現在、人工知能は最も議論されているトピックの1つであり、デジタルビジネス変革の主要なエンジンです。 MicrosoftのAI戦略には、開発者向けのAIの民主化、つまり 知的問題を解決するための使いやすいフレームワークとサービスを提供します。 この記事では、.NET開発者がプロジェクトでAIの機能を使用する方法について説明します。クラウドで動作する既製の認知サービスから、.NET言語でのニューラルネットワークのトレーニング、Raspberry Piなどのコンパクトなデバイスでの複雑なニューラルネットワークの実行まで。
記事のプロトタイプは、 DotNext 2017モスクワ会議でのDmitry Soshnikovによるレポートでした。 Dmitryは、マイクロソフトのテクノロジエバンジェリストであり、初心者の開発者の間で最新のソフトウェア開発テクノロジを推進しています。 モノのインターネットの分野、ユニバーサルWindowsアプリケーションの開発、関数型プログラミングの分野、および.NETプラットフォーム(F#、Roslyn)を専門としています。 彼は個人的にロシアで数十のハッカソンを実施し、多くの学生のスタートアップがさまざまな分野でプロジェクトを開始するのを助けました。 准教授、博士は、モスクワ物理学技術研究所とロシア人工知能協会のメンバーであるモスクワ航空研究所で、夏にUNIO-R子供キャンプのコンピューター技術学科の指導者として授業を行っています。
注意トラフィック! この投稿には、膨大な数の写真があります。720p形式のビデオのスライドとスクリーンショットです。
この記事では、人工知能について説明します。 なぜ今彼について話すのが流行なのですか? なぜなら、それは世界を非常に急速に変化させる一連のテクノロジーだからです。
世界の変化の例は、マクドナルドです。 そしてアメリカでは、McAutoがあります。 注文を受け取る男性がそこに座っています。 そして、すでに約20年前にアメリカでは、そこに人は必要ないと決められました。彼をインドに座っているオペレーターと交換する必要があります-それはずっと安くなります。 彼は訪問者と電話で話し、それをすべてコンピューターに入れます。注文は準備され、アメリカ人に支払う必要はありません。 窓に座っているアメリカ人は非常に高価です。 この決定により、価格を下げることができました。ハンバーガーが安くなり、人々の健康が低下しました。すべてが順調です。 この方向の最後の一歩は、そこに人はまったく必要ないことに気づいたときに行われました。 これを取得して、音声認識アルゴリズムに置き換えることができます。 このようなプロジェクトは1年以上前に、米国マイクロソフトの同僚によって作成されました。
インターネットには、マクドナルドの窓にいる人が聞いていることを理解し、その人の苦しみの全体の深さを感じることができるビデオがあります。 彼は何も聞こえません。騒音があり、車が通り過ぎており、彼はこれを認識せざるを得ません。 人間は疲れるので、AIは人間よりもうまく対処できます。
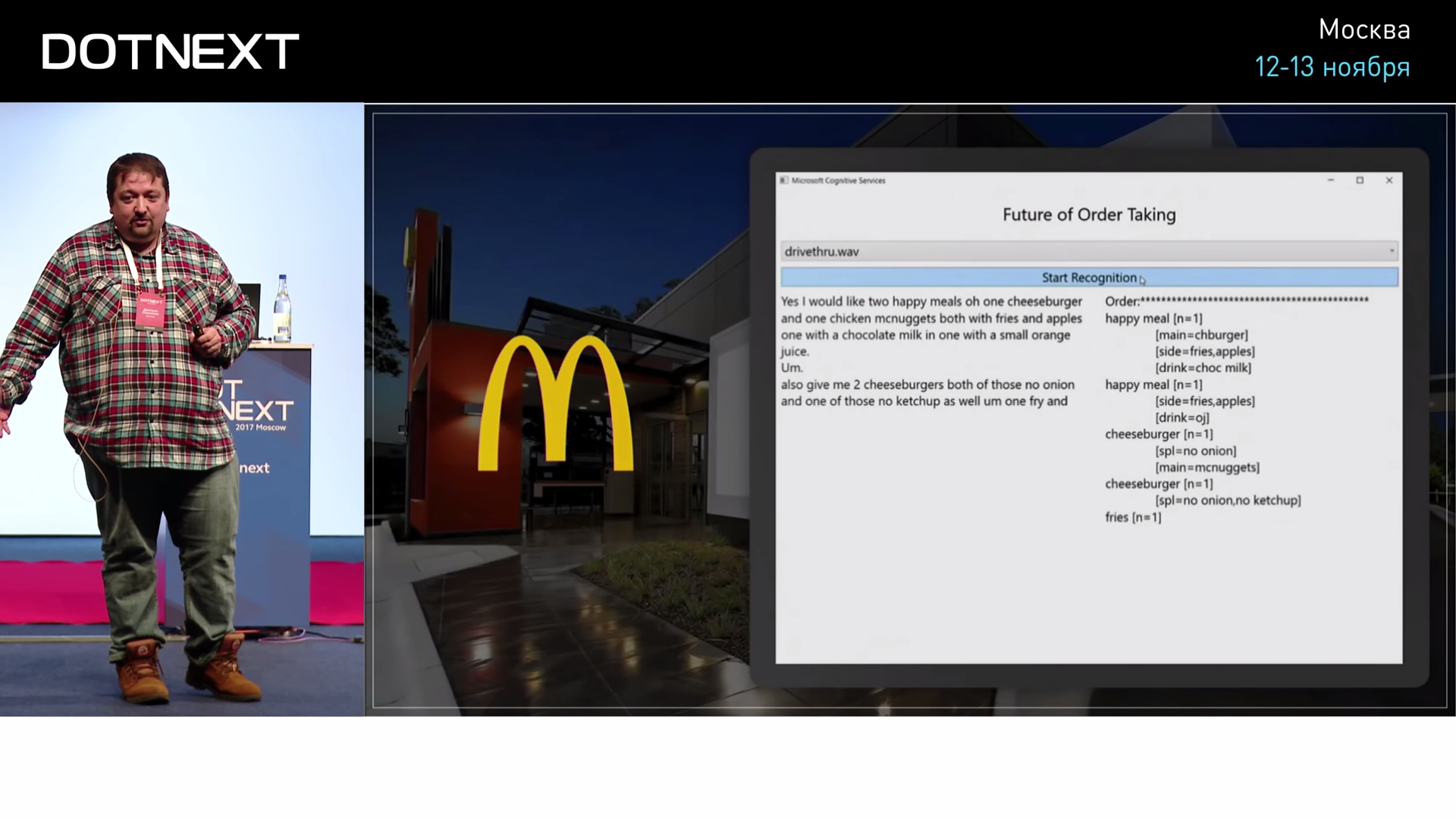
注文を出す場合、オペレーターとの会話は非常に具体的なトピックで行われ、誰もそのようなウィンドウで人生の意味について話すことはありません。 メニューが明確なとき、言葉が明確なとき、コンピュータは人よりもよく認識します。 2016年、Microsoftは、人間よりも優れた音声認識アルゴリズムを最終的に作成したという声明を発表しました。 テストされ、本当に優れていることが確認されました。
2015年、コンピューターは特定の画像(交通標識)を認識し始めました。 従来、1000枚の写真の中から、コンピュータは人よりも道路標識を見つけやすくなっています。 なんで? おそらく、これは中央のどこかで人を悩ませますが、コンピュータでは悩みません。 しかし、結果は結果です。コンピューターは私たちよりもそのようなタスクにうまく対処します。
AIでのMicrosoftの業績のリストは次のとおりです;それらは印象的です。

