SAS Webサイトからソフトウェアをダウンロードできることを思い出させてください。SASUEのインストールに関するドキュメントへのリンクは記事1に記載されています 。
この記事では、テキストファイルを読み取るいくつかの方法について学びます。

すべての例は、c:\ workshop \ habrahabrディレクトリに保存され、メモ帳で事前に作成されたファイルに基づいています。
テキストファイルからSASデータセットを作成するには、最初のファイルを分析して、テキストファイルの読み取りの種類を正しく選択する必要があります。 テキストファイルには、標準データと非標準データの両方を含めることができます。
標準データは、SASが指示なしで読み取るデータです。たとえば、テキストファイルのSalary変数の値は12355.44として保存されるか、日付は標準SAS日付としてすでに記録されています( レッスン1を参照 )。 また、$ 12.355.44や01JAN2018などの値を処理する必要がある場合は、読み取りルール、これらの値をSAS形式に変換する指示を指定する必要があります。 この記事では、INPUTステートメントを使用して生データをSASデータセットに変換する方法について簡単に説明します。
標準の区切りデータを含むテキストファイルの読み取り。
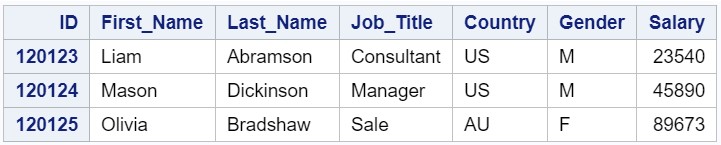
テキストファイルの最も単純な例を考えてみましょう。 managers1.datファイルはコンマ区切りのテキストファイルで、次のようになります。

新しいSASデータセットには、ID、First_Name、Last_Name、Job_Title、Country、Gender、Salaryの変数が含まれている必要があります。 このファイルに保存されているデータは標準であり、SASは問題なくそれを考慮していることに気付くかもしれません。
テキストファイルの読み取りは、DATAステップのINFILEおよびINPUTステートメントを使用して実装されます。
INFILEステートメントの詳細については、 SAS 9.4 DATA Step Statements:Referenceをご覧ください。
INFILEステートメントは、読み取る外部ファイルを設定します。
一般的なステートメントの構文:
INFILE file-specification<device-type><options><operating-environment-options>;
ファイル仕様 -データソースを識別します。外部ファイルまたは外部ファイルへのリンクです。
デバイスタイプ -アクセス方法。
オプションは有効なオプションです。
operating-environment-options-作業環境のパラメーター。
特定のケースでは、INFILEステートメントは次のように記述されます。
infile "c:\workshop\habrahabr\managers1.dat" dlm=',';
DLM = (または区切り文字=)は、外部ファイルの読み取りに使用される代替区切り文字(スペースがデフォルトの区切り文字)を定義するINFILEステートメントのオプションです。 区切り文字のリストは二重引用符で示されます。
パスを設定したら、変数名を設定する必要があります。 この問題を解決するには、 INPUT演算子が役立ちます。
INPUTステートメントの一般的な構文は次のとおりです。
INPUT <specification(s)> <@ | @@>;
仕様 -変数、変数リスト、テキストタイプフラグ($)、ポインター制御、列の仕様、読み取り形式などが含まれる場合があります(詳細については、 SAS 9.4 DATA Step Statements:Referenceを参照 )。
@ -文字列保持指定子。
この場合のINPUTステートメントは次のように記述されます。
input ID First_Name $ Last_Name $ Job_Title $ Country $ Gender $ Salary;
テキストファイルの読み取りがDATAステップで発生することをもう一度繰り返します。したがって、テキストファイルの読み取りに必要なコードは次のようになります。
data managers; infile "c:\workshop\habrahabr\managers1.dat" dlm=','; input ID First_Name $ Last_Name $ Job_Title $ Country $ Gender $ Salary; run;
managerと呼ばれる一時的なSASデータセットを作成します。これは、SASセッションが終了するまでWORKライブラリに保存されます( レッスン2を参照 )
コードが正しく機能しているか確認してください。 プログラムを実行し、ログを確認します。
データセットを印刷します。
proc print data=managers; run;
PROC PRINTステップの結果:

一部の列のテキスト値は「トリミング」されていることに注意してください。 PROC CONTENTSプロシージャを実行して、作成された変数の長さを決定します。
proc contents data=managers varnum; run;
VARNUMオプションは、テーブルに格納されている順序で変数を表示します。
プロシージャの出力の断片:

可変長
デフォルトでは、SAS Baseは長さが8バイトの任意のタイプの変数を作成します。 「クリッピング」値を回避するには、長さを明示的に設定する必要があります。 この問題は、 LENGTH演算子を使用して簡単に解決できます。
この演算子はINPUT演算子の前に記述する必要があることを知っておくことが重要です。これはSAS Baseの機能によるものです。
したがって、LENGTH演算子を使用したプログラムコードは次のようになります。
data managers; infile "c:\workshop\habrahabr\managers1.dat" dlm=','; length First_Name $ 10 Last_Name $ 12 Job_Title $25 Country $2 Gender $1; input ID First_Name Last_Name Job_Title Country Gender Salary; run; proc print data=managers; run; proc contents data=managers varnum; run;
LENGTH演算子で指定した変数のタイプに属しているため、INPUTでは変数の名前を単純にリストしました。 INPUTステートメントでは、変数はソースにある順にリストされていることに注意してください!
プログラムを実行し、結果を調べます。
PROC PRINTステップの結果:

PROC CONTENTSを実行した結果:
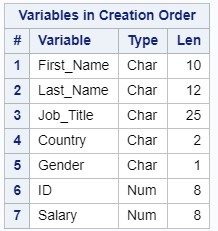
変数は異なる順序で表示されます。 これは、SAS Baseがすべてを順番に読み取るためです。最初にLENGTH演算子から変数が入力され、次にINPUTがチェックされ、データセットにID変数とSalary変数が追加されます。
列を元の順序で表示するために、LENGTHステートメントでID変数とSalary変数の長さを明示的に設定できます。 数値変数の最小の長さは3バイトですが、数値変数の長さを小さい値に変更すると、数値の精度が失われる可能性があることを忘れないでください。
したがって、プログラムは次の形式を取ります。
data managers; infile "c:\workshop\habrahabr\managers1.dat" dlm=','; length ID 8 First_Name $ 10 Last_Name $ 12 Job_Title $25 Country $2 Gender $1 Salary 8; input ID First_Name Last_Name Job_Title Country Gender Salary; run; proc print data=managers; run;
永続的な属性。
DATAステップで、変数に定数属性を設定します:フォーマットとラベル。 この場合、属性は出力データセットの記述子に書き込まれ、各PROCステップで使用されます。
data managers; infile "c:\workshop\habrahabr\managers1.dat" dlm=','; length ID 8 First_Name $ 10 Last_Name $ 12 Job_Title $25 Country $2 Gender $1 Salary 8; input ID First_Name Last_Name Job_Title Country Gender Salary; label ID = 'Employee ID' First_Name = 'First Name' Last_Name = 'Last Name' Job_Title = 'Job Title'; format Salary dollar11.2; run; proc contents data=managers varnum; run;
出力データセットの属性は記述子に書き込まれます。
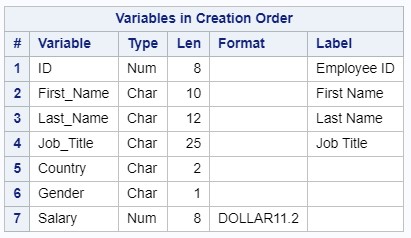
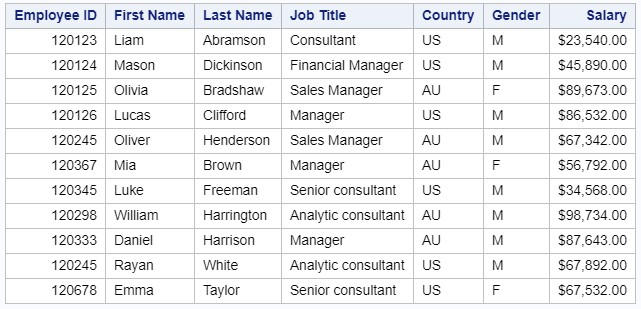
結果のSASデータセットからレポートを作成します。 PROC PRINTオプションでは、この手順でレポートで指定されたラベルが使用されるように、labelパラメーターを指定していることに注意してください。
proc print data=managers label noobs; run;
区切り記号付きの非標準データを含むテキストファイルの読み取り。
