
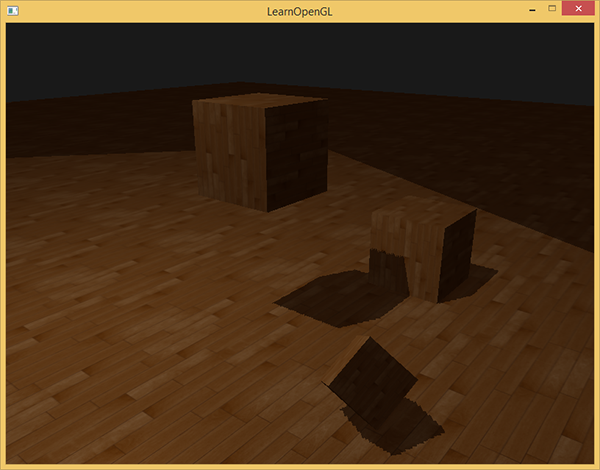
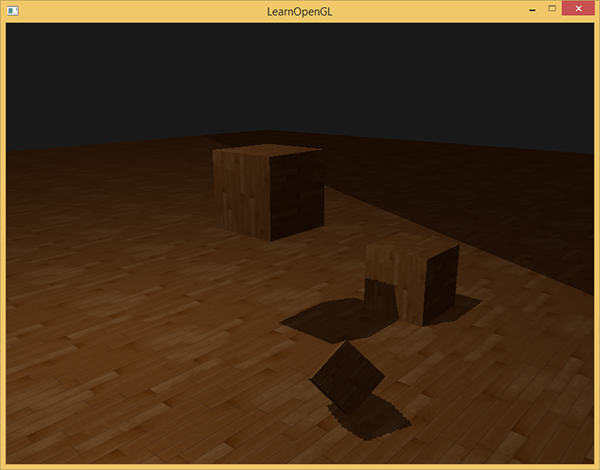
影には光がありません。 光源からの光線が他のオブジェクトに吸収されるため、オブジェクトに当たらない場合、最初のオブジェクトは影の中にあります。 影は画像にリアリズムを追加し、オブジェクトの相対的な位置を確認できるようにします。 彼らのおかげで、シーンは「深さ」を帯びています。 次のシーン画像を影ありと影なしで比較します。
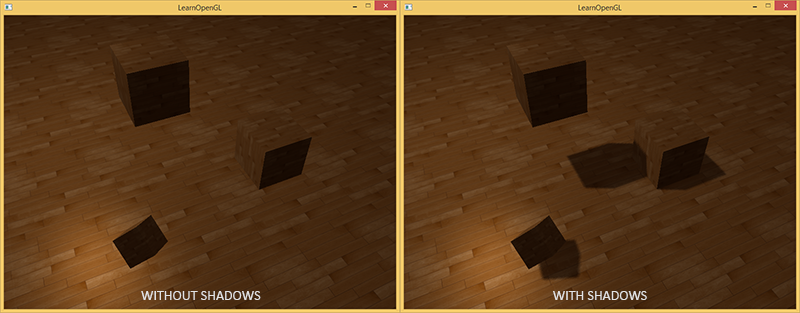
ご覧のように、影により、オブジェクトが互いにどのように配置されているかがより明確になります。 影のおかげで、立方体の1つが空中に見えます。
特に完全な影のリアルタイムアルゴリズムがまだ発明されていないため、影の実装は困難です。 影の計算を近似するためのいくつかの良い方法がありますが、それらはすべて考慮に入れなければならない独自の特性を持っています。
方法の1つであるシャドウマップは比較的簡単に実装でき、ほとんどのビデオゲームで使用されており、適切な結果が得られます。 シャドウマップはそれほど難しくなく、パフォーマンスの点で非常に安価であり、より高度なアルゴリズム( 点光源からのシャドウやカスケードシャドウマップなど)に簡単に改善できます。
パート1.はじめに
パート2.基本的な照明
パート3. 3Dモデルをダウンロードする
パート4.高度なOpenGL機能
パート5.高度な照明
パート6. PBR
(翻訳者の注意-将来、ロシア語版のいくつかの用語は、定評のある英語版と重複します。エラーがなく、わからない-元の用語と一緒に覚えておいてください。
シャドウカード
シャドウマップの基礎となるアイデアは非常に単純です。光源の視点からシーンを描画します。 私たちが見るものはすべて照らされ、残りは日陰になっています。 床と光源の間に大きな立方体がある床を想像してください。 光源は床の一部ではなく立方体を「見る」ため、床のこの部分は見えなくなります。

上の図で、青い線は光源が見える表面を示しています。 閉じた表面は黒く塗られます-陰影が付けられます。 光源から一番右の立方体の上部に線(光線)を引くと、最初に空中にぶら下がっている立方体を横切ります。 このため、右の立方体とは異なり、ぶら下がっている立方体の左面が照らされます。
光線と表面の最初の交差点を見つけて、他の交差点と比較したいと思います。 光線とサーフェスの交点が最も近い交点と一致しない場合、影の中にあります。 ソースからの何千もの異なる光線に対してこの操作を繰り返すことは非常に非効率的であり、ゲームのすべてのフレームで描画するのには適していません。
おそらく深さテストについてはすでに読んでいます: ハブの翻訳 、 元の 。 深度バッファの値は、カメラの視点からのフラグメントの深度であり、0〜1の値によって制限されます。光源の視点からシーンをレンダリングし、テクスチャに深度値を格納するとどうなりますか? したがって、光源の視点から見ることができる最小の深さを取得します。 さらに、深度値は、光源に最も近いサーフェスを示します。 このテクスチャは、 深度マップまたはシャドウマップと呼ばれます 。

左の写真は、立方体の下の表面に影を落とす指向性光源(すべての光線が平行)を示しています。 テクスチャに保存されている深度値を使用して、ソースに最も近いサーフェスを見つけ、その助けを借りて、影の中にあるものを判断します。 光源に対応する行列を使用したビューおよび投影行列として、シーンレンダリングを使用して深度マップを作成します。
平行光線を使用した指向性ライトには位置がなく、「無限に遠く」あります。 ただし、シャドウマップを作成するには、光の線上の位置からシーンを描画する必要があります。
ご注意 トランスレータ-openGLは、遠すぎる(z> 1)または近すぎる(z <0またはz <-1の設定に応じて)サーフェスを切り取ります。 カメラマトリックスは、シーン上のオブジェクトのz座標がこの間隔になるように選択されます。そうでない場合、それらは表示されません。 数学的な観点からは、位置はありませんが、実際には、カメラのポイントは、描画時に画面の中央のマスキング的に近いポイントに表示されるポイントと見なすことができます
右側の写真では、同じ光、立方体、観察者が見えます。 ポイントP
でサーフェスのフラグメントを描画し、それが影にあるかどうかを判断する必要があります。 これを行うには、 P
