現時点では、このマニュアルのインストールは機能しません。 Kubemaster APIの大幅な変更により、現在、マニュアルの作業バージョンがある新しいシリーズの記事を準備しています
記事の最初のhabr.com/en/post/462473
こんにちは
この出版物では、Kubernetes High Availability(HA)クラスターについてお話したいと思います。

目次:
- エントリー
- 使用ソフトウェアのリスト
- ホストのリストと宛先
- 運用と展開の原則
- OSの展開の準備。 docker、kubeadm、kubelet、kubectlをインストールします
- 構成スクリプトの準備
- etcdクラスターの作成
- kubeadmを使用してウィザードを初期化する
- CIDRセットアップ
- 残りのマスターノードの初期化
- keepalivedおよび仮想IPを構成する
- 作業ノードをクラスターに追加する
- ingress-nginxをインストールします
- オプショナル
エントリー
新しい職場では、興味深いタスクに直面しなければなりませんでした。つまり、非常にアクセスしやすいkubernetesクラスターをデプロイすることです。 タスクの主なメッセージは、物理マシンに障害が発生した場合にクラスターの最大限の耐障害性を実現することでした。
小さな紹介:
最小限のドキュメントと1つの展開されたスタンドを備えたプロジェクトを手に入れました。このプロジェクトの個々のコンポーネントは、ドッカーコンテナに「ぶら下がり」ました。 pm2を介して実行されるさまざまなサービスの4つのフロントもこのスタンドで機能しました。
サービスのスキームとそのサービスのロジックを理解できた後、プロジェクトが機能するインフラストラクチャの選択次第でした。 すべての議論の後、2つのシナリオに決めました。 1つ目は、すべてをlxcコンテナーに詰め込み、ansibleを使用してすべてを操縦することです。 2番目は、すべてをドッカーに残してk8sを試すことです。
最初のオプションによると、当社のほとんどのプロジェクトは機能します。 ただし、この場合、すべてをdockerのままにして、kubernetesを使用してフェールオーバークラスターにプロジェクトを配置することにしました。
フォールトトレランスを向上させるため、5つのマスターノードでクラスターを展開することが決定されました。
CoreOS Webサイトの etcdドキュメントの表によると、
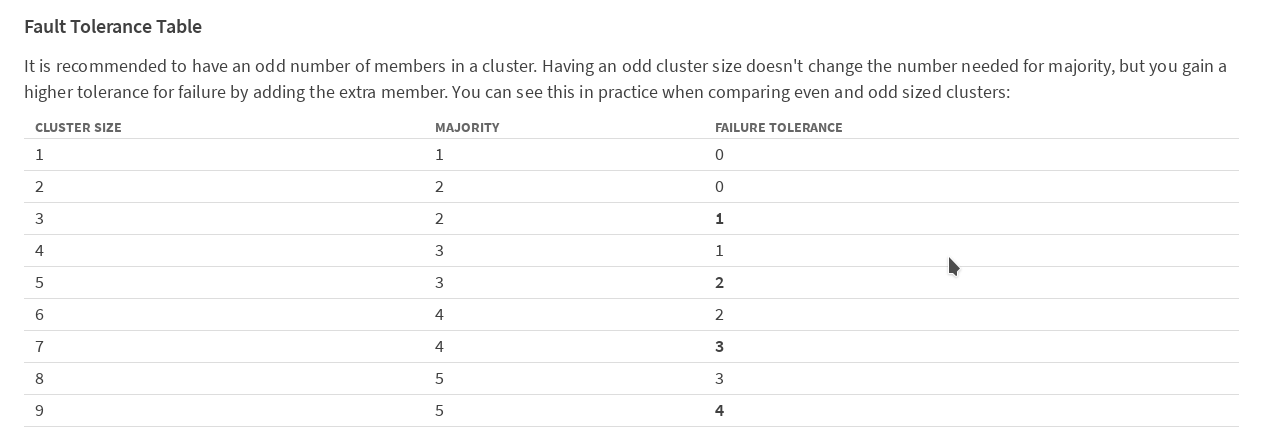
クラスター内のメンバーの数を奇数にすることをお勧めします。 1つのメンバー(この場合はkubernetesウィザード)の障害後もクラスターが引き続き機能するためには、少なくとも3台のマシンが必要です。 2台のマシンを失った後にクラスターが機能するためには、5台必要です。安全にプレイし、5つのウィザードでオプションをデプロイすることにしました。
Kubernetesには非常に詳細な公式ドキュメントがありますが、私の意見では非常に混乱しています。 特にこの製品に初めて出会ったとき。
クラスター内にマスターの役割を持つノードが1つしかない場合、ドキュメントが主に作業スキームについて説明しているのは悪いことです。 また、HAモードでのクラスターの動作に関するインターネット上の情報はあまりありませんが、私の意見では、ロシア側ではまったくありません。 したがって、私は自分の経験を共有することにしました。 おそらくそれは誰かに役立つでしょう。 だから、私は始めます:
基本的な考え方は、 料理人によってギタブに見張られていました 。 一般に、私はそれを実装し、構成の欠点のほとんどを修正し、クラスター内のマスターノードの数を5に増やしました。 以下のすべての設定とスクリプトは、GitHubのリポジトリからダウンロードできます。
展開アーキテクチャの概要と説明
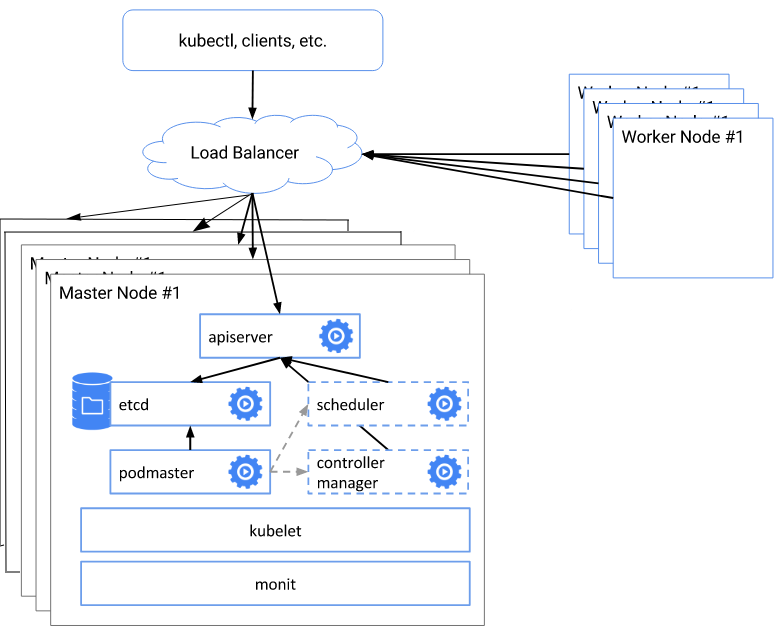
スキームの全体的なポイントは次のとおりです。
- etcdクラスターを作成する
- kubeadm initを使用して、最初のマスター証明書、キーなどを作成します。
- 生成された構成ファイルを使用して、残りの4つのマスターノードを初期化します
- 仮想アドレスの各マスターノードでnginxバランサーを構成する
- サーバーAPIのアドレスとポートを専用の仮想アドレスに変更します
- 作業ノードをクラスターに追加します
使用ソフトウェアのリスト
- Linux:
オペレーティングシステムの選択。 当初、彼らはCoreOSを試してみたかったのですが、このOSをリリースした会社がRedHatに買収されたのは私たちの選択の時でした。 CoreOSを買収した後、RedHatは買収した開発のさらなる計画を発表しなかったため、将来のライセンス制限の可能性があるため、使用を恐れました。
Debian 9.3(Stretch)を選んだのは、それを使った作業に慣れているからです。 一般に、Kubernetes用のOSの選択に特別な違いはありません。 以下のスキーム全体は、kubernetesの公式ドキュメントのリストから、サポートされているすべてのOSで動作します
- Debian
- Ubuntu
- HypriotOS
- CentOS
- Rhel
- フェドラ
- コンテナLinux
- コンテナ:
執筆時点では、dockerバージョン17.03.2-ce、ビルドf5ec1e2、およびdocker-composeバージョン1.8.0がドキュメントで推奨されています。 - Kubernetes v1.9.3
- ネットワークアドオン:フランネル
- バランサー:nginx
仮想IP:keepalivedバージョン:1:1.3.2-1
ホストリスト
| ホスト名 | IPアドレス | 説明 | コンポーネント |
|---|---|---|---|
| hb-master01〜03 | 172.26.133.21〜25 | マスターノード* 5 | keepalived、nginx、etcd、kubelet、kube-apiserver、kube-scheduler、kube-proxy、kube-dashboard、heapster |
