
Mail.ru Mailから、3つのタスクが提供されました。
- 会社のロゴの認識と分類。 このタスクは、フィッシングメールを検出するスパム対策に役立ちます。
- 手紙のテキストの決定、その部分は特定のカテゴリに属します。 名前付きエンティティ認識(NER)
- 後者のタスクの実装は規制されていません。 Mailの新しい便利な関数のプロトタイプを作成して作成する必要がありました。 評価基準は、有用性、実装の品質、MLアプリケーション、誇大宣伝機能でした。
最初の2つのタスクから1つのタスクを選択することが許可され、3番目のタスクのソリューションでは自由に参加することができました。 2番目のタスクを選択したのは、最初のタスクでは作業経験の少ないニューロンが確実に勝つことを理解していたからです。 しかし、2番目のタスクでは、クラシックMLが起動することを期待していました。 一般的に、ハッカソン中に競合チームと解決策やアイデアを話し合うことができたため、タスクの分離のアイデアが本当に気に入りました。
ハッカソンは、パブリックリーダーボードがなかったことで注目に値します。モデルは、ハッカソンの終了時にクローズドデータセットでテストされました。
タスクの説明
注文を確認したり、プロモーションを送信したりする店舗からの手紙を受け取りました。 ソース電子メールに加えて、解析モデル用のスクリプトが提供され、その結果はトレーニングモデルのデータセットでした。
文字は行ごとに解析され、各行はトークンに分割され、各トークンにはラベルが付けられます。
タグ付きデータの例
# [](http://t.adidas-news.adidas.com/res/adidas-t/spacer.gif)
39 []( OUT
39 http OUT
39 :// OUT
39 t OUT
39 . OUT
39 adidas OUT
39 - OUT
39 news OUT
39 . OUT
39 adidas OUT
39 . OUT
39 com OUT
39 / OUT
39 res OUT
39 / OUT
39 adidas OUT
39 - OUT
39 t OUT
39 / OUT
39 spacer OUT
39 . OUT
39 gif OUT
39 ) OUT
39 B-PRICE
39 PRICE
39 PRICE
マークアップされたファイルには、最初に「#」文字で始まる解析行があり、次に解析結果は3つの列の形式(行番号、トークン、クラスラベル)にあります。
タグには次の種類があります。
- 製品アイテム:B-ARTICUL、ARTICUL
- 注文とその番号:B-ORDER、ORDER
- 注文の合計金額:B-PRICE、PRICE
- 注文製品:B-PRODUCT、PRODUCT
- アイテムタイプ:B-PRODUCT_TYPE、PRODUCT_TYPE
- 売り手:B-SHOP、SHOP
- 他のすべてのトークン:OUT
必須のプレフィックス「B-」は、文のトークンの始まりを示します。 モデルを評価するために、OUTを除くすべてのラベルにf1メトリックを使用しました。
ログブックのベースラインとしてのスコア
Training time 157.34269189834595 s
================================================TRAIN======================================
+++++++++++++++++++++++ ARTICUL +++++++++++++++++++++++
Tokenwise precision: 0.0 Tokenwise recall: 0.0 Tokenwise f-measure: 0.0
+++++++++++++++++++++++ ORDER +++++++++++++++++++++++
Tokenwise precision: 0.7981220657276995 Tokenwise recall: 0.188470066518847 Tokenwise f-measure: 0.30493273542600896
+++++++++++++++++++++++ PRICE +++++++++++++++++++++++
Tokenwise precision: 0.9154929577464789 Tokenwise recall: 0.04992319508448541 Tokenwise f-measure: 0.09468317552804079
+++++++++++++++++++++++ PRODUCT +++++++++++++++++++++++
Tokenwise precision: 0.6538461538461539 Tokenwise recall: 0.0160075329566855 Tokenwise f-measure: 0.03125000000000001
+++++++++++++++++++++++ PRODUCT_TYPE +++++++++++++++++++++++
Tokenwise precision: 0.5172413793103449 Tokenwise recall: 0.02167630057803468 Tokenwise f-measure: 0.04160887656033287
