このファイルはハードドライブ上でどのくらいのスペースを占有しますか? どれくらいの空き容量がありますか? 残りのスペースにさらにいくつのファイルを収めることができますか?

これらの質問に対する答えは明らかです。 私たちは皆、ファイルシステムの仕組みを直感的に理解しており、多くの場合、バスケットにリンゴを入れるのと同じ方法でファイルをディスクに保存することを想像しています。
ただし、最新のLinuxシステムでは、このような直感は誤解を招く可能性があります。 理由を見てみましょう。
ファイルサイズ
ファイルサイズは? 答えは簡単なようです:ファイルの最初から最後まで、その内容のすべてのバイトのコレクション。
多くの場合、ファイルの内容全体がバイトごとに表示されます。

また、 ファイルサイズの概念も認識しています 。 調べるには、
ls -l file.c
または
stat
コマンド(つまり
stat file.c
)を実行し、
stat()
システムコールを行います。
Linuxカーネルでは、ファイルを表すメモリ構造はinodeです。 そして、
stat
コマンドでアクセスするメタデータはiノードにあります。
スニペット
include/linux/fs.h
:
struct inode { /* excluded content */ loff_t i_size; /* file size */ struct timespec i_atime; /* access time */ struct timespec i_mtime; /* modification time */ struct timespec i_ctime; /* change time */ unsigned short i_bytes; /* bytes used (for quota) */ unsigned int i_blkbits; /* block size = 1 << i_blkbits */ blkcnt_t i_blocks; /* number of blocks used */ /* excluded content */ }
ここでは、アクセス時間や変更時間などの使い慣れた属性と
i_size
できます。これは、上記で定義したファイルサイズです。
ファイルサイズの観点から考えることは直感的ですが、 実際にスペースがどのように使用されるかに関心があります。
ブロックとブロックサイズ
内部ファイルストレージの場合、ファイルシステムはストレージをブロックに分割します 。 従来のブロックサイズは512バイトでしたが、より適切な値は4キロバイトです。 一般に、この値を選択する場合、標準のMMU機器(メモリ管理ユニット、「メモリ管理デバイス 」- 約Transl。 )でサポートされているページサイズによってガイドされます。
ファイルシステムは、これらのブロックにチャンクファイルを挿入し、メタデータで監視します。 理想的には、次のようになります。

...しかし、実際にはファイルは常に作成、サイズ変更、削除されているため、実際の状況は次のとおりです。
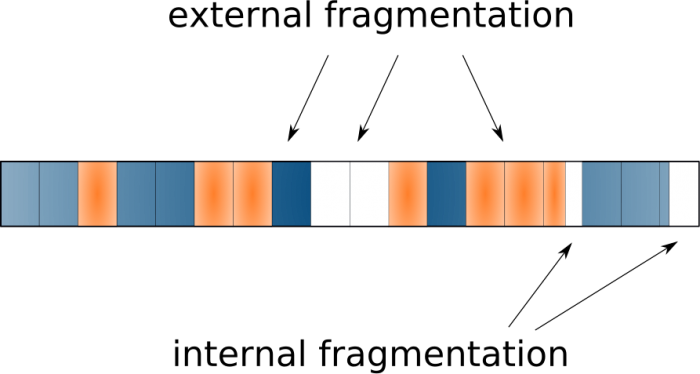
これは外部フラグメンテーションと呼ばれ、通常はパフォーマンスが低下します。 その理由は、ハードディスクの回転ヘッドがすべての断片を収集するために場所から場所へ移動しなければならず、これが遅い操作だからです。 従来のデフラグツールはこの問題に対処します。
4 KBより小さいファイルはどうなりますか? ファイルが断片に分割された後、最後のブロックの内容はどうなりますか? 未使用のスペースは自然に発生します。これは内部フラグメンテーションと呼ばれます。 明らかに、この副作用は望ましくなく、特に非常に小さなファイルが多数ある場合は、多くの空き領域が使用されないという事実につながる可能性があります。
そのため、ファイルによるディスクの実際の使用は、
stat
、
ls -ls file.c
du file.c
または
du file.c
を使用して確認できます。 たとえば、1バイトのファイルの内容は依然として4 KBのディスク容量を占有します。
$ echo "" > file.c $ ls -l file.c -rw-r--r-- 1 nacho nacho 1 Apr 30 20:42 file.c $ ls -ls file.c 4 -rw-r--r-- 1 nacho nacho 1 Apr 30 20:42 file.c $ du file.c 4 file.c $ dutree file.c [ file.c 1 B ] $ dutree -u file.c [ file.c 4.00 KiB ] $ stat file.c File: file.c Size: 1 Blocks: 8 IO Block: 4096 regular file Device: 2fh/47d Inode: 2185244 Links: 1 Access: (0644/-rw-r--r--) Uid: ( 1000/ nacho) Gid: ( 1000/ nacho) Access: 2018-04-30 20:41:58.002124411 +0200 Modify: 2018-04-30 20:42:24.835458383 +0200 Change: 2018-04-30 20:42:24.835458383 +0200 Birth: -
