最近、 タスクを公開することが流行になってきました。 投稿の中で、私はオドノクラスニキの仕事について考えを述べることにしました。 私はタスクが好きでしたが、非常に曖昧であることが判明し、すべてをリーフレットに割り当てられたスペースに入れることはできません 。 話し合いますか?
注意! 元の記事では、問題の完全な状態を把握し、自分で解決できます。
コードスニペットは、著者の分析から借用しています。
1.音楽トラックの分割と分割
/** * @return partition between 0 inclusive * and partitions exclusive */ int partition(Track track, int partitions) { assert track != null; assert partitions > 0; return track.hashCode() % partitions; }
サーバー上のTrack
オブジェクトをパーティション分割するアルゴリズムの何が問題になっていますか?
hashCode()
タスクの条件から、
hashCode()
メソッドが
Track
クラスで
hashCode()
れるのか、
Object
クラスの実装が使用されるのかは不明のままです。
ケース1:
hashCode()
メソッドが
hashCode()
ます。 Javadocはかなり説得力があるように見えますが、以前はjavadocを信頼していましたよね? ;)そのため、Vadimは負の
hashCode
値を処理する必要がありました(または誰かがFlakyテストを取得しました)。
この場合、なぜこのコードで障害を見つけるのですか? 最初に目を引くのは、パーティションアルゴリズムがサーバーの数と密接に関係していることです。 この問題は、シャードの数に関するさまざまな分散ストレージのユーザーが直面しています。 たとえば、 この問題は Elasticsearchに関連しています。 MongoDBのドキュメントもこのことを思い出させてくれます。
シャードの数とシャードキー計算アルゴリズムの選択は、責任のあるタスクです。 ElasticsearchとMongoDBを使用した上記の例では、シャードの数を変更することは意識的な要望です。 しかし、シャードサーバーが、意思に関係なく、休止することに決めた場合は、レプリケーションが役立ちます。 以下は、MongoDBのレプリカセット組織図です。
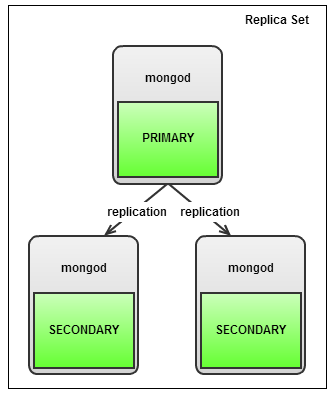
somenines.comからの画像 。
ケース2:
Object.hashCode()
メソッドが使用されます。 このメソッドのJavadocは、これについて最もよく伝えます(キーフラグメントが強調表示されています)。
同じオブジェクトで複数回呼び出されたとき後者は、アプリケーションの再起動後の同じオブジェクトの
Javaアプリケーションの実行、hashCode
メソッド
情報がない場合は、常に同じ整数を返す必要があります
オブジェクトの等equals
比較で使用されるオブジェクトが変更されます。
この整数は、1回の実行で一貫性を保つ必要はありません。
同じアプリケーションの別の実行へのアプリケーション。
hashCode
値が異なる可能性が高いことを意味します。 オブジェクトは、ビジネスロジックのコンテキスト(たとえば、データベースから取得)で同じです。 しかし、これはそれほど悪くはありません。その結果、ある時点で異なるサーバー上で、ハッシュも異なる可能性が高くなります。
hashCode
不安定性と負の値の可能性によりFlaky-testsが発生する場合があります 。 大まかに言うと、これらは同じコードベースで何らかの理由で赤くなり、調査の瞬間に(または自分で) 突然緑に変わるテストです。
特別な場合:
hashCode()
メソッドは、
hashCode
ビジネスデータ(プリミティブと文字列)に依存します。 このケースは最も一般的であり、それほど興味深いものではありません!
