猫の下には、Apache IgniteをApache Sparkで使用する方法と、このために実装した機能に関するApache Ignite Meetupに関する私のレポートのビデオおよびテキストバージョンがあります。
Apache Sparkでできること
Apache Sparkとは何ですか? これは、分散コンピューティングと分析クエリを迅速に実行できる製品です。 基本的に、Apache SparkはScalaで記述されています。
Apache Sparkには、さまざまなストレージシステムに接続したり、データを受信したりするための豊富なAPIがあります。 製品の機能の1つは、さまざまなソースから受信したデータ用の汎用SQLのようなクエリエンジンです。 複数の情報源がある場合、それらを組み合わせて結果を取得したい場合は、Apache Sparkが必要です。
Sparkが提供する主要な抽象化の1つは、Data Frame、DataSetです。 リレーショナルデータベースの観点では、これはテーブルであり、構造化された方法でデータを提供するソースです。 構造、各列のタイプ、その名前などがわかっています。 データフレームはさまざまなソースから作成できます。 例には、jsonファイル、リレーショナルデータベース、さまざまなhadoopシステム、Apache Igniteが含まれます。
SparkはSQLクエリでの結合をサポートしています。 さまざまなソースからのデータを組み合わせて結果を取得し、分析クエリを実行できます。 さらに、データを保存するためのAPIがあります。 クエリを完了し、調査を実施すると、Sparkは、この機能をサポートするレシーバーに結果を保存し、それに応じてデータ処理の問題を解決する機能を提供します。
Apache SparkとApache Igniteを統合するために実装した機能
- Apache Ignite SQLテーブルからデータを読み取ります。
- Apache Ignite SQLテーブルへのデータの書き込み。
- IgniteSparkSession内のIgniteCatalog-「手動」で登録することなく、既存のすべてのIgnite SQLテーブルを使用する機能。
- SQL最適化-Ignite内でSQLステートメントを実行する機能。
Apache Sparkは、Apache Ignite SQLテーブルからデータを読み取り、そのようなテーブルの形式でデータを書き込むことができます。 Sparkで形成されたすべてのDataFrameは、Apache Ignite SQLテーブルとして保存できます。
Apache Igniteを使用すると、標準のSparkSession拡張機能であるIgniteSparkSession内でIgniteCatalogを使用して、「手動」で登録することなく、Sparkセッションで既存のすべてのIgnite SQLテーブルを使用できます。
ここで、Sparkデバイスをもう少し深くする必要があります。 通常のデータベースに関しては、ディレクトリはメタ情報が格納される場所です。どのテーブルが利用可能か、どの列がそこにあるかなどです。 リクエストが到着すると、カタログからメタ情報が取得され、SQLエンジンはテーブルとデータに対して何らかの処理を行います。 デフォルトでは、Sparkで、すべての読み取りテーブル(関係のないデータベース、Ignite、Hadoopから)はセッションで手動で登録する必要があります。 その結果、これらのテーブルでSQLクエリを作成する機会が得られます。 Sparkはそれらについて調べます。
