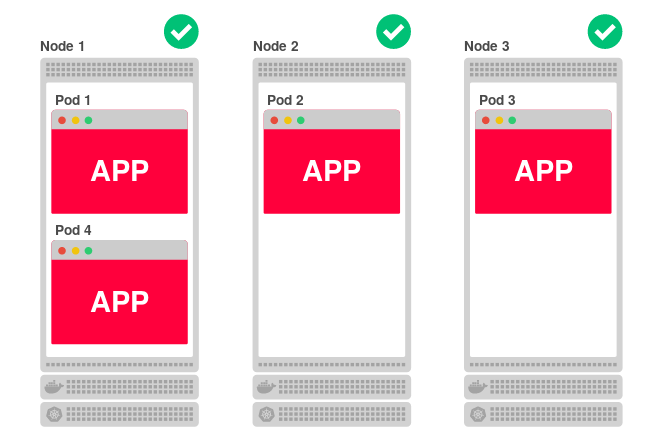
Kubernetesにデプロイされたアプリケーションのコードは、1つ以上の作業ノードで実行されます。 ノードは、物理マシンまたは仮想マシン、またはAWS EC2またはGoogle Compute Engineのいずれかに配置できます。このようなサイトが多数存在するため、アプリケーションを効果的に起動およびスケーリングできます。 たとえば、クラスターが3つのノードで構成されており、アプリケーションを4つのレプリカにスケーリングする場合、Kubernetesは次のようにノード間でそれらを均等に分散します。
そのようなアーキテクチャはうまく機能します。 1つのノードが使用できない場合、アプリケーションは他の2つのノードで引き続き動作します。 一方、Kubernetesは4番目のレプリカを別の(使用可能な)ノードに再割り当てします。
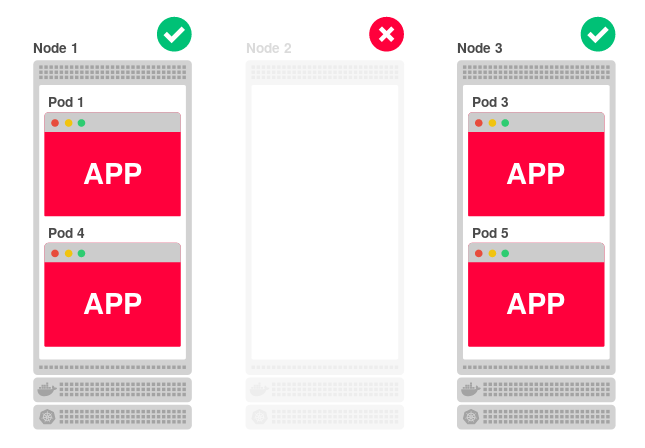
さらに、すべてのノードが分離されていても、リクエストを処理できます。 たとえば、アプリケーションレプリカの数を2つに減らします。
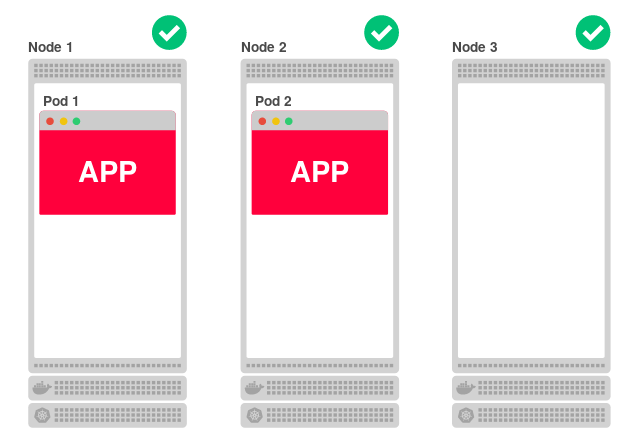
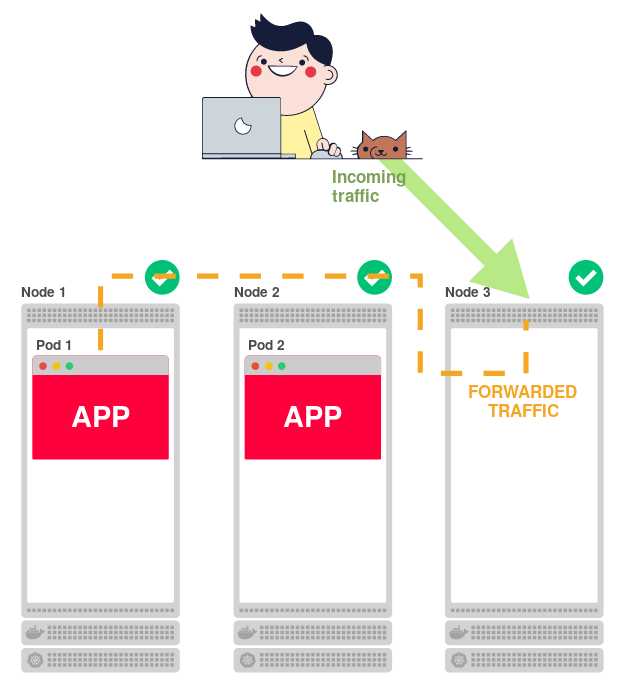
各ノードがアプリケーションを提供できるため、3番目(ノード3)は、アプリケーションが実行されておらず、他のノードの1つにトラフィックをリダイレクトする必要があることをどのように知るのですか

Kubernetesには、各ノードで実行される
kube-proxy
バイナリがあり、トラフィックを特定のサブにルーティングします。 ホテルの受付係と比較できます。
Kube-proxy
は、ノードに着信するすべてのトラフィックを受け入れ、正しいトラフィックに転送します。
しかし、 kube-proxy
は、すべてのポッドがどこにあるかをどのように知るのでしょうか?
彼は知りません。
しかし、彼はすべてのルーティングルールのリストを作成するメイン(マスター)ノードのすべてについて知っています。 そして
kube-proxy
はこれらのルールをチェックし、それらを実施
kube-proxy
ます。 上記の簡単なシナリオでは、ルールのリストは次のとおりです。
- 最初のアプリケーションレプリカはノード1 (ノード1)で利用可能です。
- 2番目のアプリケーションレプリカはノード2 (ノード2)で利用可能です。
トラフィックの
kube-proxy
ノードは関係ありません
kube-proxy
、このルールのリストに従ってトラフィックをリダイレクトする場所を認識しています。
しかし、kube-proxyがクラッシュするとどうなりますか?
そして、ルールのリストが消えたらどうしますか?
トラフィックを転送するルールがない場合はどうなりますか?
酒井学も同じ質問をしました。 そして彼はそれを理解することにしました。
GCPに2つのノードのクラスターがあるとします。
$ kubectl get nodes NAME STATUS ROLES AGE VERSION node1 Ready <none> 17h v1.8.8-gke.0 node2 Ready <none> 18h v1.8.8-gke.0
