データ分析を行うには、まずこのデータを収集する必要があります。 この目的にはさまざまな方法があります。 この記事では、Webサイトから直接データをコピーする方法、またはスクレイピングについて説明します。 Pythonを使用してコピーを作成する方法に関するHabrの記事がいくつかあります。 R言語(ver。3.4.2)とそのrvestライブラリを使用します。 例として、Google Scholar(GS)からデータをコピーすることを検討してください。
GSは、インターネット全体で情報を検索するのではなく、公開された記事または特許のみを検索する検索エンジンです。 これは非常に役立ちます。 たとえば、一部のキーワードで科学論文を検索する場合。 これを行うには、検索バーにこれらの単語を入力します。 または、特定の著者によって公開された記事を見つける必要があるとしましょう。 これを行うには、単に姓を入力できますが、キーワード「author」を使用し、「author: "D Smith"」などのように入力することをお勧めします。
この検索を実行して、結果を見てみましょう。
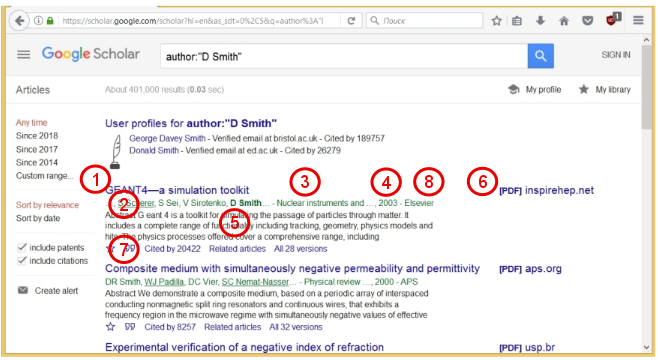
GSは、約40万件の記事が見つかったことを示しています。 各記事について、そのタイトル(1)、著者の名前(2)、雑誌の名前(3)、発行年(4)、および簡単な要約(5)が示されています。 記事のPDFファイルが利用可能な場合、対応するリンク(6)が右側に表示されます。 また、各記事には、重要なパラメーター(7)、つまり、この記事が他の作品で言及された回数(「Cited by」)が示されています。 このパラメーターは、この作業の需要を示します。 複数の記事にこのパラメーターを使用すると、科学者の生産性と「需要」を評価できます。 これは、科学者のいわゆるHインデックスです。 Wikipediaによると、Hirschインデックスは次のように定義されています。
「Np記事のhがそれぞれ少なくともh回引用され、残りの(Np-h)記事がそれぞれh回しか引用されていない場合、科学者はインデックスhを持ちます。」
つまり、特定の著者のすべての記事のリストが引用数の降順で並べられている場合 $インライン$ N_c $インライン$ その後、シリアル番号 $インライン$ n $インライン$ 最後の記事の条件 $インライン$ n \ le N_c $インライン$ 、Hirschインデックスがあります。 さまざまな科学的基盤および組織が現在、Hirschインデックスおよびその他の科学的指標に特別な注意を払っているという事実により、人々はこれらの指標を「巻き上げる」ことを学びました。 しかし、それは別の話です。
この記事では、特定の著者による記事を検索します。 たとえば、ロシアの科学者Alexei Yakovlevich Chervonenkisを取り上げます。 A. Ya。Chervonenkis、コンピューターサイエンスの分野で有名なロシアの科学者は、データ分析と機械学習の理論に大きく貢献しました。 彼は2014年に悲劇的に亡くなりました。
記事の次の7つのパラメーターを収集します:記事のタイトル (1)、 著者のリスト (2)、 雑誌のタイトル (3)、 発行年 (4)、 出版社 (8)、 引用数 (7)、 引用記事へのリンク (7) 。 最後のパラメータは、たとえば、著者の関係を見たい場合、特定の方向で研究を行っている人々のネットワークを識別するために必要です。
準備する
まず、rvestパッケージをインストールする必要があります。 これを行うには、次のRコマンドを使用します。
