
GridGainとHadoopベースのストレージ(HDFS + HBASE)の統合プロジェクトの一環として、1日あたり最大約80 Tbの大量のデータを取得および処理するタスクに直面しました。 これは、ストアフロントを構築したり、長期保管にアップロードされた後にGridGainで削除されたデータを回復するために必要です。 一般的に言えば、分散データ伝送システムを使用して2つの分散データ処理システム間でデータを転送すると言えます。 したがって、このタスクの実装中にチームが遭遇した問題と、それらの解決方法についてお話したいと思います。
統合ツールはkafka(Mikhail Golovanovの記事で詳細に説明されています)であるため、ここではSparkStreamingの使用が自然で簡単な解決策であると思われます。 クラッシュ、再接続、コミットなどについて心配する必要がないため、簡単です。 Sparkは、多数の最適化のおかげで、従来のMapReduceの迅速な代替手段として知られています。 トピックに合わせて、バッチを処理し、実装したファイルに保存するだけです。 ただし、開発およびテスト中に、データ受信モジュールの不安定性に気付きました。 コード内の潜在的なエラーの影響を排除するために、次の実験が実行されました。 すべてのメッセージ処理機能が切断され、直接保存のみがavroにすぐに残りました。
JavaRDD<AvroWrapper<GenericRecord>> map = rdd.map(messageTuple -> { SeekableByteArrayInput sin = new SeekableByteArrayInput(messageTuple.value()); DataFileReader dataFileReader = new DataFileReader<>(sin, new GenericDatumReader<>()); GenericRecord record = (GenericRecord) dataFileReader.next(); return new AvroWrapper<>(record); }); Timestamp ts = new Timestamp(System.currentTimeMillis()); map.mapToPair(recordAvroWrapper -> new Tuple2<AvroWrapper<GenericRecord>, NullWritable>(recordAvroWrapper, NullWritable.get())) .saveAsHadoopFile("/tmp/SSTest/" + ts.getTime(), AvroWrapper.class, NullWritable.class, AvroOutputFormat.class, jobConf);
すべてのテストはそのようなスタンドで行われました。

結局のところ、他の人のタスクから解放されたクラスター上ですべてが正常に機能し、かなり良い速度を得ることができます。 ただし、他のアプリケーションと同時に作業する場合、非常に大きな遅延が観察されることが判明しました。 さらに、約150 MB /秒のとんでもない速度でも問題が発生します。 うつ病から火花が出て、失われた時間に追いつくこともありますが、次のように起こることもあります。
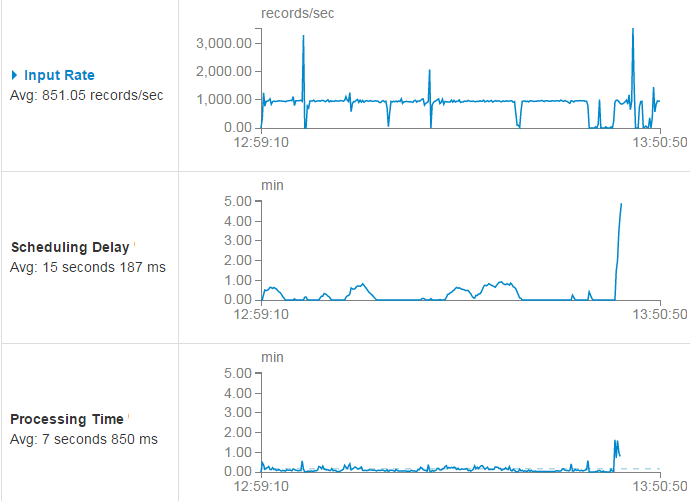
1秒あたり約1000メッセージ(入力レート)の受信レートでは、いくつかのドローダウンの後、バッチの処理開始の遅延(スケジューリング遅延)が通常(グラフの中央部分)に戻ったことがわかります。 しかし、ある時点で、処理時間が許容範囲を超え、火花の魂は地上のテストに合格せず、空に急いで行きました。
これがインドの第一人者の規範であることは明らかですが、私たちのPROMはアシュラムに含まれていないため、これは特に受け入れられません。 問題がデータストレージ関数にないことを確認するために、Datasetラッパーを使用できます-最適化されているようです。 したがって、次のコードを試します。
JavaRDD<Row> rows = rdd.map(messageTuple -> { try (SeekableByteArrayInput sin = new SeekableByteArrayInput(messageTuple.value()); DataFileReader dataFileReader = new DataFileReader<>(sin, new GenericDatumReader<>())) { GenericRecord record = (GenericRecord) dataFileReader.next(); Object[] values = new Object[]{ record.get("field_1"), … record.get("field_N")}; return new GenericRowWithSchema(values, getSparkSchema(ReflectData.get().getSchema(SnapshotContainer.class))); } }); StructType st = (StructType) SchemaConverters.toSqlType(schm).dataType(); Dataset<Row> batchDs = spark.createDataFrame(rows, st); Timestamp ts = new Timestamp(System.currentTimeMillis()); batchDs .write() .mode(SaveMode.Overwrite) .format("com.databricks.spark.avro") .save("/tmp/SSTestDF/" + ts.getTime());