そして、あなたはManabuアプリをデプロイしています:
$ kubectl create -f https://raw.githubusercontent.com/manabusakai/k8s-hello-world/master/kubernetes/deployment.yml $ kubectl create -f https://raw.githubusercontent.com/manabusakai/k8s-hello-world/master/kubernetes/service.yml
これは、現在の囲炉裏のホスト名をWebページに表示する単純なアプリケーションです。
10個のレプリカにスケールします( Deployment ):
$ kubectl scale --replicas 10 deployment/k8s-hello-world
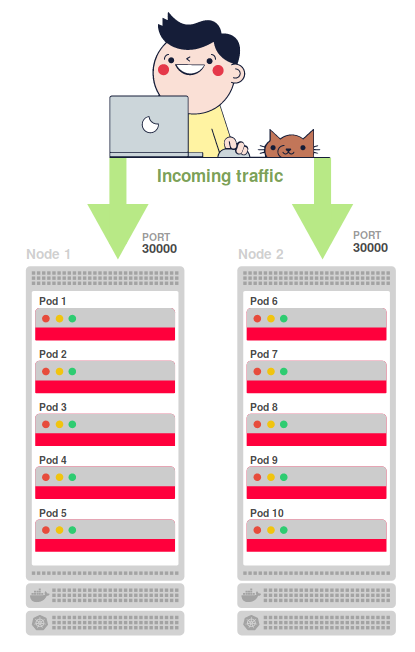
10個のレプリカが2つのノード( node1およびnode2 )に均等に分散されています 。
$ kubectl get pods NAME READY STATUS NODE k8s-hello-world-55f48f8c94-7shq5 1/1 Running node1 k8s-hello-world-55f48f8c94-9w5tj 1/1 Running node1 k8s-hello-world-55f48f8c94-cdc64 1/1 Running node2 k8s-hello-world-55f48f8c94-lkdvj 1/1 Running node2 k8s-hello-world-55f48f8c94-npkn6 1/1 Running node1 k8s-hello-world-55f48f8c94-ppsqk 1/1 Running node2 k8s-hello-world-55f48f8c94-sc9pf 1/1 Running node1 k8s-hello-world-55f48f8c94-tjg4n 1/1 Running node2 k8s-hello-world-55f48f8c94-vrkr9 1/1 Running node1 k8s-hello-world-55f48f8c94-xzvlc 1/1 Running node2

サービスは、10個のレプリカにわたる要求からの負荷を分散するために作成されます。
$ kubectl get services NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE k8s-hello-world NodePort 100.69.211.31 <none> 8080:30000/TCP 3h kubernetes ClusterIP 100.64.0.1 <none> 443/TCP 18h
NodePort
を介して外部に転送され、ポート30000でアクセス可能です。つまり、各ノードで、外部インターネット用にポート30000が開き、着信トラフィックの受信を開始します。
しかし、トラフィックはどのようにしてポート30,000から炉床にルーティングされますか?