install.packages(rvest)
ここで、このパラメーターまたはそのパラメーターが対応するWebページコードのコンポーネントを表示するツールが必要です。 ブラウザに組み込まれたツールを使用できます。 たとえば、Mozillaでは、メニューから「ツール-> Web開発->インスペクター」を選択できます。 WebページのHTMLコードが表示されます。 次に、ページの一部の要素にカーソルを合わせると、それに対応するCSSコードを確認できます。 しかし、私たちはそれを簡単にします。 SelectorGadgetツールを使用します。 これを行うには、指定されたサイトに移動し、ブラウザーのブックマークにあるコード(プログラムの説明の最後にある)へのリンクを追加します。

これで、任意のページでこのタブをクリックすると、このページのコードコンポーネントを特定できる便利なツールが表示されます(詳細については、以下を参照してください)。
データをコピーする前に、Webページのプロパティ、つまり、ページがリクエストのタイプからどのように変化するか、さまざまなリンクが対応するアドレスなどを調べることも役立ちます。 したがって、著者: "A Chervonenkis"のクエリでA. Ya。Chervonenkisの記事を検索します。 これは次のアドレスに対応します。
https://scholar.google.com/scholar?hl=en&as_sdt=1%2C5&as_vis=1&q=author%3A%22A+Chervonenkis%22&btnG=
このクエリ構文では、特許、およびChervonenkisにリンクしているが、著者ではない記事は考慮されません。
データをコピーする
それでは、データコピープログラムを入手しましょう。 まず、rvestライブラリを接続します。
library(rvest)
次に、必要なアドレスを設定し、WebページのHTMLコードを読み取ります。
url <- 'https://scholar.google.com/scholar?hl=en&as_sdt=1%2C5&as_vis=1&q=author%3A%22A+Chervonenkis%22&btnG=' wpage <- read_html(url)
次に、記事の名前をコピーします。 これを行うには、SelectorGadgetを実行し、記事のタイトルをクリックします。 この名前は緑色で強調表示されていますが、ページの他のコンポーネントも黄色で強調表示されています。 SelectorGadget行は、152個のコンポーネントが最初に選択されたことを示しています。
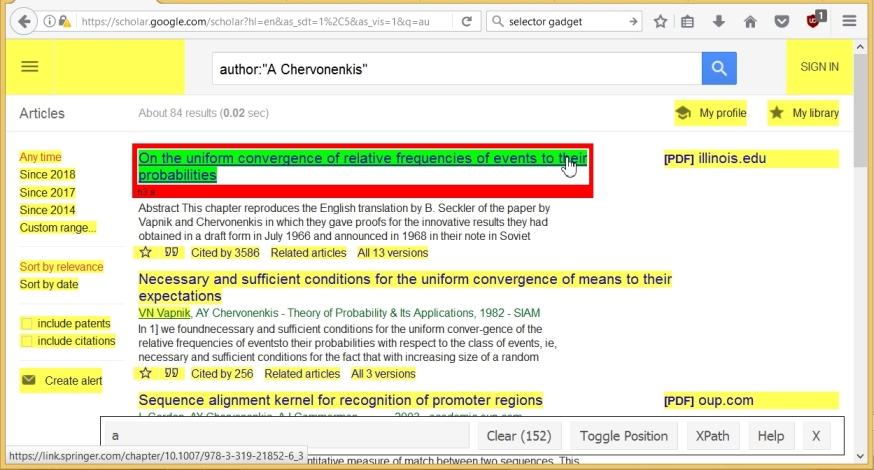
不要なコンポーネントをクリックするだけです。 その結果、(ページ上の記事の数に応じて)10個しかなく、記事の名前に対応するコンポーネントの名前、つまり「.gs_rt a」がSelectorGadget'a行に表示されます。
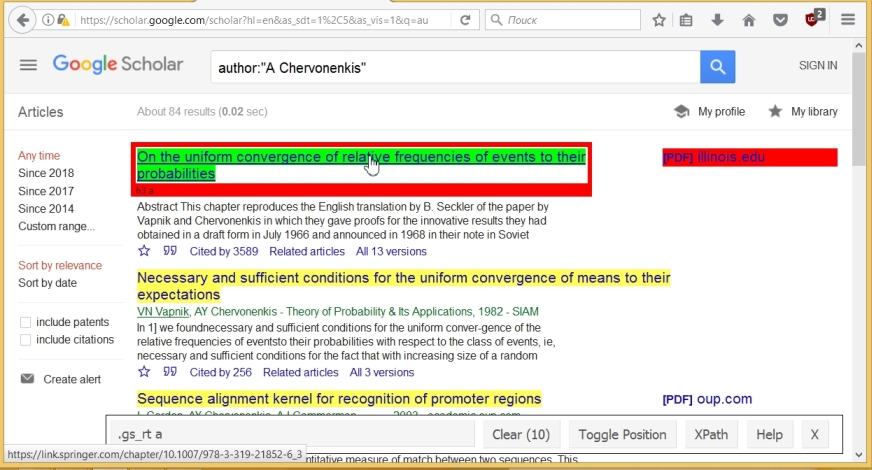
この名前を使用して、次のコマンドを使用して、すべてのタイトルをコピーし、テキスト形式に変換できます(最後のコマンドは、 titles変数の構造を示します)。
titles <- html_nodes(wpage, '.gs_rt a') titles <- html_text(titles) str(titles) ## chr [1:10] "On the uniform convergence of relative frequencies of ..."
以下、文字「##」の後に、プログラム出力(切り捨て形式)が表示されます。
同様に、著者の名前、雑誌の名前、年、出版社がコンポーネント.gs_aに対応していると判断します。 同時に、このコンポーネントのテキストの形式は「<authors>-<journal、year>-<publisher>」です。 「.gs_a」からテキストを抽出し、フォーマットに従って必要なパラメーター( authors 、 journals 、 year 、 publ )を選択し、不要な文字とスペースを削除します
# Scrap combined data, convert to text format: comb <- html_nodes(wpage,'.gs_a') comb <- html_text(comb) str(comb) ## chr [1:10] "VN Vapnik, AY Chervonenkis - Measures of complexity, ..." lst <- strsplit(comb, '-') # Find authors, journal, year, publisher, extracting components of list authors <- sapply(lst, '[[', 1) # Take 1st component of list publ <- sapply(lst, '[[', 3) lst1 <- strsplit( sapply(lst, '[[', 2), ',') journals <- sapply(lst1, '[[', 1) year <- sapply(lst1, '[[', 2) # Replace 3 dots with ~, trim spaces, convert 'year' to numeric : authors <- trimws(gsub(authors, pattern= '…', replacement= '~')) journals <- trimws(gsub(journals, pattern= '…', replacement= '~')) year <- as.numeric(gsub(year, pattern= '…', replacement= '~')) publ <- trimws(gsub(publ, pattern= '…', replacement= '~')) str(authors) ## chr [1:10] "VN Vapnik, AY Chervonenkis " "VN Vapnik, AY Chervonenkis " ...
ジャーナルの名前にハイフン「-」が含まれることがあることに注意してください。 この場合、ソース文字列からパラメータを抽出する手順はわずかに変わります。
次に、SelectorGadgetを使用して、記事ごとの引用数のコンポーネント名を決定し、不要な単語を削除し、データを数値形式に変換します
cit0 <- html_nodes(wpage,'#gs_res_ccl_mid a:nth-child(3)') cit <- html_text(cit0) lst <- strsplit(cit, ' ') cit <- as.numeric(sapply(lst, '[[', 3)) str(cit) ## num [1:10] 3586 256 136 102 30 ...
最後に、適切なリンクを抽出します。
cit_link <- html_attr(cit0, 'href') str(cit_link) ## chr [1:10] "/scholar?cites=3657561935311739131&as_sdt=2005&..."
これで、7つのパラメーターに対して7つのベクター( titles 、 authors 、 journals 、 year 、 publ 、 cit 、 cit_link )ができました。 それらを1つの構造(データフレーム)に結合できます
df1 <- data.frame(titles= titles, authors= authors, journals= journals, year= year, publ = publ, cit= cit, cit_link= cit_link, stringsAsFactors = FALSE)
アドレス「start = n&」に追加することにより、プログラムで次のページに移動できます。n/ 10 + 1はページ番号に対応します。 したがって、すべての記事に関する情報を収集することが可能です
著者。 さらに、引用記事へのリンク( cit_link )を使用すると、他の著者に関するデータを見つけることができます。
結論として、いくつかのコメント。 以下は、Google 利用規約に記載されています。
「サービスを悪用しないでください。たとえば、サービスに干渉したり、提供するインターフェースや指示以外の方法を使用してサービスにアクセスしたりしないでください。」
インターネット上の情報は、特にGSでGoogleがWebページへのアクセスを監視していることを示しています。 ボットを使用して情報が抽出されているとGoogleが疑う場合、特定のIPアドレスからの情報へのアクセスを制限またはブロックできます。 たとえば、リクエストが頻繁に行われる場合、または定期的に行われる場合、この動作は疑わしいと見なされます。
上記の方法は、他のWebサイトに簡単に適用できます。 Rとrvest SelectorGadgetの組み合わせにより、データのコピーが非常に簡単になります。