したがって、ファイルサイズと使用済みブロックの2つの値を確認します。 私たちは前者の観点から考えることに慣れていますが、後者の観点から考えなければなりません。
ファイルシステム固有の機能
ファイルの実際の内容に加えて、カーネルはあらゆる種類のメタデータも保存する必要があります。 すでにiノードメタデータを見ましたが、すべてのUNIXユーザーが使い慣れている他のデータがあります : アクセス権 、 所有者 、 uid 、 gid 、フラグ、 ACL 。
struct inode { /* excluded content */ struct fown_struct f_owner; umode_t i_mode; unsigned short i_opflags; kuid_t i_uid; kgid_t i_gid; unsigned int i_flags; /* excluded content */ }
最後に、他の構造があります-ファイルシステム自体の表現を持つスーパーブロック 、マウントポイントの表現を持つvfsmount 、 および冗長性、名前空間などに関する情報があります。 後で見るように、このメタデータの一部は重要な場所を占めることもあります。
ブロック配置メタデータ
このデータは、使用するファイルシステムに大きく依存します。各データシステムには、ブロックをファイルにマップする独自の方法があります。 ext2の従来のアプローチは、直接および間接ブロックを持つ
i_block
テーブルです。
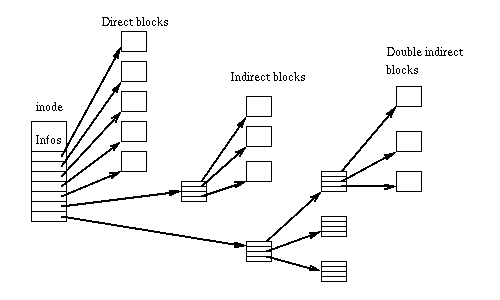
同じテーブルがメモリ構造に見られます(
fs/ext2/ext2.h
):
/* * Structure of an inode on the disk */ struct ext2_inode { __le16 i_mode; /* File mode */ __le16 i_uid; /* Low 16 bits of Owner Uid */ __le32 i_size; /* Size in bytes */ __le32 i_atime; /* Access time */ __le32 i_ctime; /* Creation time */ __le32 i_mtime; /* Modification time */ __le32 i_dtime; /* Deletion Time */ __le16 i_gid; /* Low 16 bits of Group Id */ __le16 i_links_count; /* Links count */ __le32 i_blocks; /* Blocks count */ __le32 i_flags; /* File flags */ /* excluded content */ __le32 i_block[EXT2_N_BLOCKS];/* Pointers to blocks */ /* excluded content */ }
大きなファイルの場合、単一の(大きな)ファイルには数千のブロックを一致させる必要があるため、このようなスキームは大きなオーバーヘッドにつながります。 さらに、ファイルサイズにも制限があります。この方法を使用すると、ext3 32ビットファイルシステムは8 TB以下のファイルをサポートします。 Ext3開発者は 48ビットをサポートし、 エクステントを追加することで状況を保存しました :
struct ext3_extent { __le32 ee_block; /* first logical block extent covers */ __le16 ee_len; /* number of blocks covered by extent */ __le16 ee_start_hi; /* high 16 bits of physical block */ __le32 ee_start; /* low 32 bits of physical block */ };
アイデアは本当にシンプルです。ディスク上の隣接するブロックを占有し、エクステントの開始位置とサイズを宣言するだけです。 したがって、ブロックの大きなグループをファイルに割り当てて、メタデータの量を最小限に抑えながら、より高速な順次アクセスを使用できます。
奇妙なことに注意してください:ext4には後方互換性があります 。つまり、 間接およびエクステントの両方のメソッドをサポートします 。 書き込み操作の例により、スペースがどのように分散されているかを確認できます。 記録はストレージに直接送られません-パフォーマンス上の理由から、データは最初にファイルキャッシュに送られます。 その後、ある時点で、キャッシュは永続ストレージに情報を書き込みます。
ファイルシステムキャッシュは、 writepages操作が呼び出される
address_space
構造体で表され
address_space
。 シーケンス全体は次のようになります。
(cache writeback) ext4_aops-> ext4_writepages() -> ... -> ext4_map_blocks()
...