kube-proxy
は、ポート30000から10個のポッドの1つへの着信トラフィックのルールを設定します。
いずれかのノードのポート30,000にリクエストを送信してみてください。
$ curl <node ip>:30000
注 :ホストIPアドレスは、
kubectl get nodes -o wide
コマンドで
kubectl get nodes -o wide
できます。
アプリケーションは「Hello world!」で応答し、アプリケーションが実行されているコンテナのホスト名:
Hello world! via <hostname>
Hello world! via <hostname>
。
同じURLを再リクエストすると、同じ回答が表示される場合と、変更される場合があります。 その理由は、
kube-proxy
ロードバランサーとして機能し、ルーティングをチェックし、10個のセクションにトラフィックを分散させるためです。
興味深いことに、あなたがどのノードを参照しているかは関係ありません。答えはどのポッドからでも-他のノードにあるもの(あなたが向けたものではない)からのものです。
最終構成では、外部ロードバランサーを使用する必要があります。これにより、ノード間でトラフィックが分散されます(ポート30000上)。 最終的なクエリフロースキームは次のようになります。
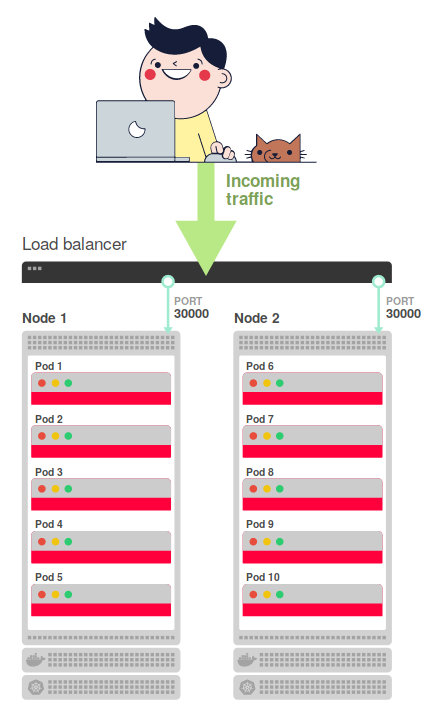
つまり、ロードバランサーは、インターネットからの着信トラフィックを2つのノードのいずれかにリダイレクトします。 このスキーム全体を明確にします-その動作の原理を要約します:
- インターネットからのトラフィックは、メインのロードバランサーに向けられます。
- このバランサーは、2つのノードのいずれかのポート30000にトラフィックを転送します。
-
kube-proxy
によって設定されたルールは、ホストからサブにトラフィックをリダイレクトします。 - トラフィックが下に落ちる。
これが全体のスキームです!
それをすべて分解する時です
すべてが相互作用する方法がわかったので、元の質問に戻りましょう。 ルーティングルールを変更するとどうなりますか? クラスターは引き続き機能しますか? ポッドはリクエストに対応しますか?
