カットの下で、Highload ++のPhilipp Delgyado ( dph )の物語は、ロシアの合法ブックメーカービジネスの支払いシステムでの数年にわたる経験、過失についてだけでなく、いくつかの成果、およびWebを正しく混合するが振らない方法についての経験エンタープライズ。

講演者について :フィリップ・デルガドはキャリアの中で、彼がやらなかったことを2リンクから
Visual BasicからハードコアSQL。 近年、彼は主にJavaでロードされたプロジェクトに従事し、さまざまな会議で彼の経験を定期的に共有しています。
3年間、私たちは支払いシステムを作り続けており、そのうち2年間は生産に携わっています。 2年前、私は 1年で支払いシステムを作成する方法について話しましたが、それ以来、もちろん、私たちの決定には多くの変化がありました。
私たちはかなり小さなチームです。10人のプログラマ、ほとんどがバックエンドの開発者、フロントエンドにいるのは2人だけ、4人のQAと私、そして何らかの管理者です。 チームは小さいので、特に最初はあまりお金がありません。
支払システム
一般的に、支払いシステムは非常に簡単です。お金を取り、マイナス記号を付けて1つのプレートから同じプレートにエントリを転送します-それだけです!
現実には、支払いシステムは非常に単純なものです。 弁護士が来るまで 。 世界中の支払いシステムには、あるタブレットから別のタブレットに送金する方法、ユーザーとやり取りする方法、彼らが約束できること、約束できないこと、私たちが責任を負わないことに関する膨大なさまざまな負担と指示があります。 そのため、支払いシステムの開発の一環として、大企業と完全に通常のスケーラブルなWebアプリケーションの間で常にバランスをとる必要があります。
企業からは次のものがあります。
私たちはお金で働きます。
したがって、複雑なアカウンティングがあり、高いレベルの信頼性、高いSLA(シンプルなシステムが私たちもユーザーも好きではないため)、および高い責任が必要です。瞬間は一般的に起こります。
私たちはNPO(非銀行信用機関)です。
実質的には銀行であり、貸し出しはできません。
- 中央銀行に報告書があります。
- 財務監視への報告があります。
- 当社の銀行部門には多くの同僚がおり、銀行の経験があります。
- 自動化された銀行システムとのやり取りを余儀なくされています。
弁護士がいます。 現在、ロシア連邦での支払いシステムの動作を規制する法律の一部を次に示します。

これらの法律のそれぞれを実装することは非常に困難です。これは、まだ多くの定款、実際の使用事例があり、これらすべてを処理する必要があるためです。
同時に、私たちはそのような純粋な企業であり、ほとんど銀行であるという事実に加えて、私たちはまだかなりのウェブ企業です。
- 市場は非常に競争が激しいため、ユーザーの利便性は私たちにとって基本的です。ユーザーを気にしないと、ユーザーは私たちを去り、お金はまったくありません。
- ビジネスが活発に発展しているため、頻繁に計算する必要があります。 現在、週に23回のリリースがあります。これは大手銀行のリリースよりもはるかに一般的であり、最近では3か月に1回リリースを開始し、非常に誇りに思っています。
- 市場投入までの最短時間:アイデアが到着したらすぐに、できるだけ早く現実の世界でそれを起動する必要があります-できれば競合他社よりも早く。
- 多くの大手銀行とは異なり、多くのお金はありません。 私たちはすべてをお金で満たすことはできません。どうにかして出て行って、決断を下さなければなりません。