を光源T(P)
の座標空間に変換します。 点P
光の視点からは見えないため、この例の座標z
は0.9
ます。 ポイントx,
の座標に基づいて、深度マップを調べると、光源に最も近いポイントが深度0.4の
であることがわかります。この値はポイントP
値よりも小さいため、ポイントP
はシャドウ内にあります。
シャドウ描画は2つのパスで構成されます。最初に深度マップを描画し、2番目のパスで通常どおりワールドを描画します。深度マップを使用して、表面のどの断片がシャドウにあるかを判断します。 複雑に思えるかもしれませんが、すべてを段階的に進めると、すべてが明確になります。
深度マップ
最初のパスでは、深度マップを生成します。 深度マップは、光源の観点からレンダリングされた深度値を持つテクスチャです。 次に、それを使用して影を計算します。 レンダリングされた結果をテクスチャに保存するには、ハブの framebuffer : translationが必要です。
最初に、深度マップを描画するためのフレームバッファーを作成します。
unsigned int depthMapFBO; glGenFramebuffers(1, &depthMapFBO);
フレームバッファの深度バッファとして使用する2Dテクスチャを作成した後。
const unsigned int SHADOW_WIDTH = 1024, SHADOW_HEIGHT = 1024; unsigned int depthMap; glGenTextures(1, &depthMap); glBindTexture(GL_TEXTURE_2D, depthMap); glTexImage2D(GL_TEXTURE_2D, 0, GL_DEPTH_COMPONENT, SHADOW_WIDTH, SHADOW_HEIGHT, 0, GL_DEPTH_COMPONENT, GL_FLOAT, NULL); glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_NEAREST); glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_NEAREST); glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_REPEAT); glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_REPEAT);
深度マップの作成は複雑に見えません。 深さの値にのみ関心があるため( r,g,b,a
色には関心がない)、テクスチャ形式GL_DEPTH_COMPONENT
を指定します。 テクスチャの高さと幅を1024 * 1024に設定します-これは深度マップのサイズになります。
次に、深度バッファとして深度テクスチャをフレームバッファにアタッチします。
glBindFramebuffer(GL_FRAMEBUFFER, depthMapFBO); glFramebufferTexture2D(GL_FRAMEBUFFER, GL_DEPTH_ATTACHMENT, GL_TEXTURE_2D, depthMap, 0); glDrawBuffer(GL_NONE); glReadBuffer(GL_NONE); glBindFramebuffer(GL_FRAMEBUFFER, 0);
光源の視点からシーンを描画する場合、深さにのみ関心があり、カラーバッファは必要ありません。 フレームバッファーはカラーバッファーがないと不完全になるため、色をレンダリングしないことを明示的に示す必要があります。 これを行うために、 glDrawBuffer
とglReadBuffer
にglDrawBuffer
を設定します。
これで、テクスチャに深度値を書き込むフレームバッファが適切に構成され、深度マップをレンダリングできます。 両方のレンダリングパスの完全な実装は次のようになります。
// 1. glViewport(0, 0, SHADOW_WIDTH, SHADOW_HEIGHT); glBindFramebuffer(GL_FRAMEBUFFER, depthMapFBO); glClear(GL_DEPTH_BUFFER_BIT); ConfigureShaderAndMatrices(); RenderScene(); // 2. ( ) glBindFramebuffer(GL_FRAMEBUFFER, 0); glViewport(0, 0, SCR_WIDTH, SCR_HEIGHT); glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT); ConfigureShaderAndMatrices(); glBindTexture(GL_TEXTURE_2D, depthMap); RenderScene();