ext4_map_blocks()
は、エクステントが使用されているかどうかに応じて
ext4_ext_map_blocks()
または
ext4_ind_map_blocks()
関数を呼び出します。
extents.c
の最初の部分を見ると、後述の穴への参照を確認できます。
チェックサム
最新世代のファイルシステムは、データブロックのチェックサムも保存して、 慎重なデータ破損を防ぎます 。 この機能を使用すると、ランダムエラーを検出して修正できます。もちろん、ファイルのサイズに比例して、ディスクの使用時に追加のオーバーヘッドが発生します。
BTRFSやZFSのような最新のシステムはデータのチェックサムをサポートしていますが、ext4のような古いシステムはメタデータのチェックサムを持っています。
ロギング
ext2のロギング機能はext3で登場しました。 ログ-停電に対する耐性を向上させるために、処理されたトランザクションを記録する循環ログ。 デフォルトでは、 メタデータにのみ適用されますが、パフォーマンスに影響する
data=journal
オプションを使用して、
data=journal
に対してアクティブ化できます。
これは通常8のiノード番号と128 MBのサイズを持つ特別な隠しファイルで、その説明は公式ドキュメントにあります:
ext3ファイルシステムに表示されるログは、システム障害が発生した場合の損傷からFSを保護するためにext4で使用されます。 小さなシーケンシャルディスクフラグメント(デフォルトでは128 MB)は、「重要な」ディスク書き込みを可能な限り迅速にドロップする場所としてFS内に予約されています。 重要なデータを持つトランザクションがディスクに完全に書き込まれ、キャッシュ(ディスク書き込みキャッシュ)からフラッシュされると、データレコードもログに書き込まれます。 後で、ログコードは、このデータに関する書き込みが消去される前に、ディスク上の最終位置にトランザクションを書き込みます(操作により、長時間の検索または多数の読み取り-削除-削除操作が発生する可能性があります)。 2回目の低速書き込み操作中にシステム障害が発生した場合、ジャーナルを使用すると、最後の記録までのすべての操作を再生でき、ジャーナルを介してディスクに書き込まれるすべての原子性を保証します。 その結果、メタデータの更新の途中でファイルシステムが停止しないことが保証されます。
テール包装
ブロックのサブ割り当てとも呼ばれるテールパッキング機能により、ファイルシステムは最後のブロックの末尾の空きスペース(「テール」)を使用し、それを異なるファイルに分散して、「テール」を単一のブロックに効果的にパックできます。
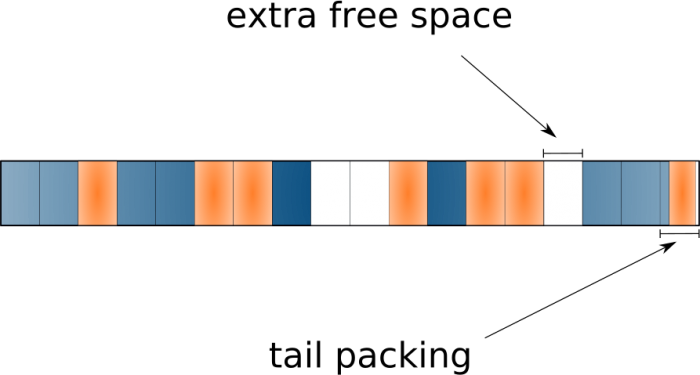
多くの小さなファイルがある場合は特に、多くのスペースを節約できることは素晴らしいことですが...しかし、既存のツールが使用されたスペースを正確に報告しないという事実につながります。 そのため、すべてのファイルの占有ブロックをすべて追加して、ディスク使用量に関する実際のデータを取得することはできません。 この機能は、BTRFSおよびReiserFSファイルシステムでサポートされています。
スパースファイル
最新のファイルシステムのほとんどは、 スパースファイルをサポートしています 。 このようなファイルには、実際にディスクに書き込まれないホールが含まれる場合があります(ディスク容量を占有しないでください)。 今回は、実際のファイルサイズは使用されるブロックよりも大きくなります。
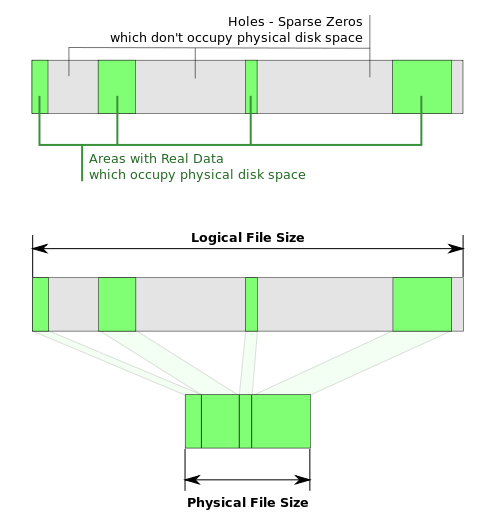
このような機能は、たとえば、大きなファイルをすばやく生成したり、要求に応じて仮想マシンの仮想ハードディスクに空き領域を提供したりする場合に非常に役立ちます。
約10 GBのディスク容量を占有する10ギガバイトのファイルをゆっくり作成するには、次を実行できます。
$ dd if=/dev/zero of=file bs=2M count=5120
同じ大きなファイルをすぐに作成するには、最後のバイトを書き込むか、または次のようにします。
$ dd of=file-sparse bs=2M seek=5120 count=0
または、
truncate