Javaを使用するのは、他の言語よりもJavaの世界でデータベースを操作することの信頼性について少なくともある程度理解している市場の開発者を見つけるのが少し簡単だからです。
支払いシステムを作成できるデータベースは3つしかありませんが、そのうちの1つは非常に高価で、2つ目はサポートを見つけるのが難しく、無料でもありません。 その結果、 PostgreSQLは私たちにとって最良の選択肢です。適切なサポートを簡単に見つけることができ、一般に、ほとんどお金をかけずにデータベースで何が起こるかを考える必要はありません。すべてがきれいで美しく、保証されています。
このプロジェクトでは、ちょっとしたKotlinを使用しています-むしろ楽しみのために、そして将来を見据えています。 Kotlinは主にある種のスクリプト言語に加えて、いくつかの小さなサービスとして使用されます。
もちろん、 サービスアーキテクチャです。 マイクロサービスをカテゴリ別に呼び出すことはできません。 私の理解では、マイクロサービスは理解してリファクタリングするよりも書き直しやすいものです。 したがって、もちろん、マイクロサービスはありませんが、通常の本格的な大規模コンポーネントがあります。
さらに、キャッシュ用のRedis 、内部キッチン用のAngular。 ユーザーに表示されるメインサイトは、最小限のJSを含む純粋なHTML + CSSで作成されます。
そしてもちろん、 カフカ 。
サービス
もちろん、私はむしろサービスなしで生きたいです。 1つの大きなモノリス、接続性の問題、バージョン管理の問題はありません。ピックアップ、書き込み、レイアウトです。 すべてがシンプルです。
ただし、 セキュリティ要件があります。 システムには個人データがあります。個人データは特別な制限付きで個別に保存および処理する必要があります。 銀行カードに関する情報があります。また、コードの変更とデータアクセスの各要件に関連する監査要件とともに、システムの別の部分に存在する必要があります。 したがって、すべてをコンポーネントにカットする必要があります。
信頼性の要件があります 。 取引相手の銀行の1つのゲートウェイが何らかの理由で故障し、すべての支払いロジックを採用してレイアウトしたため、私はそれを望んでいません。神は禁じます。間違ったレイアウト、人的要因があり、すべてが崩壊します。 したがって、すべてを比較的小さなサービスに分割する必要があります。
しかし、 セキュリティと信頼性の 要件に応じてシステムをコンポーネントに分割し始めているため、独自のストレージを必要とするすべてを個別のサービスに割り当てることは理にかなっています。 つまり 他のシステム全体に依存しないデータベースの一部については、個別のサービスを作成する方が簡単です。
そして、私たちの主な原則は、別のサービスに何かを割り当てることです-このサービス自体の明白な名前を思い付くことができるなら。
「処理」または「レポート」は多かれ少なかれ通常の名前ですが、「データベースのレプリカで動作するでたらめ」はすでに悪い名前です。 明らかに、これは1つのサービスではなく、複数のサービスまたは1つの大きなサービスの一部です。
これらの要件のうち4つで、個人を強調できます。
サービス。

もちろん、1つのサービスに対して非常に多くの単語と名前が蓄積されるため、マイクロモノリスはまだ残っています。 これは、責任を再配分する継続的なプロセスです。
サービス自体は、あらゆるWebの世界と同様に、http(s)上のJSON RPCを介して対話します。 同時に、クエリを再試行して結果をキャッシュするための個別のロジックがサービスごとに規定されています。 その結果、サービスがクラッシュした場合でも、システム全体が正常に動作し続け、ユーザーは何も気付きません。
コンポーネント
カフカ
これはメッセージキューではなく、 Kafka はサービス間のトランスポートレイヤーであり、配信保証と理解できる信頼性/クラスタリングを備えています。 つまり サービスAからサービスBに何かを送信する必要がある場合、Kafkaにメッセージを入力する方が簡単です。Kafkiからサービス自体が必要なものをピックアップします。 そして、再試行とキャッシングのすべてのロジックについて考える必要はありません。Kafkaはこの相互作用を大幅に簡素化します。 現在、私たちは可能な限りKafkaに翻訳しようとしていますが、これもまた継続的なプロセスです。