このコードには詳細は含まれていませんが、シャドウマップの一般的な概念を示しています。 glViewport
呼び出しに注意してglViewport
。通常、深度マップのサイズは、画面(または最終画像がレンダリングされるテクスチャ)のサイズとは異なります。 変更を忘れると、画面サイズの正方形のピースのみが深度テクスチャに更新されるか、(テクスチャが小さい場合)情報の一部が表示されません(エッジの外側に残ります)。
光源スペース
上記のコードで不明なのは、 ConfigureShaderAndMatrices()
関数が何をするかだけです。
2番目のパスでは、通常どおりに動作します。カメラに適切なビューと投影行列を設定し、オブジェクトにモデル行列を設定します。 ただし、最初のパスでは、投影とビューに他のマトリックスを使用します。光源の視点からシーンを描画するためです。
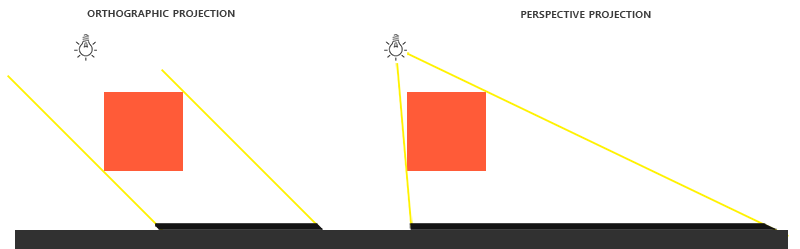
指向性光源をシミュレートするため、すべての光線は平行です。 このため、光源に正投影図法を使用します(過度の歪みはありません)。
float near_plane = 1.0f, far_plane = 7.5f; glm::mat4 lightProjection = glm::ortho(-10.0f, 10.0f, -10.0f, 10.0f, near_plane, far_plane);
これは、この記事のデモで使用される正投影図の例です。 射影行列はオブジェクトを見る距離を決定するので(つまり、ビデオカードはオブジェクトをあまりにも近くまたは遠ざけることはありません)、クリッピング領域のサイズには、深度マップに表示するすべてのオブジェクトが含まれていることを確認する必要があります。
すべてのオブジェクトが光源の視点から見えるビュー行列を作成するには、人気のない関数glm::lookAt
を使用します。光源はシーンの中心を「見る」ようになりました。
glm::mat4 lightView = glm::lookAt(glm::vec3(-2.0f, 4.0f, -1.0f), glm::vec3( 0.0f, 0.0f, 0.0f), glm::vec3( 0.0f, 1.0f, 0.0f));
(注車線-最初のベクトルはカメラの位置、2番目は見ている場所、3番目は見上げる方向です)
これら2つの行列の組み合わせにより、世界の座標から光源が世界を「見る」座標への変換行列が得られます。 これは、デプスマップをレンダリングするために必要なものです。
glm::mat4 lightSpaceMatrix = lightProjection * lightView;
lightSpaceMatrix
マトリックスは、上記でT
として指定したものとまったく同じですT
このマトリックスを使用すると、従来のカメラのビューおよび投影マトリックスの代わりに使用して、通常どおりシーンを平均化できます。 ただし、深さの値にのみ関心があり、未使用の色について不必要な計算を行わずにパフォーマンスを維持したいと考えています。 したがって、深度マップのみを描画する最も単純なシェーダーを作成します。
デプスマップレンダリング
光源のシーンをレンダリングするとき、頂点の座標のみが必要で、それ以上は必要ありません。 このような単純なシェーダー( simpleDepthShader
と呼びましょう)の場合、頂点シェーダーを記述します。
#version 330 core layout (location = 0) in vec3 aPos; uniform mat4 lightSpaceMatrix; uniform mat4 model; void main() { gl_Position = lightSpaceMatrix * model * vec4(aPos, 1.0); }
このシェーダーは、モデルごとに、 lightSpaceMatrix
を使用してモデルの頂点を光源の空間にlightSpaceMatrix
ます。