マイクロソフトは他の先を行っています。 クラウドでプログラムされたFPGAチップを使用してニューラルネットワークを実行する方法に関する研究が進行中です。 ここでのソリューションの範囲は広範です。
会社の全体的な戦略は何ですか? AIの分野でマイクロソフトは何をしていますか?
まず、当然、製品に導入します。 Power BI、HoloLens-認識が今ではめちゃくちゃになっています。 また、PowerPointには、AIが使用される多くの場所があります。 たとえば、「スライドをデザインしてください」というボタンがあり、「デザインのアイデア」と呼ばれ、シンプルなスライドのデザインを提供します。 これは、機械学習とAIテクノロジーの適用の結果です。 または、PowerPointに画像を挿入すると、自然言語の署名が生成されます-それに描かれているもの。 次に、Webのどこかにエクスポートすると、対応するタグが正しく付加されます。 些細なことのように思えますが、素晴らしいことです。
AIは製品に導入され、クラウドでより効率的に使用する方法について研究が行われています。そして、最も重要なのは開発者にとって、AIは使いやすくするために民主化されています。

認知サービスがあります。 これらは、画像処理など、対処する必要がある基本的なタスクに単純に使用できます。 たとえば、製品に機能を導入して、画像にキャプションが自動的に挿入されるようにします。 これは難しくありません-既製のクラウドサービスがあります。写真を提供すると、彼は英語で説明を返します。 機械翻訳を製品に導入する場合、すべてが非常に簡単です。BingTranslatorサービスを使用すると、ほぼすべての言語からあらゆる言語への翻訳が提供されます。 これらの機能は誰でも利用できます。
民主化には、認知サービス、ボット、機械学習-Azure ML、ニューラルネットワーク-Microsoft Cognitive Toolkitの4つの主要な領域があります。 最後の2つについて説明しましょう。
機械学習の主なアイデアは、コンピューターがデータに対して何かを行う方法を学習することです。
たとえば、写真から人間の感情を認識する方法を学びたいです。 これをどのように行うことができますか?

アルゴリズムの書き方を考えると、すぐに行き止まりになることは明らかです。 たとえば、驚きと恐怖を正確に区別する方法はわかりません。どちらの場合も目は丸いです。 これをアルゴリズム的に行う方法は明確ではありません。 そして、多くの写真を撮るなら、おそらく、どういうわけか自動的にそれを行うことができます。 どうやって? まず、写真からいくつかの基本的な兆候を特定することが重要です。何らかの数値インジケータに切り替えることが重要です。 なぜなら写真は多くの詳細を伴う抽象的なものだからです。 しかし、たとえば、目の位置、唇の角の位置を認識し、表で表すことができる数値的なものに進むことができます。 さらに、これは入力として機械学習に適用できるため、アルゴリズムはそれらのパターンを見つけ、予測を行うことができるモデルを構築します。 次に、顔を取り、その中の同じ記号を強調表示して、モデルの入力に送信します。モデルは、たとえば、これは80%が幸せ、20%が何か他の人であると伝えます。

用語について話す場合、人工知能は人間のタスクに対処する何かをする一般的なトピックです。 機械学習はAIの一部です。アルゴリズムが私たちによって書かれていない場合、データ処理に基づいて書かれています。 ニューラルネットワークは、機械学習の1つの特定のケースです。 また、ニューラルネットワークの内部では、ファッショナブルな用語である「ディープラーニング」も、ニューラルネットワークが深い場合に区別されます。 一般に、多くの複雑なタスクはこの非常に「深い学習」の助けを借りて正確に解決されるため、ニューラルネットワークは残りのアルゴリズムを混雑させています。

ツールに関して:ディープラーニングを行う人々はどのように生きますか? PythonとRの2つの言語があります。Pythonがデータサイエンティストに人気を博したのはなぜですか? もちろん、C ++で書かれた非常に優れたライブラリが多数ありますが(そうでなければ遅いので)、Pythonには非常に優れたラッパーがあります。 したがって、Pythonをさまざまなライブラリの接着剤として使用すると便利であることがわかりました。 また、機械学習用のライブラリがすでに多数あるため、それらを選択して使用を開始できるようになりました。
ニューラルネットワークでも同じです。 誰もがライブラリを実装し始めたとき、「すべてのデータサイエンティストがPythonで記述しているため、すべてのライブラリをPythonで作成する必要もあります。」と考えました。 そのため、Pythonをサポートするライブラリが多数ありました。 MicrosoftでさえCNTKライブラリのPythonサポートを作成しましたが、.NETは長い間サポートしませんでした。
R言語では、さらに興味深いことがあります。Rには、既成の包括的なRアーカイブネットワークがあり、あらゆる場面で既製のライブラリがたくさんあります。 この言語と他の10万のライブラリを学ぶ必要があります。
そして、これに遭遇したことがない人はどうですか?

一方では、勉強に行くことができますが、したくありません。 私はニューラルネットワークを使用する必要があるため、Pythonを使用する場合、それほど嫌悪感を感じることはありませんが、これを行うのは困難です。 型付けされた美しい.NET言語の後、すべてを開始したときにエラーがチェックされず明確にされる型付けされていない言語に切り替えることは、心理的に非常に困難です。 手のないプログラミングのような感覚。
ニューラルネットワークの機械学習とトレーニングの問題を解決するために、.NETの世界にどんなツールがあるのか見てみましょう。