Igniteにアップロードしたデータを操作するには、テーブルを登録する必要があります。 ただし、各テーブルを手で登録する代わりに、すべてのIgniteテーブルに自動的にアクセスする機能を実装しました。
ここの機能は何ですか? なんらかの理由で、Sparkのディレクトリは内部APIです。 外部の人が来て、独自のカタログ実装を作成することはできません。 また、SparkはHadoopを離れたため、Hiveのみをサポートします。 そして、他のすべてを手で登録する必要があります。 ユーザーは頻繁にこれを回避する方法を尋ね、すぐにSQLクエリを作成します。 〜およびsms〜を登録せずにIgniteテーブルを参照およびアクセスできるディレクトリを実装し、最初にSparkコミュニティでこのパッチを提案しましたが、その答えに答えました。 そして、彼らは内部APIを提供しませんでした。
Igniteカタログは、Sparkの内部APIを使用して実装された興味深い機能です。 このディレクトリを使用するために、セッションの独自の実装がありますこれは通常のSparkSessionであり、その内部でリクエストを行い、データを処理できます。 違いは、Igniteテーブルを操作するためにExternalCatalogを統合したことと、IgniteOptimization(以下で説明します)です。
SQL最適化 -Ignite内でSQLステートメントを実行する機能。 デフォルトでは、結合、グループ化、集計計算、およびその他の複雑なSQLクエリを実行するとき、Sparkは行ごとのモードでデータを読み取ります。 データソースでできることは、行を効率的にフィルタリングすることだけです。
結合またはグループ化を使用する場合、Sparkは、指定されたフィルターを使用して、テーブルからすべてのデータをメモリにワーカーにプルし、それらをグループ化するか、他のSQL操作を実行します。 Igniteの場合、Ignite自体には分散アーキテクチャがあり、その中に格納されているデータの知識があるため、これは最適ではありません。 したがって、Ignite自体が集計とグループを効率的に計算できます。 さらに、大量のデータが存在する可能性があり、それらをグループ化するには、すべてを減算し、Sparkのすべてのデータを上げる必要があります。これは非常に高価です。
Sparkは、SQLクエリの初期計画を変更し、最適化を実行し、そこで実行できるSQLクエリの一部をIgniteに転送できるAPIを提供します。 これは、すぐにグループ化されるデータを引き出すために使用しないため、速度とメモリ消費の点で効果的です。
仕組み
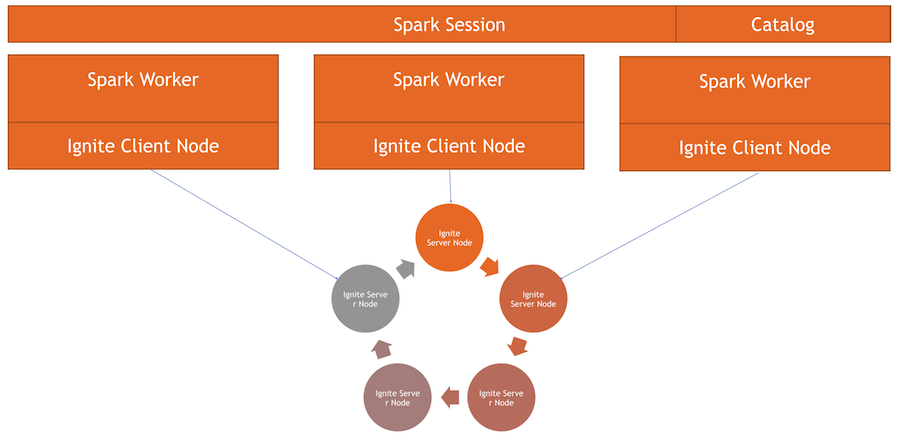
Igniteクラスターがあります-これは写真の下半分です。 5つのノードしかないため、Zookeeperはありません。 Sparkワーカーがあり、各ワーカー内でIgniteクライアントノードが発生します。 それを介して、リクエストを作成し、データを読み取り、クラスターと対話できます。 また、クライアントノードは、ディレクトリが機能するためにIgniteSparkSession内で立ち上がります。
データフレームに点火
コードに目を向ける:SQLテーブルからデータを読み取る方法 Sparkの場合、すべてが非常にシンプルで優れています。一部のデータを計算し、フォーマットを示したいと言います-これは一定の定数です。 さらに、いくつかのオプションがあります-クライアントノードの設定ファイルへのパス。データを読み込むときに開始します。 読み込むテーブルを指定し、Sparkにロードするよう指示します。 データを取得し、必要な処理を実行できます。