そして、まったく同じ問題が発生します。 また、異なるクラスターで2つのバージョンを同時に実行すると、問題はより負荷の高いクラスターで機能するバージョンでのみ発生しました。 これは、問題がkafkaではなく、データストレージ機能の詳細にないことを意味していました。 また、テストでは、同じクラスターでflumeを使用して、SSが同時に機能する同じトピックを読んだ場合、データ抽出で同じスローダウンが得られたことが示されました。
トピック1、クラスター1、SparkSreaming-スローダウン
トピック2、クラスター1、Flume-スローダウン
Topic2、Cluster2、SparkSreaming-スローダウンなし
つまり、問題は正確にクラスターのバックグラウンド負荷にありました。 したがって、タスクは、負荷の高い環境で確実に動作するアプリケーションを作成することでした。また、上記のテストにはデータ処理ロジックがまったく含まれていないため、これはすべて複雑でした。 実際のプロセスは次のようになります。
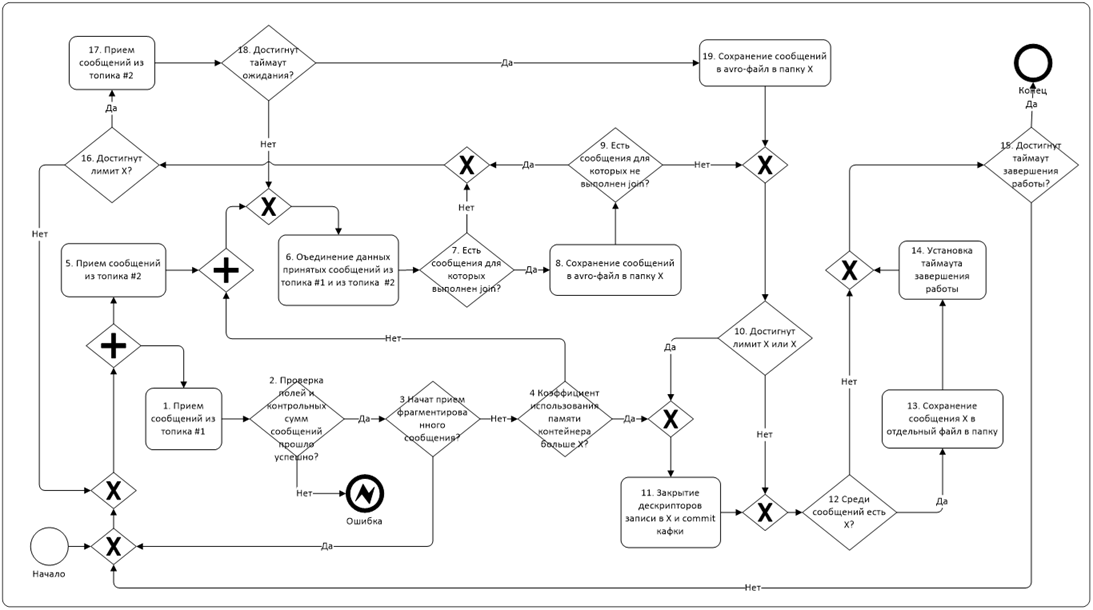
ここでの主な難点は、2つのトピック(1つの小さなデータストリームと2番目の大きなデータストリーム)から同時にデータを収集し、それらをオンザフライで結合するタスクです。 また、1つのバッチから異なるファイルに同時にデータを書き込む必要がありました。 スパークでは、これはシリアライズ可能なクラスを使用して実装され、メッセージ受信マップからそのメソッドを呼び出しました。 時々、火花が落ち、トピックから腐ったメッセージを読み取ろうとして、オフセットをhbaseに格納し始めました。 ある時点で、私たちはある種の切望と苦しみに苦しむ結果の怪物を見始めました。
したがって、私たちは力の明るい側、つまり、温かい管のジャワに目を向けることにしました。 幸いなことに、我々は機敏であり、何らかの理由であなたがしたくないときに

ただし、このためには、複数のノードからの分散メッセージ受信の問題を一度に解決する必要があります。 このために、Spring for Apache Hadoopフレームワークが選択されました。これにより、必要な数のYarnコンテナーを実行し、それぞれで独自のコードを実行できます。
彼の作品の一般的な論理は次のとおりです。 YARNコンテナーのコーディネーターであるAppMasterが起動します。 つまり、彼はそれらを起動し、必要なパラメータを入力として渡し、実行のステータスを監視します。 コンテナがクラッシュした場合(たとえば、OutOfMemoryにより)、コンテナを再起動またはシャットダウンする場合があります。
コンテナ内で直接、Kafkaとデータ処理を操作するロジックが実装されます。 YARNはクラスターノードをほぼ均一に分散してコンテナーを起動するため、ネットワークトラフィックやディスクアクセスのボトルネックはありません。 各コンテナは専用のパーティションにしがみつき、それだけで動作します。これにより、消費者のバランスを取り直すのに役立ちます。
以下は、モジュールのロジックの非常に単純化された説明、春の覆いの下で起こることのより詳細な説明であり、同僚は別の記事で行う予定です。 オリジナルの例をこちらからダウンロードできます 。
したがって、ウィザードを実行するには、クライアントモジュールが使用されます。
@EnableAutoConfiguration public class ClientApplication { public static void main(String[] args) { ConfigurableApplicationContext applicationContext = SpringApplication.run(ClientApplication.class, args); YarnClient yarnClient = applicationContext.getBean(YarnClient.class); yarnClient.submitApplication(); } }
送信ウィザードが完了すると、クライアントは終了します。 次に、application.ymlに登録されたCustomAppMasterクラスが機能します。
spring: hadoop: fsUri: hdfs://namespace:port/ resourceManagerHost: hostname resources: - "file:/path/hdfs-site.xml" yarn: appName: some-name applicationDir: /path/to/app/ appmaster: resource: memory: 10240 virtualCores: 1 appmaster-class: enter.appmaster.CustomAppMaster containerCount: 10 launchcontext: archiveFile: container.jar container: container-class: enter.appmaster.FailingContextContainer
preLaunch関数はその中で最も興味深いものです。 ここでは、入力に渡されるコンテナとパラメーターを管理します。