「一般的に、自分で何かを書くのは難しいですか?」という質問から始めましょう。 簡単な場合はどうなりますか?」
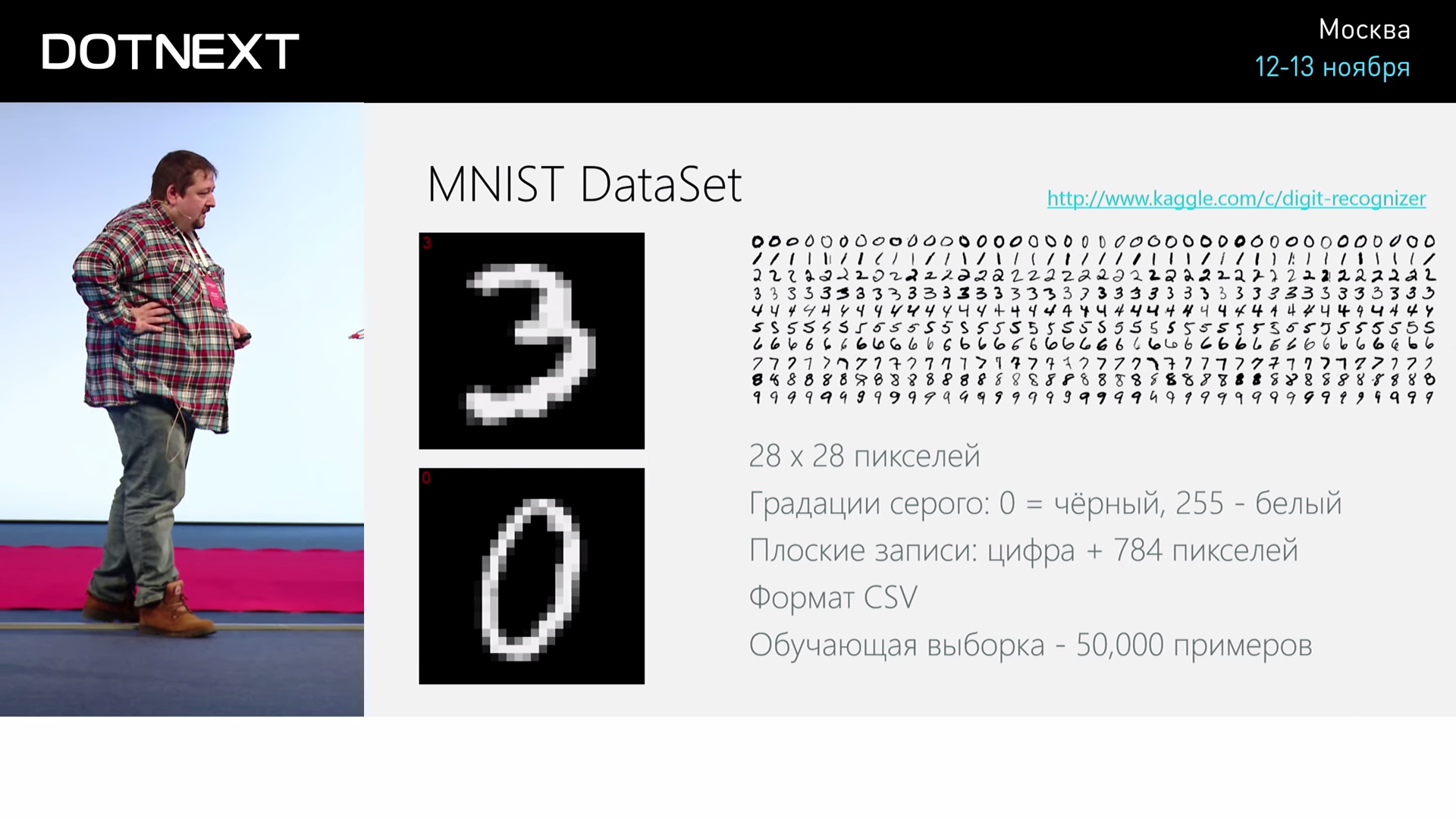
そして、そのような古典的なタスクを取りましょう:手書き数字認識。 米国統計局の一部の従業員が書いた50,000〜70000の手書き数字のどこかに既製のデータセットがあります。 このデータは公開されており、28 x 28ピクセルの画像として表示されます。 この作業はそれほど難しくないように思えますが、一方で、あまりにも単純ではなく、一部のおもちゃはまったくなく、モスクワのアパートの価格を予測していません。 彼女にアプローチする方法はあまり明確ではありません。 この問題をどのように解決し、どのように効率的かつ適切に解決できるかを見てみましょう。
頭に浮かぶ最も簡単な解決策は何ですか? 50,000の例があり、誰かが数字を書いて「この数字は何ですか?」と言います。 50,000個すべてと単純に比較して、最も適切なものを選択できます。 比較する方法は? ピクセル単位の明るさの違いを考慮することができます。

このようなアルゴリズムは、Kが1である「K最近傍」と呼ばれます。プログラミングが困難かどうかを見てみましょう。

同時に、すべてのデータサイエンティストが使用する優れたツールであるJupyter Notebookを紹介します。 これは、Web上のプログラムテキストとmarqdownで記述されたテキストを組み合わせることができる非常に便利なツールです。 こんな感じです。
テキストセルがあり、実行できるコードセルがあります。 Jupyter NotebookはPythonの世界のツールであるため、PythonとRを十分にサポートしますが、C#、F#、Prologなどの他の言語のサポートも追加できます。 同時に、マイクロソフトは次のように述べています。「これらのJupyterノートブックをクラウドで使用できるようにします。」 これを自分でインストールする場合は、コンピューターにPython、Jupyterをインストールし、すべて実行してからブラウザーで開く必要があります。 また、Microsoftは既製のノートブックをクラウドで提供しています。notebooks.azure.comにアクセスして作業を開始できます。Microsoftアカウントでログインし、コードを使用してこれらのノートブックを作成できます。 このコードはクラウドで無料で実行されますが、特定の制限があります。 たとえば、クラウドまたはGitHubからの特定の場所からのみデータを取得できます。 これらのMicrosoftノートブックは、Python、R、およびF#をサポートしています。 C#-いいえ、F#サポート。 なんで? F#の方が良いからですか?
実際、F#にはすてきな既製の優れたサポートが既にあるためです。 C#には、Xamarin Workbookと呼ばれる同様のツールがあります。 これは多少似ており、コンピューター上でローカルに機能しますが、コードとテキストを組み合わせることができます。 コードをテキストと組み合わせると、すべてが一度に明確になり、すべての手順が説明されるため、非常に便利です。
これらの数値の画像は、CSV(コンマ区切り値)の形式で表示されます。 さらに、各行の最初の要素は書き込まれた数字そのものであり、残りは784個の数字の配列であり、それぞれが対応するピクセルの明るさです。 そして、この数字の行列は、数字の長い列に配置されています。 F#で、これらの値をインターネットから取得し、そのような長い行を読み取って返す関数を説明しました。
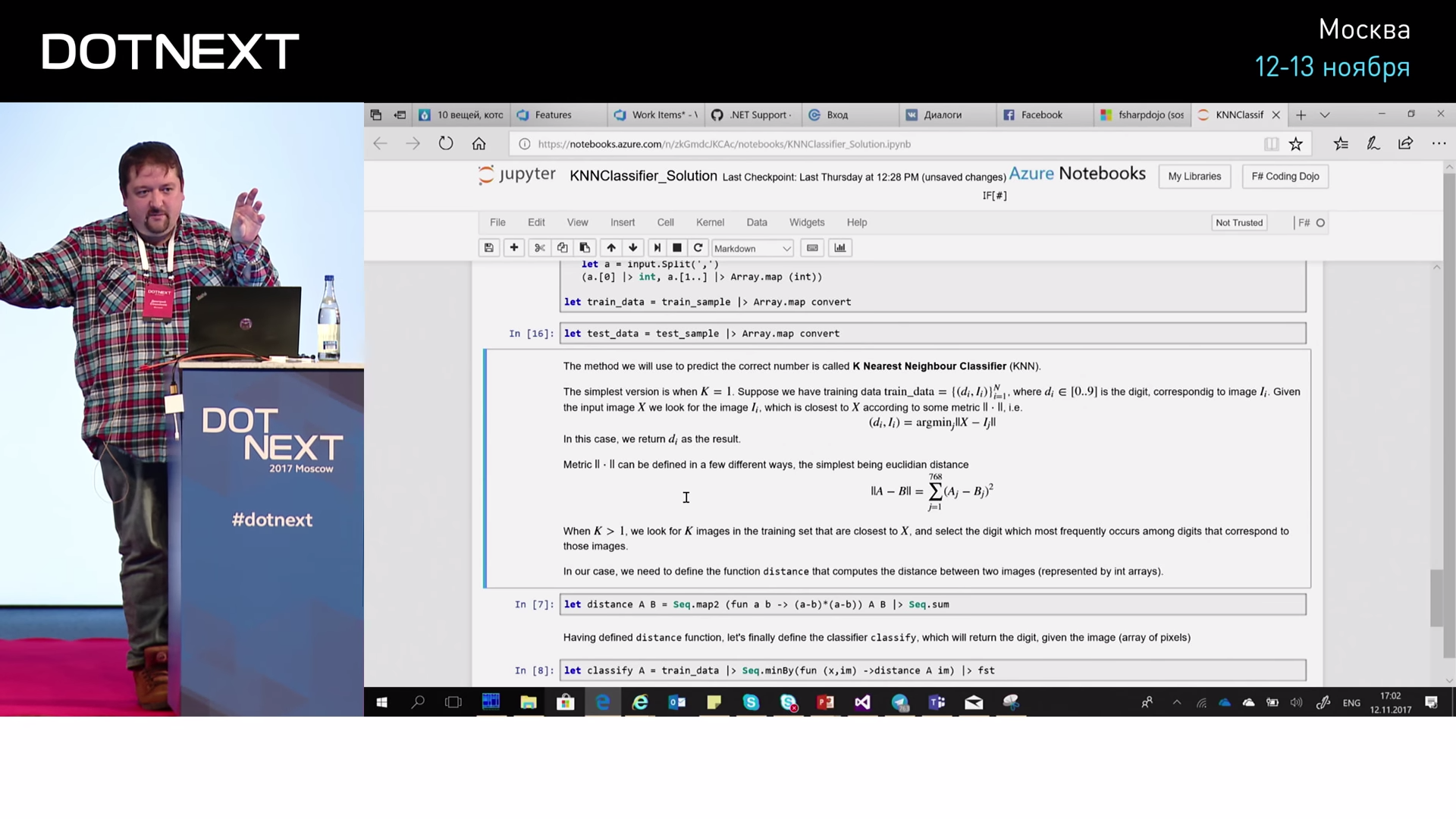
さて、これで何かをするために、それを配列に入れて2つの部分に分けます: train_sample
これはトレーニングサンプル、 test_sample
これは検証用です。 通常、50,000のトレーニングと数千のテストを実施します。 そして、それらを便利な形にします。ペアで提示します。 ペアでは、数字と残りのピクセルの配列があります。 そして、そのようなカップルがたくさんあります。
次に、どのようにして最も近いものを見つけるのでしょうか? 最も近いものを見つけるために、距離を決定する必要があります。 距離を決定するために、距離関数を説明します。この関数は、イメージを含む2つの配列を受け取り、これらの配列を反復処理し、平方の差と合計を考慮します。 つまり、これはデカルト距離であり、単にルートを抽出しません。 近接性を示します。配列が同じ場合はゼロを示し、少し異なる場合はいくつかの数があります。 そして、対応する数字を見つけるために、すべてのtrain_data
- train_data
を取得し、それらのどれが最小距離であるかを探し、対応する数字を取得します。 コードは簡単です。 さらに開始すると、すべてが機能します。