まあ、とりわけ、それはすべての操作に関するデータのバックアップソースです 。 もちろん、仕事の詳細が貢献するので、私は妄想的です。 私は(このプロジェクトではなく、かなり前に)たくさんのお金の商用データベースが、独自のデータベースファイルだけでなく、すべてのレプリカとバックアップにも、ある時点でナンセンスを書き始めたのを見ました。 また、ログからデータを復元する必要がありました。これは支払われたデータであり、それらがなければ、会社は翌日静かに閉鎖できたからです。
ログから重要なデータを抽出するのはあまり好きではないので、必要な情報はすべて同じカフェに入れたほうがいいでしょう。 突然、私に不可能なことが起こった場合、少なくとも、主記憶装置に接続されていないバックアップデータの入手先を知っています。
一般的に、支払いシステムの場合、2つの独立したデータウェアハウスを持つことは標準的な慣行であり、それなしで生活することは単に怖いです。たとえば、私にとっては。
開発ログ
もちろん、多くの異なるログがあります。 開発ログをKafkaに保存し、Clickhouseにアップロードします。これは、結果として、より簡単で安価なためです。 また、同時にクリックハウスについても研究しています。これは将来に役立ちます。 ただし、ログの操作に関する個別のレポートを作成できます。

モニタリング
Prometheus + Grafanaで監視します。 正直なところ、私はプロメテウに満足していません。

問題は何ですか?
- Prometheusは、既成の標準コンポーネントからデータを収集する必要があり、これらのコンポーネントが多数ある場合に最適です。 かなりの数の車があります。 40種類のサービスがあり、これは約150台の仮想マシンですが、それほど多くはありません。 Prometheusを通じて、特定のゲートウェイを通過する支払いの数、内部キュー内のイベントの数など、何らかのビジネス監視情報を収集する場合、クライアント側で非常に多くのコードを記述する必要があります。 さらに、残念なことに、コードはあまり単純ではないため、開発者は内部ロジックと、Prometheusが何かを正確にどのように考えているかを積極的に理解する必要があります。
- Prometheusは、正直なイベント指向の時系列データベースとして使用できません。 私はそれを取って、支払い開始のイベント、支払い終了のイベントがあると言うことはできず、彼に他のすべての指標をカウントさせます。 クライアントで必要なすべてのメトリックを事前に計算する必要があります。突然それらのいずれかを変更する必要がある場合、これは実稼働コンポーネントの次の計算であり、非常に不便です。
- 統合されたメトリックを実行することは非常に困難です。 多数のサービス(たとえば、すべてのフロントエンドサーバー上のクライアントへの応答時間のパーセンタイル)の共通のメトリックを収集する必要がある場合、Prometheusを介してこれを理論的にも行うことはできません。 Grafanaレベルで既にいくつかのあいまいな平均合計を行うことができます。 プロメテウス自体はこれを行うことができません。
したがって、私は真剣にどこかに行くと思います。
さらに、どのようなアーキテクチャ上の課題があったか、それらをどのように解決したか、何が良いか、何が悪いかについて、いくつかの個別のケースについてお話します。
データベースの使用
一般的に、支払いは非常に困難です。 以下は、支払いコンテキストの説明の例です:多くのタプル(連想配列)、タプルリスト、リストタプル、いくつかのパラメーター。 そして、これらはすべて、ビジネスロジックの変化により絶えず変化しています。

正直に言うと、多くのテーブルがあり、それらの間には多くのリンクがあります。 その結果、ORMが必要になり、列を追加するときに複雑な移行ロジックが必要になります。 PostgreSQLでは、テーブルに新しいNULL可能列を追加するだけでも(特定の状況では)長い間、このテーブルが完全に使用できなくなるという事実につながることを思い出してください。 つまり 実際、多くの人が考えるように、null許容列を追加することはアトミックフリー操作ではありません。 私たちはこれに一度つまずいたことさえありました。
これはすべて不快で悲しいことです。特にORMを使用している場合は、これをすべて避けたいと思います。 したがって、JSONでこれらのすべての大規模で複雑なエンティティを削除します。これは、アプリケーションサーバーを除いて、このすべてのデータと構造がどこにも必要ないことが現実的だからです。 私はこのアプローチを10年間使用しており、最後に、これが主流ではないとしても、少なくとも一般的に受け入れられている慣行になっていることに気付きました。
JSONプラクティス
原則として、複雑なビジネスデータをJSONの形式でデータベースに保存することで、パフォーマンスが低下することはなく、場合によっては勝つこともありません。 次に、誤って自分自身を足で撃たないようにする方法を説明します。