@Override public ContainerLaunchContext preLaunch(Container container, ContainerLaunchContext context) { Integer attempt = 1; // ContainerId containerId = container.getId(); ContainerId failedContainerId = failed.poll(); if (failedContainerId == null) { // } else { // ( ..) } Object assignedData = (failedContainerId != null ? getContainerAssign().getAssignedData(failedContainerId) : null); if (assignedData != null) { attempt = (Integer) assignedData; attempt += 1; } getContainerAssign().assign(containerId, attempt); Map<String, String> env = new HashMap<String, String>(context.getEnvironment()); env.put("some.param", "param1"); context.setEnvironment(env); return context; }
そして、落下ハンドラー:
@Override protected boolean onContainerFailed(ContainerStatus status) { ContainerId containerId = status.getContainerId(); if (status.getExitStatus() > 0) { failed.add(containerId); getAllocator().allocateContainers(1); } return true; }
コンテナクラスContainerApplication.javaで、必要なBeanが接続されます。次に例を示します。
@Bean public WorkClass workClass() { return new WorkClass(); }
作業クラスでは、@ OnContainerStartアノテーションを使用して、コンテナの起動時に自動的に呼び出されるメソッドを示します。
@OnContainerStart public void doWorkOnStart() throws Exception { // containerId DefaultYarnContainer yarnContainer = (DefaultYarnContainer) containerConfiguration.yarnContainer(); Map<String, String> environment = yarnContainer.getEnvironment(); ContainerId containerId = getContainerId(environment); // String param = environment.get("some.param"); SimpleConsumer<Serializable, Serializable> simpleConsumer = new SimpleConsumer<>(); // simpleConsumer.kafkaConsumer(param); }
現実には、実装のロジックはもちろんはるかに複雑です。 特に、RESTを介してコンテナとAppMasterの間でメッセージ交換が行われます。これにより、データの受信プロセスなどを調整できます。
その結果、ロードされたクラスターでテストする必要があるアプリケーションが得られました。 これを行うために、日中、バックグラウンドの負荷が高いときに、SparkStreamingで機能を削減したバージョンを起動しました。 それぞれに2つのコアを持つ30のコンテナと同じリソースが割り当てられました。

Javaでのソリューションのパフォーマンス制限を理解するために、純粋な条件で実験を行うことは興味深いことです。 これを行うために、1.2 TBのデータ、1コアの65コンテナーのダウンロードが開始され、10分で完了しました。

つまり 速度は2 GB /秒でした。 上記の図のより高い値は、HDFSのデータ複製の係数が3に等しいという事実によって説明されます。データ受信クラスタークラスターE5-2680v4 @ 2.40GHzのCPU。 とにかく、リソースの使用率が50%を大幅に下回るため、残りのパラメーターはあまり意味がありません。 現在のソリューションではさらに簡単に拡張できますが、意味がありません。 現時点では、ボトルネックはkafkaそのものです(より正確には、そのネットワークインターフェイスには、信頼性のために3つのブローカーがあり、同時にトリプルレプリケーションがあります)。
実際、原則として火花に反対するものはないようです。 これは特定の条件で非常に優れたツールであり、さらに処理するためにも使用します。 ただし、あらゆるデータをすばやく簡単に操作できる高レベルの抽象化には代償があります。 何かがうまくいかないときはいつも起こります。 Hbaseのパッチ適用とHiveコードの選択の経験がありましたが、実際にはこれが最も刺激的なアクティビティではありません。 もちろん、スパークの場合、許容可能な解決策を見つけることも可能ですが、多大な労力がかかります。 そして、このアプリケーションでは、常に問題の原因をすばやく見つけて修正し、非常に複雑なロジックを実装することができます。これはすぐに機能します。 一般的に、古いラテン語のsayingにあるように:
