
ユーザーの興味(内部名-Hydra )に基づいてコンテンツを選択するiviの推奨システムについては、 こことここに書いてい ます 。 多くの時間が経過し、プロジェクトコードが大幅に変更されました:オフラインパーツはSparkに移動し、オンラインパーツは高負荷に適応し、Hydraは異なる推奨モデルの使用を開始しました-これらの変更はすべて記事で強調表示されます。
ヒドラアーキテクチャ
2014年に、HydraはPythonアプリケーションの形式で作成されました。推奨モデルのデータは、外部ソース(Vertica、Mongo、Postgres)から別のスクリプト(「オフラインパーツ」)にロードされました。 スクリプトは、次元のユーザー項目マトリックスを準備しました ここで、mはトレーニングサンプルのユーザー数、nはカタログサイズ(一意のコンテンツユニットの数)です。アイテムベースの個人的な推奨事項の詳細については、 Sergei Nikolenkoの記事を参照してください 。
ユーザーの履歴は次元ベクトルです 、ユーザーが操作した各コンテンツ(見た、評価した)にはユニットがあり、残りの要素はゼロです。 各ユーザーは数十単位のコンテンツと対話し、カタログサイズは数千単位であるため、スパース行ベクトルが得られます。このベクトルには多くのゼロがあり、ユーザーアイテムマトリックスはそのようなベクトルで構成されます。 iviオンラインシネマは、ユーザーから豊富なフィードバックを収集します-コンテンツビュー、評価(10ポイントスケール)、オンボーディング結果(嫌いなバイナリ設定、こちらはNetflixの例のプレゼンテーションです)-モデルはこのデータでトレーニングされます。
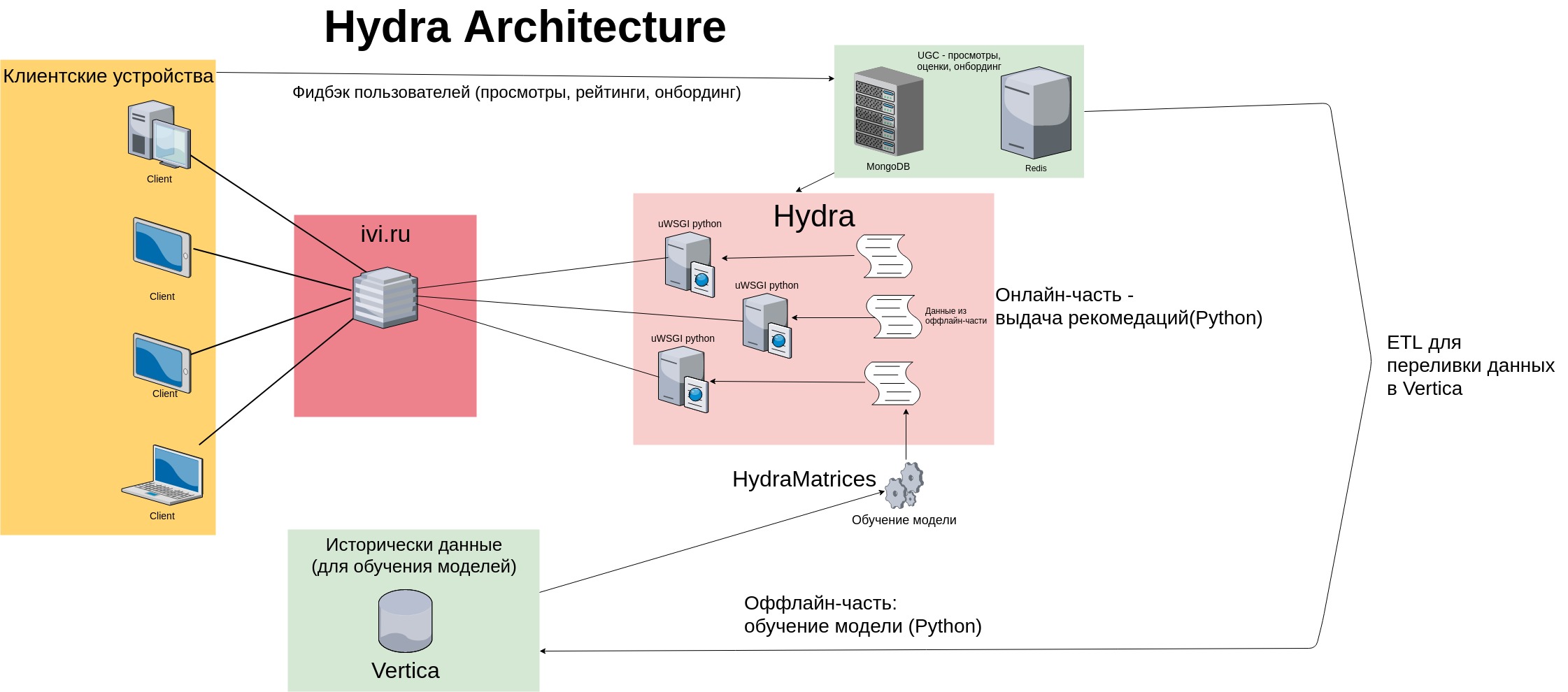
推奨事項を発行するために、古典的なメモリベースのアルゴリズムが使用されました-Hydraはトレーニングセットを「記憶」し、ユーザービュー(および評価)のマトリックスをメモリに保存しました。 サービスの対象者が増加するにつれて、ユーザー項目マトリックスのサイズも比例して増加しました。 当時の推奨サービスのアーキテクチャは次のとおりでした。
ヒドラの欠点
図からわかるように、ユーザーフィードバック(ビュー、コンテンツレーティング、オンボーディングマーク)は、高速なキーと値のストア(MongoDBとRedis)およびVertica-列データストレージに保存されます。 データは、特別なETL手順を使用して段階的に注入されます。
オフラインパーツはクラウンによって毎日起動されます。データをダウンロードし、モデルをトレーニングし、テキストファイルとバイナリファイル(スパースマトリックス、.pkl形式のpythonオブジェクト)として保存します。 オンラインパーツは、対象ユーザーアクションのモデルと履歴に基づいて、ビュー、評価、コンテンツ購入(Redis / Mongoからのユーザーフィードバックを読みます)に基づいた推奨事項の発行を形成します。 推奨事項は、各サーバーで実行されている多数のpythonプロセスを使用して発行されます(Hydraクラスターには合計8つのサーバーがあります)。
このアーキテクチャはいくつかの問題を引き起こしました:
- Hydraはpythonプロセスのバンドルであり、それぞれが独自のファイルセットをオフライン部分からメモリに持ち上げます-これは、メモリ消費が時間とともに増加するという事実につながり(ファイルサイズはユーザー数とともに増加します)、システムのスケーリングを複雑にします。 さらに、サービスの開始時に、各プロセスはディスクからファイルを読み取る必要があります-これは遅いです。
- より多くのユーザーが存在するため、データ収集には多くの時間がかかり始めています。
- Hydraはモノリシックアプリケーションでした。データの準備はますます複雑になり、残りのiviマイクロサービスをあまり活用しませんでした。そのため、さまざまな補助スクリプトを開発する必要がありました。
ヒドラ:復活
この形式のシステム(継続的な改善と改善を伴う)は、2017年2月まで存続しました。 オフライン部分でデータをダウンロードする時間は、アルゴリズムモデルが変更されないままになりました。 2017年の初めに、メモリベースの推奨モデルから最新のALSアルゴリズムに移行することを決定しました( このモデルに関するCourseraのビデオがあります)。
要するに-アルゴリズムは私たちの巨大なまばらなユーザーアイテム行列を提示しようとしています ユーザー行列とコンテンツ行列の2つの「密」行列の積の形で:
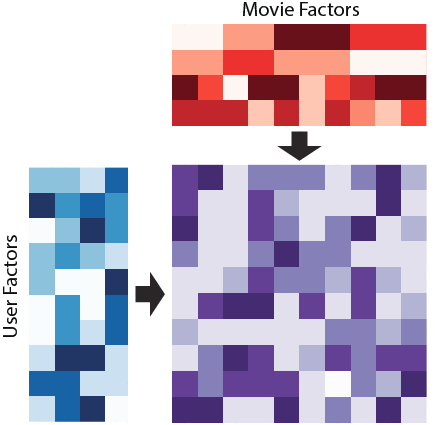
ALSを使用すると、すべてのユーザーのトレーニングができます ベクトル 寸法 -いわゆる ユーザーの「隠れた要因」。 コンテンツの各ユニット 一致するベクトル 同じ次元、コンテンツの「隠された要因」。 同時に 、隠された要因の空間の次元はカタログのサイズよりもはるかに小さく、各ユーザーは低次元の密なベクトルで記述されます(通常は )
ユーザーのベクターとコンテンツベクターの積は、ユーザーとコンテンツの関連性です。値が高いほど、映画がショーに参加する可能性が高くなります。 推奨システムには、「ユーザーが好きなコンテンツを表示する」タスクに加えて、コンテンツの収益化、サービスの配置などに関連する多くのタスクがあるため、ビジネスルールの肉挽き器でALSの排気は削られます。 ビジネスルールは、推奨事項のベクトルをわずかにゆがめます。たとえば、モデルのオフライン評価を行う場合、この事実を考慮する必要があります。
新しいアーキテクチャ
サービスを再設計するために多くの作業が行われましたが、その結果は次のとおりです。

- モデルトレーニングのデータ準備はSparkに移動しました。Verticaにアクセスする代わりに、Hive Hadoopリポジトリから読み取ります。 Verticaは非常に高速なデータベースですが、データ量の増加に伴い、ネットワークを介してデータを転送するのに時間がかかり、Sparkではクラスターノードに分散された計算を実行できます。 さらに、Sparkは暗黙的なフィードバックのためにALSモデルを実装します(モデルは、ユーザーがコンテンツを視聴している期間のデータでトレーニングされます)。