テストデータを取得します。 この場合、上位3つのエントリを取得して認識しようとします。8は8、7は7、2は2として認識されます。これは良いことで、希望を呼び起こします。 テストサンプル全体をさらに調べると、94%の正しい認識が得られます。 これは、原則として非常に優れています。
94%-ほんの数行しか書いていませんが、これ以上ほとんど何もできません。
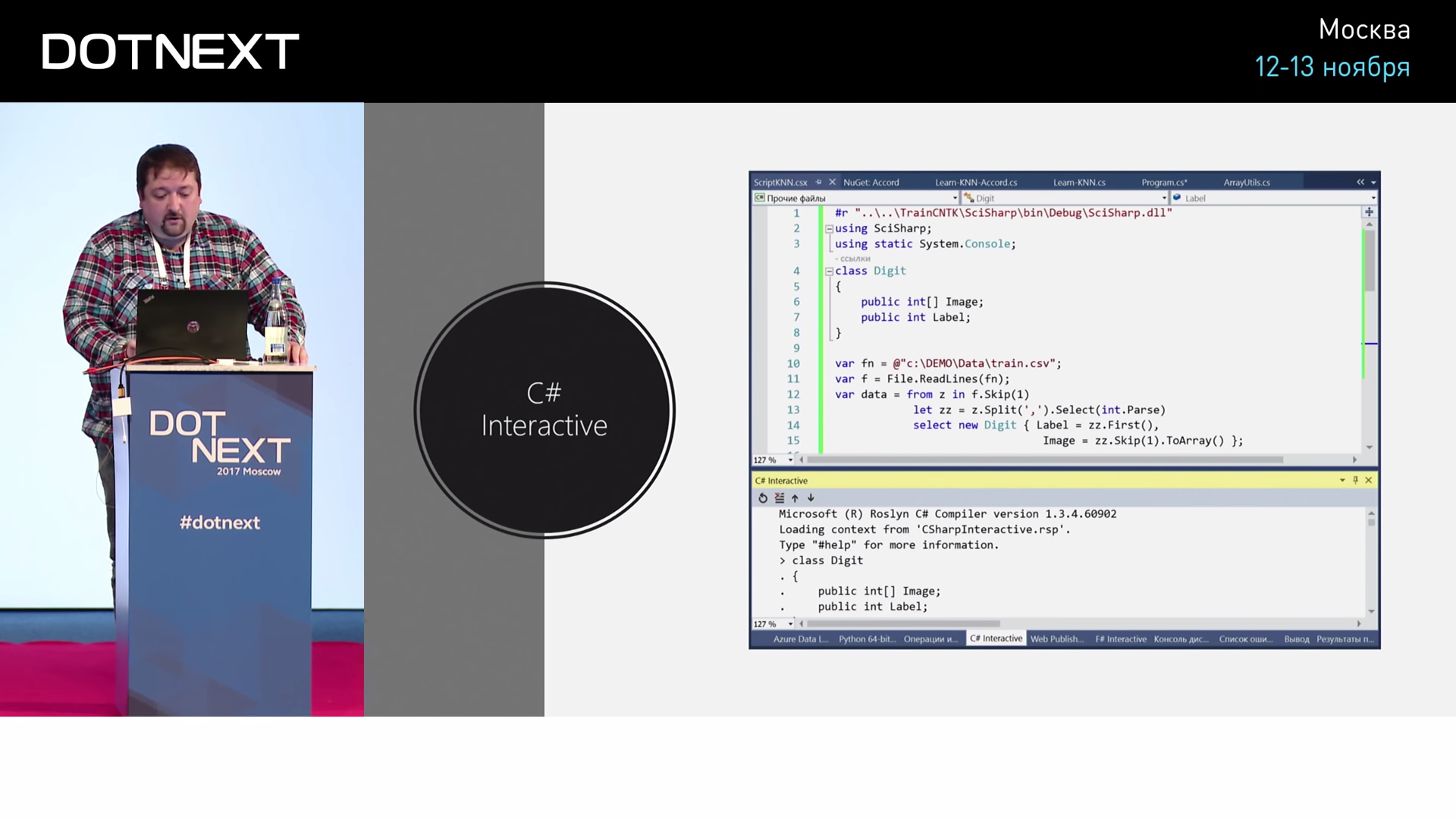
そして、C#で同じことをしたい場合は?
誰かが知らない場合は表示します。 Visual Studioには、C#Interactiveという優れたツールがあります。 これは、次のようにC#を直接実行できるコンソールです。テキストを選択し、キーを押すと、コンソールで実行されます。 C#で同じことをしたい場合、どのようになりますか?
#r "SciSharp.dll" using SciSharp; using static System.Console; class Digit { public int[] Image; public int Label; } var fn = @"train.csv"; var f = File.ReadLines(fn); var data = from z in f.Skip(1) let zz = z.Split(',').Select(int.Parse) select new Digit { Label = zz.First(), Image = zz.Skip(1).toArray(); }; var train = data.Take(10000).toArray(); var test = data.Skip(10000).Take(1000).toArray(); Func<int[ ],int[ ],int> dist = (a, b) => a.Zip(b, (x, y) => { return (x - y); } ).Sum(); Func<int[ ], int> classify = (im) => train.MindBy(d => dist(d.Image, im)).Label; int count = 0, correct = 0; foreach (var z in test) { var n = classify(z.Image); WriteLine("{0} => {1}", z.Label, n); if (z.Label == n) correct++; count++; }
以上です。 その後、実行して結果を楽しむことができます。 数字はゆっくりと認識されます。これは、数字ごとに50,000レコード(この場合は50,000レコードではなく、10,000レコード)を調べる必要があるためです。 したがって、実際の使用では、このようなアルゴリズムはあまり適していません。 すぐに書きましたが、それほど悪くはありませんが、非常に遅いです。 一般に、機械学習が高速で動作するモデルを構築し、プロセスの本質をカプセル化するのは素晴らしいことです。すべてのソースデータと比較するたびにではありませんが、ある程度の規則性があります。 したがって、もちろん、他のアルゴリズムを使用することをお勧めします。

