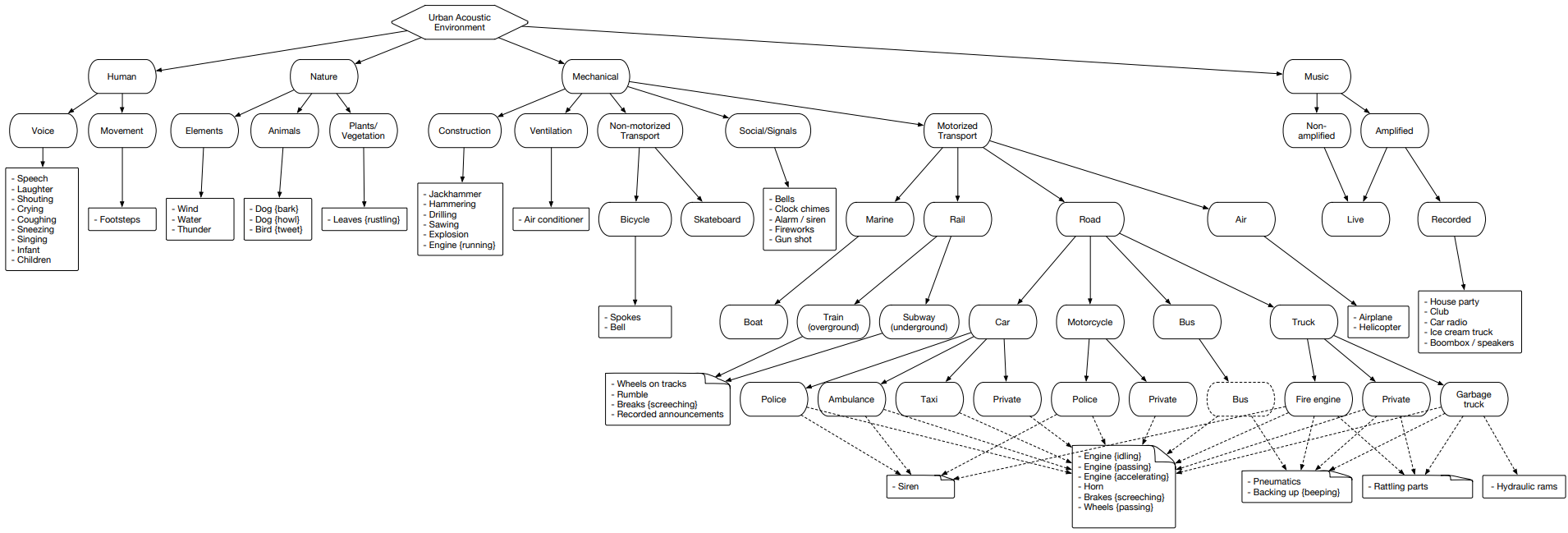
Urbansoundは、タグ付けされたサウンドイベントを持つ最大のデータセットの1つであり、そのクラスは都市環境に属します。 このセットは分類(カテゴリ)と呼ばれます。 各クラスはサブクラスに分割されます。 そのような多数は、ツリーの形で表すことができます。
後で使用するために都市サウンドデータをアップロードするには、ページに移動して[ ダウンロード ]をクリックします 。
タスクはすべてのサブクラスを使用する必要はなく、車に関連付けられた単一のクラスのみが必要であるため、ダウンロードしたファイルを解凍するときに取得したディレクトリのルートにあるメタファイルを使用して必要なクラスをフィルタリングする必要があります。
リストされたソースから必要なすべてのデータをアンロードした後、15,000を超えるファイルを含むデータセットを形成することが判明しました。 このような大量のデータにより、音響分類器のトレーニングのタスクに進むことができますが、データの「純度」に関する未解決の問題が残っています。 トレーニングセットには、解決する問題の必要なクラスに関連しないデータが含まれます。 たとえば、「ガラス破壊」クラスのファイルを聞くと、「ガラスを破壊するのは良くない」という話をする人を見つけることができます。 したがって、データをフィルタリングするという課題に直面しています。この種の問題を解決するためのツールとして、ツールは完璧に適しています。そのコアはベラルーシ人によって開発され、「Yandex.Toloka」という奇妙な名前が付けられました。
ヤンデックス・トロカ

Yandex.Tolokaは、機械学習でさらに使用するために大量のデータをマークアップまたは収集するために2014年に作成されたクラウドファンディングプロジェクトです。 実際、このツールを使用すると、人的資源を使用してデータを収集、マーク、およびフィルタリングできます。 はい、このプロジェクトでは問題を解決できるだけでなく、他の人もお金を稼ぐことができます。 この場合の経済的負担はあなたの肩にかかりますが、10,000人以上のトーカーがパフォーマーの側で行動するという事実のために、仕事の結果は近い将来に受け取られます。 このツールの操作に関する適切な説明は、 Yandexブログにあります。
一般に、タスクの公開にはサイトへの登録、最低10米ドル、および適切に実行されたタスクのみが必要なため、クラッシュの使用は特に難しくありません。 タスクを正しく定式化するには、 Yandex.Tolokのドキュメントを参照するか、Habrに関する悪い記事はありません。 私自身からこの記事まで、タスクの要件に適したテンプレートが利用できない場合でも、コーヒーとタバコを一休みすることで、その開発に数時間しかかからず、実行者の結果は営業日の終わりまでに得られることを付け加えたいと思います。
おわりに
機械学習では、分類または回帰の問題を解決する際の主要なタスクの1つは、信頼できるデータセット(データセット)を開発することです。 この記事では、特定のタスクに必要なデータセットを形成し、バランスを取ることを可能にする、大量の音響データを持つ情報ソースを検討しました。 提示されたプログラムコードにより、データのアップロード操作が最小限に抑えられるため、データを受信して残りのデータを分類器の開発に費やす時間が短縮されます。
私の仕事に関しては、この記事で説明したすべてのソースからデータを収集し、その後データをフィルタリングした後、ニューラルネットワークに基づく音響分類器のトレーニングに必要なデータセットを作成しました。 この記事があなたとあなたのチームが時間を節約し、新しい技術の開発に費やすことを願っています。
PS Pythonで開発されたソフトウェアモジュール。提示された各ソースの音響データの分析とダウンロードについては、githubリポジトリにあります。