シャドウのフレームバッファーにはカラーバッファーがないため、フラグメントシェーダーは計算を必要とせず、空のままにできます。
#version 330 core void main() { // gl_FragDepth = gl_FragCoord.z; }
空のフラグメントシェーダーは何も実行せず、シェーダーの最後に更新された深度バッファーを取得します。 このコード行のコメントを外すことができますが、実際には深さはとにかく計算されます。
深度バッファに描画すると、次のコードになります。
simpleDepthShader.use(); glUniformMatrix4fv(lightSpaceMatrixLocation, 1, GL_FALSE, glm::value_ptr(lightSpaceMatrix)); glViewport(0, 0, SHADOW_WIDTH, SHADOW_HEIGHT); glBindFramebuffer(GL_FRAMEBUFFER, depthMapFBO); glClear(GL_DEPTH_BUFFER_BIT); RenderScene(simpleDepthShader); glBindFramebuffer(GL_FRAMEBUFFER, 0);
RenderScene
関数はシェーダーを受け取り、描画に必要な関数を呼び出し、必要に応じてモデル行列をインストールします。
その結果、光の点で最も近いフラグメントの深さを含む各ピクセルに対して、深さバッファがいっぱいになります。 このテクスチャを画面サイズの長方形に投影して表示できます。 (フレームバッファを使用した例の後処理の場合と同様です。 元の ハブでの変換 。)
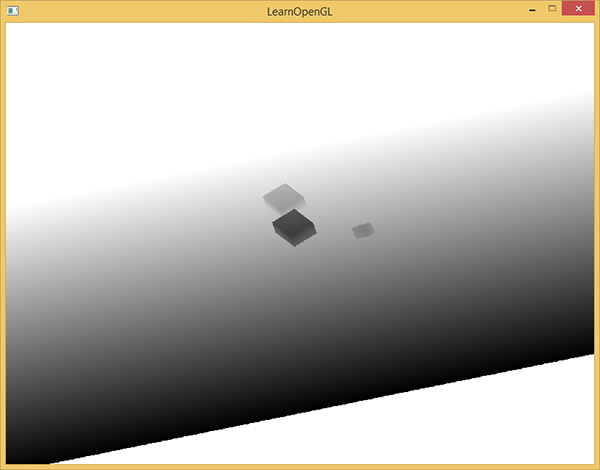
長方形に深度マップを描画するには、次のシェーダーを使用します。
#version 330 core out vec4 FragColor; in vec2 TexCoords; uniform sampler2D depthMap; void main() { float depthValue = texture(depthMap, TexCoords).r; FragColor = vec4(vec3(depthValue), 1.0); }
シャドウをレンダリングするときに、投影マトリックスが直交ではなく遠近法になる場合、深度は非線形に変化します。 記事の最後で、この違いについて説明します。
シーンを深度マップにレンダリングするためのソースコードは、 ここにあります 。
影絵
適切に作成された深度マップを使用して、影を描画できます。 フラグメントシェーダーを使用してフラグメントがシャドウにあるかどうかを確認しますが、頂点シェーダーで光源のスペースに変換します。
#version 330 core layout (location = 0) in vec3 aPos; layout (location = 1) in vec3 aNormal; layout (location = 2) in vec2 aTexCoords; out VS_OUT { vec3 FragPos; vec3 Normal; vec2 TexCoords; vec4 FragPosLightSpace; } vs_out; uniform mat4 projection; uniform mat4 view; uniform mat4 model; uniform mat4 lightSpaceMatrix; void main() { vs_out.FragPos = vec3(model * vec4(aPos, 1.0)); vs_out.Normal = transpose(inverse(mat3(model))) * aNormal; vs_out.TexCoords = aTexCoords; vs_out.FragPosLightSpace = lightSpaceMatrix * vec4(vs_out.FragPos, 1.0); gl_Position = projection * view * model * vec4(aPos, 1.0); }
ここから新しいものは、頂点シェーダーの出力にある追加のベクトルFragPosLightSpace
です。 深さを描画するために最初のパスで使用されたのと同じlightSpaceMatrix
を受け入れ、その助けを借りて、ベクトルを光源の空間に変換します。 頂点シェーダーは、ワールドのスペース( vs_out.FragPos