コマンドを使用します。
$ truncate -s 10G
ファイルに割り当てられたディスク容量は、
fallocate()
システムコールを行う
fallocate
コマンドで変更できます。 この呼び出しでは、さらに高度な操作を使用できます。例:
- ゼロを挿入して、ファイルのスペースを事前に割り当てます。 この操作により、ディスク領域の使用量とファイルサイズの両方が増加します。
- スペースを解放します。 この操作により、ファイルに穴が作成され、ファイルがまばらになり、ファイルサイズに影響を与えることなくスペースの使用が削減されます。
- ファイルサイズとディスク使用量を削減して、スペースを最適化します。
- 末尾に穴を挿入して、ファイルスペースを増やします。 ファイルサイズは増加しており、ディスク使用量は変化していません。
- 穴をリセットします。 穴は、ディスクに書き込まれるエクステントではなく、ディスクスペースとその使用に影響を与えずにゼロとして読み取られます。
たとえば、次のように、ファイルをスパースに変えることでファイルに穴を作成できます。
$ fallocate -d file
cp
コマンドは、スパースファイルの操作をサポートしています。 単純なヒューリスティックを使用して、ソースファイルがスパースかどうかを判断しようとします。そうであれば、結果のファイルもスパースになります。 次のように、非スパースファイルをスパースファイルにコピーできます。
$ cp --sparse=always file file_sparse
...逆のアクション(スパースファイルの「高密度」コピーを作成する)は次のようになります。
$ cp --sparse=never file_sparse file
したがって、スパースファイルを使用したい場合は、次のエイリアスを端末環境に追加できます(
~/.zshrc
または
~/.bashrc
)。
alias cp='cp --sparse=always'
プロセスが穴のセクションのバイトを読み取ると、ファイルシステムはそれらにゼロのページを提供します。 たとえば、ext4のホール領域にあるファイルシステムからファイルキャッシュが読み取られたときに何が起こるかを確認できます。 この場合、
readpage.c
のシーケンスは
readpage.c
ようになります。
(cache read miss) ext4_aops-> ext4_readpages() -> ... -> zero_user_segment()
その後、プロセスが
read()
システムコールでアクセスしようとしているメモリセグメントは、高速メモリから直接ゼロを取得します。
COWファイルシステム(コピーオンライト)
次の(extファミリの後の)ファイルシステムの生成は、いくつかの非常に興味深い機能をもたらしました。 おそらく、ZFSやBTRFSのようなファイルシステムの機能の中で最大の注目は、COW(copy-on-write、 "copy-on-write")に値するでしょう。
コピーオンライトまたはクローン 操作 、またはreflinkコピー 、またはシャローコピーを実行する場合、実際にはエクステントの重複はありません。 新しいファイルのメタデータに注釈を作成するだけで、元のファイルの同じエクステントを参照し、エクステント自体はsharedとしてマークされます。 同時に、個別に変更できる2つの個別のファイルがあるという錯覚がユーザー空間に作成されます。 プロセスが共有エクステントに書き込みたい場合、カーネルは最初にそのコピーを作成し、このエクステントが単一のファイルに属することを注釈します(少なくとも現時点では)。 その後、2つのファイルにはさらに違いがありますが、多くのエクステントで共有できます。 つまり、COW対応ファイルシステムのエクステントはファイル間で分割でき、FSは必要な場合にのみ新しいエクステントの作成を保証します。
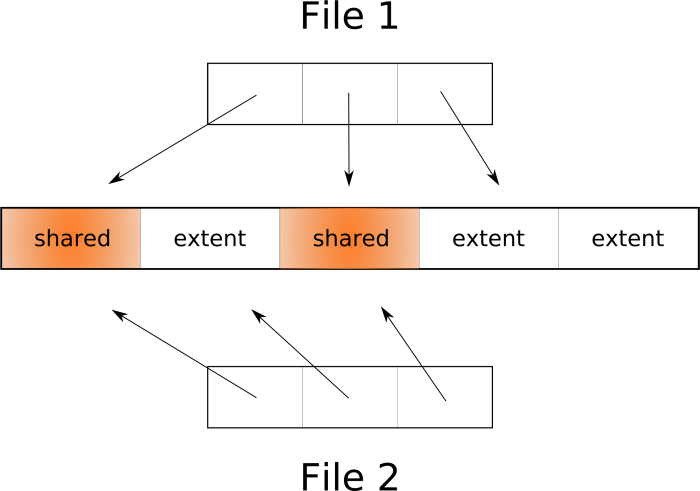
ご覧のとおり、クローン作成は非常に高速な操作であり、通常のコピーの場合に使用されるスペースを2倍にする必要はありません。 BTRFSおよびZFSでインスタントスナップショットを作成する可能性の背後にあるのは、このテクノロジーです。 文字通り、ルートファイルシステム全体を1秒未満で複製(またはスナップショット )できます。 たとえば、何かが壊れた場合にパッケージを更新する前に非常に便利です。