まず、競合の可能性についてすぐに考えなければなりません。
1つのデータフィールドセットを持つオブジェクトのバージョンができたら、別のバージョンのデータフィールドセットが既にある別のバージョンをリリースしました。古いJSONを何らかの方法で読み取り、便利なオブジェクトに変換する必要があります。
この問題を解決するには、通常、適切なシリアライザー/デシリアライザーを見つけるだけで十分です.JSONからこのフィールドをそのようなフィールドセットに変換する必要があることを明示的に言うことができます、これらのものはまあまあシリアル化されるべきですデフォルト値などで置き換える Javaでは、幸いなことに、このようなシリアライザーに問題はありません。 私のお気に入りはジャクソンです。
書き込み中の構造のバージョンをデータベースに保存してください。
つまり JSONを保存する各フィールドの隣に、バージョンが保存される別のフィールドがあるはずです。 まず、これは、新しいバージョンの古いバージョンを理解するためのコードを際限なくサポートしないために必要です。
新しいバージョンをリリースし、新しいデータ構造を取得したら、データベース全体を実行し、構造のすべての古いバージョンを検索し、それらを読み取り、新しい形式で書き込み、しばらく時間が経過した後、移行スクリプトを作成するだけです。 、データベースには最大2〜3の異なるバージョンのデータがあり、長年にわたって蓄積したさまざまなもののサポートに苦しむことはありません。 これは、自分自身をレガシーから取り除き、自分自身を技術的義務から取り除くことです。
PostgreSQLの場合-jsonとjsonbを選択します。
むかしむかし、この選択はまだ理にかなっています。 たとえば、ずっと前に始めたのでJSONを使用しました。 JSONデータ型は単なるテキストフィールドであり、その中のどこかをクロールするために、PostgreSQLは毎回解析します。 そのため、運用では、データベース内のjsonオブジェクトの内部に再度入らないようにしてください。これは、不具合のサポートまたは修正の場合に限ります。 良い意味で、SQLコードにはjsonフィールドを操作するコマンドはないはずです。
JSONBを使用する場合、PostgreSQLはすべてをバイナリ形式にきちんと解析しますが、JSONオブジェクトの元の外観を保持しません。 たとえば、私たちの元のデータを保存する場合、常にJSONのみを使用します。
JSONBはまだ必要ありませんが、現時点では、JSONBを常に使用し、それについてもう考えないことが本当に理にかなっています。 単純な読み取りと書き込みでも、パフォーマンスの差はほとんどゼロになりました。
PCI DSS。 単純なものから難しくするものまで、そしてウェブが起業家になる方法
開発段階でさえ、生産に入るかなり前に、カード番号自体を含む銀行カード情報を使用した小さなシンプルなサービスがありました。もちろん、 PostgreSQL を使用して暗号化しました 。 同時に、理論的には、運用管理者はおそらくこの暗号化の鍵をどこかで見つけて何かを見つけることができますが、私たちは彼を完全に信頼していました。
サービスの信頼性は、 アクティブスタンバイによって実装されました。サービスが小さいため、すぐに再起動し、他のコンポーネントは3〜5秒待機するため、何らかの複雑なクラスターシステムを積み上げるのは意味がありません。
開始前に、PCI DSS監査を開始しましたが、データアクセス制御にはかなり厳しい要件があり、監査人の場合、次の事実に要約されました。
- データベースからすべての情報を読むことができる人が一人いるべきではありません。 一緒にアクセスする必要があるのは、少なくとも数人でなければなりません。
- アクセスキーの定期的な変更が必要です。
- PCI DSSでは、検出された脆弱性のインフラストラクチャを更新する必要があります。オペレーティングシステムとインフラストラクチャソフトウェアの脆弱性は非常に一般的であるため、システムも頻繁に更新する必要があります。
そもそも、キーを知っている人が1人もいない場合は、オペレーションマネージャーへの信頼を停止し、スキームを考え出そうとします。