ルーティングルールを削除し、別のターミナルで-アプリケーションの応答時間と要求の欠落を監視します。 後者の場合、1秒ごとに現在の時刻を表示してアプリケーションに要求を行うループを作成するだけで十分です。
$ while sleep 1; do date +%X; curl -sS http://<your load balancer ip>/ | grep ^Hello; done
出力では、囲炉裏から時間と応答テキストを含む列を取得します。
10:14:41 Hello world! via k8s-hello-world-55f48f8c94-vrkr9 10:14:43 Hello world! via k8s-hello-world-55f48f8c94-tjg4n
それでは、ホストからルーティングルールを削除しましょうが、最初にこれを行う方法を考えましょう。
kube-proxy
は、 userspace 、 iptablesおよびipvsの 3つのモードで動作できます。 Kubernetes 1.2以降のデフォルトモードはiptablesです。 ( 注 :最後のモードipvsは、 K8s 1.8リリースで登場し、 1.9でベータステータスを受け取りました。)
iptablesモードでは、
kube-proxy
はiptablesルールを使用してホスト上のルーティングルールをリストします。 したがって、
iptables -F
コマンドを使用して、任意のノードに移動してこれらのルールを削除できます。
注 :
iptables -F
を呼び出すと、SSH接続が切断される可能性があることに注意してください。
すべてが計画どおりに進んだ場合、次のようなものが表示されます。
10:14:41 Hello world! via k8s-hello-world-55f48f8c94-xzvlc 10:14:43 Hello world! via k8s-hello-world-55f48f8c94-tjg4n # `iptables -F` 10:15:10 Hello world! via k8s-hello-world-55f48f8c94-vrkr9 10:15:11 Hello world! via k8s-hello-world-55f48f8c94-vrkr9
すぐにわかるように、iptablesルールがリセットされてから次の回答まで約27秒(10:14:43から10:15:10まで)かかりました。
この間に何が起きましたか? 27秒後にすべてが正常になったのはなぜですか? たぶんこれは単なる偶然でしょうか?
再びルールをリセットしましょう。
11:29:55 Hello world! via k8s-hello-world-55f48f8c94-xzvlc 11:29:56 Hello world! via k8s-hello-world-55f48f8c94-tjg4n # `iptables -F` 11:30:25 Hello world! via k8s-hello-world-55f48f8c94-npkn6 11:30:27 Hello world! via k8s-hello-world-55f48f8c94-vrkr9
11:29:56から11:30:25までの29秒の一時停止が表示されます。 しかし、クラスターは再び機能するようになりました。
応答に30秒かかるのはなぜですか? ルーティングテーブルがなくても、要求はノードに届きますか?
この30秒間にノードで何が起こるかを確認できます。 別のターミナルで、アプリケーションに毎秒リクエストを行うループを実行しますが、今回は、ロードバランサーではなくノードにアクセスします。
$ while sleep 1; printf %"s\n" $(curl -sS http://<ip of the node>:30000); done
そして、iptablesルールを再度リセットします。 次のログを取得します。
Hello world! via k8s-hello-world-55f48f8c94-xzvlc Hello world! via k8s-hello-world-55f48f8c94-tjg4n # `iptables -F` curl: (28) Connection timed out after 10003 milliseconds curl: (28) Connection timed out after 10004 milliseconds Hello world! via k8s-hello-world-55f48f8c94-npkn6 Hello world! via k8s-hello-world-55f48f8c94-vrkr9
ルールをリセットした後、ホストへの接続がタイムアウトすることは驚くことではありません。 しかし、
curl
が10秒の応答を待つのは興味深いことです。
しかし、前の例でロードバランサーが新しい接続を待機している場合はどうでしょうか。 これは30秒の遅延を説明しますが、十分に長い待機の後、ノードが接続を受け入れる準備ができている理由は明確ではありません。
では、なぜ30秒後に再びトラフィックが流れるのでしょうか? 誰がiptablesルールを復元しますか?