| N \ A | 172.26.133.20 | keepalived仮想IP | N \ A |
| hb-node01〜03 | 172.26.133.26〜28 | 作業ノード* 3 | kubelet、kube-proxy |
OSの展開の準備。 docker、kubeadm、kubelet、kubectlをインストールします
デプロイメントを開始する前に、クラスターのすべてのノードでシステムを準備する必要があります。つまり、必要なパッケージをインストールし、ファイアウォールを構成し、スワップを無効にします。
$ sudo -i :~#
スワップを使用する場合は、無効にする必要があります。 kubeadmはスワップをサポートしていません。 スワップパーティションなしですぐにシステムをインストールしました。
swapoff -a
/ etc / fstabを編集します。 手動で
vim /etc/fstab # swap was on /dev/sda6 during installation #UUID=5eb7202b-68e2-4bab-8cd1-767dc5a2ee9d none swap sw 0 0
sedを介したLibo
sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
Debian 9にはselinuxはありません。 ディストリビューションにそれがある場合、それを許容モードに変換する必要があります
iptablesにルールがある場合は、それらをクリアすることをお勧めします。 インストールおよび構成中に、Dockerおよびkubernetesはファイアウォールルールを書き留めます。
クラスターの各ノードで、正しいホスト名を指定する必要があります。
vim /etc/hostname hb-master01
これで準備が完了しました。次のステップの前に再起動します
reboot
クラスター内の各マシンで、 kubernetesドキュメントの指示に従ってdockerをインストールします 。
apt-get update apt-get install -y \ apt-transport-https \ ca-certificates \ curl \ software-properties-common \ curl -fsSL https://download.docker.com/linux/ubuntu/gpg | apt-key add - add-apt-repository \ "deb https://download.docker.com/linux/$(. /etc/os-release; echo "$ID") \ $(lsb_release -cs) \ stable" apt-get update && apt-get install -y docker-ce=$(apt-cache madison docker-ce | grep 17.03 | head -1 | awk '{print $3}') docker-compose
次に、同じ指示に従ってkubeadm、kubelet、kubectlを配置します。
apt-get update && apt-get install -y apt-transport-https curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - cat <<EOF >/etc/apt/sources.list.d/kubernetes.list deb http://apt.kubernetes.io/ kubernetes-xenial main EOF apt-get update apt-get install -y kubelet kubeadm kubectl
keepalivedをインストールします。
apt-get install keepalived systemctl enable keepalived && systemctl restart keepalived
CNI(Container Network Interface)が正しく機能するためには、/ proc / sys / net / bridge / bridge-nf-call-iptablesを1に設定します
sysctl net.bridge.bridge-nf-call-iptables=1
構成スクリプトの準備
git clone https://github.com/rjeka/kubernetes-ha.git cd kubernetes-ha
各マスターノードで、create-config.shスクリプトを準備します
vim create-config.sh #!/bin/bash # local machine ip address export K8SHA_IPLOCAL=172.26.133.21 # local machine etcd name, options: etcd1, etcd2, etcd3, etcd4, etcd5 export K8SHA_ETCDNAME=etcd1 # local machine keepalived state config, options: MASTER, BACKUP. One keepalived cluster only one MASTER, other's are BACKUP export K8SHA_KA_STATE=MASTER # local machine keepalived priority config, options: 102, 101, 100, 99, 98. MASTER must 102 export K8SHA_KA_PRIO=102 # local machine keepalived network interface name config, for example: eth0 export K8SHA_KA_INTF=ens18 ####################################### # all masters settings below