spark.read .format(FORMAT_IGNITE) .option(OPTION_CONFIG_FILE, TEST_CONFIG_FILE) .option(OPTION_TABLE, "person") .load()
データ(オプションでIgnite、任意のソース)を生成したら、形式と対応するテーブルを指定することで、すべてを簡単に保存できます。 Sparkに書き込みを指示し、フォーマットを指定します。 構成では、接続するクラスターを指定します。 保存するテーブルを指定します。 さらに、ユーティリティオプションを規定することができます-このテーブルで作成する主キーを指定します。 テーブルを作成せずにデータが単に動揺する場合、このパラメーターは不要です。 最後に[保存]をクリックすると、データが書き込まれます。
tbl.write. format(FORMAT_IGNITE). option(OPTION_CONFIG_FILE, CFG_PATH). option(OPTION_TABLE, tableName). option(OPTION_CREATE_TABLE_PRIMARY_KEY_FIELDS, pk). save
それでは、すべての仕組みを見てみましょう。
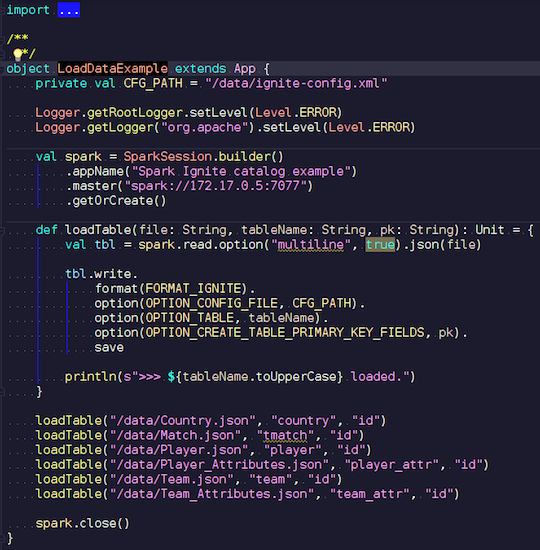
LoadDataExample.scala
この明らかなアプリケーションは、最初に録音機能を実証します。 たとえば、サッカーの試合に関するデータを選択し、有名なリソースから統計をダウンロードしました。 トーナメントに関する情報が含まれます:リーグ、試合、選手、チーム、選手属性、チーム属性-欧州諸国(イングランド、フランス、スペインなど)のリーグでのサッカーの試合を説明するデータ。
それらをIgniteにアップロードします。 Sparkセッションを作成し、ウィザードのアドレスを指定し、これらのテーブルの読み込みを呼び出して、パラメーターを渡します。 この例はJavaではなくScalaで記述されています。これは、Scalaの方が冗長性が低く、優れているためです。
ファイル名を転送して読み取り、複数行であることを示します。これは標準のjsonファイルです。 次に、Igniteに書き込みます。 ファイルの構造はどこにも記述していません。Spark自体がどのデータを持ち、どのような構造であるかを決定します。 すべてが順調に進むと、必要なデータ型のすべての必要なフィールドがあるテーブルが作成されます。 これが、Ignite内にすべてをロードする方法です。
データが読み込まれると、Igniteで表示してすぐに使用できます。 単純な例として、どのチームが最も多くの試合をしたかを知ることができるクエリ。 ホームチームとアウェイチーム、ホストとゲストの2つの列があります。 コマンドのデータを選択、グループ化、カウント、合計、結合して、コマンドの名前を入力します。 Ta-dam-Igniteで取得したjson-chiksのデータ。 トゥールーズのパリ・サンジェルマンが見えます-フランスのチームに関する多くのデータがあります。
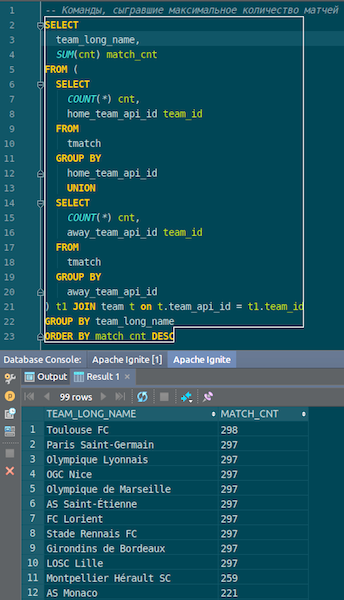
まとめます。 これで、ソースのjsonファイルからIgniteにデータが非常にすばやく読み込まれました。 おそらく、ビッグデータの観点からは、これは大きすぎませんが、ローカルコンピューターには適切です。 テーブルスキーマは、元の形式でjsonファイルから取得されます。 テーブルが作成され、列名がソースファイルからコピーされ、主キーが作成されました。 IDはどこにでもあり、主キーはIDです。 このデータはIgniteに取り込まれ、使用できます。
