Motizukiの栄誉を主張することなく、仮説で約束された平等がどれだけ満たされているかをコンピューターで確認することにしました。 実際、そうではない-現代のプロセッサはゲームをプレイするだけではありません-その主な(計算)目的でコンピューターを使用しないのはなぜですか...
猫の下で、誰が何が起こったか気にしてください。
問題の声明
最初から始めましょう。 定理とは何ですか? ウィキペディアが言うように(英語版の表現はもう少し明確です)、相互に単純な(共通の除数がない)a、b、cの場合、a + b = c、ε> 0の場合、トリプルa + bの数は限られています = c、そのような:

rad関数はradicalと呼ばれ、数の素因数の積を示します。 たとえば、rad(16)= rad(2 * 2 * 2 * 2)= 2、rad(17)= 17(17は素数)、rad(18)= rad(2 * 3 * 3)= 2 * 3 = 6、rad(1,000,000)= rad(2 ^ 6⋅5 ^ 6)= 2 * 5 = 10。
実際、定理の本質は、そのようなトリプルの数が非常に少ないことです。 たとえば、ε= 0.2および等式100 + 27 = 127をランダムに取る場合、rad(100)= rad(2 * 2 * 5 * 5)= 10、rad(27)= rad(3 * 3 * 3)= 3 rad(127)= 127、rad(a * b * c)= rad(a)* rad(b)* rad(c)= 3810、3810 ^ 1.2は明らかに127より大きく、不等式は成り立ちません。 ただし、例外はあります。たとえば、49 + 576 = 625の等式の場合、定理の条件は満たされます(希望する人は自分で確認できます)。
定理によれば、次の重要な瞬間はこれらの平等の限られた数です。 つまり これは、単にコンピューター上でそれらをすべて整理しようとすることができることを意味しています。 その結果、これは
それでは始めましょう。
ソースコード
最初のバージョンはPythonで書かれており、この言語はこのような計算には遅すぎますが、コードを記述するのは簡単でシンプルで、プロトタイピングには便利です。
ラジカルを取得する :数を素因数に分解してから、繰り返しを削除し、配列をセットに変換します。 次に、すべての要素の積を取得します。
def prime_factors(n): factors = [] # Print the number of two's that divide n while n % 2 == 0: factors.append(int(2)) n = n / 2 # n must be odd at this point so a skip of 2 ( i = i + 2) can be used for i in range(3, int(math.sqrt(n)) + 1, 2): # while i divides n , print i ad divide n while n % i == 0: factors.append(int(i)) n = n / i # Condition if n is a prime number greater than 2 if n > 2: factors.append(int(n)) return set(factors) def rad(n): result = 1 for num in prime_factors(n): result *= num return result
相互に素数 : 数を因数分解し 、集合の共通部分をチェックします。
def not_mutual_primes(a,b,c): fa, fb, fc = prime_factors(a), prime_factors(b), prime_factors(c) return len(fa.intersection(fb)) == 0 and len(fa.intersection(fc)) == 0 and len(fb.intersection(fc)) == 0
チェック :既に作成された関数を使用します。ここではすべてが簡単です。
def check(a,b,c): S = 1.2 # Eps=0.2 if c > (rad(a)*rad(b)*rad(c))**S and not_mutual_primes(a, b, c): print("{} + {} = {} - PASSED".format(a, b, c)) else: print("{} + {} = {} - FAILED".format(a, b, c)) check(10, 17, 27) check(49, 576, 625)
希望する人は、上記のコードを任意のオンラインPython言語エディターにコピーして、自分で実験することができます。 もちろん、コードは期待どおりに実行され、すべてのトリプルを少なくとも100万個まで列挙するのは長すぎます。 ネタバレの下に最適化されたバージョンがあり、それを使用することをお勧めします。
最終バージョンは、マルチスレッドといくつかの最適化を使用してC ++で書き直されました(交差セットを使用したCでの作業はハードコアですが、おそらく高速になります)。 ソースコードはスポイラーの下にあり、無料のg ++コンパイラでコンパイルできます。コードはWindows、OSX、さらにはRaspberry Piでも動作します。
C ++コード