したがって、スムーズに次のエピソードに進みます。

自分でプログラムを作成しないようにするには、既製のライブラリがあるかどうかを確認する必要があります。 ここで、.NETにはAccord.NETと呼ばれる優れたライブラリがあることがわかりました。

機械学習を行うには、マトリックス、統計、およびさまざまな統計関数を適切に処理できる必要があります。 また、Accord.NETには関連する要素が含まれています。 統計を担当するフラグメントがあり、遺伝的アルゴリズム、ニューラルネットワーク、音の処理、画像を担当するアルゴリズムがあります。 グラフを作成できる便利な機能もあります。 データサイエンティストは、多くの場合、データが相互にどのように依存しているかを確認する必要があります。
このために、すでにプログラムを作成します。WriteLineが書き込まれているような空白があります。 これは、すでに存在しているのと同じコードです。 彼はすべてのデータを私に読み、テストとトレーニングのサンプルに分割します。 そして、Accord.NETを使用して、これらの数字を画面に描画します。 このような美しい関数があります-ImageBox.Showを使用すると、何かを描画できます。
#r "SciSharp.dll" using SciSharp; using static System.Console; class Digit { public int[] Image; public int Label; } var fn = @"train.csv"; var f = File.ReadLines(fn); var data = from z in f.Skip(1) let zz = z.Split(',').Select(int.Parse) select new Digit { Label = zz.First(), Image = zz.Skip(1).toArray(); }; var train = data.Take(10000).toArray(); var test = data.Skip(10000).Take(1000).toArray(); for (int i = 0; i < 5; i++) { ImageBox.show(train[i].Image.Select(x => x / 256.0).toArray(), 28, 28); }
次に、何らかの学習アルゴリズムをそれらに適用します。 まず、同じKNearestNeighbors分類子。 アコードではどのように見えますか?
var classifier = new KNearestNeighbors(1); classifer.Learn( (from x in train select x.Image.Select(z=>(double)z).toArray()).toArray(), (from x in train select x.Label).toArray());
「Kが1のKNearestNeighbors分類器を作成したい」と単純に言います。 ところで、KNNアルゴリズムでは、このKはどういう意味ですか? 一般的な場合、最も近い番号を取得するだけでなく、たとえば、最も近い5つの番号を取得し、その中で最も頻繁に発生する番号を探しています。 4は3倍、2倍は1のようになります。そして、4を取ります。このクラスを増やすと、認識が少し良くなりますが、効率が大幅に低下します。 したがって、1を取り、「Classifier.Learn。 学んでください。」 そして、彼にデータを渡します。 この場合、画像マトリックスと対応する数字のマトリックスを別々に送信する必要があるため、データをカットする必要がありました。 このアコードは、2つの配列が渡されるように配置されています。
次に、それがどのように機能するかを見ることができます。
foreach (var z in test) { var n = classifer.Decide(z.Image.Select(t=>(double)t)).toArray()); WriteLine("{0} => {1}", z.Label, n); if (z.Label == n) correct++; count++; }
これは以前見たものより少し速く動作するようですが、それほど多くはありません。 5,000桁待つと、十分に長くなります。 ただし、同じアルゴリズムを使用したため、認識の精度はまったく変化しません。 しかし、私たちは手動でそれを書いたのではなく、完成した実装を取りました。
なぜこのアプローチは良いのですか? これで、代わりに他の分類子を使用できます。 たとえば、この分類子を削除し、いわゆる分類子サポートベクターマシンを使用します。 これは、異なるクラスのアルゴリズムです。
var svm = new MuliclassSupportVectorLearning<Linear>(); var classifier = svm.Lean( (from x in train select x.Image.Select(z=>(double)z).toArray()).toArray(), (from x in train select x.Label).toArray());
彼らはどのように配置されていますか? 機械学習の観点では、このタスクは分類問題と呼ばれ、オブジェクトがあり、10のクラスのいずれかに割り当てる必要があります。 そして、ここではサポートベクターマシンがこれらのクラスを取ります。 それらが状態空間で何らかのグラフィック形式で提示される場合、それはテキスト、いくつかの多次元ポイントの雲になります。 784の次元を持つ空間内のポイントを想像してください。各ポイントはそれぞれの数字に対応しています。 彼らは何とか分離する必要があります。 サポートベクターマシンアルゴリズムのアイデアは、これらのクラスの要素から可能な限り離れた平面を構築することです。 しかし、省略されたものの垂線に関して分割するのが最善です。 つまり、分類タスクは、最適に分離される平面を構築するタスクです。 この平面に最も近い点から垂線を見て、この距離を最小化すると、サポートベクターマシンは対応する平面を描画します。
2行だけを置き換えました。 実際、アルゴリズムの名前は変更されています。
実行すると、アルゴリズムはしばらく学習します。 ここでの状況は、ある意味では、私たちが見たものの反対です。 前のアルゴリズムがトレーニングされていなかったが、すぐに番号を分類する準備ができていたが、分類プロセスで作業自体が行われたために非常に長い間行った場合、このアルゴリズムが最初にトレーニングされます。 彼はこれらの超平面の係数を選択します。 そして、彼がそれをしている間、一定の時間が経過します。 しかし、彼はすぐに認識し始めます。 非常に高速なので、これらの非常に1000または5000のテストデータがすべて計算される方法を数秒で確認できます。 そして、精度は約91.8%で、やや低いことがわかります。