IgniteSparkSessionおよびIgniteCatalog
仕組みを見てみましょう。
CatalogExample.scala
かなり簡単な方法で、すべてのデータにアクセスして照会できます。 最後の例では、標準のスパークセッションを開始しました。 そして、そこにはIgniteの特異性はありませんでした-正しいデータソースでjarを置く必要があることを除いて-パブリックAPIを介した完全に標準的な作業。 ただし、Igniteテーブルに自動的にアクセスする場合は、拡張機能を使用できます。 違いは、SparkSessionの代わりにIgniteSparkSessionを作成することです。
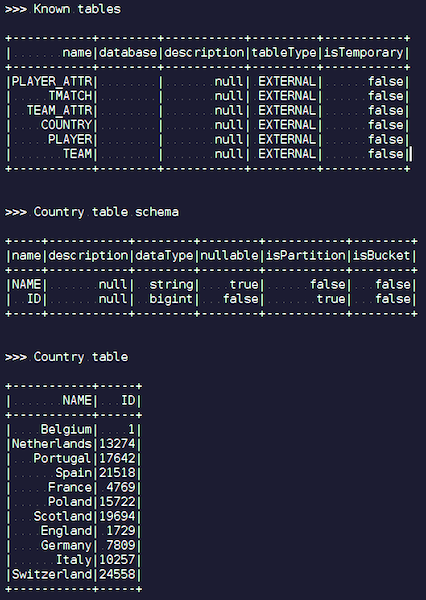
IgniteSparkSessionオブジェクトを作成するとすぐに、ディレクトリに、Igniteにロードしたばかりのすべてのテーブルが表示されます。 あなたは彼らの図とすべての情報を見ることができます。 SparkはIgniteのテーブルをすでに知っているため、すべてのデータを簡単に取得できます。
点火最適化
JOINを使用してIgniteで複雑なクエリを作成する場合、Sparkは最初にデータをプルし、次にJOINがそれらをグループ化します。 プロセスを最適化するために、IgniteOptimization機能を作成しました。Sparkクエリプランを最適化し、Ignite内で実行できるリクエストの部分をIgnite内で転送できるようにします。 特定のリクエストに対して最適化を示します。
SQL Query: SELECT city_id, count(*) FROM person p GROUP BY city_id HAVING count(*) > 1
私たちは要求を満たします。 個人テーブルがあります-一部の従業員、人々。 各従業員は、自分が住んでいる都市のIDを知っています。 各都市に何人住んでいるのか知りたいです。 複数の人が住んでいる都市でフィルタリングします。 Sparkが構築する初期計画は次のとおりです。
== Analyzed Logical Plan == city_id: bigint, count(1): bigint Project [city_id#19L, count(1)#52L] +- Filter (count(1)#54L > cast(1 as bigint)) +- Aggregate [city_id#19L], [city_id#19L, count(1) AS count(1)#52L, count(1) AS count(1)#54L] +- SubqueryAlias p +- SubqueryAlias person +- Relation[NAME#11,BIRTH_DATE#12,IS_RESIDENT#13,SALARY#14,PENSION#15,ACCOUNT#16,AGE#17,ID#18L,CITY_ID#19L] IgniteSQLRelation[table=PERSON]
リレーションは単なるIgniteテーブルです。 フィルターはありません-クラスターからネットワークを介してPersonテーブルのすべてのデータをポンプアウトするだけです。 次に、Sparkはこれらすべてを集約します-要求に従って、要求の結果を返します。