ディレクトリc:\ workshop \ habrahabrにあるテキストファイルmanagers2.datを検討します。
前のものと比較して、非標準のSASデータを含む列があります。
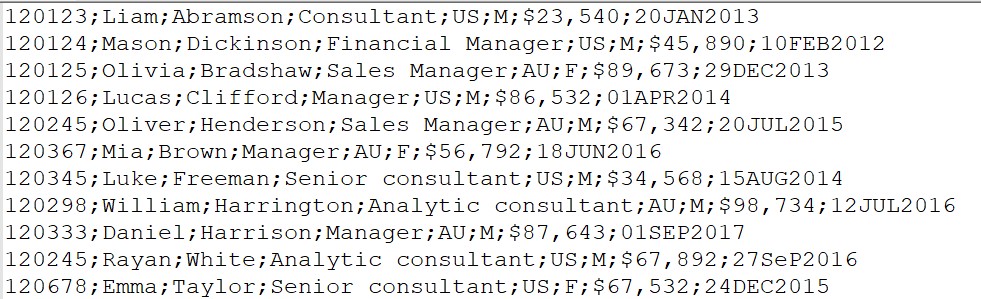
新しいデータセットには、ID、First_Name、Last_Name、Job_Title、Country、Gender、Salary、Hire_Dateの変数が含まれている必要があります。
Salary変数には特殊文字が含まれます。また、SAS形式の日付は1960年1月1日から始まる日数を表す数値であり( レッスン1を参照 )、HireDateは他の値を格納します。 非標準データを読み取るには、入力形式Informatを使用する必要があります。 入力形式を適用するには、列のデータが同じタイプでなければならないことに注意することが重要です。
入力形式に関するすべての情報は、 SAS 9.4 Formats and Informats:Referenceにあります。
Infromatは、非標準のSAS入力データの読み取りに使用されるルールです。 読み取り形式のタイプは、SASデータタイプに対応しています。 たとえば、100,000ドルの値がソースに保存されます。 この値を数値に変換する前にドル記号とコンマを削除するには、INFORMATカンマ8を適用する必要があります。 またはドル8。 この場合、値100000がサマリーテーブルに保存されます。
読み取りの一般的な形式の構文は次のとおりです。
<$>informat<w>.<d>
$は、テキストタイプポインターです。
Informatは、読み取り用の形式の名前です。
w-すべての文字を含むフィールド幅。
dは小数点以下の桁数です。
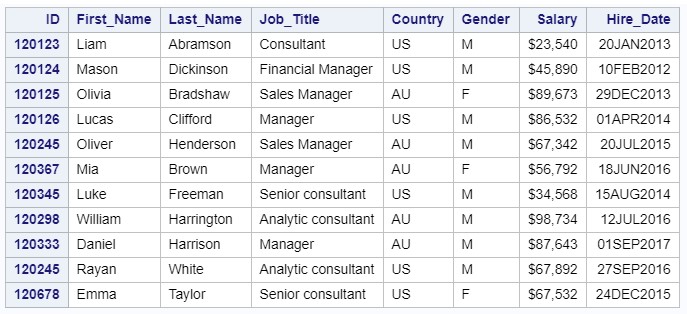
テキストファイルmanagers2.datを読みます
data managers2; infile "c:\workshop\habrahabr\managers2.dat" dlm=';'; input ID :8. First_Name :$10. Last_Name :$12. Job_Title :$25. Country :$2. Gender :$1. Salary :dollar10. Hire_Date :date9.; label ID = 'Employee ID' First_Name = 'First Name' Last_Name = 'Last Name' Job_Title = 'Job Title'; format Salary dollar10. Hire_Date date9.; run; proc print data=managers2 noobs; ID ID; run;
手順の結果:
欠損値を処理します。
データに欠損値がある場合、DSDとMISSOVERの2つのオプションを使用できます。
DSDは、文字列内の欠損値を検索し、最後にMISSOVERを検索します。
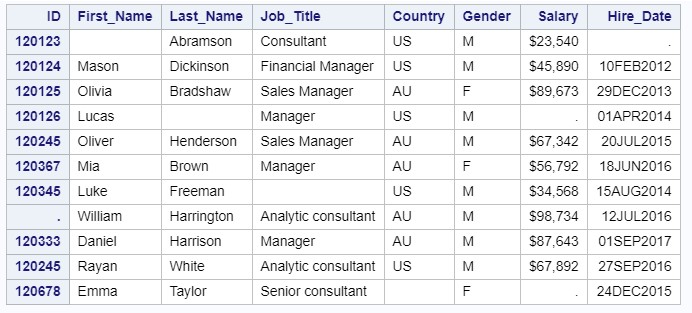
したがって、managers2aファイルを読み取りたい場合、2つの連続した区切り文字が欠損値をエンコードします:

これらのオプションを使用すると、このテキストファイルを簡単に読み取ることができます。
data managers2a; infile "c:\workshop\habrahabr\managers2a.dat" dlm=';' dsd missover; input ID :8. First_Name :$10. Last_Name :$12. Job_Title :$25. Country :$2. Gender :$1. Salary :dollar10. Hire_Date :date9.; label ID = 'Employee ID' First_Name = 'First Name' Last_Name = 'Last Name' Job_Title = 'Job Title'; format Salary dollar10. Hire_Date date9.; run; proc print data=managers2a; ID ID; run;
プログラムの結果:
データの読み取りエラー。
列にさまざまなタイプまたは形式のデータが含まれている場合は、次の例を検討してください
c:\ workshop \ habrahabrディレクトリにはbad_data.datファイルが含まれています