)と光源のスペース( vs_out.FragPos
)の両方の頂点の座標を同時にフラグメントに転送します。
Blinn-Fongライトモデルに基づいたフラグメントシェーダーを使用します。 フラグメントシェーダーでは、 shadow
値を見つけます。フラグメントがシャドウ内にある場合は1.0になり、ライトがかかっている場合は0.0になります。 結果として生じるdiffuse
およびspecular
色(拡散および鏡面反射照明)は(1.0 - shadow)
で乗算されます。 間接照明のために影が完全に黒になることはめったにないため、影に関係なく背景の照明が存在します。
#version 330 core out vec4 FragColor; in VS_OUT { vec3 FragPos; vec3 Normal; vec2 TexCoords; vec4 FragPosLightSpace; } fs_in; uniform sampler2D diffuseTexture; uniform sampler2D shadowMap; uniform vec3 lightPos; uniform vec3 viewPos; float ShadowCalculation(vec4 fragPosLightSpace) { [...] } void main() { vec3 color = texture(diffuseTexture, fs_in.TexCoords).rgb; vec3 normal = normalize(fs_in.Normal); vec3 lightColor = vec3(1.0); // ambient vec3 ambient = 0.15 * color; // diffuse vec3 lightDir = normalize(lightPos - fs_in.FragPos); float diff = max(dot(lightDir, normal), 0.0); vec3 diffuse = diff * lightColor; // specular vec3 viewDir = normalize(viewPos - fs_in.FragPos); float spec = 0.0; vec3 halfwayDir = normalize(lightDir + viewDir); spec = pow(max(dot(normal, halfwayDir), 0.0), 64.0); vec3 specular = spec * lightColor; // calculate shadow float shadow = ShadowCalculation(fs_in.FragPosLightSpace); vec3 lighting = (ambient + (1.0 - shadow) * (diffuse + specular)) * color; FragColor = vec4(lighting, 1.0); }
これは、ほとんどの場合、ライティングの例で使用したシェーダーのコピーです: ハブ上の変換 、 高度なライティング 。
ここではシャドウ計算のみが追加されています。 作業の大部分は、 ShadowCalculation
関数によって行われます。 フラグメントシェーダーの最後で、光の拡散反射と鏡面反射からの寄与に(1.0-シャドウ)を掛けます-つまり、フラグメントがシェーディングされていない量に依存します。 さらに、この入力シェーダーは、光源のスペース内のフラグメントの位置と、深さの値を持つテクスチャー(最初のパスでレンダリングされた)をさらに受け入れます。
フラグメントがシャドウ内にあるかどうかを確認するために、光源の空間の位置を正規化された座標に移動します。 頂点シェーダーで頂点の位置をgl_Position
に戻すと、openGLはx,y,z
をw
自動的に分割し、パースペクティブが正しく機能するようにします。 FragPosLightSpace
として渡されないため、この分割を自分で行う必要があります。
float ShadowCalculation(vec4 fragPosLightSpace) { // perform perspective divide vec3 projCoords = fragPosLightSpace.xyz / fragPosLightSpace.w; [...] }
光源の空間内のフラグメントの位置を取得します。