アコードのメリットは何ですか? さまざまなアルゴリズムがあり、試してみるのは非常に簡単です。コンストラクターを置き換えるだけで、あるアルゴリズムを別のアルゴリズムに置き換えることができ、その動作原理は非常に似ています。 機械学習の課題に直面している場合、これは始めるための良い第2ステップです。 最初のステップは、MicrosoftクラウドでのAzure Machine Learningです。プログラミングは一切必要ありません。 そこで、データを視覚的に簡単に試すことができます。 そして、.NETを知っている人のための2番目のステップはAccord.NETです。

SciPyやScikit-learnのようなあらゆる種類のライブラリがPythonで使用される分野では、.NETの世界の類似物はAccord.NETであることを理解しています。
ニューラルネットワークに移りましょう。

ニューラルネットワークとは何かについて少し話しましょう。 あなたがそれらについて知る必要がある最も重要なことは、近年、多くの人がニューラルネットワークをAI一般の同義語と見なしていることです。 人が「人工知能」と言うと、すぐに頭の中にニューラルネットワークが現れます。 Microsoftのすべての認知サービスはニューラルネットワークに基づいており、魔法のように見えます。 想像してみてください。あなたが彼女に写真を渡すと、彼女は英語で何が描かれているかを説明します。 これをどのように行うことができますか? 私の意見では、これは奇跡です。

しかし、同時に、数学的な観点から、この奇跡は、非常に多次元空間内の特定の点群を最適に近似する関数を構築する方法にすぎないことを理解しています。 つまり、そのような奇妙な状況が判明します。一方で、数学の観点からは、奇妙なことは何も起こりません。 すべてが非常に明確に思えます。 そして他方では、何らかの理由でこれはそのような興味深い問題を解決します。
私は最近、夜もひどく眠り始めました。「そして、私の脳もそうですか? たぶん彼は関数を近似しているだけかもしれませんか?」
すべてが魔法のように見えます。 画像をテキストに変換するなどの深刻なタスクには、非常に大きなコンピューティングリソースが必要であることを理解することが非常に重要です。 これはおそらくクラウドまたは強力なビデオカードのいずれかですが、暗号通貨はすでにすべてを購入しているため、すでに利用できなくなっています。 そして、これも悲しいです。 しかし、車はクラウドに残りました。

ニューラルネットワークはどのように配置されていますか? ニューラルネットワークは、ある意味で、建築における人間の脳に似ています。 人間の脳には、互いに接続されたニューロンがあり、学習プロセスにおけるこれらの接続は、伝導率、重みを変化させます。 したがって、ソフトウェアの観点から、特定の数の入力があり、それぞれが何らかの種類の数値を持つ可能性がある設計を取得します。 次に、いくつかの中間層があります。たとえば、入力からこの前の層から信号を取得し、特定の重み係数で要約します。 ここで特定の数値を取得し、次の入力レイヤーから集計すると、結果として何らかの出力が得られます。
たとえば、猫や犬の写真の認識問題の場合。 エントランスに何を提出しますか? 入り口で写真を提出します。 各入力は写真の別々のピクセルになり、猫または犬の2つの出力があります。 そして、中央に一定数のレイヤーがあります。
そして、何をする必要がありますか? このニューラルネットワークがエントリの正しい出口を提供するように重みを調整します。 最初に画像を指定した場合、出力に乱数が表示されることは明らかです。 そこに係数がランダムだった場合、それはいくつかの数を与えます。 そして、「いいえ、猫のように見えるように重みを調整しましょう」と言います。 このために、いくつかのアルゴリズムを使用します。
エラーの逆伝播のためのアルゴリズムがあり、重みを調整できます。 次に、次の例を示します-重みを再度調整します。 そのため、非常に多くの例に対して何度も何度も行います。 数学の観点から、ここでは非常に単純なことが起こります。 この層のこの出力層がベクトルであると想像した場合、実際には、この入力ベクトルxに何らかの行列を乗算し、他のシフトを追加して、これに非線形関数を適用します。 実際、各レイヤーに対して、ベクトルによるマトリックス乗算を行います。 すべてが非常に簡単です。
しかし、なぜ非線形関数を使用するのでしょうか? 特定の範囲の数値を取得することもあります。 しかし、非常にキラーな議論があります。 そうでない場合、すべて行列の積のように見え、行列の積は任意の1つの行列に相当します。 入力ベクトルを取得する場合、1つの行列を乗算し、次に別の行列を乗算します。2つの行列を単純に乗算し、この行列の積で数値を指定します。 したがって、非線形関数を追加していなければ、レイヤーの数は影響を受けず、すべてが1つのレイヤーのようになります。 そして、非線形性の追加により、それは連続した拡張のようになります。 そして、これが級数展開の場合、任意の関数を近似できます。 これが当てはまらない場合は、凸線形多様体のみを近似できます。 したがって、非線形関数を追加することが非常に重要です。 さらに、非線形関数も異なります。
以前は、「シグモイド」と呼ばれるこのような美しい非線形関数を作成することが慣習でしたが、現在では線形関数の形で非線形関数を作成することが流行になってきています。 それは半分線形です:それは0より大きい線形であり、0より小さい線形は0です。なぜですか? 実装に効果的だからです。 その派生物は簡単であると考えられますが、それは悪い派生物です。 ただし、このような機能はよく使用されます。

ニューラルネットワークを実装するにはどうすればよいですか? 手動でプログラムすることもできますが、このタスクはそれほど難しくはありませんが、あまり快適ではありません。 さらに重要なのは、GPUでこれをすべて訓練したいので、うまくやれば、鉄の行列のグラフィック乗算を学習する必要があります-これはすべて難しくなります。
したがって、通常、既成のフレームワークを使用します。 GoogleのTensorFlowがあります。これは主要な競合であり、誰もが主に使用しています。 他にもいくつかあります。

アコードにはニューラルネットワークもあります。このアルゴリズムを使用して変更するだけで、ここでニューラルネットワークを取得できます。 すべてが少し異なります。
var nn = new ActivationNetwork(new SigmoidFunction(0.1), 784, 10); var learn = new BackPropagationLearning(nn); nn.Randomize(); WriteLine("StartingLearning"); for (int ep=0; ep<50, ep++) { var err = learn.RunEpoch((from x in train select x.Image.Select(t=>(double)t/256.0).toArray(), (from x in train select x.Label.ToOneHot10(10).ToDoubleArray()).toArray() ) WriteLine($"Epoch={ep}, Error={err}"); } int count=0, correct=0; foreach (var v in test) { var n = nn.Compute(v.Image.Select(t=>(double)t/256.0).toArray()); var z = n.MaxIndex(); WriteLine("{0} => {1}"), z, v.Label); if (z == v.Label) correct++; count++; } WriteLine("Done, {0} of {1} correct ({2}%)", correct, count, (double)count * 100);
ニューラルネットワークにはこのような問題があります。それを行うと、さまざまなトレーニングパラメーターがあるため、常にうまく機能するとは限りません。 この場合、これはまさにこのアクティベーション関数の幅です。 0から1にしたのはあまり良くありません。-1から1にしたほうが負のゾーンにある方が良いでしょう。 たとえば、関数が線形ではなく、半線形である場合、負のゾーンにあることが重要です。 微妙な違いがあります。 そして、最初の試みは常に成功するとは限りません。
トレーニングの各段階で、残っている間違いを印刷します。 出口を必要なものに近づけますが、同時に何らかの間違いが依然として存在し、学習プロセスは常に減少します。 しかし、時々それは増加し始めます-これはおそらく、何かが間違っていたという確かな兆候であり、すでにトレーニングを停止する価値があります。 また、再トレーニングの問題もあります。ネットワークが再トレーニングされると、予測が悪化し始めます。
たとえば、上記のコードのテストを実行すると、88.3%が得られます。 これはあまり良くありませんが、それほど悪くはありません。
しかし、ニューラルネットワークは以前よりもはるかに優れていることがわかります。
しかし、ニューラルネットワークはAccordで教えることができますが、必要ではありません。より優れた専用のフレームワークがあるためです。
Microsoft Cognitive Toolkit、なぜそれが美しいのですか? GPU、GPUコンピューターのクラスターで使用できます-あらゆるケースで。 さらに、オープンソースであり、迅速かつ積極的に開発されています。 たとえば、9月まで、.NETでのニューラルネットワークのトレーニングは許可されていませんでしたが、現在は許可されています。