+++++++++++++++++++++++ SHOP +++++++++++++++++++++++
Tokenwise precision: 0.0 Tokenwise recall: 0.0 Tokenwise f-measure: 0.0
+++++++++++++++++++++++ CORPUS MEAN METRIC +++++++++++++++++++++++
Tokenwise precision: 0.7852941176470588 Tokenwise recall: 0.05550935550935551 Tokenwise f-measure: 0.1036893203883495
================================================TEST=======================================
+++++++++++++++++++++++ ARTICUL +++++++++++++++++++++++
Tokenwise precision: 0.0 Tokenwise recall: 0.0 Tokenwise f-measure: 0.0
+++++++++++++++++++++++ ORDER +++++++++++++++++++++++
Tokenwise precision: 0.8064516129032258 Tokenwise recall: 0.205761316872428 Tokenwise f-measure: 0.3278688524590164
+++++++++++++++++++++++ PRICE +++++++++++++++++++++++
Tokenwise precision: 0.8666666666666667 Tokenwise recall: 0.05263157894736842 Tokenwise f-measure: 0.09923664122137404
+++++++++++++++++++++++ PRODUCT +++++++++++++++++++++++
Tokenwise precision: 0.4 Tokenwise recall: 0.0071174377224199285 Tokenwise f-measure: 0.013986013986013988
+++++++++++++++++++++++ PRODUCT_TYPE +++++++++++++++++++++++
Tokenwise precision: 0.3333333333333333 Tokenwise recall: 0.011627906976744186 Tokenwise f-measure: 0.02247191011235955
+++++++++++++++++++++++ SHOP +++++++++++++++++++++++
Tokenwise precision: 0.0 Tokenwise recall: 0.0 Tokenwise f-measure: 0.0
+++++++++++++++++++++++ CORPUS MEAN METRIC +++++++++++++++++++++++
Tokenwise precision: 0.7528089887640449 Tokenwise recall: 0.05697278911564626 Tokenwise f-measure: 0.10592885375494071
トレーニングデータセット内のラベルの分布は次のとおりです。
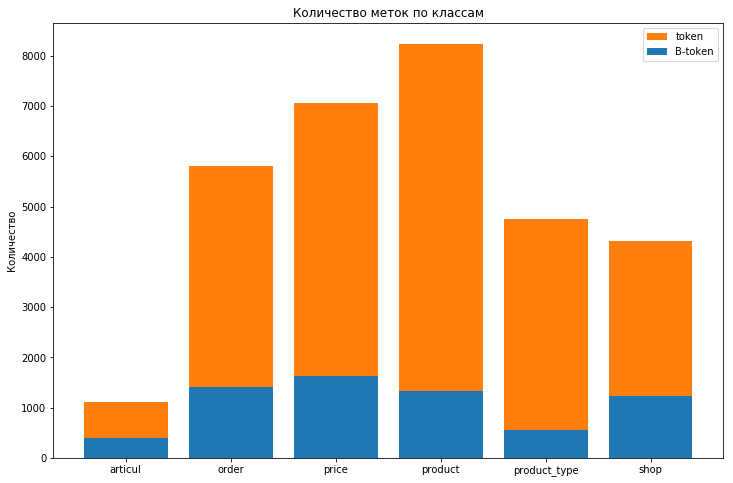
Outクラスのタグはほぼ580kです
強いクラスの不均衡が見られ、モデルの品質を評価するために考慮するOUTラベルはまったく意味がありません。 クラスの不均衡を考慮するために、class_weight = 'balanced'パラメーターをフォレストに追加しました。 ただし、電車とテストのスコアは(0.27と0.15から0.09と0.08に)減少しましたが、再訓練を取り除くことができました(これらの指標の差は減少しました)。
モデル
単語をベクトルとして表すために、ロシア語のfastTextの単語埋め込みを使用しました。これにより、トークンを300個の値のベクトルとして表すことができました。 チームの一部がニューロンを記述しようとしていた間に、logreg、ランダムフォレスト、knn、xgboostなどの標準的な分類アルゴリズムが試行されました。 テストの結果によれば、ニューロンが発進しない場合に備えて、ランダムフォレストがフォールバックとして選択されました。 他のモデルと比較して満足のいく品質でモデルをトレーニングし、予測する(競争の終わりに大幅に節約した)速度が速いことにより、選択が大きく正当化されました。
