 コンピュータの能力の発達と多くの画像処理技術の出現により、質問がますます頻繁に発生しました。画像を見て認識できるように機械を教えることは可能ですか? たとえば、猫と犬、またはブラッドハウンドとバセットを区別するには? 認識の正確さについて話す必要はありません。前もって物体に関する十分な情報を受け取っていれば、脳は目の前にあるものを比類なく速く理解できます。 つまり 犬の一部しか見ていなくても、犬だと自信を持って言えます。 そして、あなたが犬のブリーダーであるなら、あなたは簡単に犬の品種を決定することができます。 しかし、それらを区別するために車を教える方法は? どんなアルゴリズムがありますか? 車をだますことは可能ですか? (ネタバレ:もちろんできます!私たちの脳のように。)これらすべての質問を理解し、可能であれば答えてみましょう。 それでは始めましょう。
コンピュータの能力の発達と多くの画像処理技術の出現により、質問がますます頻繁に発生しました。画像を見て認識できるように機械を教えることは可能ですか? たとえば、猫と犬、またはブラッドハウンドとバセットを区別するには? 認識の正確さについて話す必要はありません。前もって物体に関する十分な情報を受け取っていれば、脳は目の前にあるものを比類なく速く理解できます。 つまり 犬の一部しか見ていなくても、犬だと自信を持って言えます。 そして、あなたが犬のブリーダーであるなら、あなたは簡単に犬の品種を決定することができます。 しかし、それらを区別するために車を教える方法は? どんなアルゴリズムがありますか? 車をだますことは可能ですか? (ネタバレ:もちろんできます!私たちの脳のように。)これらすべての質問を理解し、可能であれば答えてみましょう。 それでは始めましょう。
車に見方を教える方法は?
マシンビジョンとは、セマンティックアナライザー、サウンドレコグナイザーなどを含む機械学習を指します。 これは複雑な主題分野であり、数学(brrrrr、テンソル数学を含む)の深い知識が必要です。 パターン認識で使用される多くのアルゴリズムがあります:VGG16、VGG32、VGG29、ResNet、DenseNet、Inception(V1、V2、V3、V ...それらは何百もあります!)。 最も人気があるのはVGG16とInception V3およびV4です。 最も簡単で、最も人気があり、クイックスタートに最適なのはVGG16であるため、選択して選択します。 VGG16という名前から始めて、その中の神聖なものとそれがどのように解読されるかを調べましょう。 そして、K.O。 VGGはオックスフォード大学工学部のビジュアルジオメトリグループです。 さて、どこから16? ここではもう少し複雑で、アルゴリズムに直接関係しています。 16-ニューラルネットワークの層数。パターン認識に使用されます(やっと興味深い層を開始しました。 そして、マタンの本質に立ち入る時です。 それら自体は、ニューラルネットワークの各レベルで16から19のレイヤーと3x3フィルターを使用します。 実際には、いくつかの理由があります:最大のパフォーマンスは、このような数のレイヤー、認識精度(これで十分です、記事へのリンク、 1回または2回 )です。 ニューラルネットワークは単純なものではなく、改良された畳み込みニューラルネットワーク(畳み込みニューラルネットワーク(CNN)および洗練された畳み込みニューラルネットワーク(CNN-R))を使用していることに注意してください。
そして、このアルゴリズムの動作原理、畳み込みニューラルネットワークが必要な理由、およびそれが機能するパラメーターを理解します。 もちろん、実際にはすぐに行う方が良いでしょう。 スタジオのアシスタント!

この素晴らしいハスキーは私たちのアシスタントになり、彼女と一緒に実験します。 彼女はすでに幸福に輝いており、すぐに詳細を知りたいと思っています。
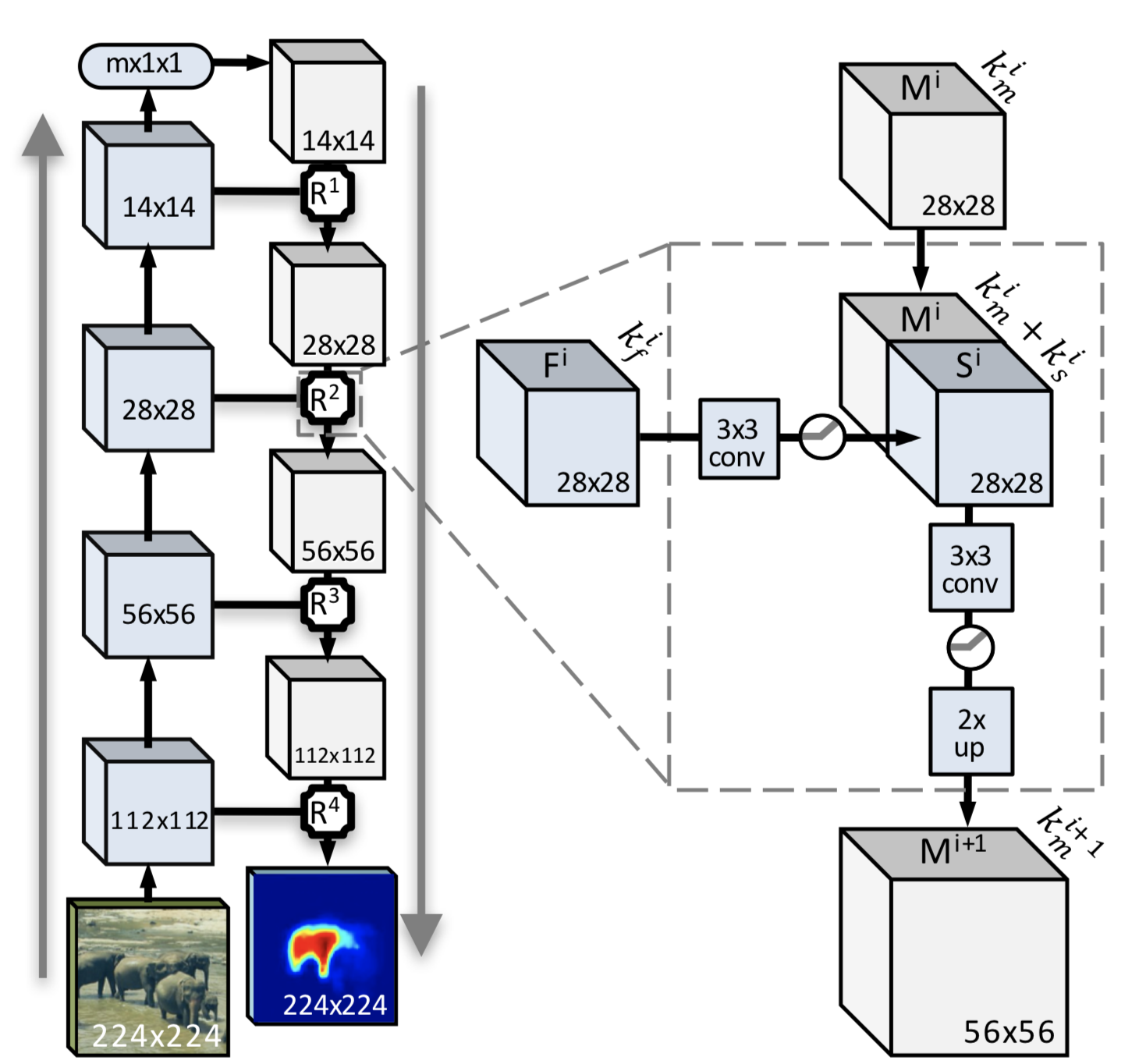
つまり、簡単な言葉で言えば、畳み込みニューラルネットワークは2つの「コマンド」で動作します(誇張しますが、より明確になります)。 最初-フラグメントを選択し、2番目-オブジェクト全体を見つけようとします。 なぜ全部なのか? オブジェクト全体の輪郭を持つ最小パターンのセットを使用すると、ニューラルネットワークが将来的に特徴を取得し、認識される必要がある画像と比較することが容易になります。 そしてここで、最終形式のアルゴリズムのイメージが役立ちます。 誰がマタンをたくさん使って詳細に勉強したいのか-これがpruflinkです。 そして先に進みます。
次のアルゴリズムの説明はそれほど難しくありません。 これは、改善モジュールを備えた完全な畳み込みニューラルネットワークアルゴリズムです(これは点線で囲まれ、各畳み込みステップの後に存在するものです)。
最初のステップ:画像を半分に切断します(ハスキーを行いますが、写真の象ほど壮観ではありません)。 それから半分になり、さらにどんどん増えて、ブロック14x14以下の意味でゴキブリに到達します(すでに述べたように、最小サイズは3x3です)。 ステップの間が主な魔法です。 すなわち、対象物全体のマスクと、のこぎり部分で対象物全体を見つける確率を取得します。 これらすべての操作の後、ピースのセットとそれらのマスクのセットを取得します。 今、それらをどうしますか? 答えは簡単です。画像を縮小すると、隣接するピクセルが劣化します。これにより、マスクの構成が簡素化され、オブジェクト間の遷移を区別する可能性が高くなります。
独立したソース記述は、サムネイルの分析に基づいて構築され、すべてのマスクの結果が平均化されます。 ただし、オブジェクトをセグメント化する場合、このオプションは最適ではないことに注意してください。 平均化されたマスクは、オブジェクトと背景のわずかな色の違いに常に適用できるとは限りません(そのため、このようなテスト画像が選択されました)。
提案されたアプローチは多かれ少なかれ実行可能ですが、完全に画像上にあり、背景と対照的なオブジェクトに対して、同時に、2つの同一または類似のオブジェクトの分離(例:羊の群れ、誰もが白い羊毛)は大きな困難を引き起こします。
適切なピクセルマスクと個別のオブジェクトを取得するには、アルゴリズムを念頭に置く必要があります。
そして今、質問する時が来ました。すべてが問題ないように思えるのに、なぜこの「モジュールエンハンサー」が必要なのでしょうか。
各ステップで、マスクの構築だけでなく、低レベル関数から得られたすべての情報と、ニューラルネットワークの上位層で認識される高レベルオブジェクトに関する知識の使用も追加します。 独立した結果の取得に加えて、生成と粗認識が各ステップで実行され、結果は意味的に完全な機能的マルチチャネルマップになり、初期層からの肯定的な情報のみが統合されます。
従来の畳み込みニューラルネットワークと改良された畳み込みニューラルネットワークの違いは何ですか?
元の画像を縮小する各ステップでは、一般的な画像から縮小画像に渡すときに、エンコードされたマスクを生成できます。 これに加えて、高度な畳み込みニューラルネットワークでは、特徴的な関数(ポイント)を受け取ると、小さな画像から大きな画像に移動します。 結果は、関数と特性ポイントの双方向のマージの結果として得られるマスクです。
かなり紛らわしいですね。 画像に適用してみましょう。

壮観です。 これは、DeepMask-イメージ内のオブジェクトの大まかな境界線と呼ばれます。 理由を理解してみましょう。 簡単なことから始めましょう-鼻で。 画像の劣化により、コントラストが明確になるため、鼻が独立したオブジェクトとして強調表示されます。 同じことが鼻孔でも起こります。畳み込みの特定のレベルで、それらは完全に断片上にあるという事実のために独立したオブジェクトになりました。 さらに、2匹目の犬の銃口は個別に丸で囲まれています(どうして見えないのですか?はい、ここにあります!)。 手のひらが背景として認識されました。 さて、何をすべきか? 背景の主要部分では、色は対照的ではありません。 しかし、移行「アームシャツ」が強調表示されます。 そして、「ハンドネット」スポットと、背景とハスキーの頭を捉える大きなスポットという形のエラー。
さて、結果は面白いです! アルゴリズムがタスクによりよく対処するのをどのように支援できますか? あなたが私たちのアシスタントをm笑する場合のみ。 まず、グレースケールで作成してみてください。 うーん...写真はパスポートよりも悪いです。 その後、実験助手は何も失うことなく、1つのフィルターをオンにしただけで、すべてが反転しました...セピア、続いてソラリゼーション、レイヤーの重ね合わせと減算、画像の追加で背景をぼかします-一般に、私はそれを見て、それを適用しました; 主なものは、オブジェクトが画像内でより見やすくなることです。 彼らが言うように、Photoshopの画像はすべてに耐えます。 馬鹿げた、今度は画像がどのように認識されるかを見てみましょう。

ニューラルネットワークは、「少なくともなんとか分類できる人はいない」と述べました。 論理的には、鼻と目だけが対照的です。 トレーニング用の小さなセットではあまり特徴的ではありません。

うわー、なんて恐ろしい(ごめん、友達)! しかし、ここでは画像内のオブジェクトに真剣にコントラストを追加しました。 どうやって? 画像を取得して複製します(数回できます)。 一方ではコントラストをひねり、他方では-明るさ、三番目に-色を燃やし(不自然に明るくし)、それをすべて足し合わせます。 そして最後に、辛抱強いハスキーを処理に詰め込みましょう。

私はそれが良くなったと言わなければなりません。 まっすぐに「すごい、どれだけクール」ではなく、より良い。 不完全なオブジェクトの数が減少し、オブジェクト間のコントラストが現れました。 前処理のさらなる実験では、オブジェクト-オブジェクト、オブジェクト-背景のコントラストが大きくなります。 8つのセグメントではなく4つのセグメントを取得します。大量の画像ストリーム(1分あたり150画像)を処理するという観点からは、前処理をまったく行わない方がよいでしょう。 彼女-だから、自宅のコンピューターで遊ぶ。
続けましょう。 SharpMaskは実質的に違いはありません。 SharpMaskは、オブジェクトの洗練されたマスクを構築しています。 改善アルゴリズムは同じです。
DeepMaskの主な問題は、このモデルが「粗い」マスクを正常に作成する単純な直接分配ネットワークを使用するが、ピクセルセグメンテーションを実行しないことです。 ハスキーの生活はそれほど簡単ではないため、このステップの例をスキップします。
最後のステップは、マスクを明確にした後に何が起こったかを認識する試みです。

迅速に組み立てられたデモを起動し、結果を取得します-これは70%が犬であることを示しています。 悪くない。
しかし、マシンはそれが犬であることをどのように理解しましたか? それで、私たちはピースを挽き、美しいマスク、それらへのマトリックス、そしてサインのセットを得ました。 次は? そして、すべてが簡単です。機能、マスクなどの参照セットなどを備えた訓練されたネットワークがあります。 さて、彼らは、そして次は何ですか? ここに、一連の機能を備えたハスキーがあります。ここに、一連の機能を備えた真空中の基準球面犬があります。 率直な比較は額に行うことができません。なぜなら、画像に特徴が欠けていると認識されるとエラーが発生するからです。 そして何をすべきか? これを行うために、彼らはドロップアウトのような素晴らしいパラメーター、またはネットワークパラメーターのランダムなリセットを思いつきました。 これは次のことを意味します:両方のセットが取得され、それぞれから符号がランダムに削除されます(つまり、10個の符号のセットがあり、ドロップアウト=0.1。1つの符号に従ってそれらをドロップし、比較します)。 結果として? そしてその結果-利益。
2番目の犬が犬ではなく、手が男ではない理由の質問にすぐに答えます。 テストサンプルは、猫と犬の1000枚の画像のみでした。 彼女は進化のたった2つのステップで勉強しました。
結論の代わりに
それで、私たちは写真と、それが犬であるという結果を得ました(私たちには明らかですが、ニューラルネットワークにとってはあまり良くありませんでした)。 トレーニングはわずか2ステップで実行され、モデルの進化はありませんでした(これは非常に重要です)。 画像はそのまま処理されずにロードされました。 将来的には、ニューラルネットワークが最小の兆候セットで犬を認識できるかどうかを確認する予定です。
プロから:
- 1台のマシンでトレーニングを実施しました。 必要に応じて、ファイルを他のマシンにすぐに分散させることができ、それら(マシン)はすでに同じことを行うことができます。
- トレーニング中およびネットワークの進化中の決定の高精度(これはすっごく長いです)。
- さまざまな認識アルゴリズムに進化して、ネットワークを「再トレーニング」できます。
- 画像COCOおよびVOCの巨大なデータベース(毎年更新)。
マイナス面:各フレームワークでタンバリンと踊る。
PS実験中、ハスキーに害はありませんでした。 彼らがどのように収集したか、何を収集したか、どのくらいの熊手、どの場所に行くかなどについて-シリーズの次の記事「主婦向けのマシンビジョン」で。
PPSそして、非常に要約すると、銀の弾丸は存在しませんが、ファイルに変換できるファウストカートリッジがあります。 また、クイックスタートのために、次のフレームワークが使用されました。
ケラス
カフェ
テンソルフロー