must be same ####################################### # master keepalived virtual ip address export K8SHA_IPVIRTUAL=172.26.133.20 # master01 ip address export K8SHA_IP1=172.26.133.21 # master02 ip address export K8SHA_IP2=172.26.133.22 # master03 ip address export K8SHA_IP3=172.26.133.23 # master04 ip address export K8SHA_IP4=172.26.133.24 # master05 ip address export K8SHA_IP5=172.26.133.25 # master01 hostname export K8SHA_HOSTNAME1=hb-master01 # master02 hostname export K8SHA_HOSTNAME2=hb-master02 # master03 hostname export K8SHA_HOSTNAME3=hb-master03 # master04 hostname export K8SHA_HOSTNAME4=hb-master04 # master04 hostname export K8SHA_HOSTNAME4=hb-master05 # keepalived auth_pass config, all masters must be same export K8SHA_KA_AUTH=55df7dc334c90194d1600c483e10acfr # kubernetes cluster token, you can use 'kubeadm token generate' to get a new one export K8SHA_TOKEN=4ae6cb.9dbc7b3600a3de89 # kubernetes CIDR pod subnet, if CIDR pod subnet is "10.244.0.0/16" please set to "10.244.0.0\\/16" export K8SHA_CIDR=10.244.0.0\\/16 ############################## # please do not modify anything below ##############################
Cookeemは設定ファイル自体に非常に詳細なコメントを残しましたが、それでも主なポイントを見ていきましょう。
復号化create-config.sh
#各ノードのローカルマシンの設定(各ノードには独自のノードがあります)
K8SHA_IPLOCAL-スクリプトが構成されているノードのIPアドレス
K8SHA_ETCDNAME -ETCDクラスター内のローカルマシンの名前(それぞれmaster01-etcd1、master02-etcd2など)
K8SHA_KA_STATE -keepalivedのロール。 1つのMASTERノード、他のすべてのBACKUP。
K8SHA_KA_PRIO-キープアライブされた優先度、マスター102の残りの101、100 、..... 98。 番号102のマスターが落ちると、その場所は番号101のノードなどに引き継がれます。
K8SHA_KA_INTF -keepalivedネットワークインターフェイス。 keepalivedがリッスンするインターフェイスの名前
#すべてのマスターノードの共通設定は同じです
K8SHA_IPVIRTUAL = 172.26.133.20-クラスターの仮想IP。
K8SHA_IP1 ... K8SHA_IP5-マスターのIPアドレス
K8SHA_HOSTNAME1 ... K8SHA_HOSTNAME5-マスターノードのホスト名。 重要なポイントは、これらの名前によってkubeadmが証明書を生成することです。
K8SHA_KA_AUTH -keepalivedのパスワード。 任意を指定できます
K8SHA_TOKEN-クラスタートークン。 kubeadm token generateコマンドで生成できます
K8SHA_CIDR-囲炉裏のサブネットアドレス。 フランネルを使用しているので、CIDR 0.244.0.0/16です。 必ずスクリーニングしてください-設定では、K8SHA_CIDR = 10.244.0.0 \\ / 16である必要があります
K8SHA_IPLOCAL-スクリプトが構成されているノードのIPアドレス
K8SHA_ETCDNAME -ETCDクラスター内のローカルマシンの名前(それぞれmaster01-etcd1、master02-etcd2など)
K8SHA_KA_STATE -keepalivedのロール。 1つのMASTERノード、他のすべてのBACKUP。
K8SHA_KA_PRIO-キープアライブされた優先度、マスター102の残りの101、100 、..... 98。 番号102のマスターが落ちると、その場所は番号101のノードなどに引き継がれます。
K8SHA_KA_INTF -keepalivedネットワークインターフェイス。 keepalivedがリッスンするインターフェイスの名前
#すべてのマスターノードの共通設定は同じです
K8SHA_IPVIRTUAL = 172.26.133.20-クラスターの仮想IP。
K8SHA_IP1 ... K8SHA_IP5-マスターのIPアドレス
K8SHA_HOSTNAME1 ... K8SHA_HOSTNAME5-マスターノードのホスト名。 重要なポイントは、これらの名前によってkubeadmが証明書を生成することです。
K8SHA_KA_AUTH -keepalivedのパスワード。 任意を指定できます
K8SHA_TOKEN-クラスタートークン。 kubeadm token generateコマンドで生成できます