// To compile: g++ abc.cpp -O3 -fopenmp -oabc #include <string.h> #include <math.h> #include <stdbool.h> #include <stdint.h> #include <stdio.h> #include <vector> #include <set> #include <map> #include <algorithm> #include <time.h> typedef unsigned long int valType; typedef std::vector<valType> valList; typedef std::set<valType> valSet; typedef valList::iterator valListIterator; std::vector<valList> valFactors; std::vector<double> valRads; valList factors(valType n) { valList results; valType z = 2; while (z * z <= n) { if (n % z == 0) { results.push_back(z); n /= z; } else { z++; } } if (n > 1) { results.push_back(n); } return results; } valList unique_factors(valType n) { valList results = factors(n); valSet vs(results.begin(), results.end()); valList unique(vs.begin(), vs.end()); std::sort(unique.begin(), unique.end()); return unique; } double rad(valType n) { valList f = valFactors[n]; double result = 1; for (valListIterator it=f.begin(); it<f.end(); it++) { result *= *it; } return result; } bool not_mutual_primes(valType a, valType b, valType c) { valList res1 = valFactors[a], res2 = valFactors[b], res3; // = valFactors[c]; valList c12, c13, c23; set_intersection(res1.begin(),res1.end(), res2.begin(),res2.end(), back_inserter(c12)); if (c12.size() != 0) return false; res3 = valFactors[c]; set_intersection(res1.begin(),res1.end(), res3.begin(),res3.end(), back_inserter(c13)); if (c13.size() != 0) return false; set_intersection(res2.begin(),res2.end(), res3.begin(),res3.end(), back_inserter(c23)); return c23.size() == 0; } int main() { time_t start_t, end_t; time(&start_t); int cnt=0; double S = 1.2; valType N_MAX = 10000000; printf("Getting prime factors...\n"); valFactors.resize(2*N_MAX+2); valRads.resize(2*N_MAX+2); for(valType val=1; val<=2*N_MAX+1; val++) { valFactors[val] = unique_factors(val); valRads[val] = rad(val); } time(&end_t); printf("Done, T = %.2fs\n", difftime(end_t, start_t)); printf("Calculating...\n"); #pragma omp parallel for reduction(+:cnt) for(int a=1; a<=N_MAX; a++) { for(int b=a; b<=N_MAX; b++) { int c = a+b; if (c > pow(valRads[a]*valRads[b]*valRads[c], S) && not_mutual_primes(a,b,c)) { printf("%d + %d = %d\n", a,b,c); cnt += 1; } } } printf("Done, cnt=%d\n", cnt); time(&end_t); float diff_t = difftime(end_t, start_t); printf("N=%lld, T = %.2fs\n", N_MAX, diff_t); }
C ++コンパイラをインストールするのが面倒な人のために、少し最適化されたPythonバージョンが提供されており、任意のオンラインエディタで実行できます( https://repl.it/languages/pythonを使用しました)。
Pythonバージョン
from __future__ import print_function import math import time import multiprocessing prime_factors_list = [] rad_list = [] def prime_factors(n): factors = [] # Print the number of two's that divide n while n % 2 == 0: factors.append(int(2)) n = n / 2 # n must be odd at this point so a skip of 2 ( i = i + 2) can be used for i in range(3, int(math.sqrt(n)) + 1, 2): # while i divides n , print i ad divide n while n % i == 0: factors.append(int(i)) n = n / i # Condition if n is a prime number greater than 2 if n > 2: factors.append(int(n)) return factors def rad(n): result = 1 for num in prime_factors_list[n]: result *= num return result def not_mutual_primes(a,b,c): fa, fb, fc = prime_factors_list[a], prime_factors_list[b], prime_factors_list[c] return len(fa.intersection(fb)) == 0 and len(fa.intersection(fc)) == 0 and len(fb.intersection(fc)) == 0 def calculate(N): S = 1.2 cnt = 0 for a in range(1, N): for b in range(a, N): c = a+b if c > (rad_list[a]*rad_list[b]*rad_list[c])**S and not_mutual_primes(a, b, c): print("{} + {} = {}".format(a, b, c)) cnt += 1 print("N: {}, CNT: {}".format(N, cnt)) return cnt if __name__ == '__main__': t1 = time.time() NMAX = 100000 prime_factors_list = [0]*(2*NMAX+2) rad_list = [0]*(2*NMAX+2) for p in range(1, 2*NMAX+2): prime_factors_list[p] = set(prime_factors(p)) rad_list[p] = rad(p) calculate(NMAX) print("Done", time.time() - t1)
結果
トリプルa、b、cは実際にはごくわずかです。
以下にいくつかの結果を示します。
N = 10 :1「3」、リードタイム<0.001c
1 + 8 = 9
N = 100 :2“トリプル”、ランタイム<0.001c
1 + 8 = 9
1 + 80 = 81
N = 1000 :8「トリプル」、ランタイム<0.01c
1 + 8 = 9
1 + 80 = 81
1 + 242 = 243
1 + 288 = 289
1 + 512 = 513
3 + 125 = 128
13 + 243 = 256
49 + 576 = 625
N = 10000 :23「トリプル」、ランタイム2秒
スリーA、B、C最大10000
1 + 8 = 9
1 + 80 = 81
1 + 242 = 243
1 + 288 = 289
1 + 512 = 513
1 + 2400 = 2401
1 + 4374 = 4375
1 + 5831 = 5832
1 + 6560 = 6561
1 + 6655 = 6656
1 + 6859 = 6860
3 + 125 = 128
5 + 1024 = 1029
10 + 2187 = 2197
11 + 3125 = 3136
13 + 243 = 256
49 + 576 = 625
1331 + 9604 = 10935
81 + 1250 = 1331
125 + 2187 = 2312
243 + 1805 = 2048
289 + 6272 = 6561
625 + 2048 = 2673
N = 100000 :53「トリプル」、ランタイム50c
スリーA、B、C最大100,000
1 + 8 = 9
1 + 80 = 81
1 + 242 = 243
1 + 288 = 289
1 + 512 = 513
1 + 2400 = 2401
1 + 4374 = 4375
1 + 5831 = 5832
1 + 6560 = 6561
1 + 6655 = 6656
1 + 6859 = 6860
1 + 12167 = 12168
1 + 14336 = 14337
1 + 57121 = 57122
1 + 59048 = 59049
1 + 71874 = 71875
3 + 125 = 128
3 + 65533 = 65536
5 + 1024 = 1029
7 + 32761 = 32768
9 + 15616 = 15625
9 + 64000 = 64009
10 + 2187 = 2197
11 + 3125 = 3136
13 + 243 = 256
28 + 50625 = 50653
31 + 19652 = 19683
37 + 32768 = 32805
49 + 576 = 625
49 + 16335 = 16384
73 + 15552 = 15625
81 + 1250 = 1331
121 + 12167 = 12288
125 + 2187 = 2312
125 + 50176 = 50301
128 + 59049 = 59177
169 + 58880 = 59049
243 + 1805 = 2048
243 + 21632 = 21875
289 + 6272 = 6561
343 + 59049 = 59392
423 + 16384 = 16807
507 + 32768 = 33275
625 + 2048 = 2673
1331 + 9604 = 10935
1625 + 16807 = 18432
28561 + 89088 = 117649
28561 + 98415 = 126976
3584 + 14641 = 18225
6561 + 22000 = 28561
7168 + 78125 = 85293
8192 + 75843 = 84035
36864 + 41261 = 78125
N = 1,000,000の場合、 102個の「トリプル」しかなく、完全なリストがネタバレの下に表示されます。
スリーA、B、C最大1,000,000
1 + 8 = 9
1 + 80 = 81
1 + 242 = 243
1 + 288 = 289
1 + 512 = 513
1 + 2400 = 2401
1 + 4374 = 4375
1 + 5831 = 5832
