前文
私はコンサルティング会社でWeb開発者として働いていますが、あるプロジェクトが既に終了し、次のプロジェクトがまだ指名されていない場合があります。 ただ座っているだけでなく、ベンチにいる全員が会社の知的財産に貢献しなければなりません。 原則として、これは、著者が所有するトピックに関するトレーニング資料の作成、または新しいテクノロジーの研究と、その週の終わりの後続のデモンストレーションまたはプレゼンテーションのいずれかです。
そのような機会があれば、機械学習のトピックに触れてみることにしました。なぜなら、それはスタイリッシュでファッショナブルで若者だからです。 このトピックの以前の知識から、私は一流の開発者からのプレゼンテーションをほんの2、3しか持っていませんでした。
機械学習を使用して解決する特定の問題を特定し、掘り始めました。 究極の目標を設定することは、情報の流れの中でナビゲートする方が簡単だったことに注意してください。
そのような機会があれば、機械学習のトピックに触れてみることにしました。なぜなら、それはスタイリッシュでファッショナブルで若者だからです。 このトピックの以前の知識から、私は一流の開発者からのプレゼンテーションをほんの2、3しか持っていませんでした。
機械学習を使用して解決する特定の問題を特定し、掘り始めました。 究極の目標を設定することは、情報の流れの中でナビゲートする方が簡単だったことに注意してください。
シャベルを付ける
まず、公式のTensorFlow Webサイトにアクセスし、初心者向けの MLと初心者 向けのTensorFlowを読みました 。 英語の資料。
TensorFlowは、Googleチームの成果であり、Python、Java、C ++、Goをサポートする最も一般的な機械学習ライブラリであり、グラフィックカードの計算能力を使用して複雑なニューラルネットワークを計算する機能も備えています。
私の検索で、別のPython指向のScikit学習機械学習ライブラリを見つけました。 さらに、このライブラリは、箱から出してすぐに使える機械学習用の多数のアルゴリズムで、プレゼンテーションは金曜日に行われたので間違いなくプラスであり、実際に動作モデルを実証したかったのです。
既製の例を探して、Scikit-learnを使用してテキストを記述する言語を決定するチュートリアルに出会いました。
したがって、私のタスクは、テキスト文字列内のSQLインジェクションの存在を判断するためにモデルをトレーニングすることでした。 (もちろん、正規表現の助けを借りてこの問題を解決できますが、教育目的
まず、データセットに関する最初のこと...
私が解決しようとしている問題のタイプは分類です。つまり、アルゴリズムは、供給されたデータに応じて、このデータがどのカテゴリーに属しているかを教えてくれます。
アルゴリズムがパターンを探すデータは機能と呼ばれます 。
この機能またはその機能が属するカテゴリはlabelと呼ばれます。 入力には複数の機能がありますが、ラベルは1つだけであることに注意することが重要です。
雌しべと雄しべの長さによってアイリスの花の品種を決定する機械学習の古典的な例では、サイズ情報を持つ個々の列が特徴であり、アイリスの亜種のどれがそのような値を持つ花を持つかを意味する最後の列はラベルです
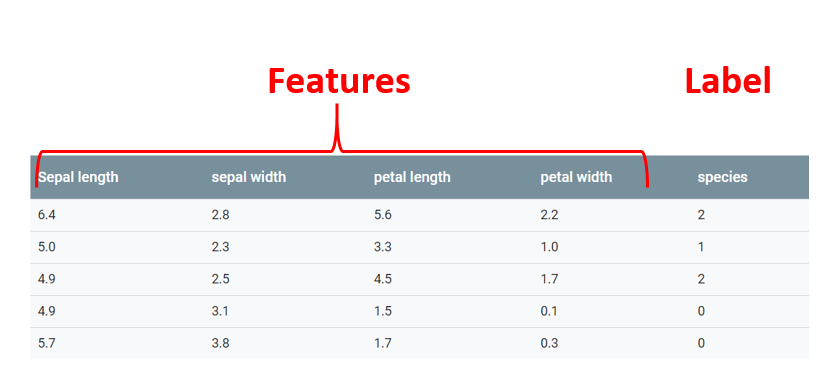
分類問題を解決する方法は、教師あり学習、または教師あり学習と呼ばれます。 これは、学習プロセスで、アルゴリズムが特徴とラベルの両方を受け取ることを意味します。
機械学習の助けを借りて問題を解決する最初のステップは、この機械が学習するデータの収集です。 理想的な世界では、これは実際のデータである必要がありますが、残念ながら、インターネット上で満足できるものは見つかりませんでした。 データを独立して生成することが決定されました。
ランダムな電子メールアドレスとSQLインジェクションを生成するスクリプトを書きました。 その結果、csvファイルには3種類のデータがありました。ランダム電子メール(20,000)、SQLインジェクションを伴うランダム電子メール(20,000)、および純粋なSQLインジェクション(10,000)です。 次のようになりました。
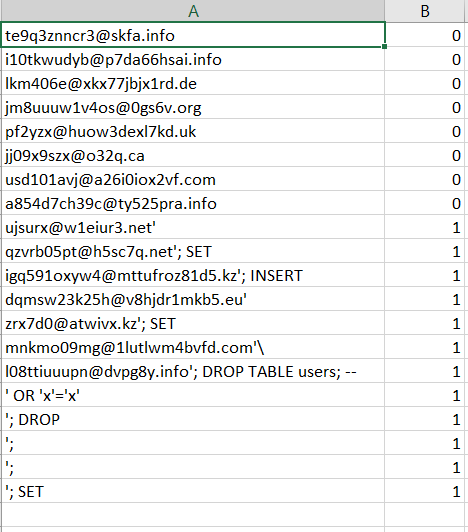
次に、ソースデータを読み取る必要があります。 この関数は、フィーチャを含むシートX、各フィーチャのラベルを含むシートY、および結果を表示するときに便利なラベルのテキスト定義を単に含むシートlabel_namesを返します。
import csv def get_dataset(): X = [] y = [] label_names = ["safe data","Injected email"] with open('trainingSet.csv') as csvfile: readCSV = csv.reader(csvfile, delimiter='\n') for row in readCSV: splitted = row[0].split(',') X.append(splitted[0]) y.append(splitted[1]) print("\n\nData set features {0}". format(len(X))) print("Data set labels {0}\n". format(len(y))) print(X) return X, y, label_names
さらに、これらのデータはトレーニングセットとテストセットに分割する必要があります。 慎重に作成されたcross_validation.train_test_split()関数は、これを支援します。これにより、レコードがシャッフルされ、4つのデータセットが返されます。2つのトレーニングと、フィーチャとラベルの2つのテストセットです。
# Split the dataset on training and testing sets X_train, X_test, y_train, y_test = cross_validation.train_test_split(X,y,test_size=0.2,random_state=0)
次に、ベクトル化オブジェクトを初期化します。このオブジェクトは、送信されたデータを一度に1文字ずつ読み取り、 N-gramに結合し、機械学習アルゴリズムが認識できる数値ベクトルに変換します。
#Setting up vectorizer that will convert dataset into vectors using n-gram vectorizer = feature_extraction.text.TfidfVectorizer(ngram_range=(1, 4), analyzer='char')
フィードデータ
次のステップでは、パイプラインを初期化し、以前に作成したベクトライザーとデータセットの分析に使用するアルゴリズムを渡します。 これでは、 ロジスティック回帰アルゴリズムを使用します。
#Setting up pipeline to flow data though vectorizer to the liner model implementation pipe = pipeline.Pipeline([('vectorizer', vectorizer), ('clf', linear_model.LogisticRegression())])
モデルはデータをダイジェストする準備ができています。 これで、機能とラベルのトレーニングセットをパイプラインに転送するだけで、モデルがトレーニングを開始します。 次の行では、パイプラインを介して機能テストセットを渡しますが、ここでは、predictを使用して、正しく推測されたデータの数を取得します。
#Pass training set of features and labels though pipe. pipe.fit(X_train, y_train) #Test model accuracy by running feature test set y_predicted = pipe.predict(X_test)
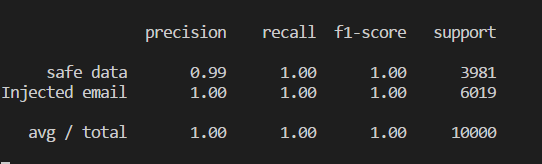
予測におけるモデルの精度を知りたい場合は、推測されたデータとテストシートのラベルを比較できます。
print(metrics.classification_report(y_test, y_predicted,target_names=label_names))
モデルの精度は、0〜1の値によって決まり、パーセントに変換できます。 このモデルでは、100%のケースで正しい答えが得られます。 もちろん、実際のデータを使用すると、そのような結果はそれほど単純ではなく、タスクは非常に単純です。
最後の最後の仕上げは、訓練された形式でモデルを保存し、他のpythonプログラムで再訓練することなく使用できるようにすることです。 Scikit-learnの組み込み関数を使用して、モデルをpickleファイルにシリアル化します。
#Save model into pickle. Built in serializing tool joblib.dump(pipe, 'injection_model.pkl')
別のプログラムでシリアル化されたモデルを使用する方法の小さなデモ。
import numpy as np from sklearn.externals import joblib #Load classifier from the pickle file clf = joblib.load('injection_model.pkl') #Set of test data input_data = ["aselectndwdpyrey@gmail.com", "andrew@microsoft.com'", "a.johns@deloite.com", "'", "select@mail.jp", "update11@nebuzar.com", "' OR 1=1", "asdasd@sick.com'", "andrew@mail' OR 1=1", "an'drew@bark.1ov111.com", "andrew@gmail.com'"] predicted_attacks = clf.predict(input_data).astype(np.int) label_names = ["Safe Data", "SQL Injection"] for email, item in zip(input_data, predicted_attacks): print(u'\n{} ----> {}'.format(label_names[item], email))
出力では、次の結果が得られます。
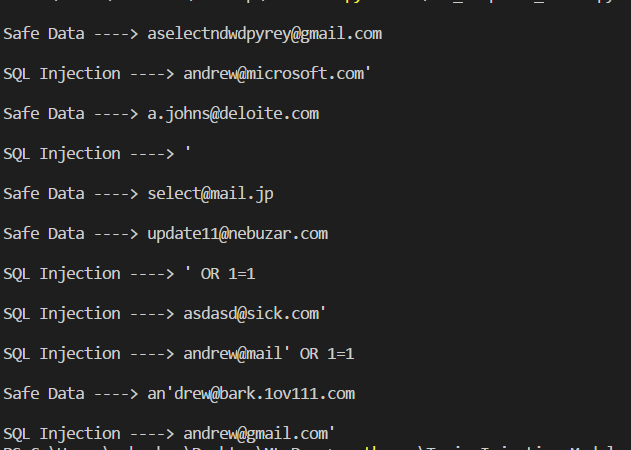
ご覧のように、モデルはSQLインジェクションにかなり自信を持っています。
おわりに
結果として、SQLインジェクションを決定するための訓練されたモデルがあり、理論的にはサーバー側にプラグインできます。インジェクションを決定する場合、他の可能性のある脆弱性から目をそらすためにすべてのリクエストを偽のデータベースにリダイレクトします。 週末にデモを行うために、Flaskで小さなREST APIを作成しました。
これらは機械学習の私の最初のステップでした。 私のように長い間、機械学習に興味を持っていたが、それに触れることを恐れていた人々を鼓舞できることを願っています。
完全なコード
from sklearn import ensemble from sklearn import feature_extraction from sklearn import linear_model from sklearn import pipeline from sklearn import cross_validation from sklearn import metrics from sklearn.externals import joblib import load_data import pickle # Load the dataset from the csv file. Handled by load_data.py. Each email is split in characters and each one has label assigned X, y, label_names = load_data.get_dataset() # Split the dataset on training and testing sets X_train, X_test, y_train, y_test = cross_validation.train_test_split(X,y,test_size=0.2,random_state=0) #Setting up vectorizer that will convert dataset into vectors using n-gram vectorizer = feature_extraction.text.TfidfVectorizer(ngram_range=(1, 4), analyzer='char') #Setting up pipeline to flow data though vectorizer to the liner model implementation pipe = pipeline.Pipeline([('vectorizer', vectorizer), ('clf', linear_model.LogisticRegression())]) #Pass training set of features and labels though pipe. pipe.fit(X_train, y_train) #Test model accuracy by running feature test set y_predicted = pipe.predict(X_test) print(metrics.classification_report(y_test, y_predicted,target_names=label_names)) #Save model into pickle. Built in serializing tool joblib.dump(pipe, 'injection_model.pkl')
参照資料
このプロジェクトに役立った有用なリソースのリストを残します(ほとんどすべてが英語です)
初心者向けのテンソルフロー
Scikit-learnチュートリアル
Scikit-Learnによる言語検出機能の構築
Mediumには、機械学習に関する簡単な例を提供する8つの記事のシリーズなど、いくつかのすばらしい記事が見つかりました。 ( UPD:同じ記事のロシア語翻訳 )