K8SHA_CIDR-囲炉裏のサブネットアドレス。 フランネルを使用しているので、CIDR 0.244.0.0/16です。 必ずスクリーニングしてください-設定では、K8SHA_CIDR = 10.244.0.0 \\ / 16である必要があります
すべての値が登録された後、各マスターノードでcreate-config.shスクリプトを実行して構成を作成する必要があります
kubernetes-ha# ./create-config.sh
etcdクラスターの作成
受信した構成に基づいて、etcdクラスターを作成します
docker-compose --file etcd/docker-compose.yaml up -d
コンテナがすべてのマスターで上昇した後、etcdのステータスを確認します
docker exec -ti etcd etcdctl cluster-health member 3357c0f051a52e4a is healthy: got healthy result from http://172.26.133.24:2379 member 4f9d89f3d0f7047f is healthy: got healthy result from http://172.26.133.21:2379 member 8870062c9957931b is healthy: got healthy result from http://172.26.133.23:2379 member c8923ecd7d317ed4 is healthy: got healthy result from http://172.26.133.22:2379 member cd879d96247aef7e is healthy: got healthy result from http://172.26.133.25:2379 cluster is healthy
docker exec -ti etcd etcdctl member list 3357c0f051a52e4a: name=etcd4 peerURLs=http://172.26.133.24:2380 clientURLs=http://172.26.133.24:2379,http://172.26.133.24:4001 isLeader=false 4f9d89f3d0f7047f: name=etcd1 peerURLs=http://172.26.133.21:2380 clientURLs=http://172.26.133.21:2379,http://172.26.133.21:4001 isLeader=false 8870062c9957931b: name=etcd3 peerURLs=http://172.26.133.23:2380 clientURLs=http://172.26.133.23:2379,http://172.26.133.23:4001 isLeader=false c8923ecd7d317ed4: name=etcd2 peerURLs=http://172.26.133.22:2380 clientURLs=http://172.26.133.22:2379,http://172.26.133.22:4001 isLeader=true cd879d96247aef7e: name=etcd5 peerURLs=http://172.26.133.25:2380 clientURLs=http://172.26.133.25:2379,http://172.26.133.25:4001 isLeader=false
クラスターが正常であれば、次に進みます。 何かが間違っている場合は、ログを見てください
docker logs etcd
kubeadmを使用して最初のマスターノードを初期化する
kubeadmを使用してhb-master01で、kubernetesクラスターを初期化します。
kubeadm init --config=kubeadm-init.yaml
Kubeletのバージョンに応じてエラーがある場合は、行にキーを追加する必要があります
--ignore-preflight-errors=KubeletVersion
ウィザードが初期化されると、kubeadmはサービス情報を表示します。 クラスターの他のメンバーを初期化するトークンとハッシュを示します。 フォームの行を必ず保存してください: kubeadm join --token XXXXXXXXXXXX 172.26.133.21:6443 --discovery-token-ca-cert-hash sha256:XXXXXXXXXXXXXXXXXXXXXXXXXXXこの情報は一度表示されるため、どこか別の場所にあります。 トークンが失われた場合、トークンを再生成する必要があります。
Your Kubernetes master has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ You can now join any number of machines by running the following on each node as root: kubeadm join --token XXXXXXXXXXXX 172.26.133.21:6443 --discovery-token-ca-cert-hash sha256:XXXXXXXXXXXXXXXXXXXXXXX
次に、ルートからクラスターを操作できるように、環境変数を設定する必要があります
vim ~/.bashrc export KUBECONFIG=/etc/kubernetes/admin.conf
source ~/.bashrc
通常のユーザーとして作業する必要がある場合は、ウィザードの初期化時に画面に表示された指示に従ってください。
To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
すべてが正しく行われていることを確認します。
kubectl get node NAME STATUS ROLES AGE VERSION hb-master01 NotReady master 22m v1.9.5 NotReady cidr, .
CIDRセットアップ
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/v0.9.1/Documentation/kube-flannel.yml clusterrole "flannel" created clusterrolebinding "flannel" created serviceaccount "flannel" created configmap "kube-flannel-cfg" created daemonset "kube-flannel-ds" created
すべてが正常であることを確認します
kubectl get pods --all-namespaces NAMESPACE NAME READY STATUS RESTARTS AGE kube-system kube-apiserver-hb-master01 1/1 Running 0 1h kube-system kube-controller-manager-hb-master01 1/1 Running 0 1h kube-system kube-dns-6f4fd4bdf-jdhdk 3/3 Running 0 1h kube-system kube-flannel-ds-hczw4 1/1 Running 0 1m kube-system kube-proxy-f88rm 1/1 Running 0 1h kube-system kube-scheduler-hb-master01 1/1 Running 0 1h
残りのマスターノードの初期化
ここで、クラスターが1つのノードで動作した後、残りのマスターノードをクラスターに導入します。
これを行うには、hb-master01を使用して、/ etc / kubernetes / pkiディレクトリを各マスターのリモートの/ etc / kubernetes /ディレクトリにコピーする必要があります。 ssh設定でコピーするために、一時的にルート接続を許可しました。 もちろん、ファイルをコピーした後、この機能をオフにしました。
残りの各マスターノードで、sshサーバーを構成します
vim /etc/ssh/sshd_config PermitRootLogin yes systemctl restart ssh
ファイルをコピーする
scp -r /etc/kubernetes/pki 172.26.133.22:/etc/kubernetes/ \ && scp -r /etc/kubernetes/pki 172.26.133.23:/etc/kubernetes/ \ && scp -r /etc/kubernetes/pki 172.26.133.24:/etc/kubernetes/ \ && scp -r /etc/kubernetes/pki 172.26.133.25:/etc/kubernetes/
hb-master02でkubeadmを使用してクラスターを起動し、ポッドkube-apiserver-が動作状態にあることを確認します。
kubeadm init --config=kubeadm-init.yaml Your Kubernetes master has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ You can now join any number of machines by running the following on each node as root: kubeadm join --token xxxxxxxxxxxxxx 172.26.133.22:6443 --discovery-token-ca-cert-hash sha256:xxxxxxxxxxxxxxxxxxxxxxxxx
hb-master03、hb-master04、hb-master05で繰り返します
すべてのウィザードが初期化され、クラスターで機能することを確認します
kubectl get nodes NAME STATUS ROLES AGE VERSION hb-master01 Ready master 37m v1.9.5 hb-master02 Ready master 33s v1.9.5 hb-master03 Ready master 3m v1.9.5 hb-master04 Ready master 17m v1.9.5 hb-master05 Ready master 19m v1.9.5
kubectl get pods --all-namespaces NAMESPACE NAME READY STATUS RESTARTS AGE kube-system kube-apiserver-hb-master01 1/1 Running 0 6m kube-system kube-apiserver-hb-master02 1/1 Running 0 1m kube-system kube-apiserver-hb-master03 1/1 Running 0 1m kube-system kube-apiserver-hb-master04 1/1 Running 0 1m kube-system kube-apiserver-hb-master05 1/1 Running 0 10s kube-system kube-controller-manager-hb-master01 1/1 Running 0 6m kube-system kube-controller-manager-hb-master02 1/1 Running 0 1m kube-system kube-controller-manager-hb-master03 1/1 Running 0 1m kube-system kube-controller-manager-hb-master04 1/1 Running 0 1m kube-system kube-controller-manager-hb-master05 1/1 Running 0 9s kube-system kube-dns-6f4fd4bdf-bnxl8 3/3 Running 0 7m kube-system kube-flannel-ds-j698p 1/1 Running 0 6m kube-system kube-flannel-ds-mf9zc 1/1 Running 0 2m kube-system kube-flannel-ds-n5vbm 1/1 Running 0 2m kube-system kube-flannel-ds-q7ztg 1/1 Running 0 1m kube-system kube-flannel-ds-rrrcq 1/1 Running 0 2m kube-system kube-proxy-796zl 1/1 Running 0 1m kube-system kube-proxy-dz25s 1/1 Running 0 7m kube-system kube-proxy-hmrw5 1/1 Running 0 2m kube-system kube-proxy-kfjst 1/1 Running 0 2m kube-system kube-proxy-tpkbt 1/1 Running 0 2m kube-system kube-scheduler-hb-master01 1/1 Running 0 6m kube-system kube-scheduler-hb-master02 1/1 Running 0 1m kube-system kube-scheduler-hb-master03 1/1 Running 0 1m kube-system kube-scheduler-hb-master04 1/1 Running 0 48s kube-system kube-scheduler-hb-master05 1/1 Running 0 29s
kube-dnsサービスのレプリカを作成します。 hb-master01で実行
kubectl scale --replicas=5 -n kube-system deployment/kube-dns
すべてのマスターノードで、構成ファイルにAPIサーバーの数を含む行を追加します
1.9以降のkubernetesバージョンを使用している場合は、この手順をスキップできます。
vim /etc/kubernetes/manifests/kube-apiserver.yaml - --apiserver-count=5 systemctl restart docker && systemctl restart kubelet
keepalivedおよび仮想IPを構成する
すべてのマスターノードで、keepalivedとnginxをバランサーとして構成します
systemctl restart keepalived docker-compose -f nginx-lb/docker-compose.yaml up -d
テスト作業
curl -k https://172.26.133.21:16443 | wc -1 wc: invalid option -- '1' Try 'wc --help' for more information. % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 233 100 233 0 0 15281 0 --:--:-- --:--:-- --:--:-- 15533
100%の場合-すべてが問題ありません。
有効な仮想アドレスを取得したら、それをサーバーAPIアドレスとして示します。
hb-master01で
kubectl edit -n kube-system configmap/kube-proxy server: https://172.26.133.20:16443
すべてのkube-proxyポッドを削除して、新しいパラメーターで再起動します。
kubectl get pods --all-namespaces -o wide | grep proxy kubectl delete pod -n kube-system kube-proxy-XXX
すべてが再起動されることを確認します。
kubectl get pods --all-namespaces -o wide | grep proxy kube-system kube-proxy-2q7pz 1/1 Running 0 28s 172.26.133.22 hb-master02 kube-system kube-proxy-76vnw 1/1 Running 0 10s 172.26.133.23 hb-master03 kube-system kube-proxy-nq47m 1/1 Running 0 19s 172.26.133.24 hb-master04 kube-system kube-proxy-pqqdh 1/1 Running 0 35s 172.26.133.21 hb-master01 kube-system kube-proxy-vldg8 1/1 Running 0 32s 172.26.133.25 hb-master05
作業ノードをクラスターに追加する
各作業ノードで、ウィザードと同様にdocke、kubernetes、kubeadmをインストールします。
初期化時に生成されたトークンを使用して、ノードをクラスターに追加しますhb-master01
kubeadm join --token xxxxxxxxxxxxxxx 172.26.133.21:6443 --discovery-token-ca-cert-hash sha256:xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx [preflight] Running pre-flight checks. [WARNING FileExisting-crictl]: crictl not found in system path [discovery] Trying to connect to API Server "172.26.133.21:6443" [discovery] Created cluster-info discovery client, requesting info from "https://172.26.133.21:6443" [discovery] Requesting info from "https://172.26.133.21:6443" again to validate TLS against the pinned public key [discovery] Cluster info signature and contents are valid and TLS certificate validates against pinned roots, will use API Server "172.26.133.21:6443" [discovery] Successfully established connection with API Server "172.26.133.21:6443" This node has joined the cluster: * Certificate signing request was sent to master and a response was received. * The Kubelet was informed of the new secure connection details. Run 'kubectl get nodes' on the master to see this node join the cluster.
すべての作業ノードがクラスターに含まれており、使用可能であることを確認します。
kubectl get nodes NAME STATUS ROLES AGE VERSION hb-master01 Ready master 20h v1.9.5 hb-master02 Ready master 20h v1.9.5 hb-master03 Ready master 20h v1.9.5 hb-master04 Ready master 20h v1.9.5 hb-master05 Ready master 20h v1.9.5 hb-node01 Ready <none> 12m v1.9.5 hb-node02 Ready <none> 4m v1.9.5 hb-node03 Ready <none> 31s v1.9.5
/etc/kubernetes/bootstrap-kubelet.confおよび/etc/kubernetes/kubelet.confファイルの作業ノードでのみ
仮想IPに対するサーバー変数の値
vim /etc/kubernetes/bootstrap-kubelet.conf server: https://172.26.133.20:16443
vim /etc/kubernetes/kubelet.conf server: https://172.26.133.20:16443
systemctl restart docker kubelet
その後、必要に応じて新しい作業ノードを追加して、クラスターのパフォーマンスを向上させることができます。
ingress-nginxをインストールします
Ntgthmイングレスをインストールする必要があります。
kubernetes Ingressのドキュメントには次のように書かれています:
クラスター内のサービス(通常はHTTP)への外部アクセスを制御するAPIオブジェクト。
Ingressは、負荷分散、SSL終了、名前ベースの仮想ホスティングを提供できます。
一般的に、これ以上詳細に説明することはできません。 イングレス設定は、別の記事の資料です。クラスターインストールのコンテキストでは、そのインストールについてのみ説明します。
kubectl apply -f kube-ingress/mandatory.yaml namespace "ingress-nginx" created deployment.extensions "default-http-backend" created service "default-http-backend" created configmap "nginx-configuration" created configmap "tcp-services" created configmap "udp-services" created serviceaccount "nginx-ingress-serviceaccount" created clusterrole.rbac.authorization.k8s.io "nginx-ingress-clusterrole" configured role.rbac.authorization.k8s.io "nginx-ingress-role" created rolebinding.rbac.authorization.k8s.io "nginx-ingress-role-nisa-binding" created clusterrolebinding.rbac.authorization.k8s.io "nginx-ingress-clusterrole-nisa-binding" configured deployment.extensions "nginx-ingress-controller" created
kubectl apply -f kube-ingress/service-nodeport.yaml service "ingress-nginx" created
イングレスが上昇したことを確認します。
kubectl get all -n ingress-nginx NAME READY STATUS RESTARTS AGE pod/default-http-backend-5c6d95c48-j8sd4 1/1 Running 0 5m pod/nginx-ingress-controller-58c9df5856-vqwst 1/1 Running 0 5m NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/default-http-backend ClusterIP 10.109.216.21 <none> 80/TCP 5m service/ingress-nginx NodePort 10.96.229.115 172.26.133.20 80:32700/TCP,443:31211/TCP 4m NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE deployment.apps/default-http-backend 1 1 1 1 5m deployment.apps/nginx-ingress-controller 1 1 1 1 5m NAME DESIRED CURRENT READY AGE replicaset.apps/default-http-backend-5c6d95c48 1 1 1 5m replicaset.apps/nginx-ingress-controller-58c9df5856 1 1 1 5m
このステップで、クラスター構成が完了します。 すべてを正しく行った場合、フェールセーフエントリポイントと仮想アドレス上のバランサーを備えたフェールセーフで動作するKubernetesクラスターを取得する必要があります。
ご清聴ありがとうございました。コメントや不正確な点を指摘させていただきます。 githubで問題を作成することもできます。私はそれらに迅速に対応しようとします。
よろしく
エフゲニー・ロディオノフ
オプショナル
|Kubernetes Dashboardコントロールパネルをインストールする
Kubernetesには、cliのほかに素敵なツールバーがあります。 それは非常に簡単にインストールされ、手順とドキュメントはGitHubにあります
コマンドは、5つのウィザードのいずれでも実行できます。 私はhb-master01を使用しています
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/master/src/deploy/recommended/kubernetes-dashboard.yaml
私たちはチェックします:
kubectl get pods --all-namespaces -o wide | grep kubernetes-dashboard kube-system kubernetes-dashboard-5bd6f767c7-cz55w 1/1 Running 0 1m 10.244.7.2 hb-node03
このパネルは次の場所で利用できます。
http:// localhost:8001 / api / v1 / namespaces / kube-system / services / https:kubernetes-dashboard:/ proxy /しかし、それに到達するには、コマンドを使用してローカルマシンからプロキシを転送する必要があります
kubectl proxy
これは都合が悪いので、 NodePortを使用して、NodePortに割り当てられた範囲の最初の使用可能なポートのhttps: //172.26.133.20haps0000にパネルを配置します。
kubectl -n kube-system edit service kubernetes-dashboard
type:ClusterIPの値をtype:NodePortに置き換え、ポートセクションでnodePortの値を追加します:30000

次に、名前admin-userおよびクラスター管理者特権を持つユーザーを作成します。
kubectl apply -f kube-dashboard/dashboard-adminUser.yaml serviceaccount "admin-user" created clusterrolebinding "admin-user" created
管理者ユーザーのトークンを取得する
kubectl -n kube-system describe secret $(kubectl -n kube-system get secret | grep admin-user | awk '{print $1}') Name: admin-user-token-p8cxl Namespace: kube-system Labels: <none> Annotations: kubernetes.io/service-account.name=admin-user kubernetes.io/service-account.uid=0819c99c-2cf0-11e8-a281-a64625c137fc Type: kubernetes.io/service-account-token Data ==== ca.crt: 1025 bytes namespace: 11 bytes token: XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
トークンをコピーして、アドレスに移動します。
https://172.26.133.20haps0000/これで、管理者権限でKubernetesクラスターコントロールパネルにアクセスできます。
ヒープスター
次に、Heapsterをインストールします。 これは、クラスターのすべてのコンポーネントのリソースを監視するためのツールです。 GitHubプロジェクトページ
インストール:
git clone https://github.com/kubernetes/heapster.git cd heapster kubectl create -f deploy/kube-config/influxdb/ deployment "monitoring-grafana" created service "monitoring-grafana" created serviceaccount "heapster" created deployment "heapster" created service "heapster" created deployment "monitoring-influxdb" created service "monitoring-influxdb" created
kubectl create -f deploy/kube-config/rbac/heapster-rbac.yaml clusterrolebinding "heapster" created
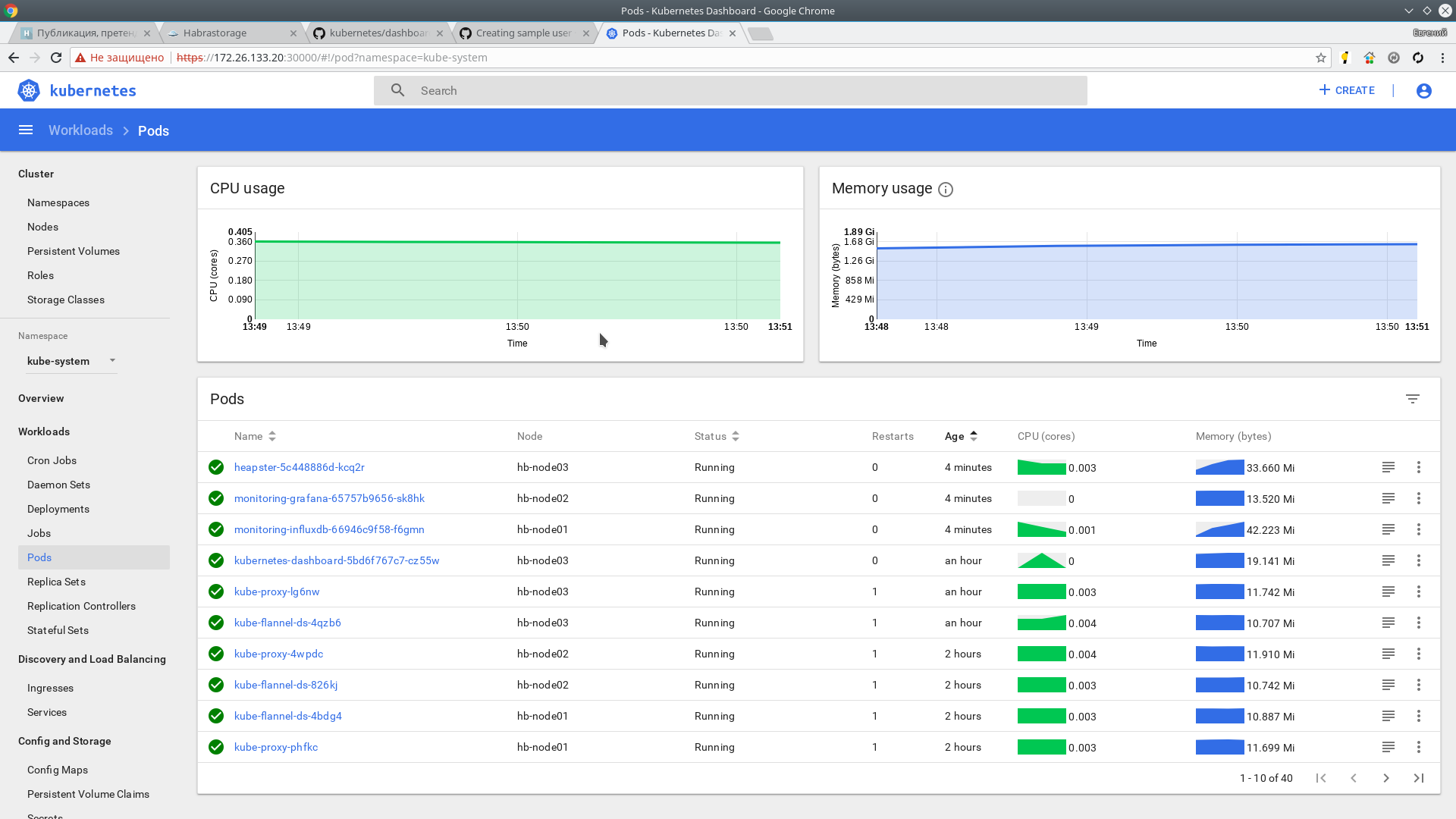
情報は数分で届くはずです。 私たちはチェックします:
kubectl top nodes NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% hb-master01 166m 4% 1216Mi 31% hb-master02 135m 3% 1130Mi 29% hb-master03 142m 3% 1091Mi 28% hb-master04 193m 4% 1149Mi 29% hb-master05 144m 3% 1056Mi 27% hb-node01 41m 1% 518Mi 3% hb-node02 38m 0% 444Mi 2% hb-node03 45m 1% 478Mi 2%
メトリックはWebインターフェースでも使用できます。
ご清聴ありがとうございました。
材料の使用: