
ストーリーは1年前に始まりました。友人、同僚、エンタープライズマーケティングの大規模な専門家が次の言葉で私たちのところに来ました。「みんな、おしゃれな機能をすべて備えたシックな倉庫があります。 90TB。」 特別な必要はありませんでしたが、もちろん拒否しませんでした。 そこでいくつかのバックアップを設定し、しばらくの間は安全に忘れていました。
定期的に、ホスト間で大きなファイルを転送したり、Postgreレプリカ用のWALを構築したりするなどのタスクが発生しました。徐々に、プロジェクトに関連する散乱したすべての良さをこの冷蔵庫に転送し始めました。 バックアップの試行が成功した場合と成功しなかった場合のアラートをローテーションで設定します。 年間を通じて、このストレージはオペレーティンググループのインフラストラクチャの重要な要素の1つになりました。
私たちの専門家が再び私たちのところに来て、彼が彼のプレゼントを取りたいと言ったまで、すべては大丈夫でした。 そして、早急に返却する必要があります。
選択は小さかった-どこでもすべてを再び突き出すか、ブラックジャックとスティックからあなた自身の冷蔵庫を集める。 この瞬間までに、私たちはすでに教えられており、多くのまったくフォールトトレラントではないシステムを十分に見て、フォールトトレランスが2番目の自己になりました。
多くの選択肢のうち、Gluster、Glasster、特に目を引きました。 とにかく、何を呼ぶか。 結果があった場合のみ。 したがって、私たちは彼をm笑し始めました。
Glasterとは何ですか、なぜ必要なのですか?
これは、OpenStackと長年親しまれ、oVIrt / RHEVに統合されている分散ファイルシステムです。 私たちのIaaSは Openstackではありませんが、Glasterには大規模なアクティブコミュニティがあり、libgfapiインターフェースの形式でネイティブqemuをサポートしています。 したがって、1つの石で2羽の鳥を殺します。
- 私たちが完全にサポートしているバックアップのためにバックアップを上げます。 ベンダーが壊れた部品を送るとき、予想を恐れる必要はもうありません。
- 将来的にお客様に提供できる新しいタイプのストレージ(ボリュームタイプ)をテストしています。
テストした仮説:
- グラスターの仕組み。 確認済み。
- フォールトトレラントである-任意のノードを再起動でき、クラスターは引き続き動作し、データが利用可能になります。 複数のノードを再起動できますが、データは失われません。 確認済み。
- 信頼できること-つまり、それ自体で落ちたり、メモリ内で期限切れにならないなど組み立てたどの構成でも安定していません(詳細は最後にあります)。
1か月間、さまざまな構成とバージョンの実験とアセンブリが行われ、その後、テクニカルバックアップの2番目の目的地として、運用環境でテスト運用が行われました。 彼に完全に依存する前に、6か月間彼がどのように振る舞うかを見たかったのです。
育て方
実験用に十分な容量がありました。DellPoweredge r510を搭載したラックと、古いS3から継承したそれほど高速でないSATA 2テラバイトのパックです。
20 TBを超えるストレージは必要ないことがわかりました。その後、2つの古いDell Power Edge r510を10個のディスクで満たし、アービターロール用に別のサーバーを選択し、パッケージをダウンロードして展開するのに約30分かかりました。 結果はそのようなスキームです。
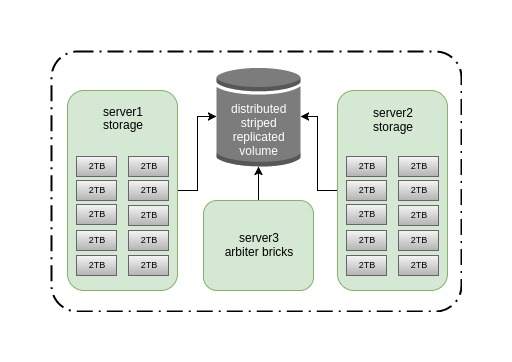
アービターでストライプレプリケーションを選択したのは、高速(データが複数のブリックに均等に分散される)、十分な信頼性(レプリカ2)があり、スプリットブレインを受信せずに1つのノードのフォールを生き残ることができるからです。 私たちはどのように間違っていました...
現在の構成でのクラスターの主な欠点は、1Gのみの非常に狭いチャネルですが、目的のためにはこれで十分です。 したがって、この投稿はシステムの速度をテストすることではなく、その安定性と事故の場合にどうするかについてです。 将来的には、rdmaを使用してInfiniband 56Gに切り替えてパフォーマンステストを実施する予定ですが、これはまったく別の話です。
ここでは、クラスターを組み立てるプロセスについて詳しく説明しません。すべてが非常に簡単です。
ブリックのディレクトリを作成します。
for i in {0..9} ; do mkdir -p /export/brick$i ; done
xfsをブリキの車輪に転がします:
for i in {b..k} ; do mkfs.xfs /dev/sd$i ; done
/ etc / fstabにマウントポイントを追加します。
/dev/sdb /export/brick0/ xfs defaults 0 0 /dev/sdc /export/brick1/ xfs defaults 0 0 /dev/sdd /export/brick2/ xfs defaults 0 0 /dev/sde /export/brick3/ xfs defaults 0 0 /dev/sdf /export/brick4/ xfs defaults 0 0 /dev/sdg /export/brick5/ xfs defaults 0 0 /dev/sdh /export/brick6/ xfs defaults 0 0 /dev/sdi /export/brick7/ xfs defaults 0 0 /dev/sdj /export/brick8/ xfs defaults 0 0 /dev/sdk /export/brick9/ xfs defaults 0 0
マウント:
mount -a
ボリュームのディレクトリをbriksに追加します。これは、holodilnikと呼ばれます。
for i in {0..9} ; do mkdir -p /export/brick$i/holodilnik ; done
次に、クラスターホストをスピンし、ボリュームを作成する必要があります。
3つのホストすべてにパッケージを配置します。
pdsh -w server[1-3] -- yum install glusterfs-server -y
Glasterを起動します。
systemctl enable glusterd systemctl start glusterd
Glasterにはいくつかのプロセスがあることを知っておくと便利です。その目的は次のとおりです。
glusterd =管理デーモン
メインデーモンは、ボリュームを制御し、ブリックとデータリカバリを担当する残りのデーモンを引き出します。
glusterfsd = ブロックごとのデーモン
各brikは独自のglusterfsdデーモンを起動します。
glustershd =自己修復デーモン
クラスターノードダンプが発生した場合に、複製されたボリュームのデータを再構築します。
glusterfs =通常はクライアント側ですが、サーバー上のNFSも
たとえば、glusterfs-fuseネイティブクライアントパッケージに付属しています。
Pirimノード:
gluster peer probe server2 gluster peer probe server3
ボリュームを収集します。ここではブリックの順序が重要です-複製されたブリックは次々に続きます。
gluster volume create holodilnik stripe 10 replica 3 arbiter 1 transport tcp server1:/export/brick0/holodilnik server2:/export/brick0/holodilnik server3:/export/brick0/holodilnik server1:/export/brick1/holodilnik server2:/export/brick1/holodilnik server3:/export/brick1/holodilnik server1:/export/brick2/holodilnik server2:/export/brick2/holodilnik server3:/export/brick2/holodilnik server1:/export/brick3/holodilnik server2:/export/brick3/holodilnik server3:/export/brick3/holodilnik server1:/export/brick4/holodilnik server2:/export/brick4/holodilnik server3:/export/brick4/holodilnik server1:/export/brick5/holodilnik server2:/export/brick5/holodilnik server3:/export/brick5/holodilnik server1:/export/brick6/holodilnik server2:/export/brick6/holodilnik server3:/export/brick6/holodilnik server1:/export/brick7/holodilnik server2:/export/brick7/holodilnik server3:/export/brick7/holodilnik server1:/export/brick8/holodilnik server2:/export/brick8/holodilnik server3:/export/brick8/holodilnik server1:/export/brick9/holodilnik server2:/export/brick9/holodilnik server3:/export/brick9/holodilnik force
Glasterが安定して動作するように、パラメーター、カーネルバージョン(3.10.0、4.5.4)、およびGlusterfs自体(3.8、3.10、3.13)の多数の組み合わせを試す必要がありました。
また、次のパラメーター値を実験的に設定します。
gluster volume set holodilnik performance.write-behind on gluster volume set holodilnik nfs.disable on gluster volume set holodilnik cluster.lookup-optimize off gluster volume set holodilnik performance.stat-prefetch off gluster volume set holodilnik server.allow-insecure on gluster volume set holodilnik storage.batch-fsync-delay-usec 0 gluster volume set holodilnik performance.client-io-threads off gluster volume set holodilnik network.frame-timeout 60 gluster volume set holodilnik performance.quick-read on gluster volume set holodilnik performance.flush-behind off gluster volume set holodilnik performance.io-cache off gluster volume set holodilnik performance.read-ahead off gluster volume set holodilnik performance.cache-size 0 gluster volume set holodilnik performance.io-thread-count 64 gluster volume set holodilnik performance.high-prio-threads 64 gluster volume set holodilnik performance.normal-prio-threads 64 gluster volume set holodilnik network.ping-timeout 5 gluster volume set holodilnik server.event-threads 16 gluster volume set holodilnik client.event-threads 16
追加の便利なオプション:
sysctl vm.swappiness=0 sysctl vm.vfs_cache_pressure=120 sysctl vm.dirty_ratio=5 echo "deadline" > /sys/block/sd[bk]/queue/scheduler echo "256" > /sys/block/sd[bk]/queue/nr_requests echo "16" > /proc/sys/vm/page-cluster blockdev --setra 4096 /dev/sd[bk]
バックアップの場合、つまり線形操作の場合、これらのパラメーターが優れていることを付け加える価値があります。 ランダムな読み取り/書き込みの場合、他のものを選択する必要があります。
次に、Glasterへのさまざまな接続の長所と短所、およびネガティブテストケースの結果を検討します。
volyumに接続するために、すべての主要オプションをテストしました。
1. backupvolfile-serverパラメーターを使用したGluster Native Client(glusterfs-fuse)。
短所:
-クライアントへの追加ソフトウェアのインストール。
-スピード。
プラス/マイナス:
-クラスターノードの1つがダンプされた場合のデータへの長いアクセス不能。 この問題は、network.ping-timeoutサーバー側オプションによって修正されます。 パラメータを5に設定すると、ボールはそれぞれ5秒間落ちます。
プラス:
-それは非常に安定して動作し、壊れたファイルに大きな問題はありませんでした。
2. Gluster Native Client(gluster-fuse)+ VRRP(キープアライブ)。
クラスターの2つのノード間で移動IPを構成し、そのうちの1つを消滅させました。
マイナス:
-追加ソフトウェアのインストール。
プラス:
-クラスターノードダンプが発生した場合の切り替え時の構成可能なタイムアウト。
判明したように、backupvolfile-serverパラメーターまたはkeepalived設定の指定はオプションであり、クライアント自体がGlasterデーモンに接続し(アドレスに関係なく)、残りのアドレスを認識し、クラスターのすべてのノードで記録を開始します。 この例では、クライアントからserver1およびserver2への対称トラフィックを確認しました。 あなたが彼にVIPアドレスを与えたとしても、クライアントはまだGlusterfsのクラスタアドレスを使用します。 起動時に、クライアントが使用できないGlusterfsサーバーに接続しようとすると、このパラメーターは有用であり、次にbackupvolfile-serverで指定されたホストに接続するという結論に達しました。
公式文書からのコメント:
FUSEクライアントでは、GlusterFSの「ラウンドロビン」スタイルの接続でマウントを行うことができます。 / etc / fstabでは、1つのノードの名前が使用されます。 ただし、内部メカニズムによりそのノードに障害が発生し、クライアントは信頼できるストレージプール内の他の接続されたノードにロールオーバーします。 パフォーマンスは、テストに基づくNFS方式よりもわずかに遅くなりますが、それほど大きくはありません。 利益は自動HAクライアントフェールオーバーであり、これは通常、パフォーマンスに影響する価値があります。
3. Pacemakerを使用したNFS-Ganeshaサーバー。
何らかの理由でネイティブクライアントを使用したくない場合に推奨される接続の種類。
短所:
-さらに追加のソフトウェア。
-ペースメーカーで大騒ぎ。
- バグをキャッチしました。
4. NFSv3およびNLM + VRRP(キープアライブ)。
ロックをサポートし、2つのクラスターノード間でIPを移動するクラシックNFS。
長所:
-ノードに障害が発生した場合の高速スイッチング。
-keepalivedのセットアップの容易さ。
-nfs-utilsは、デフォルトですべてのクライアントホストにインストールされます。
短所:
-マウントポイントへのrsyncが数分間続いた後、NFSクライアントをDステータスでハング。
-クライアントとのノードの完全なドロップ-バグ:ソフトロックアップ-CPUがXでスタックしている!
-ファイルが古いファイルハンドルのエラー、rm -rfで空でないディレクトリ、リモートI / Oエラーなどでファイルが破損した多くのケースをキャッチしました。
さらに最悪のオプションは、Glusterfsの以降のバージョンでは非推奨になりました。誰にもお勧めしません。
その結果、keepalivedとbackupvolfile-serverパラメーターなしでglusterfs-fuseを選択しました。 私たちの構成では、比較的低速にもかかわらず、安定性を示した唯一のものでした。
生産性の高い運用では、非常にアクセスしやすいソリューションを構成する必要性に加えて、事故が発生した場合にサービスを復元できる必要があります。 そのため、安定した作業クラスターを組み立てた後、破壊テストに進みました。
ノードの異常シャットダウン(コールドリブート)
1つのクライアントから多数のファイルのrsyncを起動し、クラスターノードの1つをハードオフして、非常に面白い結果を得ました。 ノードが落ちた後、最初に記録が5秒間停止し(network.ping-timeout 5パラメーターがこれに関与します)、その後、クライアントはデータを複製できなくなり、残りのノードへのすべてのトラフィックの送信を開始するため、ボールへの書き込み速度が2倍になりました1Gチャンネルに。

サーバーが起動すると、クラスター内の自動データ駆除プロセスが開始され、そのためにglustershdデーモンが原因となり、速度が大幅に低下しました。
そのため、ノードのダンプ後に処理されたファイルの数を確認できます。
gluster volume heal holodilnik info
...
Brick Server2:/エクスポート/ brick1 / holodilnik
/2018-01-20-weekly/billing.tar.gz
ステータス:接続済み
エントリー数:1
Brick Server2:/ export / brick5 / holodilnik
/2018-01-27-weekly/billing.tar.gz
ステータス:接続済み
エントリー数:1
Brick Server3:/ export / brick5 / holodilnik
/2018-01-27-weekly/billing.tar.gz
ステータス:接続済み
エントリー数:1
...
/2018-01-20-weekly/billing.tar.gz
ステータス:接続済み
エントリー数:1
Brick Server2:/ export / brick5 / holodilnik
/2018-01-27-weekly/billing.tar.gz
ステータス:接続済み
エントリー数:1
Brick Server3:/ export / brick5 / holodilnik
/2018-01-27-weekly/billing.tar.gz
ステータス:接続済み
エントリー数:1
...
治療の終わりに、カウンターはゼロにリセットされ、記録速度は以前の値に戻りました。
ディスクブレードとその交換
ブレードディスクダンプと交換は、ボールへの書き込み速度を低下させませんでした。 おそらく、ここでのボトルネックはディスクノードの速度ではなく、クラスターノード間のチャネルであることでしょう。 Infinibandカードを追加したらすぐに、より広いチャネルでテストを実施します。
クラッシュしたディスクを変更すると、sysfsで同じ名前(/ dev / sdX)で返されるはずです。 次のドライブが新しいドライブに割り当てられることがよくあります。 次回の再起動時に古い名前が使用され、ブロックデバイスの名前が移動し、ブリックが増加しないため、この形式で導入しないことを強くお勧めします。 したがって、いくつかのアクションを実行する必要があります。
おそらく、問題はシステムのどこかにクラッシュしたディスクのマウントポイントがあったことです。 したがって、umountを実行してください。
umount /dev/sdX
また、このデバイスが保持できるプロセスを確認します。
lsof | grep sdX
そして、このプロセスを停止します。
その後、再スキャンを行う必要があります。
クラッシュしたディスクの場所に関する詳細情報については、dmesg-Hをご覧ください。
[Feb14 12:28] quiet_error: 29686 callbacks suppressed
[ +0.000005] Buffer I/O error on device sdf, logical block 122060815
[ +0.000042] lost page write due to I/O error on sdf
[ +0.001007] blk_update_request: I/O error, dev sdf, sector 1952988564
[ +0.000043] XFS (sdf): metadata I/O error: block 0x74683d94 ("xlog_iodone") error 5 numblks 64
[ +0.000074] XFS (sdf): xfs_do_force_shutdown(0x2) called from line 1180 of file fs/xfs/xfs_log.c. Return address = 0xffffffffa031bbbe
[ +0.000026] XFS (sdf): Log I/O Error Detected. Shutting down filesystem
[ +0.000029] XFS (sdf): Please umount the filesystem and rectify the problem(s)
[ +0.000034] XFS (sdf): xfs_log_force: error -5 returned.
[ +2.449233] XFS (sdf): xfs_log_force: error -5 returned.
[ +4.106773] sd 0:2:5:0: [sdf] Synchronizing SCSI cache
[ +25.997287] XFS (sdf): xfs_log_force: error -5 returned.
sd 0:2:5:0 — :
h == hostadapter id (first one being 0)
c == SCSI channel on hostadapter (first one being 2) — PCI-
t == ID (5) —
l == LUN (first one being 0)
再スキャン:
echo 1 > /sys/block/sdY/device/delete echo "2 5 0" > /sys/class/scsi_host/host0/scan
ここで、sdYは交換されたドライブの誤った名前です。
次に、ブリックを置き換えるには、マウント用の新しいディレクトリを作成し、ファイルシステムをロールアップしてマウントする必要があります。
mkdir -p /export/newvol/brick mkfs.xfs /dev/sdf -f mount /dev/sdf /export/newvol/
レンガを交換します。
gluster volume replace-brick holodilnik server1:/export/sdf/brick server1:/export/newvol/brick commit force
治療を開始します。
gluster volume heal holodilnik full gluster volume heal holodilnik info summary
レフリーブレード:
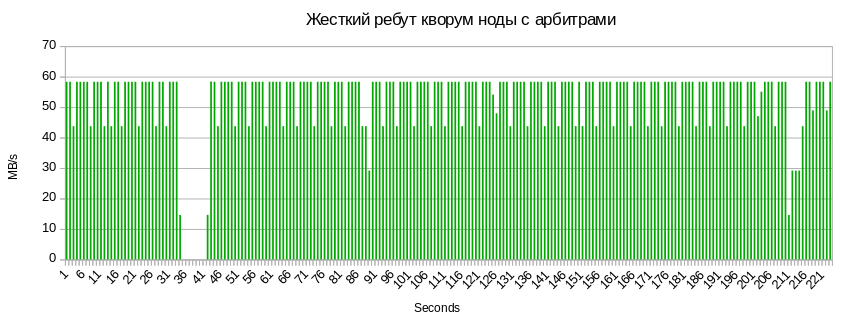
クォーラムノード上のメタデータの同期に関連して、同じ5〜7秒のボールへのアクセス不能と3秒のドローダウン。
まとめ
破壊的なテストの結果は私たちを喜ばせ、製品に部分的に導入しましたが、長い間幸せではありませんでした...
問題1、既知のバグ
多数のファイルとディレクトリ(約100,000)を削除するとき、次の「美」を食べました。
rm -rf /mnt/holodilnik/* rm: cannot remove 'backups/public': Remote I/O error rm: cannot remove 'backups/mongo/5919d69b46e0fb008d23778c/mc.ru-msk': Directory not empty rm: cannot remove 'billing/2018-02-02_before-update_0.10.0/mongodb/': Stale file handle
2013年に始まるこのようなアプリケーションを約30冊読みました。 問題の解決策はどこにもありません。
Red Hat はバージョンの更新を推奨していますが、これは役に立ちませんでした。
回避策は、すべてのノードのブリックにある壊れたディレクトリの残りをクリーンアップすることです。
pdsh -w server[1-3] -- rm -rf /export/brick[0-9]/holodilnik/<failed_dir_path>
しかし、さらに悪いことです。
問題2、最悪
ストライプボリュームボール内の多数のファイルでアーカイブを解凍し、Uninterruptible sleepでぶら下がりtar xvfzを取得しようとしました。 これは、クライアントノードの再起動によってのみ処理されます。
そんなふうに生きていけないことに気付いた私たちは、最後に試したことのない構成に目を向けました。 その唯一の難しさは、ボリュームを組み立てる原理を理解することです。
すべて同じ破壊テストを実行した結果、同じ快適な結果が得られました。 何百万ものファイルがダウンロードされ、削除されました。 試してすぐに、分散ボリュームの破壊に成功しませんでした。 CPUの負荷が高くなりましたが、これまでのところこれは重要ではありません。
現在では、インフラストラクチャの一部をバックアップし、内部アプリケーションのファイルクリーナーとして使用されています。 さまざまな負荷の下で彼がどのように機能するかを見るために、彼と一緒に暮らしたいと思っています。 ストライプボリュームのタイプが奇妙に機能し、残りが非常にうまく機能することは明らかです。 さらに計画-広いInfinibandチャネルを備えた6台のサーバーで50 TBの分散ボリューム4 + 2を収集し、パフォーマンステストを実行し、その作業の原則をさらに深く掘り下げます。