- メモリに保存するために各プロセスが使用したオフライン部分からのデータがRedisに移動しました。 現在、メモリ内のオブジェクトを複製する代わりに、HydraはRedisリポジトリを使用します。サーバー上のすべてのプロセスのデータのコピーを1つ取得し、メモリ消費を2倍削減しました。 サービスを再起動する時間は半時間から6分に短縮されました-数十のプロセスがファイルからデータを長時間読み取るまで待機します。再起動時にHydraが可用性を確認するだけで、データはすでにRedisにあります
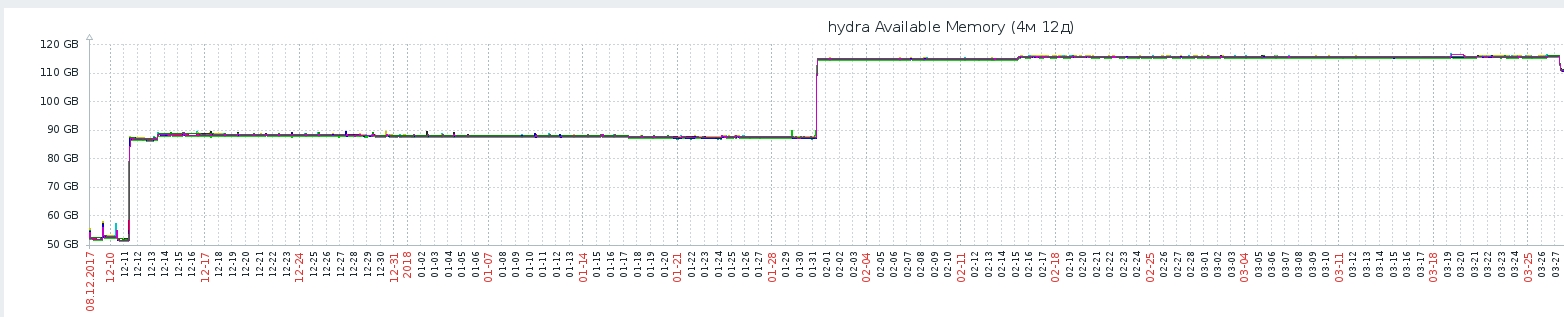
- Hydraは、各ユーザーのアプリケーション画面間の移行に応じて、推奨事項を変更する可能性のあるターゲットアクションをユーザーが実行しなかった場合でも(コンテンツを見て、評価した場合)、推奨事項を再集計しました。 膨大な計算を行うことは、プロセッサリソースの点で非常に高価であることが判明しました。 ALSモデルの推奨事項を取得する方法の深さでは、numpyから小さな線形代数(たとえばnumpy.linalg.solve )を使用しますが、各pythonプロセスはいくつかのコアを使用して高速にカウントします-これによりCPUが非常にロードされます。 図からわかるように、ALSテストモデルの導入後、システムの応答時間は毎日増加しました(これは、新しいモデルのABテストが新しいユーザーを獲得したためです)。 ユーザー数への負荷の線形依存を回避するために、推奨ベクトルのキャッシュシステムが開発されました。キャッシュは、ユーザーの新しい「ターゲットアクション」:表示または評価後にのみ破棄されました(および推奨が再カウントされました)。

- ユーザーの推奨事項のベクトルを形成するために、彼らはハイブリッドモデルを使用し始めました。 以前は、レコメンダーシステムのビジネスルール(および多くのビジネスルールがあります)では、いわゆる 「パーソナライゼーションの境界線」:ユーザーの表示回数が5回未満の場合、推奨事項は人気のあるコンテンツのトップになり、5回目の表示後、ユーザーは個人的な推奨事項の受信を開始しました。 推奨事項を作成するとき、新しいモデルは、現時点でサービスで人気のあるものに関する情報とユーザーの個人的な推奨事項を組み合わせます:ユーザーからより多くのフィードバックが蓄積されるほど、トップで人気が低く、より個人的なものになります-ユーザーは最初の表示しています。
- この図は、Hiveのすぐにクライアントアプリケーションからの矢印を示しています。これは、 grootイベント分析システムからのデータであり、(ユーザークリック、クライアントアプリケーションの現地時間)Hydraがより積極的に使用し始めたデータです。たとえば、同じユーザーの場合、コンテキストに適合した推奨事項のベクトル-たとえば、視聴時間(朝または夕方、平日または週末)。
- 以前は、オフライン部分の結果は、サービスの再起動時に各Hydraプロセスがメモリに生成した一連のファイルでした。 これで、データはオフラインファイルからRedisに直接到達し、中間ファイルをバイパスします。 このスキームにより、サービスの再起動が大幅に加速されます。ディスクから何かを読み取る必要はありません。データはすでにメモリ内にあり、すぐに使用できます。
おわりに
Hydraは、アーキテクチャとアルゴリズムの両方の面で、1年で大きく変化しました。 これらの変更の詳細については、一連の記事で説明します。