Ignite内でフィルターと集計を使用したこのサブツリーをすべて実行できることは簡単にわかります。 これは、Sparkの潜在的に大きなテーブルからすべてのデータをプルするよりもはるかに効果的です。これがIgniteOptimization機能の機能です。 ツリーを分析および最適化した後、次の計画を取得します。
== Optimized Logical Plan == Relation[CITY_ID#19L,COUNT(1)#52L] IgniteSQLAccumulatorRelation( columns=[CITY_ID, COUNT(1)], qry=SELECT CITY_ID, COUNT(1) FROM PERSON GROUP BY city_id HAVING count(1) > 1)
その結果、ツリー全体を最適化したため、1つのリレーションのみが取得されます。 内部では、Igniteが元のリクエストに十分近いリクエストを送信していることがすでにわかります。
さまざまなデータソースを結合するとします。たとえば、Igniteの1つのDataFrame、jsonの2つ目、Igniteの3つ目、何らかのリレーショナルデータベースの4つ目があるとします。 この場合、プランではサブツリーのみが最適化されます。 できることを最適化し、Igniteにドロップすると、Sparkが残りを行います。 これにより、速度が向上します。
JOINの別の例:
SQL Query - SELECT jt1.id as id1, jt1.val1, jt2.id as id2, jt2.val2 FROM jt1 JOIN jt2 ON jt1.val1 = jt2.val2
2つのテーブルがあります。 値、ID、値からすべてを選択します。 Sparkはそのような計画を提供します:
== Analyzed Logical Plan == id1: bigint, val1: string, id2: bigint, val2: string Project [id#4L AS id1#84L, val1#3, id#6L AS id2#85L, val2#5] +- Join Inner, (val1#3 = val2#5) :- SubqueryAlias jt1 : +- Relation[VAL1#3,ID#4L] IgniteSQLRelation[table=JT1] +- SubqueryAlias jt2 +- Relation[VAL2#5,ID#6L] IgniteSQLRelation[table=JT2]
彼は1つのテーブルからすべてのデータを取り出し、2番目のテーブルからすべてのデータを取り出し、自分の内部でそれらを結合し、結果を与えることがわかります。 処理と最適化の後、Igniteに送られる要求とまったく同じ要求を受け取り、比較的迅速に実行されます。
== Optimized Logical Plan == Relation[ID#84L,VAL1#3,ID#85L,VAL2#5] IgniteSQLAccumulatorRelation(columns=[ID, VAL1, ID, VAL2], qry= SELECT JT1.ID AS id1, JT1.VAL1, JT2.ID AS id2, JT2.VAL2 FROM JT1 JOIN JT2 ON JT1.val1 = JT2.val2 WHERE JT1.val1 IS NOT NULL AND JT2.val2 IS NOT NULL)
例を示します。
OptimizationExample.scala