ODSからmlcourse_openコースをパスした経験があるため、高品質の機能のみがスコアを大幅に向上させることができることに気付き、残りの時間をかけてそれらを生成しました。 最初に思いついたのは、文のトークンインデックスなどの単純な記号を追加することでした。 トークンの長さ; トークンが英数字かどうか。 大文字または小文字のみで構成されます。 これにより、テストサンプルでメトリックf1が0.21に増加しました。 データセットをさらに調査すると、コンテキストが重要であると結論付け、それに応じて、2つの同一のトークンに異なるクラスラベルを付けることができます。 コンテキストを考慮するために、ウィンドウを取りました。前と次のトークンを記号のベクトルに追加しました。 これにより、スコアはすでに列車で0.55、テストで0.43に増加しました。 ハッカソンの最後の夜、私たちはウィンドウを拡大し、12ギガバイトのラップトップRAMにより多くの兆候を押し込もうとしました。 判明したように、それは詰め込みません。 これらの試みを放棄し、彼らは他の兆候をモデルに追加できるかについて考え始めました。 pymorphy2ライブラリに目を向けましたが、適切に固定できませんでした。
提出する
テストデータセットと最初の提出が発行されるまで、数時間かかりました。 データセットの発行後、予測を立てて主催者に送信するために1時間が与えられました-これが最初の提出でした。 その後、2回目の試行のためにさらに1時間与えられました。 それでは、前処理を開始し、サンプル全体のフォレストをトレーニングします。 また、私たちはまだニューロンへの信仰を捨てませんでした。 50本の木の森の前処理とトレーニングは驚くほど迅速に進みました:前処理に10分(埋め込み用の辞書の5分間のダウンロードを含む)、さらにサイズのマトリックス(609101、906)で森をトレーニングするのに10分。 この速度は、モデルを2番目のサブミットにすばやく調整して再トレーニングできることを示しているため、私たちを満足させました。 訓練された森林は、サンプル全体で0.59のスコアを示しました。 延期されたサンプルでのモデルの以前のテストを考えると、リーダーボードで少なくとも0.4の結果、または少なくとも0.3以上の結果を表示したいと考えました。
〜300,000トークンのテストデータセットを受け取り、既にトレーニング済みのモデルを持っているため、文字通り2分で予測を行いました。 彼らは0.2997のスコアを最初に受け取った。 他のチームの結果を待って、自分のモデルを改善する計画を考えて、ラベルを付けたテストサンプルをトレーニングセットに追加するというアイデアを思いつきました。 第一に、手作業によるマーキングが禁止されているため、これは規則に矛盾していませんでした。第二に、私たちはそれから何が起こるのだろうと思いました。 この時点で、他のチームの結果を学びました-それらはすべて私たちの後ろにあり、私たちは喜んで驚いていました。 しかし、私たちに最も近い結果は0.28で、これによりライバルは私たちを回避する機会を得ました。 また、彼らの袖に切り札がないこともわかりませんでした。 2時間目は緊張し、チームは最後まで提出し続け、トレーニングサンプルを増やすというアイデアは失敗しました。ラップトップは1.5倍のデータをメモリに押し込むというアイデアを嫌い、MemoryErrorは抗議してハングで応答しました。
時間が経過すると、最終的なリーダーボードが表示され、一部のチームは結果を改善し、一部のチームでは結果が悪化しましたが、まだ1位でした。 ただし、答えは検証されました。作業モデルを表示し、主催者の前で予測を行う必要がありました。また、ノートブックを再起動しました。 どうする その後、主催者は私たちに会いに行き、モデルが学習して予測するまで待つことに同意しました。 ただし、キャッチがありました。フォレストはランダムであり、SEEDを修正しなかったため、予測の精度は最後の桁まで確認する必要がありました。 最善を尽くすことを期待し、辞書がすでにロードされている2台目のラップトップでトレーニングを開始しました。 この時点で、主催者はデータとコードを注意深く調べ、モデル、機能について尋ねました。 ラップトップは私の神経に乗ることを止めず、時には数分間ハングアップしたため、時間さえ変わらなかった。 トレーニングが完了すると、予測を繰り返して主催者に送信しました。 この時点で、2台目のラップトップがトレーニングを完了し、両方のラップトップのトレーニングサンプルの予測が完全に一致したため、結果の検証の成功に対する信頼が高まりました。 そして今、数秒後に、主催者はあなたに勝利を祝福し、手を振る:)
まとめ
Mail.Ru Groupのオフィスで素晴らしい週末を過ごし、MailチームからMLおよびDLのトピックに関する興味深いレポートを聞きました。 クッキー、ミルクチョコレート(ただし、ミルクは有限ですが補充されたリソースであることが判明)、ピザ、そして忘れられない雰囲気と興味深い人々とのコミュニケーションを楽しみました。
タスク自体と経験を考慮すると、次の結論を導き出すことができます。
- ファッションを追いかけずにすぐにDLを適用してください。おそらく古典的なモデルはかなりうまくいくかもしれません。
- より有用な機能を生成してから、モデルを最適化し、ハイパーパラメーターを選択します。
- SEEDを修正し、モデルとバックアップを保存します:)

EpicTeamチームは、NERチャレンジの勝者です。 左から右へ:
- レオニード・ジャリコフ、MSTU テクノパークの学生、バウマン。
- アンドレイアタマニュク、MSTU テクノパークの学生、バウマン。
- ミリヤ・ファットディノバ、REU プレハノフ。
- アンドレイ・パシュコフ、NRNU MEPhI、TechnoAtomの学生。