最初は、2つのトレーニングモードがありました。ネットワークアーキテクチャをBrainScriptと呼ばれる特別な言語で記述し、ソースデータとこのスクリプトをコマンドラインでユーティリティに送り、「ニューラルネットワークを教えてください」と言うことができました。 これはすべてコマンドラインで行われ、モデルファイルが書き込まれました。これは、C#、Pythonなどのプロジェクトから取得して使用できます。
しかし、その後、まるでファッションの指示に従うかのように、彼らは学習プロセスをPythonに移しました。 実際、これはそれほど悪くはありません。すべてがより柔軟になり、ネットワークの異なる芸術的なアーキテクチャを作成でき、新しい言語のBrainScriptを学ぶ必要がないからです。 しかし、2017年9月までは、CNTKを使用する主なモードは次のとおりでした。Pythonで教えますが、.NETで使用できます。
しかし、何らかのプロジェクトを行って結果を顧客に見せたいときは常に、ニューラルネットワークをボットでラップします。 次に、写真を撮影すると、ネットワークが結果を生成します。 ボットはC#で記述されており、ニューラルネットワーク計算を簡単に統合でき、トレーニングは常にPythonとクラウド内の仮想マシンで行われています。

クラウドを試してみたい場合は、クラウドにData Science Virtual Machineと呼ばれる既製のマシンがあります。 作成すると、主にPythonで必要なソフトウェアがすべてインストールされているマシンがわかります。

少し繰り返します。以前、トレーニングのメインモードはこれでした。BrainScriptまたはPythonを使用してニューラルネットワークをトレーニングし、ファイルを取得してから.NETから使用します。 そして、これはすべてC ++ライブラリの上で動作します。 それと、別の両方:トレーニングと計算の両方。
9月に、トレーニングをサポートするために特別なAPIが追加されました。 なぜこれが可能ですか? 競合他社がまだないのはなぜですか?
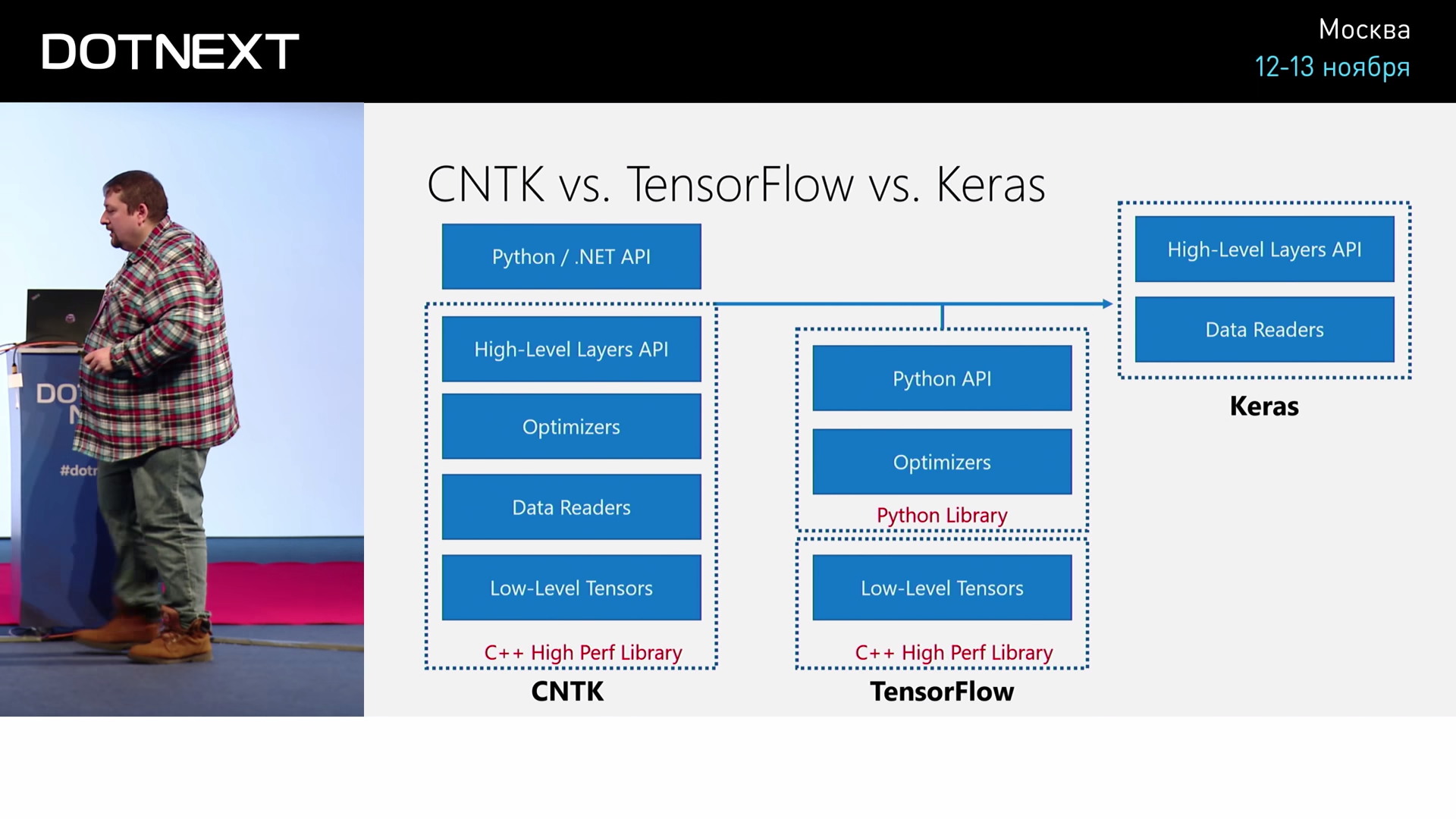
CNTKの仕組みを見ると、このようなライブラリには何が含まれていますか?テンソルと呼ばれるこれらの行列を扱うには、特定の低レベルがあります。これは、非常に多次元の行列を扱うことが多いためです。配列は3次元、4次元、多次元なので、テンソルもそうです。しかし、異なるスライスを取るためにテンソルだけを乗算する必要がある場合が多いため、これを行うことができる特別なライブラリが必要です。
CNTK , - . , : . , , , , , . - . , : , -, , , - . , transformations, - .
CNTK. — , . , , , . , , , , , . .
CNTK API , . , , : « - , -, - ». Layers API.
CNTK, C++, API Python .NET.
? TensorFlow. TensorFlow C++, , , . Python. , , , . TensorFlow .NET. , TensorFlow C#, .
Keras. TensorFlow, , , Keras , CNTK Layer API. .
Keras , CNTK . Keras, CNTK TensorFlow, - .