BTRFSは、浅いコピーを作成するための2つの方法をサポートしています。 最初はサブボリュームを参照し、
btrfs subvolume snapshot
を使用します。 2番目は個々のファイル用で、
cp --reflink
を使用し
cp --reflink
。 デフォルトで高速の浅いコピーを作成する場合、このようなエイリアス(
~/.zshrc
または
~/.bashrc
)が
~/.zshrc
ます。
cp='cp --reflink=auto --sparse=always'
次のステップは、非浅いコピーまたはファイル、またはエクステントが重複するファイルがある場合、それらを重複排除して、共通のエクステントを(reflinkを介して)使用し、スペースを解放することができます。 このためのツールの1つはduperemoveです 。ただし、これによりファイルの断片化が自然に増加することに注意してください。
ここで、ファイルによってディスク領域がどのように使用されるかを理解しようとすると、事態はそれほど単純ではありません。
du
やdutreeのようなユーティリティは、ブロックの一部が共有されている可能性を考慮せずに、使用されているブロックのみを考慮します。
同様に、BTRFSの場合は、BTRFSファイルシステムによって占有されているスペースが空きとして表示されるため、
df
コマンドは使用しないでください。
btrfs filesystem usage
を使用する方が良い:
$ sudo btrfs filesystem usage /media/disk1 Overall: Device size: 2.64TiB Device allocated: 1.34TiB Device unallocated: 1.29TiB Device missing: 0.00B Used: 1.27TiB Free (estimated): 1.36TiB (min: 731.10GiB) Data ratio: 1.00 Metadata ratio: 2.00 Global reserve: 512.00MiB (used: 0.00B) Data,single: Size:1.33TiB, Used:1.26TiB /dev/sdb2 1.33TiB Metadata,DUP: Size:6.00GiB, Used:3.48GiB /dev/sdb2 12.00GiB System,DUP: Size:8.00MiB, Used:192.00KiB /dev/sdb2 16.00MiB Unallocated: /dev/sdb2 1.29TiB $ sudo btrfs filesystem usage /media/disk1 Overall: Device size: 2.64TiB Device allocated: 1.34TiB Device unallocated: 1.29TiB Device missing: 0.00B Used: 1.27TiB Free (estimated): 1.36TiB (min: 731.10GiB) Data ratio: 1.00 Metadata ratio: 2.00 Global reserve: 512.00MiB (used: 0.00B) Data,single: Size:1.33TiB, Used:1.26TiB /dev/sdb2 1.33TiB Metadata,DUP: Size:6.00GiB, Used:3.48GiB /dev/sdb2 12.00GiB System,DUP: Size:8.00MiB, Used:192.00KiB /dev/sdb2 16.00MiB Unallocated: /dev/sdb2 1.29TiB
残念ながら、COWファイルシステム内の個々のファイルの占有スペースを追跡する簡単な方法は知りません。 サブボリュームレベルでは、 btrfs-duなどのユーティリティを使用して、スナップショットに固有であり、スナップショット間で共有されるデータ量の概算を取得できます。
参照資料
翻訳者からのPS
ブログもご覧ください。