論理的にシャミール計画に到達します。 これは、既製のキーに基づいていくつかのキーが生成され、そのサブセットが元のキーを生成できる場合のキー生成方法です。
たとえば、長いキーを作成し、すぐに5つのピースに分割して、3つのうちどれでも元のキーを生成できるようにします。 その後、これら3つの操作を分散し、誰かが病気になったり、バスに乗ったりする場合に備えて、2つを金庫に保管し、安心して生活します。 オリジナルの長いキーは不要で、これらのピースのみが必要です。
サービスでシャミールスキームに切り替えた後、キーを生成および変更するロジックが表示されることは明らかです。 キーを生成するために、別個のvirtualochkaが使用されます。
- キーが生成されます
- 管理者に配布
- virtualochkaが殺されます。
その結果、SB-schnikovの存在下で急速に死にかけているシステム上で作成され、「生成された」キーのみが配布されるため、誰も元のキーを認識できません。
キーを変更するとき、同時に2つの実際のキーをシステムに保持できることがわかります。1つは古いもので、もう1つは新しいもので、データの一部は古いもので暗号化されます。新しいキーを再暗号化する手順が必要です。
コンポーネントを今すぐ開始するには2〜3人かかるため、これには30秒ではなく数分かかります。 そのため、再起動時の単純なコンポーネントには数分かかり、複数のインスタンスが同時に動作するアクティブ/アクティブスキームに切り替える必要があります。
したがって、数十行の単純で明白なサービスは、かなり複雑な設計になります。複雑な開始ロジック、クラスタリング、やや複雑な保守指示が必要です。 通常のシンプルなウェブから、私たちは喜んで起業家になりました。 そして、残念なことに、これは非常に頻繁に発生します。 さらに、トップマネジメントとビジネスは、全体を見て、今と同じように万が一のためにすべてのデータを暗号化する必要があり、どこでもActive-Activeが好きだと言いました。 そして、率直に言って、これらのビジネス上の欲求は必ずしも簡単に実現できるとは限りません。
支払いのロジック。 難しいものからシンプルなものまで
私が言ったように、支払いは非常に複雑です。 以下は、ユーザーから最終的なカウンターパーティに送金するプロセスの例示的な図ですが、すべてが図にあるわけではありません。 支払いの過程で、一部の外部エンティティに多くの依存関係があります。銀行、取引相手、銀行情報システム、トランザクション、トランザクションがあり、これらすべてが確実に機能するはずです。
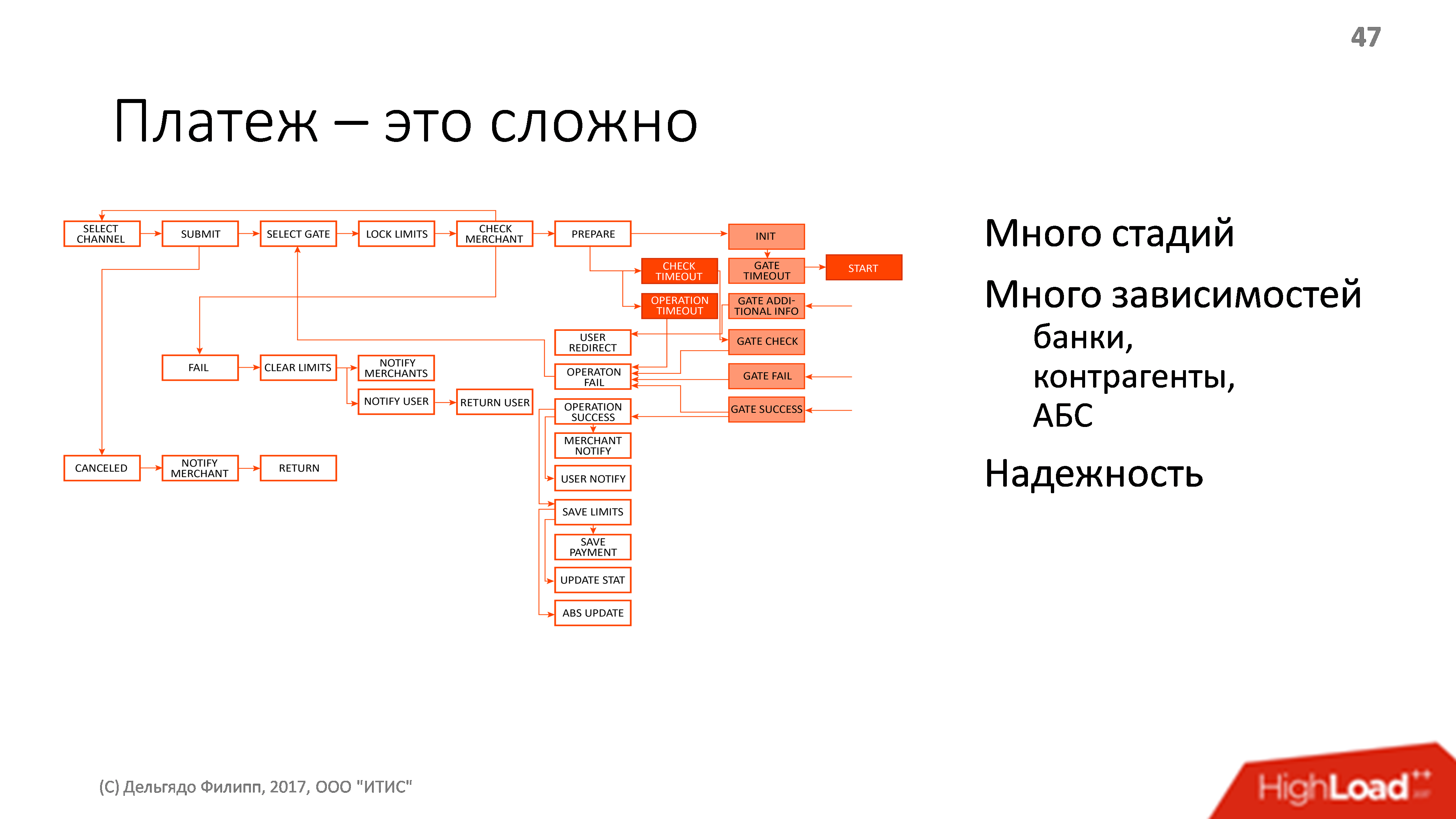
信頼できる-これは、お金が誰の側にあるか、そしてすべてが今落ちているかどうか、誰からこのお金を要求するかを常に知っていることを意味します。 最も重要なことは、私たちとではなく、相手方で凍結する可能性があります。 そして、これらすべてを確認してユーザーに報告できるように、彼らが誰から垂れ下がっているのかを正確に知る必要があり、もちろん、できるだけ問題が少ないことが望ましい。
有限状態マシン