IgniteSparkセッションを作成しています。このセッションでは、すべての最適化機能がすでに自動的に含まれています。 ここでの要求は次のとおりです。最高の評価を持つプレイヤーを見つけ、名前を表示します。 プレーヤーテーブルで、その属性とデータ。 参加し、ジャンクデータをフィルタリングし、最高評価のプレーヤーを表示しています。 最適化後に得られたプランを見て、このクエリの結果を示しましょう。
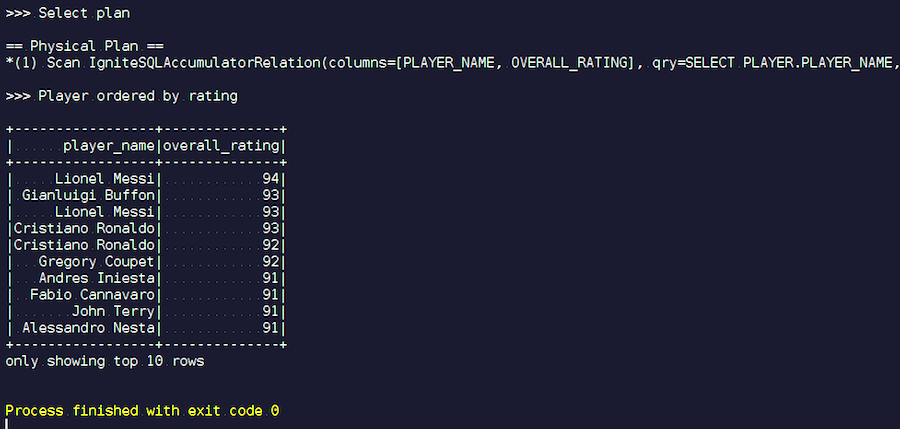
始めます。 メッシ、ブッフォン、ロナウドなど、よく知られた名前があります。 ちなみに、いくつかの理由で、メッシとロナウドの2つの装いで会います。 サッカー愛好家は、未知の選手がリストに載っていることを奇妙に感じるかもしれません。 これらは、他のプレーヤーを背景にした、かなり高い特性を持つプレーヤーであるゴールキーパーです。 次に、実行されたクエリプランを確認します。 Sparkでは、ほとんど何も行われませんでした。つまり、リクエスト全体をIgniteに再度送信しました。
Apache Ignite開発
私たちのプロジェクトはオープンソース製品なので、開発者からのパッチとフィードバックに常に満足しています。 あなたの助け、フィードバック、パッチは大歓迎です。 私たちは彼らを待っています。 Igniteコミュニティの90%はロシア語を話します。 たとえば、私にとって、Apache Igniteの作業を開始するまで、英語の最良の知識は抑止力ではありませんでした。 開発者リストにロシア語で書く価値はほとんどありませんが、何か間違ったことを書いたとしても、彼らが答えてくれます。
この統合で何を改善できますか? あなたがそのような欲求を持っている場合、どうすれば助けられますか? 以下のリスト。 アスタリスクは複雑さを示しています。

最適化をテストするには、複雑なクエリを使用してテストを作成する必要があります。 上記では、いくつかの明らかなクエリを示しました。 多数のグループ化と多数の結合を作成すると、何かが落ちてしまう可能性があることは明らかです。 これは非常に簡単なタスクです-やってみてください。 テスト結果に基づいてバグを見つけた場合は、修正する必要があります。 そこは難しくなります。
もう1つの明確で興味深いタスクは、Sparkとシンクライアントの統合です。 最初はIPアドレスのいくつかのセットを指定できます。これはIgniteクラスターに参加するのに十分であり、外部システムと統合する場合に便利です。 この問題の解決策に突然参加したい場合は、個人的にお手伝いします。
Apache Igniteコミュニティに参加したい場合、以下の便利なリンクをご覧ください。
- ここから開始-https://ignite.apache.org/community/resources.html
- ソースはこちら-https://github.com/apache/ignite/
- ドックはこちら-https ://apacheignite.readme.io/docs
- バグはこちら-https://issues.apache.org/jira/browse/IGNITE
- ここに書くことができます-dev @ ignite.apache.org、user @ ignite.apache.org
レスポンシブな開発者リストが用意されています。 まだ理想とはほど遠いですが、他のプロジェクトと比較すると、本当に活気があります。
JavaまたはC ++を知っている場合は、仕事を探しており、オープンソース(Apache Ignite、Apache Kafka、Tarantoolなど)を開発したいと考えています。ここに書いてください:join-open-source@sberbank.ru。