たとえば、Intellij IDEAでは、単純なデータクラスの
hashCode()
および
equals()
メソッドを生成できます。
public class Address { private final String street; private final Integer house; }
この実装を取得します:
@Override public int hashCode() { int result = street != null ? street.hashCode() : 0; result = 31 * result + (house != null ? house.hashCode() : 0); return result; }
では、問題は何ですか? 結論を出すには時期尚早です。ソースコード(JDK 8)の調査を続けます。
public final class String { /** * Returns a hash code for this string. The hash code for a * {@code String} object is computed as * <blockquote><pre> * s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1] * </pre></blockquote> * using {@code int} arithmetic, where {@code s[i]} is the * <i>i</i>th character of the string, {@code n} is the length of * the string, and {@code ^} indicates exponentiation. * (The hash value of the empty string is zero.) * * @return a hash code value for this object. */ @Override public int hashCode() { int h = hash; if (h == 0 && value.length > 0) { char val[] = value; for (int i = 0; i < value.length; i++) { h = 31 * h + val[i]; } hash = h; } return h; } } public final class Integer { /** * Returns a hash code for this {@code Integer}. * * @return a hash code value for this object, equal to the * primitive {@code int} value represented by this * {@code Integer} object. */ @Override public int hashCode() { return Integer.hashCode(value); } /** * Returns a hash code for a {@code int} value; compatible with * {@code Integer.hashCode()}. * * @param value the value to hash * @since 1.8 * * @return a hash code value for a {@code int} value. */ public static int hashCode(int value) { return value; } }
さて、アプリケーションの再起動間で結果が再現可能であることを確認しました。 問題は、 実装の詳細に依存していることです。 Javaの将来のバージョンで動作が変更されないという保証はありません。 信頼できるjavadocの一意性にもかかわらず、それらは現在の実装にのみ関連しています。
追加。
String.hashCode()
のスクロールはそれほど真実ではありません。 コメントに正しく記載されているように、アルゴリズムを変更すると、大量のコンパイルされたコードが無効になり、Javaコミュニティ全体が怒ります。
例
ソースコードは次のとおりです。
コンパイル先:
ご覧のとおり、コンパイルされたコードではハッシュは定数です。
switch(s) { case "s": System.out.println("S"); break; case "b": System.out.println("B"); break; }
コンパイル先:
int var_ = -1; switch(s.hashCode()) { case 98: if(s.equals("b")) { var_ = 1; } break; case 115: if(s.equals("s")) { var_ = 0; } } switch(var_) { case 0: System.out.println("S"); break; case 1: System.out.println("B"); }
ご覧のとおり、コンパイルされたコードではハッシュは定数です。
断言する
私は
assert
ことがあまり好きではないとすぐに言います。 assertステートメント ( JLS 14.10 )を使用することについてのみです。
2つのユースケースがあることを思い出させてください。
assert condition [: msg];
condition == false
場合、
AssertionError
エラーがスローされます。 同時に、
msg
式が指定されていない場合、 詳細メッセージなしでエラーが発生しますが 、これは受け入れがたいです。 2番目の場合、コンストラクター
AssetionError(String detailMessage)
が呼び出されます。
簡単な例から始めましょう:
public class Main { public static void main(String[] args) { assert args.length != 0; assert args.length == 0; System.out.println("OMG! Is it possible?"); } }
突然、
OMG! Is it possible?
がコンソールに表示されます
OMG! Is it possible?
OMG! Is it possible?
assert
デフォルトでは有効になっていないため:
java -ea | -enableassertions Main
java -ea | -enableassertions Main
。
assertを使用しない理由
まず、短いレコードを使用すると、何もないよりも少し多くの情報が得られます。スタックトレースがなければ、それを把握することはできません。
次に、
Error
ためにjavadocを参照します。
/** * An {@code Error} is a subclass of {@code Throwable} * that indicates serious problems that a reasonable application * should not try to catch. Most such errors are abnormal conditions. * The {@code ThreadDeath} error, though a "normal" condition, * is also a subclass of {@code Error} because most applications * should not try to catch it. * <p> * A method is not required to declare in its {@code throws} * clause any subclasses of {@code Error} that might be thrown * during the execution of the method but not caught, since these * errors are abnormal conditions that should never occur. * * That is, {@code Error} and its subclasses are regarded as unchecked * exceptions for the purposes of compile-time checking of exceptions. * * @author Frank Yellin * @see java.lang.ThreadDeath * @jls 11.2 Compile-Time Checking of Exceptions * @since JDK1.0 */ public class Error extends Throwable { /* code omitted */ }
私の見解では 、Error
は、合理的なアプリケーションがキャッチしようとしてはならない重大な問題を示します。 そのようなエラーのほとんどは異常な状態です。
Error
はビジネス例外としてユーザーコードによって使用されるべきではなく、その外観はバグの存在を示すべきです。 タスクのコードでは、
partitions == 0
、コードにエラーが存在するというよりもビジネスチェックに似ています。
たとえば、使用可能な単一のシャードはありません-それは非常に通常の(処理された)状況です。
partition()
メソッドがこのケースを処理する必要がありますか? おそらくそうではありませんが、それは別の問題です。
どちらの場合でも、
IllegalArgumentException
を使用する方が適切です。
おわりに
この課題は、テストを使用する利点の代表例です。 同時に、これは不安定なテストがどのように現れるかを示す良いデモンストレーションです。
assert
の使用に関しては、テストを本質的に製品コードに転送する必要はないという立場
assert
固守しています。
脳トレーニングのための著者に感謝します。