もちろん、最初はFSM (通常の状態マシン)があり、各イベントはトランザクションで処理されます。 現在の状態もDBMSに保存されます。 すべて自分で実装。
最初の問題は、同時イベントがあることです。
たとえば、支払いの開始を確認するユーザーに関連するイベントを処理します。 この時点で、取引の可能性をキャンセルする取引先からのイベントが発生し、このイベントも処理する必要があります。 したがって、作業のロジックでは、何らかの種類のリソースロックを取得したり、ロック解除が解除されるのを待ったりします。 幸いなことに、最初はすべての支払い処理が1台のマシンで行われ、ロックはJVMレベルで実装できました。
さらに、多くのステップには明確な最大実行時間(タイムアウト)があり、これらの時間は、タイムアウトイベントが発生したときにどこかで保存、処理、監視する必要があります(同時に発生します)。
これはすべて、Javaマシン内のロックのロジックを介して実装されました。これは、データベースでは非常に簡単ではないためです。 その結果、Active-Standbyのみを使用した高可用性組織と、コンテキストおよびタイムアウトを回復するための一連の特別なロジックを備えたシステムが得られました。
負荷はかなり小さく、1秒あたりの支払いはわずか数十、最大潜在ピークの場合は100未満です。 ただし、この場合、1秒あたり10回の支払いでも、1秒あたり100件のリクエスト(個別のステップ)になります。 これらは小さな負荷なので、1台の車でほぼ常に十分です。
すべてが素晴らしかったが、アクティブ-アクティブが必要だった。
アクティブアクティブ
まず、Shamirスキームを使用したいと思いました。また、他のウィッシュリストも登場しました。ユーザーの3%にのみ新しいバージョンを投稿しましょう。 支払いのロジックを頻繁に変更しましょう。 停止時間ゼロなどでアップロードしたい
分散ロックを行うのは悲しいですが、分散タイムアウトを行うのも悲しいです。 そして、もう一度私たちは理解し始めました-支払いとは何ですか? 支払いは、厳密に順番に処理する必要がある一連のイベントであり、複雑で変更可能な状態であり、支払い処理は並行して実行する必要があります。
定義を誰が認識しましたか? そうです、 支払いは俳優です。
Javaにはさまざまなアクターモデルがあります。 美しいAkkaがあり、時には奇妙だがクールなVert.xがあり、 クエーサーははるかに少ない。 それらはすべて素晴らしいですが、根本的な欠陥が1つあります(あなたが考えたものではありません)- 保証が不十分です。
それらはいずれもアクター間のメッセージ配信を保証するものではなく、すべてがデータベース内のトランザクション内での作業に問題があります。
私たちは長い間それを見て、何かを正常な状態に仕上げることができるかどうかを考えましたが、その後、バイクを作りました:PostgreSQLのキューは更新スキップのロックを選択します。

ソリューション全体が数千行のコードになり、開発に約2週間、テストと改良に約2週間かかりました。 同時に、通常は同じAkkaで行うことのできない社内のニーズの多くが満たされました。
ロックをスキップ
これは、PostgreSQLでキューを実装するのに最適です。 実際、このメカニズムは、MySQLを除くすべてのデータベースにあります。
2つのラベルがあるとしましょう:アクターを持つラベル-フロー、およびこれらのアクターのイベントラベルは、フロー列で接続されています。 イベントは自動インクリメントキーIDでソートされ、すべて正常です。 SQLクエリを作成しています。

フローの最初のイベントで最初のイベントを選択し、更新スキップロックのマジックを指定します。 プレートにロックがない場合、リクエストは通常の更新とまったく同じように機能します。ロックを取得し、選択した最初の行にロックを設定します。 最初のアクターの行と、このアクターの最初のイベントの行。
同じクエリを2回実行し、まったく同じことを行いますが、すでにロックされている行をスキップします。 したがって、彼は2番目のアクター(テーブルの3行目)で最初のイベントを選択し、ロックをかけます。
この間に、最初のイベントの処理を完了し、それを削除して、トランザクションを閉じたとします。 ロックが解除されたため、次にリクエストを完了したときに、最初のアクターの最初のイベントを取得します。

すべて十分に高速かつ確実に動作します。 安価なハードウェアでは、各操作が約10ミリ秒遅くなるという条件で、1秒あたり約1000のそのような操作を受け取りました。 私はこのアプローチを数回使用しました。すべてのコードは文字通り3行で書かれており、あらゆる種類の便利なものをそのようなキューに簡単に追加できます。
このようなキューでは何が得られますか?

すべてのメッセージはトランザクションです: トランザクションを開始し、データベースで何かをし、どこかで他のアクターにメッセージを送信します。トランザクションがロールバックされると、メッセージも送信されません。これは非常に便利です。
前のメッセージをキャンセルするメッセージを送信することを考える必要はありません。処理の最後とコミット後にのみ、すべてのメッセージをバッチで送信することを考える必要はありません。 一般に、多くのことについて考えることをやめます。 たとえば、 ロックについて考える必要はありません。すべてのイベントは順番に処理されるため、実際にはアクターが発明されたからです。
実装では、支払いロジックの80%が実際に起こりうるエラーを処理しているため、 複雑なエラー処理ポリシーも追加しました。別の取引先、別のゲートウェイなどを選択する必要があります。 あらゆる種類のエラーを処理するための非常に多くの異なる複雑なロジックがあります。
私たちにとって、このソリューションは効果的です -1秒あたり100の支払いが私たちに合っています。
しかし、このソリューションの適用範囲は非常に限られています。独自の自転車は、どこでもかなり使用できます。 . . , , 100 . , , , , . , enterprise- — OpenSource .
. , — . — .
— - . , , , , . , . , , .
: , , . , . . : , - .
, . — . , PostgreSQL , — . PostgreSQL, , — . - , . , .
, . , - , , , . , , - . , — 100 — . .
. , , . , - , .
, , , . , , , skip locked - Redis Lua , . , .
, ( ). , .
— - , . : « », . , , , , , . !
. Business Intelligence
, , , . Business Intelligence . , - , - , . — « ».
Power BI — ?

PowerBI — Microsoft: csv, csv , PowerBI. , , , , . csv — .
, — , — . 1 , , , , Microsoft 1 . , .
, .
ClickHouse
— , ClickHouse! Kafk, ClickHouse, , , , , , . ClickHouse - . Clickhouse Redash. Redash, — , , , , drill-down .
, . - Tableau, . Tableau Vertica, , -, : Kafka, Kafka Vertica.
Vertica , , , , Tableau Server . — Vertica , , , ,. Tableau . , , , Vertica — , Community Edition , . Tableau -, - . , , , Tableau.
, , enterprise- , web- . , . Vertica : . — . , , .

, , ClickHouse, Tableau , ClickHouse - .
内容
:
- , , ..;
- , , ;
- ;
- ;
- .
. , , , , , , , . — : , , .

: -, , , -, . , .
, CS. CS , :
- ;
- , ;
- ;
- Java-.
CS — , , , .
, , Git : . Git - , - , - git .
, , , IntelliJ IDEA, Git . , , JetBrains , .
:
- .
- html, html, CMS .
- — , , . .
- ( ) - . Jira, , — , , , , .

, , - enterprise.
, — . embedded CMS , , -, . , , , , .
結論

? .
web, enterprise, , . , Vertica, .
, IBM DB2 — , , , . , - , , .
enterprise web- , .
— .

. , - . — , , . — , .
Java SQL — , . , , , ,
ニュース
HighLoad++ 2018 8 9 , Percona Live.
Highload++ Siberia , 25 26 , , , , — .
++ , . :
- « ClickHouse » ClickHouse .
- Yuri Lilekovが、開発者が統計を必要とする理由、または製品の品質を改善する方法についてのレポートをお持ちですか?
- Alexander Serbul が、ラムダアーキテクチャの機能、Amazon Lambdaマイクロサービスプラットフォーム、およびNode.JSとマルチスレッドJavaの落とし穴と勝利について説明します。