1 + 6560 = 6561
1 + 6655 = 6656
1 + 6859 = 6860
1 + 12167 = 12168
1 + 14336 = 14337
1 + 57121 = 57122
1 + 59048 = 59049
1 + 71874 = 71875
1 + 137780 = 137781
1 + 156249 = 156250
1 + 229375 = 229376
1 + 263168 = 263169
1 + 499999 = 500000
1 + 512000 = 512001
1 + 688127 = 688128
3 + 125 = 128
3 + 65533 = 65536
5 + 1024 = 1029
5 + 177147 = 177152
7 + 32761 = 32768
9 + 15616 = 15625
9 + 64000 = 64009
10 + 2187 = 2197
11 + 3125 = 3136
13 + 243 = 256
13 + 421875 = 421888
17 + 140608 = 140625
25 + 294912 = 294937
28 + 50625 = 50653
31 + 19652 = 19683
37 + 32768 = 32805
43 + 492032 = 492075
47 + 250000 = 250047
49 + 576 = 625
49 + 16335 = 16384
49 + 531392 = 531441
64 + 190269 = 190333
73 + 15552 = 15625
81 + 1250 = 1331
81 + 123823 = 123904
81 + 134375 = 134456
95 + 279841 = 279936
121 + 12167 = 12288
121 + 255879 = 256000
125 + 2187 = 2312
125 + 50176 = 50301
128 + 59049 = 59177
128 + 109375 = 109503
128 + 483025 = 483153
169 + 58880 = 59049
243 + 1805 = 2048
243 + 21632 = 21875
289 + 6272 = 6561
338 + 390625 = 390963
343 + 59049 = 59392
423 + 16384 = 16807
507 + 32768 = 33275
625 + 2048 = 2673
864 + 923521 = 924385
1025 + 262144 = 263169
1331 + 9604 = 10935
1375 + 279841 = 281216
1625 + 16807 = 18432
2197 + 583443 = 585640
2197 + 700928 = 703125
3481 + 262144 = 265625
3584 + 14641 = 18225
5103 + 130321 = 135424
6125 + 334611 = 340736
6561 + 22000 = 28561
7153 + 524288 = 531441
7168 + 78125 = 85293
8192 + 75843 = 84035
8192 + 634933 = 643125
9583 + 524288 = 533871
10816 + 520625 = 531441
12005 + 161051 = 173056
12672 + 117649 = 130321
15625 + 701784 = 717409
18225 + 112847 = 131072
19683 + 228125 = 247808
24389 + 393216 = 417605
28561 + 89088 = 117649
28561 + 98415 = 126976
28561 + 702464 = 731025
32768 + 859375 = 892143
296875 + 371293 = 668168
36864 + 41261 = 78125
38307 + 371293 = 409600
303264 + 390625 = 693889
62192 + 823543 = 885735
71875 + 190269 = 262144
131072 + 221875 = 352947
132651 + 588245 = 720896
残念ながら、プログラムはまだゆっくりと動作し、N = 10,000,000の結果を待たず、計算時間は1時間以上です(どこかでアルゴリズムの最適化を間違えた可能性があります。
さらに興味深いのは、結果をグラフィカルに見ることです。
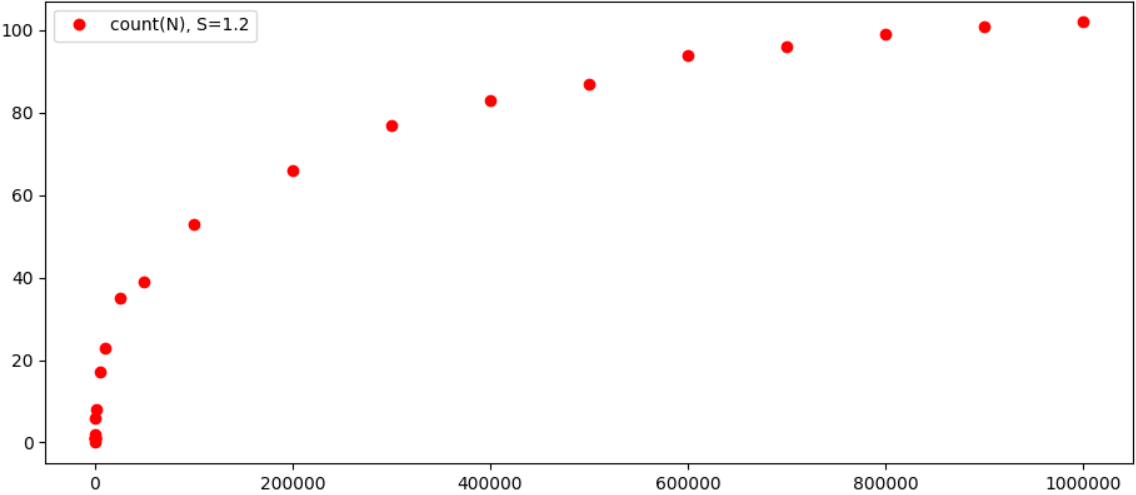
原則として、可能なトリプルの数のNへの依存性がN自体よりも著しく遅くなることは非常に明白であり、結果は各εの特定の数に収束する可能性があります。 ところで、εが増加すると、トリプルの数が著しく減少します。たとえば、ε= 0.4の場合、N <100000(1 + 4374 = 4375および343 + 59049 = 59392)に対して2つの等式しかありません。 そのため、一般に、定理は本当に成り立っているようです(まあ、おそらく、より強力なコンピューターで既にテストされており、おそらくこれはすべて長い間計算されています)。
希望する人は自分で実験することができます。誰かが10,000,000以上の数字の結果を持っているなら、私は喜んでそれらを記事に加えます。 もちろん、「トリプル」のセットが完全に成長を停止する瞬間まで「カウント」することは興味深いでしょうが、非常に長い時間がかかる可能性があり、計算速度はNにN * N(またはN ^ 3)とても長い。 それにもかかわらず、驚くべきものが近くにあり、希望する人は検索に参加することができます。
編集:コメントで示唆されているように、ウィキペディアには結果の表がすでにあります-Nから10 ^ 18の範囲で「トリプル」の数はまだ増え続けているため、セットの「終わり」はまだ見つかりません。 さらに興味深いことに、陰謀は依然として保存されています。