正投影を使用する場合、座標w=1.0
は変化せず、wによる除算は不要になります。 ただし、透視投影を使用する場合は分割が必要であり、コードは両方の場合に正しく機能します。
(レーンに注意してください-wによる分割は、フラグメントシェーダーで行う必要があります。 この記事の最初の図は、テクスチャ座標の線形補間と透視補間の違いを示しています。)
テクスチャ座標は[0,1]の範囲にあり、レンダリング時の可視フラグメントの座標は[-1,1]の値を取ります。 それらを間隔[0,1]に移動します。
projCoords = projCoords * 0.5 + 0.5;
これらの座標に基づいて、テクスチャの深度値を確認できます。これは、光源に最も近いオブジェクトの深度になります。
float closestDepth = texture(shadowMap, projCoords.xy).r;
現在のフラグメントの深さを取得するには、光源の空間でそのz座標を取得します。
float currentDepth = projCoords.z;
その後、 currentDepth
とclosestDepth
単純な比較により、フラグメントが最も近いか、影にあるかを判断できます。
float shadow = currentDepth > closestDepth ? 1.0 : 0.0;
ShadowCalculation関数のすべてのコードは次のとおりです。
float ShadowCalculation(vec4 fragPosLightSpace) { // perform perspective divide vec3 projCoords = fragPosLightSpace.xyz / fragPosLightSpace.w; // transform to [0,1] range projCoords = projCoords * 0.5 + 0.5; // get closest depth value from light's perspective (using [0,1] range fragPosLight as coords) float closestDepth = texture(shadowMap, projCoords.xy).r; // get depth of current fragment from light's perspective float currentDepth = projCoords.z; // check whether current frag pos is in shadow float shadow = currentDepth > closestDepth ? 1.0 : 0.0; return shadow; }
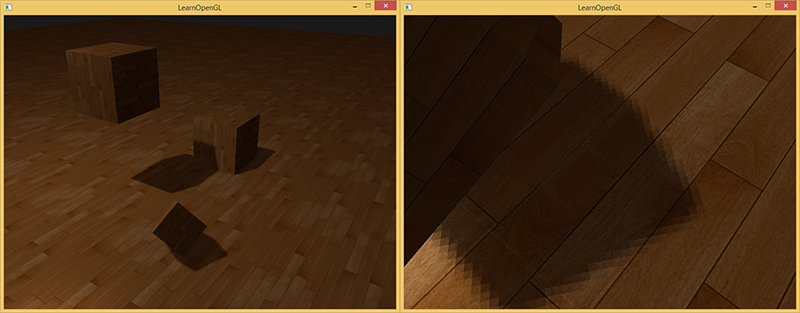
2番目のレンダーパスでこのシェーダーをテクスチャと通常のビューおよび投影マトリックスと共に使用すると、結果は図のようになります。
すべてを正しく行った場合、床と立方体に影が見えます(ただし、いくつかのアーティファクトがあります)。 ソースコードデモ 。
シャドウマップの改善
シャドウマップの作業を完了できましたが、画像にいくつかのアーティファクトを見ることができます。 後続のテキストは、それらの修正に専念します。
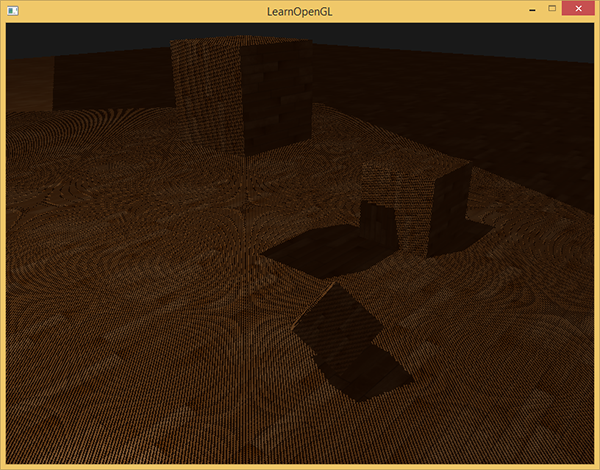
モアレパターン
明らかに、下の画像で何かが間違っています。 拡大された画像は、 モアレパターンに似ています 。

床全体は、はっきりと見える交互の黒いストライプで覆われています。 この効果は、単一の画像で説明できます。

(レーンに注意してください-作者は「 シャドウニキビ 」という用語を使用して効果を説明します。確立された翻訳は見つかりませんでした。
シャドウマップの解像度は限られているため(上記の例では、テクスチャ1024*1024
を使用しました)、最終画像のいくつかのピクセルは深度マップから同じ値を取得できます。 上の図は、各傾斜部分(左下から右へ)がデプスマップの1つのテクセルを表す床を示しています。 (テクセル-テクスチャピクセル)
通常、これは正常ですが、上の例のように、光が表面に対して斜めに落ちると問題になる可能性があります。 テクスチャから深度を受け取る一部のフラグメントは、このフラグメントのフロアの実際の深度に対応しない値を取得します。 このため、フラグメントの一部は影付きと見なされ、ストライプが表示されます。
この問題は小さなハックで解決できます。つまり、すべてのフラグメントが表面より上になるように、深さの値を少しだけシフト(シャドウバイアス)します。
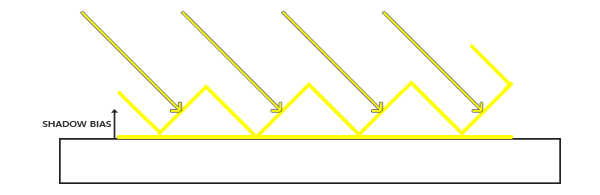
(レーンに注意してください。-私は絵が正しく描かれていないと強く感じています。フラグメントの陰影を防ぐために、深度マップからの値を記述するジグザグ線は表面の下にあるべきです)
float bias = 0.005; float shadow = currentDepth - bias > closestDepth ? 1.0 : 0.0;
シーン全体の0.005のシフトで問題は解決しますが、非常に小さな角度で光が当たる一部のサーフェスにはまだ影の縞があります。 より深刻なアプローチは、光が表面に当たる角度に応じてシフトを変更することです。 スカラー積を使用します。
float bias = max(0.05 * (1.0 - dot(normal, lightDir)), 0.005);
したがって、光線にほぼ垂直な床タイプの表面のシフトは非常に小さくなります。 法線と光の方向の間の角度が大きいほど、シフトが大きくなります。 次の図は、同じシーンを示していますが、シフトを使用しています。明らかに良く見えます。

シフトごとに正しい値を選択するには、シーンごとに異なる可能性があるため、選択する必要がありますが、これは通常、アーティファクトが消えるまでシフトを増やすだけで行われます。
ピーターパンの効果
(ピットパン)
深度のシフトを使用することの欠点は、オブジェクトの実際の深度にシフトを適用することです。 その結果、このシフトは十分に大きくなる可能性があるため、下の図のように、オブジェクトと影の間に顕著な距離が表示されます(誇張して大きなシフトを伴う)。

影が被写体から少し逃げるため、これはピーターパン効果と呼ばれます。 ほとんどの問題を解決するために少しのトリックを使用できます。深度マップを描画するときに、正面向きのポリゴンのクリッピングを使用します。 オリジナル のHabréで顔を数えることについて読んでください。
デフォルトでは、openGLは逆向きのポリゴンをカットします。 openGLを切り替えて反対のことを行うことができます。
レンダリングの最初のパスでは、深さの値のみが必要であり、前面からまたは背面からどの深さを取るかは関係ありません。 オブジェクト内に影があるかどうかは関係ないので、不正確な結果に気付くことはありません-それらはまだ見えません。

Peter Panの効果を除去するために、最初のパスでフロントエッジを切り取りました。 GL_CULL_FACE
有効にする必要があることに注意してください。
glCullFace(GL_FRONT); RenderSceneToDepthMap(); glCullFace(GL_BACK); //
これにより、Peter Penエフェクトの問題が解決されますが、これはすべての面にサーフェスがあるオブジェクトに対してのみです。 この例では、これはキューブに対してはうまく機能しますが、前面のポリゴンをクリップすると床が完全に削除されるため、床に対しては機能しません。 この方法を使用する場合は、理にかなっている場合にのみ、正面向きのポリゴンのクリッピングを使用してください。
(車線に注意してください-特にこの例では、下にオブジェクトがないため、床を完全に切断しても問題はありません。下に影があるかどうかは関係ありません。)
オブジェクトがシェーディングされた表面に近すぎると、結果が正しく表示されない場合があります。 これが理にかなっているオブジェクトに対してのみ、前面のクリッピングを使用します。 ただし、適切な値をシフトに使用することにより、ピーターペン効果を完全に回避できます。
あなたが好むかもしれないし好まないかもしれないもう一つの目に見える欠点は、光源の範囲の外側のいくつかの表面が、理論的に光が当たったとしても陰影で描かれることです。 これは、光源の参照フレーム内のリモートポイントの場合、座標が1.0より大きくなり、テクスチャ座標が0.0から1.0にのみ変化するためです。 表面が光源から遠すぎる場合、深度マップには値がありません。
上の画像では、光の領域を想像することができます-それ以外はすべて日陰です。 照らされた領域は、深度マップがどのように床に投影されるかを示します。 この動作の理由は、以前にGL_REPEAT
モードを深度テクスチャに設定したGL_REPEAT
です。
このようなフラグメントの深さ1.0を返したいと思います-これは、(可視オブジェクトは1を超える深さを持つことができないため)シャドウに決して含まれないことを意味します。 "GL_CLAMP_TO_BORDER"
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_BORDER); glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_BORDER); float borderColor[] = { 1.0f, 1.0f, 1.0f, 1.0f }; glTexParameterfv(GL_TEXTURE_2D, GL_TEXTURE_BORDER_COLOR, borderColor);
, [0,1], 1.0, shadow
0.0. :
, . , . , .
z
, 1.0, GL_CLAMP_TO_BORDER
. ( 1.0) ( 1.0) — .
— , z .
float ShadowCalculation(vec4 fragPosLightSpace) { [...] if(projCoords.z > 1.0) shadow = 0.0; return shadow; }
1.0 .

, , , . , , .
PCF
Percentage-closer filtering
, , . , .

, . .
, .
() — PCF (Percentage-closer filtering), , . , — . , . .
PCF — :
float shadow = 0.0; vec2 texelSize = 1.0 / textureSize(shadowMap, 0); for(int x = -1; x <= 1; ++x) { for(int y = -1; y <= 1; ++y) { float pcfDepth = texture(shadowMap, projCoords.xy + vec2(x, y) * texelSize).r; shadow += currentDepth - bias > pcfDepth ? 1.0 : 0.0; } } shadow /= 9.0;
textureSize
— , . , , . , . 9 (x,y)
, , .
/ texelSize
, . PCF :
. , , (, 9 ). , PCF .
, PCF, . , .
vs
. , , . . .
( ). , — .
#version 330 core out vec4 FragColor; in vec2 TexCoords; uniform sampler2D depthMap; uniform float near_plane; uniform float far_plane; float LinearizeDepth(float depth) { float z = depth * 2.0 - 1.0; // Back to NDC return (2.0 * near_plane * far_plane) / (far_plane + near_plane - z * (far_plane - near_plane)); } void main() { float depthValue = texture(depthMap, TexCoords).r; FragColor = vec4(vec3(LinearizeDepth(depthValue) / far_plane), 1.0); // perspective // FragColor = vec4(vec3(depthValue), 1.0); // orthographic }
このコードは、正投影で見たものと同様の深度値を示しています。これはデバッグ専用であることに注意してください。非線形変換は単調であり、2つの深度値を比較すると、線形か非線形かに関係なく同じ結果が得られます。
追加のリソース:
- tutorial-16-shadow-mappingは、いくつかの追加の詳細を含む同様の例です。
- シャドウマッピング-パート1:ogldevの別の例
- シャドウマッピングの仕組み: -シャドウマップとその実装に関する3部構成のビデオ
- シャドウ深度マップを改善するための一般的なテクニック:シャドウマップの品質を改善するための多数の方法をリストした優れたMicrosoftの記事。