このファイルを考慮したDATA Stepを作成します。
data new; infile "c:\workshop\habrahabr\bad_data.dat" dlm=','; input ID :8. First_Name :$10. Last_Name :$12. Job_Title :$25. Country :$2. Gender :$1. Salary :5. Hire_Date :date9.; label ID = 'Employee ID' First_Name = 'First Name' Last_Name = 'Last Name' Job_Title = 'Job Title'; format Salary dollar10. Hire_Date date9.; run; proc print data=new; ID ID; run;
コードを実行し、ログを参照してください:
ログでは、データ読み取りエラーの表示:

2つの自動変数が作成されます:_N_および_ERROR_。
_N_はステップの反復です。
_ERROR_-値1はエラーを示します。
プログラムの結果:

Country変数の値「44」はデータ読み取りエラーなしで考慮され、LogのSalary変数とHire_Date変数では、データ読み取りエラーの兆候が現れたことに注意してください。
テキストファイルの読み取り時に変数の開始文字の位置インジケーターを使用する
ディレクトリc:\ workshop \ habrahabrから同様のテキストファイルinfo.datを読み取る必要がある場合:

外部ファイルを読み取る別のオプションは、変数の最初の文字の位置インジケータを使用することです。
位置、変数名、入力形式(入力形式)が示されます。
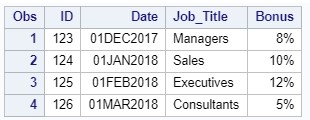
このケースのコードは次のようになります。
data info; infile "c:\workshop\habrahabr\info.dat"; input @1 ID 3. @4 Date mmddyy10. @15 Job_Title $11. @26 Bonus percent3.; format Date date9. Bonus percent.; run; proc print data=info; run;
コードを実行して結果を確認します。
数行の観察でテキストファイルを読み取ります。
1つの観測が数行かかるテキストファイルを読み取る必要がある場合:

この問題を解決するにはいくつかの方法があります。
- 複数のINPUTステートメントを使用します。
data managers6; infile "c:\workshop\habrahabr\managers6.dat"; input ID :8. First_Name :$6. Last_Name :$10.; input Job_Title :$11. Country :$2. Gender :$1. Salary :8.; run;
- ポインターを使用します。
SASは、スラッシュ文字(/)がINPUTステートメントで検出されると、次のレコード(行)をロードします。
data managers6; infile "c:\workshop\habrahabr\managers6.dat"; input ID :8. First_Name :$6. Last_Name :$10./ Job_Title :$11. Country :$2. Gender :$1. Salary :8.; run;
どちらの場合も、managers6データセットが作成されます。これは、一時的なWORKライブラリにあります( レッスン2を参照 )。
結果のデータセットを印刷します。
proc print data=managers6 noobs; id id; run;
手順の結果:
外部ファイルをインポートする
PROC IMPORTプロシージャを使用して、外部ファイルを読み取ることができます。
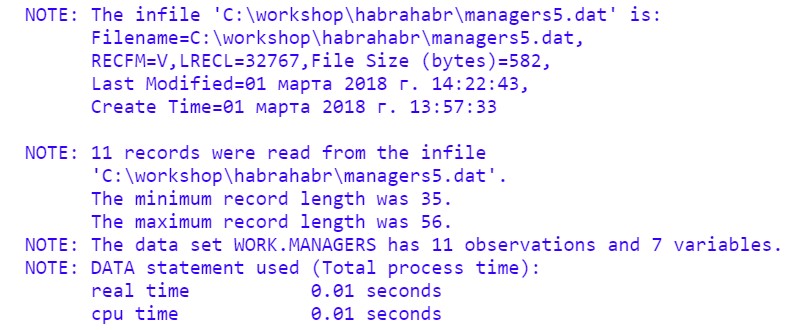
テキストファイルマネージャーをインポートする5。

この場合のPROCインポート手順は次のとおりです。
proc import datafile="C:\workshop\habrahabr\managers5.dat" dbms=dlm out=managers replace; delimiter=','; getnames=yes; run; proc print data=managers; run;
コードを実行し、ログを参照してください:
プログラムの結果:

したがって、これはテキストファイルの読み取りについて簡単に説明しています。 考慮される演算子と手順の機能ははるかに広範囲であり、詳細な説明がドキュメントに記載されていることに注意してください。
次の記事では、SASデータセットの作成について見ていきます。 そして、もちろん、伝統的に-SASで成長しましょう!