iptablesルールをリセットする前に、それらを見ることができます:
$ iptables -L
ルールをリセットし、このコマンドの実行を続けます-数秒でルールが復元されることがわかります。
あなたは
kube-proxy
ですか? はい! 公式のkube-proxyドキュメントには、2つの興味深いフラグがあります。
-
--iptables-sync-period
-iptablesルールが更新される最大間隔(例:「5s」、「1m」、「2h22m」)。 0より大きくなければなりません。デフォルトは30秒です。 -
--iptables-min-sync-period
エンドポイントおよびサービスへの変更が発生したときにiptablesルールが更新される最小間隔(例:「5s」、「1m」、「2h22m」)。 デフォルトは10秒です。
つまり、
kube-proxy
iptablesルールを10〜30秒ごとに更新します。 iptablesルールをリセットすると、
kube-proxy
がこれを認識して復元するまでに最大30秒かかります。
そのため、ノードが再び機能するまでに約30秒かかりました。 また、ルーティングテーブルがマスターノードからワーカーノードに到達する方法についても説明します。 それらは
kube-proxy
によって定期的に同期されます。 つまり、炉床を追加または削除するたびに、メインノードはルートのリストをやり直し、
kube-proxy
は規則を現在のノードと定期的に同期します。
そのため、ホスト上のiptablesルールを誰かが台無しにした場合にKubernetesと
kube-proxy
どのように復元されるかをまとめます。
- iptablesルールはホストから削除されました。
- 要求はロードバランサーに送信され、ノードにルーティングされます。
- ノードは着信要求を受け入れないため、バランサーは待機しています。
- 30秒後、
kube-proxy
はiptablesルールを復元します。 - ホストは再びトラフィックを受信できます。 Iptablesルールは、バランサー要求をsubにリダイレクトします。
- Underは、30秒の合計遅延でロードバランサーを満たします。
30秒の待機は、アプリケーションでは受け入れられない場合があります。 この場合、
kube-proxy
標準更新間隔の変更を検討する必要があります。 これらの設定はどこにあり、どのように変更するのですか?
ノードにエージェント-kubelet-があり、各ノードで静的炉床として
kube-proxy
を起動するのは彼です。 静的な提出に関するドキュメントは、kubeletが特定のディレクトリの内容をチェックし、そこからすべてのリソースを作成することを示唆しています。
ノードで実行されているkubeletプロセスを見ると、フラグ
--pod-manifest-path=/etc/kubernetes/manifests
実行されていることがわかります。 小学校の
ls
は秘密のベールを開きます:
$ ls -l /etc/kubernetes/manifests total 4 -rw-r--r-- 1 root root 1398 Feb 24 08:08 kube-proxy.manifest
この
kube-proxy.manifest
は何が含まれていますか?
apiVersion: v1 kind: Pod metadata: name: kube-proxy spec: hostNetwork: true containers: - name: kube-proxy image: gcr.io/google_containers/kube-proxy:v1.8.7-gke.1 command: - /bin/sh - -c -> echo -998 > /proc/$$$/oom_score_adj && exec kube-proxy --master=https://35.190.207.197 --kubeconfig=/var/lib/kube-proxy/kubeconfig --cluster-cidr=10.4.0.0/14 --resource-container="" --v=2 --feature-gates=ExperimentalCriticalPodAnnotation=true --iptables-sync-period=30s 1>>/var/log/kube-proxy.log 2>&1
注 :簡単にするために、ファイルの内容はここでは完全ではありません。
謎は解決しました! ご覧のとおり、
--iptables-sync-period=30s
オプションは30秒ごとに使用され、iptablesルールを更新します。 ここで、特定のノードでルールを更新するための最小時間と最大時間を変更できます。
結論
iptablesルールをリセットすると、ホストにアクセスできなくなります。 トラフィックは引き続きノードに送信されますが、それ以上(つまり、サブに)転送することはできません。 Kubernetesは、ルーティングルールを監視し、必要に応じて更新することにより、このような問題から回復できます。
このテキストに多くの点でインスピレーションを与えたブログ投稿の酒井学 、およびウィザードから他のサイトへのiptablesルールの転送の問題を研究してくれたValentin Ouvrardに感謝します。
翻訳者からのPS
ブログもご覧ください。
- “ Kubernetesでのネットワーキングの図解ガイド ”;
- “ Kubernetesでの高可用性の提供方法 ”;
- “ Kubernetesの信頼性の向上:ノードが落ちたことに素早く気付く方法 ”;
- 「kubectlの実行が開始されるとKubernetesで何が起こりますか?」: パート1およびパート2 ;
- 「 Kubernetesスケジューラは実際にどのように機能しますか?」 ";
- 「 小規模プロジェクトでのKubernetesでの経験 」 (ビデオレポート、Kubernetesの技術デバイスの紹介を含む) 。
- 「 Container Networking Interface(CNI)は、Linuxコンテナのネットワークインターフェイスおよび標準です 。」