, CNTK .
, . ? , float, 256 — , 0 1.
#r "SciSharp.dll" using SciSharp; using static System.Console; class Digit { public float[] Image; public int Label; } var fn = @"train.csv"; var f = File.ReadLines(fn); var data = from z in f.Skip(1) let zz = z.Split(',').Select(int.Parse) select new Digit { Label = zz.First(), Image = zz.Skip(1).Select(x=>x/256f).toArray(); }; var train = data.Take(10000).toArray(); var test = data.Skip(10000).Take(1000).toArray();
, CNTK? .
DeviceDescriptor device = DeviceDescriptor.CPUDevice; int inputDim = 784; int outputDim = 10; var inputShape = new NDShape(1, inputDim); var outputShape = new NDShape(1, outputDim);
-, , CPU. , 784 — 28 28, — 10, 10 . Shape. Shape — . NDShape . .
Variable features = Variable.InputVariable(inputShape, DataType.Float); Variable label = Variable.InputVariable(outputShape, DataType.Float); var W = new Parameter(new int[] { outputDim, inputDim }, DataType.Float, 1, device, "w"} ); var b = new Parameter(new int[] { outputDim }, DataType.Float, 1, device, "b"} ) var z = CNTKLib.Times(W, features) + b;
? . ? , , . , Variables, . variable, features — , 768, , lable, 10. . . , , , , .
, — W — 10 768. 10, outputDim. . , , — Z, W + b. . それだけです
: « , - , , ».
var loss = CNTLib.CrossEntropyWithSoftmax(z, label); var evalError = CNTKLib.ClassificationError(z, label);
, CrossEntropyWithSoftmax, , . .
, . ). Learner, Trainer. Trainer , Learner, 60 : «Trainer.Train».
.

: ? , , , , . Python? 同じように。 Python - , . Python, C# — .

. ? . ? 1500, - . , . , . 94% .

. , , , ? — ? , .

, « ». ? , . , , . , , . . , , , , . . , , . , 98%.

- .

, . Convolution. 28 28 1 — 28 28 — 14 14 4. 4 , - , , , . , 14 14 4 7 7 8. .

- . , 5 . : « , , , ?» : « , 20 , ». , . , : « ! - !» , , .
, , , , . , , . , , , , 500-1500 , . , , , , , — . , , . , .
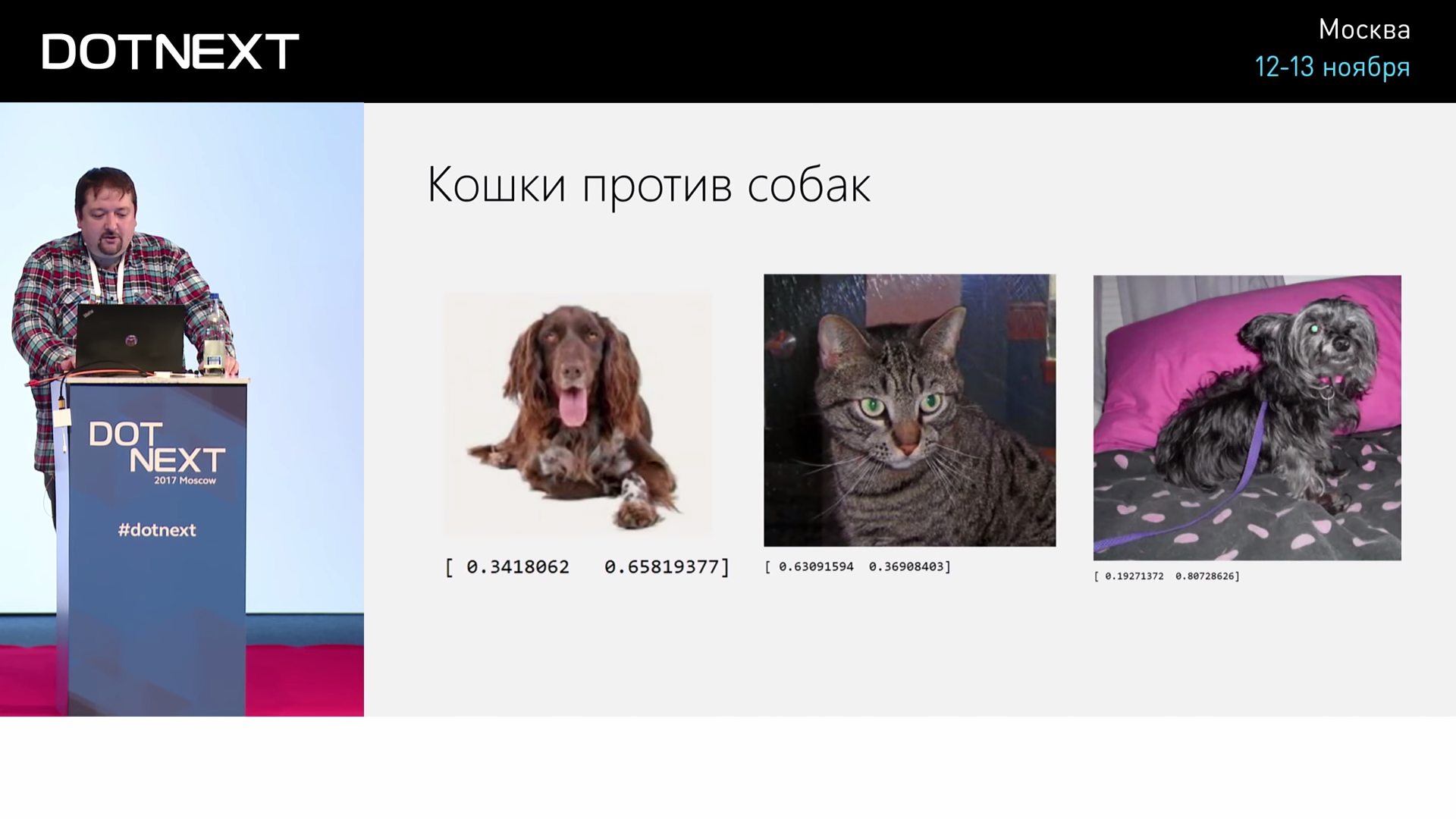
C#, , ( Python), — 6 . 3 , 5 5 — 32 32 . . 3 3 .
Python , , 50, 75. , , , . 0,8 , 0,4 , 0,65 . , 3-4 , .
?
:
F# API CNTK:
, , . , . — , . 4, -, 6. , Notebook' Python , . . , Coursera - .
— , , - . CNTK, , , F#. C# , F#. . , . GitHub , . , , , — 2017 C#, , , .

, , . ? .NET , . , Azure Notebooks, C# Interactive, Xamarin Workbooks — , , . , Microsoft — CNTK, C#, , . , 10-15 , .
広告の分。 おそらくご存知のように、会議を行っています。 .NET — DotNext 2018 Piter . 22-23 2018 -. — YouTube . .NET . 要するに、私たちはあなたを待っています。